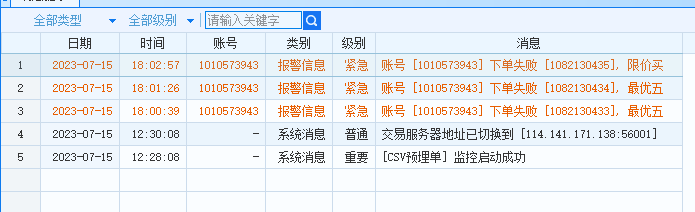
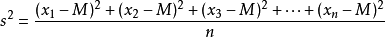RIS 系列 RISCLIP: Referring Image Segmentation Framework using CLIP 论文阅读笔记
- 一、Abstract
- 二、引言
- 三、相关工作
- Referring Image Segmentation
- Visual Grounding Pretraining
- Contrastive Language-Image Pre-training (CLIP)
- 四、Referring Image Segmentation Framework using CLIP
- 4.1 总览
- 4.2 定位器
- 4.2.1 CLIP backbone
- 图像编码器
- 文本编码器
- 概率图
- 4.2.2 Backbone 自适应器
- 4.2.3 融合自适应器
- PreFusion 自适应器
- PostFusion 自适应器
- 4.3 精炼器
- 4.4 损失函数
- 五、实验
- 5.1 数据集和评估指标
- 数据集
- 评估指标
- 5.2 模型设置
- 5.3 与 SOTA方法的比较
- 5.4 消融实验
- 残差自适应地冻结 CLIP 特征
- 增加自适应器的数量
- 5.5 可视化
- 六、结论
- 限制
- 附录
- A 训练细节
- B 失败的案例
- 字符的识别
- 不存在的目标的理解
- C 可视化
- RISCLIP-B
- RISCLIP-L
- D 更深远的影响
写在前面
这周前面时间都在调试代码,跑实验,效果几乎为 0,😅。但是每周的论文阅读还是继续呀,卧凎。
这是一篇用 CLIP 来做指代图像分割的文章。方法是冻结 CLIP,再训练其它模块。
- 论文地址:https://arxiv.org/abs/2306.08498
- 代码地址:作者摘要提及在出版后提供
- 预计提交于某个会议的 Workshop?
- PS:2023 年每周一篇博文,主页 更多干货,欢迎关注呀,期待 5K 粉丝有你的参与呦~
一、Abstract
最近的一些方法推动了指代图像分割 Referring Image Segmentation (RIS),但需要在外部视觉定位数据集上进行大量预训练才能达到 SOTA 的结果。本文尝试使用 CLIP 突破这一限制:在融合自适应器和 Backbone 自适应器的作用下,采用残差结构自适应地冻结 CLIP 特征。在 3 个主要的 RIS 数据集上达到了 SOTA。
这个摘要有点太浓缩了,建议反面教材。
二、引言
首先阐述下视觉语言在多模态任务中的进展,引出 Referring Image Segmentation (RIS),解释下定义和应用范围。
传统的方法从大尺度预训练模型中获得先验知识,例如 预训练视觉 Backbone ViT 模型,BERT 预训练在 Wikipedia 和 Google’s BooksCorpus 数据上。进一步,一些方法从这些预训练模型中提取特征然后进行跨模态的融合,推动了 RIS 的发展。
最近的前沿方法需要额外的预训练在图文数据上才能达到 SOTA 的性能:在外部数据集上进行 bounding box 预测训练,要求额外的实例-文本对齐监督。另一方面,CLIP 已经拥有了大量的实例-文本对齐知识,例如 MaskCLIP。于是本文尝试利用 CLIP 打破需要外部视觉定位数据进行预训练的需求。
首先采用 MaskCLIP 进行实验,发现将 CLIP 直接应用在 RIS 上不能实现 SOTA 的性能:

假设原因是图像联合推理的缺失,使得在目标实例和指代文本间仅有粗糙的对齐,缺乏细粒度的交互。于是本文在 CLIP 图像和文本编码器间引入融合自适应器,通过跨模态注意力在两个模态间交互和结合。
直接微调 CLIP 在 RIS 上可能会丢失一些通用的信息,而仅使用冻结的特征可能会导致模型缺失学习特定 RIS 知识的机会。于是本文提出以一种残差连接的方式,采用新添加的融合自适应器来自适应地冻结 CLIP 特征。此外,在 CLIP 编码器中引入 Backbone 自适应器,以残差连接的方式注入新的特定 RIS 知识。
总之,本文提出用 CLIP - RISCLIP 来进行 RIS,能够根据跨模态交互自适应地调整 CLIP 特征到 RIS 任务中,同时在残差自适应器的帮助下保留最初的知识。实验表明方法达到了 SOTA 的效果。
三、相关工作
Referring Image Segmentation
首先讲述下 RIS 的定义。之前的方法 LSTMs+CNN,后续的方法 + 多模态交互,再之后的注意力机制。最近的方法采用预训练的 Transformer 编码器提取图文特征。本文的工作与这些最新方法类似,不同之处在于并未微调 CLIP 的图像文本编码器,这使得模型能够保留住 CLIP 的完整知识。
Visual Grounding Pretraining
最近的 SOTA 方法需要在外部的视觉定位数据集上进行预训练,主要是 Visual Genome (VG) 数据集。如果没有预训练,性能下降非常大。于是本文尝试调整已经保有充分图文对齐知识的 CLIP 特征,从而去除预训练。
Contrastive Language-Image Pre-training (CLIP)
在大尺度图文对上进行对比预训练后,CLIP 不仅含有大量的视觉和语言专家知识,而且也能一般化地对齐图文知识。 大量的多模态任务,例如文图生成,视觉字幕等,都得益于丰富的多模态对齐。另外有一些工作尝试应用 CLIP 在稠密预测任务上,例如开放词汇目标检测和语义分割。特别是 MaskCLIP 揭示了CLIP 实例-文本对齐的能力。得益于这些优势,本文用 CLIP 作为框架的 Backbone—RISCLIP,在没有预训练的情况下达到 SOTA。
四、Referring Image Segmentation Framework using CLIP
4.1 总览

如上图所示,RISCLIP 由两个部分组成:定位器 Locator 和精炼器 Refiner。给定图文对,定位器提取图文特征并输出能够定位到指代目标 token 级别的概率图。之后在来自定位器产生的中间层视觉特征
v
\mathrm{v}
v 辅助下,精炼器精炼
t
\mathrm{t}
t,产生最终像素级别的概率图
p
\mathrm{p}
p。
定位器采用 CLIP 图像和文本编码器作为 Backbone,通过引入基于融合自适应器中的跨模态注意力来进行特征彼此交互。为了学习 RIS 中的特定知识并保留 CLIP 的一般特征,冻结住 CLIP,然后以残差连接的方式用 Backbone 自适应器调整冻结的特征。总之,所有的融合自适应器和 Backbone 自适应器残差式地自适应调整冻结的 CLIP 特征,使其更适应于 RIS 任务。同时,精炼器利用简单的卷积网络上采样来自定位器输出的 token 级别概率图到最终逐像素的预测。
4.2 定位器
定位器采用图像和文本作为输入,输出定位到指代实例的概率图。其可以划分为三个部分:CLIP backbone,提供通用的图文对齐特征;Backbone 自适应器,采用特定 RIS 的知识来丰富 CLIP 特征;Fusion 自适应器,在图文特征间执行跨模态注意力操作。
4.2.1 CLIP backbone
所有的 CLIP 图像和文本编码器由多个重复堆叠的 Transformer 层、一个正则化层、一个线性投影层组成。用
f
i
∈
R
N
×
C
\mathbf{f}_{i}\in\mathbb{R}^{N\times{C}}
fi∈RN×C 表示第
i
i
i 层 Transformer 层的输出,
N
N
N 是图像或文本特征 tokens 的数量,
C
C
C 表示通道维度。接下来,前向传播过程:
f
ˉ
i
=
M
H
S
A
(
L
N
(
f
i
−
1
)
)
+
f
i
−
1
,
i
=
1
,
.
.
.
,
L
f
i
=
M
L
P
(
L
N
(
f
ˉ
i
)
)
+
f
ˉ
i
\begin{aligned}\bar{\mathbf{f}}_i&=\mathrm{MHSA}(\mathrm{LN}(\mathbf{f}_{i-1}))+\mathbf{f}_{i-1},\quad&i=1,...,L\\\mathbf{f}_i&=\mathrm{MLP}(\mathrm{LN}(\bar{\mathbf{f}}_i))+\bar{\mathbf{f}}_i\end{aligned}
fˉifi=MHSA(LN(fi−1))+fi−1,=MLP(LN(fˉi))+fˉii=1,...,L
图像编码器
图像编码器从图像中提取特征 v \mathrm v v。首先将图像划分为一组 Patches 块,展平后通过线性层映射到 embedding 空间。之后一个可学习的 [CLS] embedding 拼接到 patch embedding 的前面,输出 N visual N_{\text{visual}} Nvisual 个视觉 tokens。添加位置 embeddings 后,采用层正则化,紧接着线性投影到共享的图文 embedding 空间,维度为 d d d。最后的图像特征是一组 [CLS] 和 patch tokens 序列, v = P r o j ( L N ( f L v ) ) = [ v c l s , v p a t c h ] \mathrm{v}=\mathrm{Proj}(\mathrm{LN}(\mathrm{f}_L^v))=[\mathrm{v}_{\mathrm{cls}},\mathrm{v}_{\mathrm{patch}}] v=Proj(LN(fLv))=[vcls,vpatch], v c l s ∈ R 1 × d \mathrm{v}_{\mathrm{cls}}\in\mathbb{R}^{1\times d} vcls∈R1×d, v p a t c h ∈ R ( N visual − 1 ) × d \mathrm{v}_{\mathrm{patch}}\in\mathbb{R}^{(N_\text{visual}{ - 1 })\times d} vpatch∈R(Nvisual−1)×d。上标 v v v 表示特征 f L \mathrm{f}_L fL 来自于图像编码器。
文本编码器
文本编码器计算指代表达式的文本特征 t \mathrm{t} t。首先采用 lower-cased byte pair encoding (BPE) 将文本转化为一组 word embedding 的序列,然后拼接上 [SOS] 和 [EOS] token,输出一组长度为 N text N_{\text{text}} Ntext 的序列。与位置 embedding 求和后送入 Transformer,层正则化。共享的图文 embedding 空间投影作为文本编码器。最终的文本特征为一组序列:[SOS]、词、[EOS] tokens, t = P r o j ( L N ( f L t ) ) = [ t s o s , t w o r d s , t e o s ] \mathrm{t}=\mathrm{Proj}(\mathrm{LN}(\mathrm{f}_{L}^{t}))=[\mathrm{t}_{\mathrm{sos}},\mathrm{t}_{\mathrm{words}},\mathrm{t}_{\mathrm{eos}}] t=Proj(LN(fLt))=[tsos,twords,teos],其中 t s o s , t e o s ∈ R 1 × d \mathrm{t_{sos},t_{eos}~\in~\mathbb{R}^{1\times{d}}} tsos,teos ∈ R1×d, t words ∈ R ( N n e x t − 2 ) × d t_{\text{words}}~\in~\mathbb{R}^{(N_{\mathrm{next}}-2)\times d} twords ∈ R(Nnext−2)×d,[EOS] token t e o s \mathrm{t}_{\mathrm{eos}} teos 为文本的全局表示。
概率图
由于 CLIP 中图像文本特征是已对齐的,于是在 patch token v patch \mathrm{v}_{\text{patch}} vpatch、[EOS] token t \mathrm{t} t 间利用余弦相似度图来定位指代实例,之后这一检测图通过 sigmoid 函数转化为概率图。与 MaskCLIP 类似,本文从视觉编码器的最后一层 Transformer 层中提取 value tokens 来计算概率图。但这个比较粗糙,打不了 SOTA,于是引入 Backbone 自适应器和融合自适应器。
4.2.2 Backbone 自适应器
Backbone 自适应器以残差连接的方式添加,使得新学习到的特征可以以求和的方式添加到原始 CLIP 特征上。冻结 Backbone 能够保留住 CLIP 全面的知识,而利用 Backbone 自适应能够进一步地用新学习的 RIS 信息来丰富特征。自适应结构有一个减少通道维度的下投影线性层,一个非线性激活层,一个上投影线性层恢复到通道维度。以残差的方式的方式添加到 Transformer 层的 MHSA 和 MLP 后:
f
⃗
i
′
=
A
D
M
H
S
A
(
M
H
S
A
(
L
N
(
f
i
−
1
)
)
+
f
i
−
1
)
+
M
H
S
A
(
L
N
(
f
i
−
1
)
)
+
f
i
−
1
,
f
i
=
A
D
M
L
P
(
M
L
P
(
L
N
(
f
⃗
i
′
)
)
+
f
⃗
i
′
)
+
M
L
P
(
L
N
(
f
⃗
i
′
)
)
+
f
⃗
i
′
\begin{aligned}\vec{\mathbf{f}}_i'&=\mathrm{AD}_{\mathrm{MHSA}}\Big({\mathrm{MHSA}(\mathrm{LN}(\mathbf{f}_{i-1}))+\mathbf{f}_{i-1}}\Big)+{\mathrm{MHSA}(\mathrm{LN}(\mathbf{f}_{i-1}))+\mathbf{f}_{i-1}},\\\mathrm{f}_i&=\mathrm{AD}_{\mathrm{MLP}}\Big({\mathrm{MLP}(\mathrm{LN}(\vec{\mathbf{f}}_i^{'}))+\vec{\mathbf{f}}_i^{'}}\Big)+{\mathrm{MLP}(\mathrm{LN}(\vec{\mathbf{f}}_i^{'}))+\vec{\mathbf{f}}_i^{'}}\end{aligned}
fi′fi=ADMHSA(MHSA(LN(fi−1))+fi−1)+MHSA(LN(fi−1))+fi−1,=ADMLP(MLP(LN(fi′))+fi′)+MLP(LN(fi′))+fi′其中
A
D
M
H
S
A
\mathrm{AD}_{\mathrm{MHSA}}
ADMHSA 和
A
D
M
L
P
\mathrm{AD}_{\mathrm{MLP}}
ADMLP 为添加到第
i
i
i 层 Transformer 层中 MHSA 和 MLP 后的 Backbone 自适应器。
4.2.3 融合自适应器
单独的 Backbone 自适应器解决 RIS 的跨模态交互不太够,于是引入融合自适应器,使得图像和文本特征能够通过跨模态注意力进行交互。
跨模态融合可以在 Backbone 特征提取中、之后进行:在 CLIP 中融合中间层的图像文本特征,或在 CLIP 之后的输出特征中进行融合。实验表明同时使用这两类能达到最佳性能。分别给这两种方法取名为 PreFusion 和 PostFusion 自适应器。PostFusion 自适应器由 Cross-Attention (CA)、MHSA、MLP 组成,而 PreFusion Adapters 仅由 CA 组成。对于 PreFusion,单独的 CA 足矣,因为放置在了 CLIP 内部,使得输出的多模态特征能够再次送入 CLIP,从而能够被接下来的 CLIP 内部 MHSA 和 MLP 模块处理。同样,LN 层在每个共享的特征投影之前使用:Pre- 和 PostFusion 中的 CA、 MHSA、MLP。
PreFusion 自适应器
从 Backbone 的最深层开始,将图像和文本编码器层配对,并在两者间添加一个 PreFusion 自适应器。
以第
n
n
n 层图像编码器层和第
m
m
m 层文本编码器为例。首先,自适应器将输入的图像和文本特征
f
n
−
1
v
\mathbf{f}_{n-1}^{v}
fn−1v 和
f
m
−
1
t
\mathbf{f}_{m-1}^{t}
fm−1t分别用线性投影层
W
v
2
s
{{W}}_{v2s}
Wv2s 和
W
t
2
s
W_{t2s}
Wt2s 投影到共享的图文 embedding 空间。之后两个单独的跨模态注意力来产生视觉和文本多模态特征
m
n
−
1
v
\mathbf{m}_{n-1}^v
mn−1v 和
m
m
−
1
t
\mathbf{m}_{m-1}^t
mm−1t,其中每个模态设为多头注意力 multi-head attention (MHA) 中的 query 和其他的 key、value。最后,用线性投影
W
s
2
v
{{W}}_{s2v}
Ws2v 和
W
s
2
t
W_{s2t}
Ws2t 将多模态特征从共享的图文 embedding 空间投影回每个模态的空间
m
n
−
1
v
′
\mathrm{m}_{n-1}^{v^{\prime}}
mn−1v′ 和
m
m
−
1
t
′
{m}_{m-1}^{t^{\prime}}
mm−1t′,用公式表示
m
n
−
1
v
′
\mathrm{m}_{n-1}^{v^{\prime}}
mn−1v′ 的输出过程,
m
m
−
1
t
′
{m}_{m-1}^{t^{\prime}}
mm−1t′ 反之亦然:
s
n
−
1
v
=
W
v
2
s
f
n
−
1
v
,
s
m
−
1
t
=
W
t
2
s
f
m
−
1
t
q
v
=
W
q
s
n
−
1
v
,
k
t
=
W
k
s
m
−
1
t
,
v
t
=
W
v
s
m
−
1
t
m
n
−
1
v
=
M
H
A
(
q
v
,
k
t
,
v
t
)
m
n
−
1
v
′
=
W
s
2
v
m
n
−
1
v
\begin{aligned} &\mathrm{s}_{n-1}^{v}=W_{v2s}\mathrm{f}_{n-1}^{v},\quad\mathrm{s}_{m-1}^{t}=W_{t2s}\mathrm{f}_{m-1}^{t} \\ &\mathbf{q}^{v}=W_{q}\mathbf{s}_{n-1}^{v},\quad\mathbf{k}^{t}=W_{k}\mathbf{s}_{m-1}^{t},\quad\mathbf{v}^{t}=W_{v}\mathbf{s}_{m-1}^{t}\\ &\mathbf{m}_{n-1}^{v}=\mathrm{MHA}(\mathbf{q}^{v},\mathbf{k}^{t},\mathbf{v}^{t})\\ &\mathbf{m}_{n-1}^{v^{\prime}}=W_{s2v}\mathbf{m}_{n-1}^{v} \end{aligned}
sn−1v=Wv2sfn−1v,sm−1t=Wt2sfm−1tqv=Wqsn−1v,kt=Wksm−1t,vt=Wvsm−1tmn−1v=MHA(qv,kt,vt)mn−1v′=Ws2vmn−1v
这些多模态特征
m
n
−
1
v
′
\mathrm{m}_{n-1}^{v^{\prime}}
mn−1v′、
m
m
−
1
t
′
{m}_{m-1}^{t^{\prime}}
mm−1t′ 之后添加到输入的特征,注入多模态信息到 Backbone 的 CLIP 特征上:
f
n
−
1
v
=
f
n
−
1
v
+
m
n
−
1
v
′
\mathbf{f}_{n-1}^{v}=\mathbf{f}_{n-1}^{v}+\mathbf{m}_{n-1}^{v^{\prime}}
fn−1v=fn−1v+mn−1v′
f
m
−
1
t
=
f
m
−
1
t
+
m
m
−
1
t
′
\mathbf{f}_{m-1}^{t}=\mathbf{f}_{m-1}^{t}+\mathbf{m}_{m-1}^{t^{\prime}}
fm−1t=fm−1t+mm−1t′
之后
f
n
−
1
v
\mathbf{f}_{n-1}^{v}
fn−1v、
f
m
−
1
t
\mathbf{f}_{m-1}^{t}
fm−1t 送入第
n
n
n 个图像编码器层和第
m
m
m 个文本编码器层用于进一步的处理。
PostFusion 自适应器
PostFusion 自适应器添加在 CLIP 之后用于融合提取出的图像文本特征
v
\mathbf{v}
v、
t
\mathbf{t}
t。沿着跨模态注意力 CA 进行处理。
最终由 PostFusion 输出的 patch 和 [EOS] tokens 用于计算余弦相似度图,之后经过 sigmoid,成为 token 级别的概率图
t
\mathbf{t}
t。
4.3 精炼器
由于概率图
t
\mathbf{t}
t 是在 tokens 间计算,
t
\mathbf{t}
t 处于 token 级别,需要恢复到细粒度的像素级预测
p
\mathbf{p}
p。于是在 CLIP 图像 Backbone 的辅助下,引入精炼器上采样概率图到输入图像的分辨率上。
精炼器由堆叠的
3
×
3
3\times3
3×3 卷积 + ReLU + batch normalization 组成。非常简单,也可以用 FPN 或 UPerNet 代替。
首先精炼器以概率图为输入,沿特征通道维度拼接上来自 CLIP 图像编码器的中间层视觉特征图。然后在连续的上采样和提炼解码的视觉特征图中,以残差方式式连接浅层的视觉特征。最后一个线性投影层将特征图映射回背景和前景得分图。最后通过 sigmoid 函数得到最终的像素级别图
p
\mathbf{p}
p。在推理阶段,二值预测 mask 通过 argmax 函数获得。
4.4 损失函数
定位器和精炼器分别在不同的分辨率下(token 级别 vs. 像素级别)、两个阶段、相同的损失函数下进行训练。定位器输出的概率图
t
\mathbf{t}
t,用于训练收敛至 token 级别的下采样 GT mask
t
ˉ
\mathbf{\bar t}
tˉ,而精炼器输出的预测 mask
p
\mathbf{p}
p,用于训练收敛至像素级别的 mask
p
ˉ
\mathbf{\bar p}
pˉ。采用 DICE/F-1 loss 和 focal loss 的线性组合来训练模型:
L
s
e
g
(
t
,
t
‾
)
=
λ
f
o
c
a
l
L
f
o
c
a
l
(
t
,
t
‾
)
+
λ
d
i
c
e
L
d
i
c
e
(
t
,
t
‾
)
L
s
e
g
(
p
,
p
ˉ
)
=
λ
f
o
c
a
l
L
f
o
c
a
l
(
p
,
p
ˉ
)
+
λ
d
i
c
e
L
d
i
c
e
(
p
,
p
ˉ
)
\begin{gathered} \mathcal{L}_{\mathrm{seg}}(\mathbf{t},\overline{\mathbf{t}})=\lambda_{\mathrm{focal}}\mathcal{L}_{\mathrm{focal}}(\mathbf{t},\overline{\mathbf{t}})+\lambda_{\mathrm{dice}}\mathcal{L}_{\mathrm{dice}}(\mathbf{t},\overline{\mathbf{t}}) \\ \mathcal{L}_{\mathrm{seg}}(\mathrm{p},\bar{\mathrm{p}})=\lambda_{\mathrm{focal}}\mathcal{L}_{\mathrm{focal}}(\mathrm{p},\bar{\mathrm{p}})+\lambda_{\mathrm{dice}}\mathcal{L}_{\mathrm{dice}}(\mathrm{p},\bar{\mathrm{p}}) \end{gathered}
Lseg(t,t)=λfocalLfocal(t,t)+λdiceLdice(t,t)Lseg(p,pˉ)=λfocalLfocal(p,pˉ)+λdiceLdice(p,pˉ)其中
λ
f
o
c
a
l
\lambda_{\mathrm{focal}}
λfocal 和
λ
d
i
c
e
\lambda_{\mathrm{dice}}
λdice 为超参数。第一阶段,训练定位器,第二阶段仅训练精炼器一个 epoch。
五、实验
5.1 数据集和评估指标
数据集
RefCOCO、RefCOCO+、RefCOCOg、RefCOCO-UMD 分布。
评估指标
overall Intersection-over-Union (oIoU)、mean Intersection-over-Union (mIoU)。mIoU 比 oIoU 更加公平,因为 oIoU 有利于大目标数据。
5.2 模型设置
CLIP 模型中采用 ViT-B 和 ViT-L,对应 RISCLIP-B 和 RISCLIP-L。
在 RISCLIP-B 中,使用 ViT-B,patch_size
16
×
16
16\times16
16×16,文本编码器为 12 层的 Transformer。在 RISCLIP-L 中,使用 ViT-L,patch_size
14
×
14
14\times14
14×14,文本编码器为 12 层的 Transformer。对于所有的 RISCLIP-B 和 RISCLIP-L 模型,在编码器中添加 Backbone 自适应器,6 个 PreFusion 自适应器,6 个 PostFusion 自适应器。
5.3 与 SOTA方法的比较


5.4 消融实验
在 RefCOCOg-UMD 分布上进行消融实验。
残差自适应地冻结 CLIP 特征

增加自适应器的数量

5.5 可视化

六、结论
RISCLIP 应用 CLIP 到 RIS,实现了新的 SOAT。采用 Backbone 自适应器和融合自适应器,进行残差自适应地冻结 CLIP 特征,在充分保留和利用全面图文对齐知识的同时,建立与 RIS 中多模态的联系与交互。在 RISCLIP 中,避免了需要外部的视觉定位预训练才能达到 SOTA 对的结果。
限制
可以采用其它的图文对齐 Backbones,例如 ALIGN、Florence 来提升效果,因此这种方法可以将残差自适应地冻结图文对齐特征应用到不同的基础模型上。在附录 B 中,有些复杂的场景仍然需要进一步提高,才能更加精确地定位到指代目标。
附录
A 训练细节

B 失败的案例
字符的识别

不存在的目标的理解

C 可视化
RISCLIP-B

RISCLIP-L

D 更深远的影响
指代图像分割 Referring Image Segmentation (RIS) 在大量的人机交互领域内都很有潜力,例如自动驾驶、辅助机器人。但需要关注一下潜在的伦理问题,包括隐私、模型 bias、数据处理。总之,RIS 会影响大量采用人机交互的领域,但是道德问题也需要被解决来确保利益提升和安全部署。
写在后面
这篇论文虽然创新点比较简单,可能也就是个 Workshop 级别,但是写作水平极高(除了摘要,太朴实无华了,哈哈),文章逻辑充沛,句法自然,实验也是很充分的,尤其是实验细节的表格处理,值得好好学习。
觉得本文对您有所帮助的话,麻烦点个免费的赞或关注呗,您的支持是作者持续更新、高产的动力~