系列文章目录
第一章deeplabv3+源码之慢慢解析 根目录(1)main.py–get_argparser函数
第一章deeplabv3+源码之慢慢解析 根目录(2)main.py–get_dataset函数
第一章deeplabv3+源码之慢慢解析 根目录(3)main.py–validate函数
第一章deeplabv3+源码之慢慢解析 根目录(4)main.py–main函数
第一章deeplabv3+源码之慢慢解析 根目录(5)predict.py–get_argparser函数和main函数
第二章deeplabv3+源码之慢慢解析 datasets文件夹(1)voc.py–voc_cmap函数和download_extract函数
第二章deeplabv3+源码之慢慢解析 datasets文件夹(2)voc.py–VOCSegmentation类
第二章deeplabv3+源码之慢慢解析 datasets文件夹(3)cityscapes.py–[Cityscapes类]
第二章deeplabv3+源码之慢慢解析 datasets文件夹(4)utils.py–6个小函数
第三章deeplabv3+源码之慢慢解析 metrics文件夹stream_metrics.py–[StreamSegMetrics类和AverageMeter类]
第四章deeplabv3+源码之慢慢解析 network文件夹(0)backbone文件夹(a)hrnetv2.py–[4个类,4个函数,1个主函数]
第四章deeplabv3+源码之慢慢解析 network文件夹(0)backbone文件夹(b)mobilenetv2.py–[3个类,3个函数]
第四章deeplabv3+源码之慢慢解析 network文件夹(0)backbone文件夹©resnet.py–[2个类,12个函数]
第四章deeplabv3+源码之慢慢解析 network文件夹(0)backbone文件夹(d)xception.py–[3个类,1个函数]
第四章deeplabv3+源码之慢慢解析 network文件夹(1)_deeplab.py–[7个类和1个函数]
第四章deeplabv3+源码之慢慢解析 network文件夹(2)modeling.py–[15个函数]
第四章deeplabv3+源码之慢慢解析 network文件夹(3)utils.py–[2个类]
第五章deeplabv3+源码之慢慢解析 utils文件夹(1)ext_transforms.py.py–[17个类]
第五章deeplabv3+源码之慢慢解析 utils文件夹(2)loss.py–[1个类]
第五章deeplabv3+源码之慢慢解析 utils文件夹(3)scheduler.py–[1个类]
第五章deeplabv3+源码之慢慢解析 utils文件夹(4)utils.py–[1个类,4个函数]
第五章deeplabv3+源码之慢慢解析 utils文件夹(5)visualizer.py–[1个类]
总结
文章目录
- 系列文章目录
- 第二章datasets文件夹(2)voc.py--VOCSegmentation类
- VOCSegmentation类
第二章datasets文件夹(2)voc.py–VOCSegmentation类
本篇介绍voc.py中的VOCSegmentation类,整个voc.py中最重要的部分。
VOCSegmentation类
提示:先看完上个部分所说的voc_cmap函数和download_extract函数,本段代码会使用这部分功能。
class VOCSegmentation(data.Dataset):
"""`Pascal VOC <http://host.robots.ox.ac.uk/pascal/VOC/>`_ Segmentation Dataset.
Args:#原代码参数介绍比较详细
root (string): Root directory of the VOC Dataset.
year (string, optional): The dataset year, supports years 2007 to 2012.
image_set (string, optional): Select the image_set to use, ``train``, ``trainval`` or ``val``
download (bool, optional): If true, downloads the dataset from the internet and
puts it in root directory. If dataset is already downloaded, it is not
downloaded again.
transform (callable, optional): A function/transform that takes in an PIL image
and returns a transformed version. E.g, ``transforms.RandomCrop``
"""
cmap = voc_cmap() #详见上一节的voc_cmap函数,返回VOC数据集的分类颜色列表,前21个是数据集标注的结果。
def __init__(self,
root,
year='2012',
image_set='train',
download=False,
#download=True,
transform=None): #构造方法,默认2012年数据,训练,不下载,不转换。
is_aug=False #是否使用扩充(增广Aug)数据
if year=='2012_aug':
is_aug = True
year = '2012'
self.root = os.path.expanduser(root) #详见上文各个参数。另此段代码用到很多os.path的东西,后附补充链接。
self.year = year
self.url = DATASET_YEAR_DICT[year]['url'] #详见上一节DATASET_YEAR_DICT字典
self.filename = DATASET_YEAR_DICT[year]['filename']
self.md5 = DATASET_YEAR_DICT[year]['md5']
self.transform = transform
self.image_set = image_set
base_dir = DATASET_YEAR_DICT[year]['base_dir']
voc_root = os.path.join(self.root, base_dir)
image_dir = os.path.join(voc_root, 'JPEGImages')
if download:
download_extract(self.url, self.root, self.filename, self.md5) #上一节download_extract函数
if not os.path.isdir(voc_root): #如无路径,则表示数据集不存在,即没有下载过数据集,提示下载。
raise RuntimeError('Dataset not found or corrupted.' +
' You can use download=True to download it')
if is_aug and image_set=='train': #训练时选择扩充数据集
mask_dir = os.path.join(voc_root, 'SegmentationClassAug') #指定训练时使用的扩充标签图像文件夹的路径
assert os.path.exists(mask_dir), "SegmentationClassAug not found, please refer to README.md and prepare it manually" #断言提示
split_f = os.path.join( self.root, 'train_aug.txt')#'./datasets/data/train_aug.txt'
else:
mask_dir = os.path.join(voc_root, 'SegmentationClass') #即./datasets/data/VOCdevkit/VOC2012/SegmentationClass
splits_dir = os.path.join(voc_root, 'ImageSets/Segmentation') #即./datasets/data/VOCdevkit/VOC2012/ImageSets/Segmentation
split_f = os.path.join(splits_dir, image_set.rstrip('\n') + '.txt') #当image_set=='train'时,即./datasets/data/VOCdevkit/VOC2012/ImageSets/Segmentation/train.txt
if not os.path.exists(split_f): #当split_f不存在时,提示指定为文件夹内的三个txt文档之一。
raise ValueError(
'Wrong image_set entered! Please use image_set="train" '
'or image_set="trainval" or image_set="val"')
with open(os.path.join(split_f), "r") as f:
file_names = [x.strip() for x in f.readlines()] #打开对应的split_f文档,读取对应的图片名(标签)
self.images = [os.path.join(image_dir, x + ".jpg") for x in file_names] #输入的图像
self.masks = [os.path.join(mask_dir, x + ".png") for x in file_names] #目标图像,分割任务里是标签masks
assert (len(self.images) == len(self.masks)) #断言调试提示输入和输出数量相等
def __getitem__(self, index):
"""
Args:
index (int): Index
Returns:
tuple: (image, target) where target is the image segmentation.
"""
img = Image.open(self.images[index]).convert('RGB') #输入图像转换
target = Image.open(self.masks[index]) #打开对应的目标图像。这两行就是数据读入。
if self.transform is not None:
img, target = self.transform(img, target) #做图像转化(如main代码中的数据增强)
return img, target
def __len__(self): #返回列表的长度,即图片数量
return len(self.images)
@classmethod #定义类方法,面向对象程序设计好好学哦
def decode_target(cls, mask):
"""decode semantic mask to RGB image""" #解码就是把mask转化为RGB图片
return cls.cmap[mask] #返回mask参数所对应的语义分割颜色(即具体的分类标签)。main.py代码中main函数第161,162行。
Tips
- 补充,感兴趣的话新手同学可以参考os.path的简单介绍。
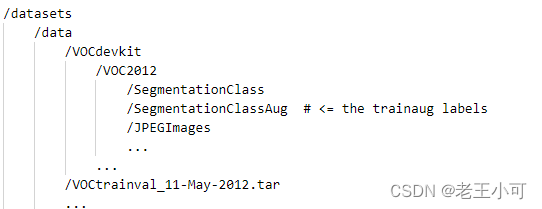
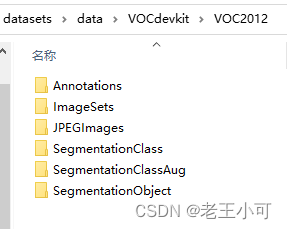
- 补充一次前文的文件夹结构目录。
如VOC数据集的文件夹层级:
- voc.py已全部梳理完。下一个节是cityscapes.py–Cityscapes类。