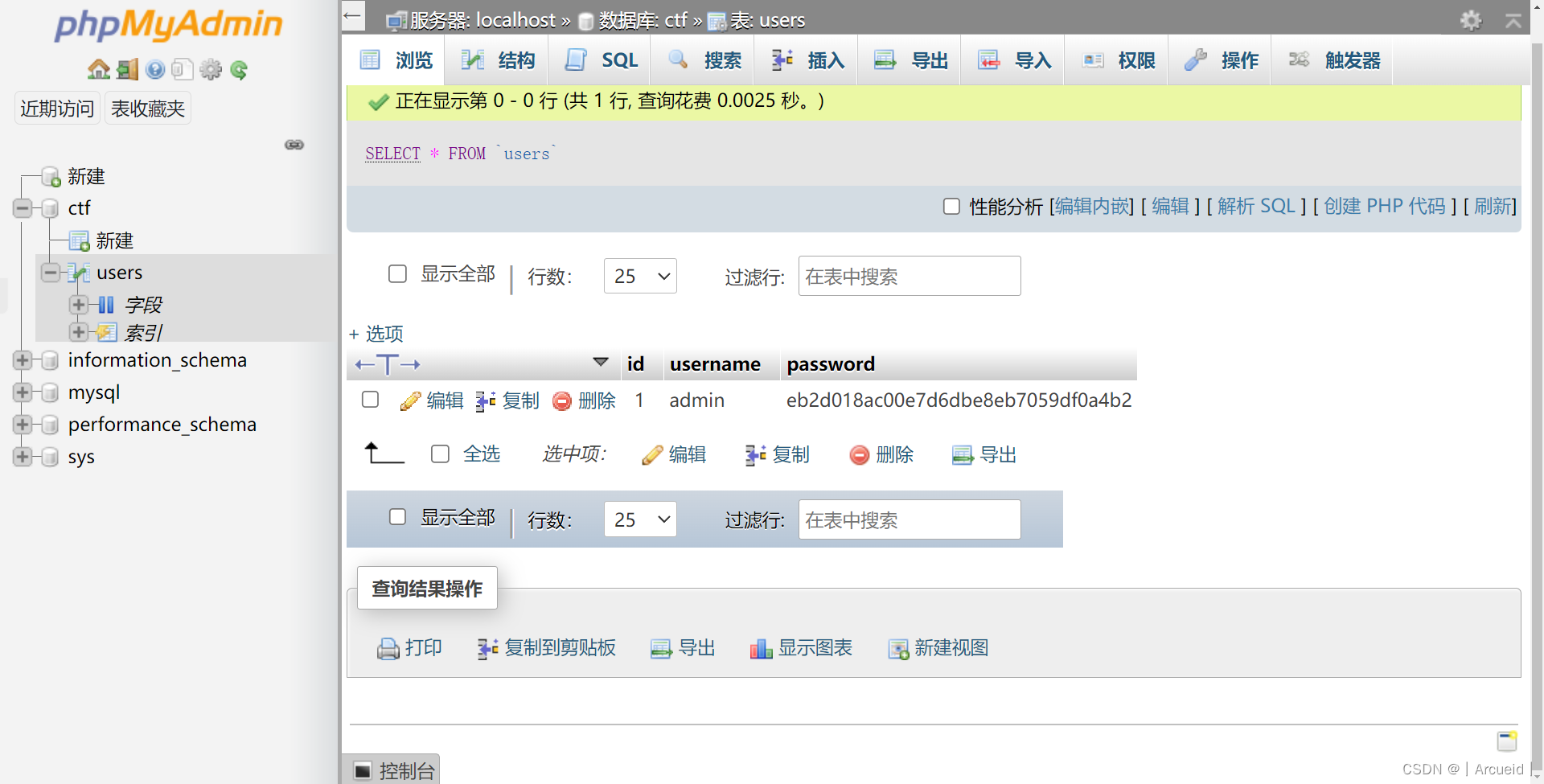
np.unique()函数详解:返回数组的唯一值唯一值默认已进行从小到大的排序

一些重要参数

return_index:bool, optional。如果设置为True,返回数组中唯一值的索引号;否则不返回。
注意:返回的数组和输入的数组的大小不相同,只包含唯一值对应的索引return_inverse:bool, optional。如果设置为True,按照唯一值返回唯一值的索引【对于每一个唯一值而言,索引相同】。
注意:返回的数组和输入的数组的大小完全
**return_count:bool, optional。如果设置为True,按照唯一值返回唯一值在该数组中的数目【对于每一个唯一值而言,索引相同】。
注意:返回的数组和输入的数组的大小完全
# Case 1
np.unique([1, 1, 2, 2, 3, 3])
# 得到唯一值数组
array([1, 2, 3])
# 对于多维数组而言,如果不指定axis,那么将多维数组看作一维数组进行唯一值寻找
a = np.array([[1, 1], [2, 3]])
np.unique(a)
array([1, 2, 3])
# 多维数组,指定axis,将axis下的看作一个整体进行唯一值search
# 对于二维数组,axis=0既是寻找完全不同的行
# 对于二维数组,axis=1既是寻找完全不同的列
a = np.array([[1, 0, 0], [1, 0, 0], [2, 3, 4], [2, 3, 4], [1, 4, 6]])
np.unique(a, axis=0)
array([[1 0 0], [1 4 6], [2 3 4]])
# Case 2
a = np.array(['a', 'b', 'b', 'c', 'a'])
u, indices = np.unique(a, return_index=True)
u
# 返回唯一值
array(['a', 'b', 'c'], dtype='<U1')
indices
# 返回唯一值对应的index,由于array只有三个唯一值,因此只有三个index
array([0, 1, 3], dtype=int64)
# 利用唯一值index提取唯一值
a[indices]
array(['a', 'b', 'c'], dtype='<U1')
# Case 3
a = np.array([1, 2, 6, 4, 2, 3, 2])
u, indices = np.unique(a, return_inverse=True)
u
# 返回唯一值
array([1, 2, 3, 4, 6])
indices
# 返回唯一值在原数组的index
array([0, 1, 4, 3, 1, 2, 1], dtype=int64)
# 利用【唯一值在原数组的index】数组得到原数组
u[indices]
array([1, 2, 6, 4, 2, 3, 2])
# Case 3
a = np.array([1, 2, 6, 4, 2, 3, 2])
values, counts = np.unique(a, return_counts=True)
values
# 返回唯一值
array([1, 2, 3, 4, 6])
counts
# 返回每个唯一值的数目
array([1, 3, 1, 1, 1], dtype=int64)、
# 进行原数组的还原,原始数组的顺序不发生变化
np.repeat(values, counts)
array([1, 2, 2, 2, 3, 4, 6])
# Case 4
# 返回tuple类型的数据
date_uniques = np.unique(date, return_index=True, return_inverse=True, return_counts=True)
学习链接:
- numpy.unique









![[Halcon3D] 3D手眼标定理论与示例解析](https://img-blog.csdnimg.cn/8706fc5749a1487faa1dc389b324b6ee.png#pic_center)