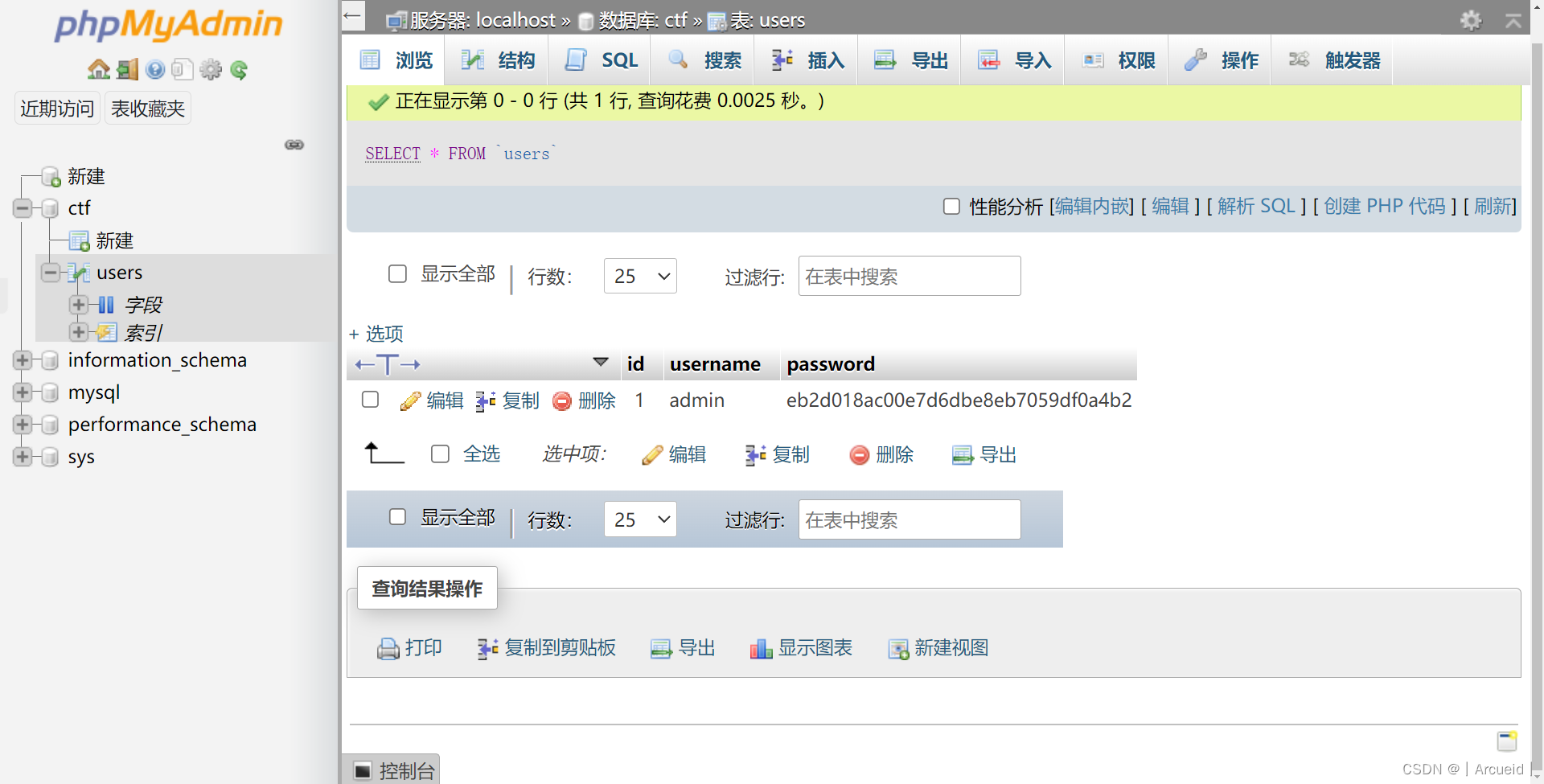
本章和下一章将介绍STL,即C++标准库的容器和算法部分。关键概念序列和迭代器用于将容器(数据)和算法(处理)联系在一起。
20.1 存储和处理数据
首先考虑一个简单的例子:Jack和Jill各自在测量车速,并记录为浮点值。Jack将测量值存储在数组中,而Jill存储在vector中。现在我们想在程序中使用他们的数据,应该怎么做?
我们可以让Jack和Jill的程序将结果写到文件中,然后在我们的程序中读取。这样我们将与他们所选择的数据结构完全隔离。如果决定这样做,我们可以使用第10~11章中的技术读取输入,使用vector<double>进行计算(如下图所示)。
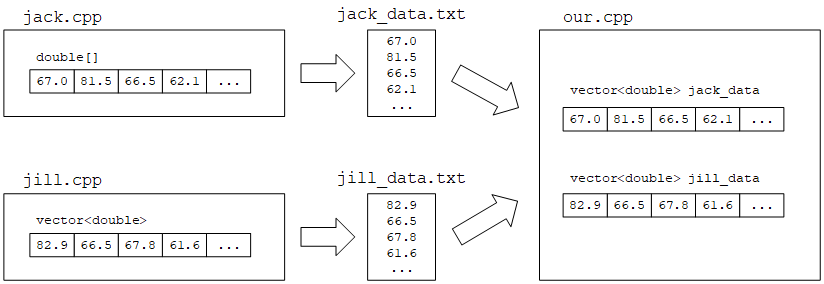
但是,如果我们的任务不适合使用文件呢?假设我们每秒调用一次Jack和Jill的函数来获得要处理的数据:
// Jack puts doubles into an array and returns the number of elements in *count
double* get_from_jack(int* count);
// Jill fills the vector
vector<double>* get_from_jill();
void fct() {
int jack_count = 0;
double* jack_data = get_from_jack(&jack_count);
vector<double>* jill_data = get_from_jill();
// ... process ...
delete[] jack_data;
delete jill_data;
}
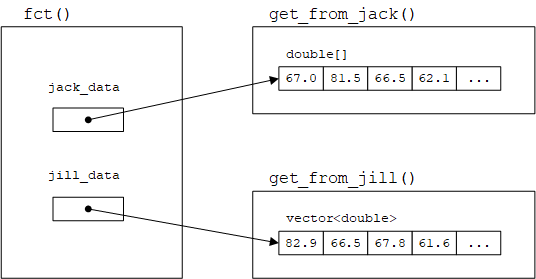
这里假设数据保存在自由存储中,我们使用完后应该删除。另一个假设是我们不能重写Jack和Jill的代码。
20.1.1 使用数据
显然,这是一个简化的例子,但它与很多现实世界中的问题没有什么不同。问题的关键在于,我们不能控制“数据提供者”存储数据的方式。
我们需要如何处理这些数据?存在无限种可能,但首先考虑一个非常简单的任务:找出每组数据中的最大值。我们可以将以下代码插入fct()函数中的 “… process …” 注释部分:
Jack-and-Jill v1
注意这种丑陋的写法:(*jill_data)[i],其中的圆括号是必须的,因为[]的优先级比*高。
20.1.2 一般化代码
我们希望使用统一的方式来访问和操作数据。下面以Jack和Jill的代码为例,讨论如何让我们的代码更加抽象和统一。
显然,我们对Jack和Jill的数据的处理方法非常相似。但是,有一些令人讨厌的差异:jack_count和jill_data–>size()以及jack_data[i]和(*jill_data)[i]。
如何编写一个可以同时处理Jack和Jill的数据的函数?出于通用性的原因(这将在接下来的两章中变得清楚),我们选择了基于指针的解决方案:
Jack-and-Jill v2
于是,我们可以这样写:
double* jack_high = high(jack_data, jack_data + jack_count);
vector<double>& v = *jill_data;
double* jill_high = high(&v[0], &v[0] + v.size());
cout << "Jill's max: " << *jill_high
<< "; Jack's max: " << *jack_high;
这段代码就简洁多了,我们没有引入那么多变量,也没有重复编写循环。
注:函数high()的思想与18.7节中回文的例子是类似的,使用一对指针/索引来表示元素序列/区间[first, last)。
【试一试】这段程序中有两个潜在的严重错误:
high()默认所有数据都非负(将h初始化为-1),如果存在负值则返回结果是错误的。- 指针
high未初始化,当序列为空(即first == last)或数据全部小于-1时,high()返回的是一个野指针。另外,high()默认last >= first,否则循环永远不会结束。
函数high()的局限性在于它只能解决一个特定的问题:
- 只能处理数组(能处理
vector是依赖于其元素也存储在数组中),不能处理list和map等。 - 只能处理
double类型的元素。
下面我们探讨如何在更一般化的数据集合上进行计算。
20.2 STL思想
C++标准库提供了一个将数据作为元素序列处理的框架,叫做标准模板库(standard template library, STL)。STL是ISO C++标准库的一部分,提供了容器(例如vector、list和map)和通用算法(例如sort()、find()和accumulate())。其他标准库特性(例如ostream和C风格字符串函数)并不属于STL。
计算包括两个主要方面:算法和数据。
我们希望编写的代码能够简单、高效地处理计算任务。而对于程序员来说,问题在于:
- 数据类型有无限种变化。
- 存储数据元素集合的方式多得令人眼花缭乱。
- 我们希望对数据集合执行的计算任务各种各样。
因此,我们希望一般化/通用化(generalize)代码来应对这些变化。我们的目标是无需考虑各种容器之间的差别、各种访问元素的方法之间的差别以及各种数据类型之间的差别(注:前两点通过迭代器实现,第三点通过模板实现)。
20.3 序列和迭代器
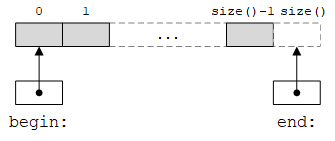
STL的核心概念是序列(sequence)。从STL的角度来看,数据集合就是一个序列。序列有一个开始(beginning)和一个结尾(end),由一对迭代器指定,如下图所示。迭代器(iterator)是标识序列中元素位置的对象。
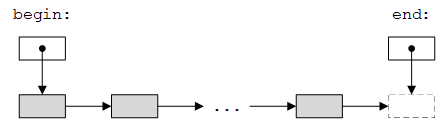
其中,begin和end是迭代器,它们标识了序列的开始和结尾。STL序列是“半开”的,即begin迭代器标识的元素是序列的一部分,而end迭代器指向序列结尾的后面一个位置。在数学上,这种序列通常表示为左闭右开区间[begin, end)。从一个元素到下一个元素的箭头表示:如果我们有指向一个元素的迭代器,那么可以得到指向下一个元素的迭代器。
迭代器究竟是什么?迭代器是一个非常抽象的概念:
- 迭代器指向序列中的一个元素(或最后一个元素的下一个位置)。
- 可以使用
==和!=来比较两个迭代器。 - 可以使用
*来引用迭代器所指向的元素的值。 - 可以使用
++得到下一个元素的迭代器。
注:
- “迭代器”本质上是一种抽象接口/概念,以上就是在描述迭代器支持的操作。
- 序列只是对数据集合的一种抽象,并不关心元素是如何存储的。例如,
vector的元素是连续存储的,而list的元素不是连续的,但二者都可以通过迭代器抽象为序列。
例如,如果p和q是指向同一个序列中元素的迭代器:
| 操作 | 含义 |
|---|---|
p == q | p和q指向同一个元素 |
p != q | p和q指向不同元素 |
*p | p指向的元素 |
++p | 使p指向下一个元素 |
显然,迭代器的思想与指针是相关的(见17.4节)。实际上,数组元素的指针就是数组的迭代器。事实证明,将迭代器作为一种抽象概念而不是特定类型可以带来极大的灵活性和通用性。
注:STL容器都定义了各自的迭代器类型,并且提供了成员函数begin()和end()分别返回开始和结束迭代器。例如,vector<T>的迭代器是vector<T>::iterator,4.6.3节就使用过sort(temps.begin(), temps.end())对向量temp进行排序。
试一试
迭代器可以将算法与数据分离——算法代码的作者只知道迭代器,而不知道迭代器是如何访问数据的;数据提供者(容器代码的作者)只需提供迭代器,而不是将数据存储的细节暴露给用户。正如STL的作者Alex Stepanov所说:“STL算法和容器之所以能很好地协同工作,是因为它们对彼此一无所知。”但是,它们都知道由一对迭代器所定义的序列。
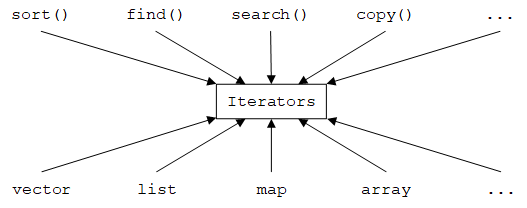
STL可能是目前最著名、使用最广泛的泛型编程的例子。
注:
- 通过使用迭代器和模板,就可以解决20.2节提到的三个问题。
- STL容器库:https://en.cppreference.com/w/cpp/container
- STL算法库:https://en.cppreference.com/w/cpp/algorithm
20.3.1 回到示例
下面使用STL的序列概念来表达“查找最大值”问题:
Jack-and-Jill v3
注意,我们消除了函数high()中表示当前遇到的最大值的局部变量h。当我们不知道序列元素的实际类型时,使用-1来初始化太随意了(可能与元素类型不兼容,导致编译错误)。另外,虽然在这个例子中不会存在负的速度,但是像-1这样的“魔数”是不利于代码维护的。
这个“一般化”的high()可用于任何可以使用<比较的元素类型,并且要求模板参数Iterator必须可拷贝并支持!=、++和*运算符(注:这就是19.3.2节所说的“满足特定的语法和语义要求”)。
模板函数high()可用于任何由一对迭代器定义的序列。在上面的代码中,第一次调用的模板参数是double*(指针作为数组的迭代器),第二次是vector<double>::iterator(使用vector自定义的迭代器,本质上仍然是指针)。
第二次调用也可以使用20.1.2节中的方式high(&v[0], &v[0] + v.size()),即使用指针作为迭代器,模板参数为double*,这依赖于vector将元素存储在数组中。如果使用这种方法,则main()函数的代码与上一个版本没有任何区别,但模板版本的high()具有更好的通用性。
【试一试】这段程序仍然遗留了一个严重错误:当序列为空(即first == last)时,high()返回的迭代器等于last(最后一个元素之后的位置),对其进行解引用会引起问题。
20.4 链表
在20.3节的序列概念示意图中,元素之间的箭头仅仅表示其逻辑位置是相邻的,与实际内存位置无关。
对于vector,其元素在内存中是连续排列的,可视化示意图如下:
本质上,下标0与迭代器v.begin()都标识第一个元素,下标size()与迭代器v.end()都标识最后一个元素的下一个位置。因此,vector的迭代器可以简单地使用下标或指针实现(见20.5节)。
对于链表(17.9.3节),其元素在内存中不是连续的,而是通过指针连接起来。双向链表的示意图如下(与STL序列示意图更接近):
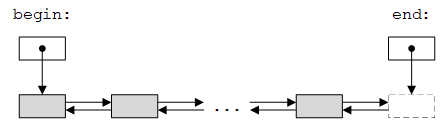
图中元素之间的箭头通常实现为指针(即Link结构体中的prev和succ)。链表的节点(node)/链接(link)由元素和一个或两个指针组成。本节将实现一个双向链表,即C++标准库提供的list(17.9.3节的实现本质上只是链表节点,并不是完整的链表类)。
上述示意图可以用代码表达为:
// doubly-linked list node
template<class Elem>
struct Link {
Link* prev; // previous link
Link* succ; // successor (next) link
Elem val; // the value
};
// doubly-linked list
template<class Elem>
class list {
public:
// ...
private:
Link<Elem>* first;
Link<Elem>* last; // one beyond the last link
};
链表的关键性质是:可以在不影响已有元素的前提下插入和删除元素(只需要调整相邻节点的指针,因此插入和删除操作的时间复杂度为O(1);相反,vector的插入和删除操作需要移动元素,时间复杂度为O(n))。
当你尝试思考链表时,我们强烈建议你画一些图示来可视化你正在考虑的操作(如17.9.3节)。
20.4.1 链表操作
对于链表我们需要什么操作?
- 构造函数、析构函数、赋值、
size() - 插入和删除
- 迭代器:用于引用元素和遍历链表
// doubly-linked list
template<class Elem>
class list {
public:
class iterator; // member type: iterator
iterator begin(); // iterator to first element
iterator end(); // iterator to one beyond last element
iterator insert(iterator p, const Elem& v); // insert v into list after p
iterator erase(iterator p); // remove p from the list
void push_back(const Elem& v); // insert v at end
void push_front(const Elem& v); // insert v at front
void pop_front(); // remove the first element
void pop_back(); // remove the last element
Elem& front(); // the first element
Elem& back(); // the last element
// ...
private:
Link<Elem>* first;
Link<Elem>* last; // one beyond the last link
};
就像我们的vector不是完整的标准库vector一样,这里的list也不是标准库list的完整定义。其目的是帮助你理解链表是什么,如何实现,以及如何使用其关键特性。
迭代器是STL list定义的核心,用于访问元素、标识插入/删除元素的位置以及遍历链表。STL容器将迭代器作为成员类型,并命名为iterator,例如list<T>::iterator、vector<T>::iterator、map<K,V>::iterator等。
list没有下标操作(因为它无法像vector一样通过下标访问元素,即随机访问(random access))。如果需要,可以使用迭代器来实现。
20.4.2 迭代
list迭代器必须提供*、++、==和!=操作。由于list是双向链表,还提供了--操作用于反向迭代。
template<class Elem>
class list<Elem>::iterator {
public:
explicit iterator(Link<Elem>* p) :curr(p) {}
iterator& operator++() { curr = curr->succ; return *this; } // forward
iterator& operator--() { curr = curr->prev; return *this; } // backward
Elem& operator*() { return curr->val; } // get value (dereference)
bool operator==(const iterator& b) const { return curr == b.curr; }
bool operator!=(const iterator& b) const { return curr != b.curr; }
private:
Link<Elem>* curr; // current link
};
这些函数十分简明且高效:没有循环和复杂的表达式。这里的list迭代器就是指向节点的指针,*、++和--运算符分别对应其指向节点的val、succ和prev成员。
再次回顾20.3.1节中的high(),我们可以将其用于list:
查找链表中的最大值
其中,high()的模板参数是list<int>::iterator。
现在,是时候回答20.3.1节中“试一试”提出的问题:对于函数high(),如果序列为空(即first == last),则其返回的迭代器等于last(最后一个元素的下一个位置),对其进行解引用是一个灾难性错误(结果取决于元素类型和迭代器实现,对于vector将导致越界访问,对于list可能导致空指针访问)。
解决方法是:通过比较开始和结尾来判断序列是否为空,如下图所示。
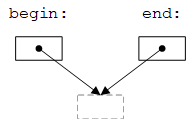
这是使end指向最后一个元素的下一个位置而不是最后一个元素的深层次原因:空序列不是特例。
在我们的例子中可以这样使用:
auto p = high(lst.begin(), lst.end());
if (p == lst.end()) // did we reach the end?
cout << "The list is empty";
else
cout << "the highest value is " << *p << '\n';
STL查找类算法普遍采用了这种方式:返回结尾迭代器表示“未找到”。
因为标准库提供了链表,我们在这里不再深入讨论其实现(见习题12)。
20.5 再次一般化vector
标准库vector有iterator成员类型以及begin()和end()成员函数(就像list一样)。然而,在第19章中我们并没有为我们的vector提供这些。
简单向量v3 - 增加迭代器
其中的using声明为类型创建了一个别名(详见Type alias)。也就是说,对于我们的vector,我们选择使用指针作为迭代器,iterator就是T*的别名/同义词(因此迭代器的*、++、==等操作就是普通指针的运算符)。现在,对于vector对象v,可以这样写:
vector<int>::iterator p = find(v.begin(), v.end(), 32);
for (vector<int>::size_type i = 0; i < v.size(); ++i) cout << v[i] << '\n';
这里的关键点在于,在编写这段代码时,我们实际上不需要知道iterator和size_type的实际类型。在大多数C++实现中,标准库vector的迭代器并不是普通指针,但上面的代码仍然能够正常运行。
使用using定义类型别名是C++11引入的语法,在C和C++11之前使用typedef。
注意:将size()改为无符号类型后要小心倒序遍历时溢出导致的无限循环:
for (auto i = v.size() - 1; i >= 0; --i) // infinite loop!
cout << v[i] << '\n';
因为无符号的0减1等于232-1(即4294967295)。
20.5.1 容器遍历
使用size()和下标,我们可以从头到尾遍历vector元素。例如:
void print1(const vector<double>& v) {
for (int i = 0; i < v.size(); ++i)
cout << v[i] << '\n';
}
这不能用于list,因为list没有提供下标操作。然而,我们可以使用更简单的range-for循环来遍历vector和list。例如:
void print2(const vector<double>& v, const list<double>& lst) {
for (double x : v)
cout << x << '\n';
for (double x : lst)
cout << x << '\n';
}
这段代码对于标准库容器和我们自己的vector和list都能正常运行。实际上,range-for循环仅仅是使用迭代器遍历序列的“语法糖”。对于容器v:
for (T x : v)
// ...
大致等价于
for (auto begin = v.begin(), end = v.end(); begin != end; ++begin) {
T x = *begin;
// ...
}
由于我们为vector和list定义了迭代器以及begin()和end(),因此“意外地”支持了使用range-for遍历。
详见range-for。
20.5.2 auto
当我们使用迭代器时,类型名称写起来很繁琐。例如:
template<class T>
void user(vector<T>& v, list<T>& lst) {
for (vector<T>::iterator p = v.begin(); p != v.end(); ++p) cout << *p << '\n';
list<T>::iterator q = find(lst.begin(), lst.end(), T{42});
}
幸运的是,我们不必这样写:我们可以将变量类型声明为auto,表示其类型由初始值推导出来(类似于模板参数推导)。例如:
template<class T>
void user(vector<T>& v, list<T>& lst) {
for (auto p = v.begin(); p != v.end(); ++p) cout << *p << '\n';
auto q = find(lst.begin(), lst.end(), T{42});
}
其中,p是vector<T>::iterator,q是list<T>::iterator。
我们可以在任何包含初始值的声明中使用auto。例如:
auto x = 123; // x is an int
auto c = 'y'; // c is a char
auto& r = x; // r is an int&
auto y = r; // y is an int (references are implicitly dereferenced)
注意,字符串常量的类型是const char*:
auto s1 = "San Antonio"; // s1 is a const char* (Surprise!?)
string s2 = "Fredericksburg"; // s2 is a string
auto的一个常见用法是指定range-for循环中的循环变量。例如:
template<class C>
void print3(const C& cont) {
for (const auto& x : cont)
cout << x << '\n';
}
20.6 示例:简单文本编辑器
链表最重要的性质是可以在不移动其他元素的情况下添加或删除元素(只需几次指针赋值操作,例如17.9.3节insert()操作的示意图)。下面我们通过一个简单的例子来说明这一点。考虑如何在文本编辑器中表示文本文件的字符,表示方式应当使得对文档的操作简单且高效。我们所选择的表示方式必须支持5种操作:
- 从输入的字节流创建
- 插入一个或多个字符
- 删除一个或多个字符
- 查找字符串
- 生成字节流从而输出到文件或屏幕
注:本节要实现的“文本编辑器”不是下面这样,而是一个能够对多行文本进行操作的类。这个类可以作为真实文本编辑器应用的后端代码,只是没有GUI界面。
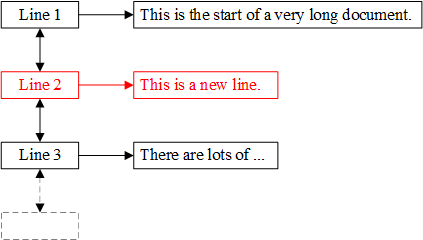
最简单的表示方式是vector<char>。然而,要插入或删除一个字符必须移动后面的所有字符,这对于超大的文档是不可接受的。我们考虑文档“分解”成多个“块”,使得改变一部分不影响其他部分(这恰好符合链表的性质)。因此,我们将文档表示为文本行的链表list<Line>,其中Line是vector<char>。例如,文档
This is the start of a very long document.
There are lots of ...
在内存中的表示如下:

现在,插入字符只需要移动相应行中的字符。如果需要插入新行,则不需要移动任何字符。例如,在第一行之后插入 “This is a new line.”,得到
This is the start of a very long document.
This is a new line.
There are lots of ...
我们只需要在链表中插入一个“节点”:
20.6.1 行
我们依靠换行符('\n')来划分“行”,并将文档表示为一个Document类的对象:
简单文本编辑器
每个Document都以一个空行开始:Document的构造函数会创建一个空行并添加到链表中(注:这是为了避免链表为空,方便迭代器的实现)。
>>运算符读取输入并划分成行。
注:如果输入结尾不是换行符,>>会强制添加一个空行,从而保证链表的最后一个元素始终是一个空行。这是为了标识序列结尾,用于实现end()迭代器(见下一节)(类似于C风格字符串始终以空字符结尾)。但这样会存在一个问题:如果两次调用>>运算符,第一次的输入结尾不是换行符,那么最后一行和第二次输入的第一行会被拆分到两个不同的“行”(链表元素)中。这不影响输出,但可能导致erase_line()删除不完整的行(见下一节)。
vector和list都有一个成员函数back(),返回最后一个元素的引用(即v.back()等价于v[v.size() - 1])。使用back()时一定要确保容器不为空,这也是我们为Document添加空行的原因。注意对输入的每个字符都会存储,包括换行符,这会极大地简化输出。
20.6.2 迭代
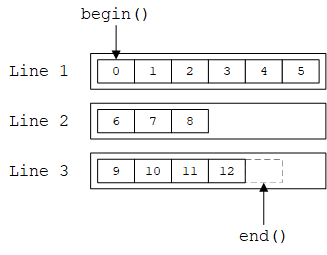
显然,我们可以使用list<Line>::iterator来迭代行的链表。但是,如果我们想要逐个访问字符而不考虑换行符,就需要专门为Document提供一个迭代器Text_iterator:
Text_iterator
Text_iterator的思想是:用行号和行内位置标识一个字符,迭代时将整个文档视为所有行拼接起来的一个字符序列(实际上就是划分行前的原始字符序列),如下图所示,其中数字表示字符的迭代顺序。
注:由于>>运算符在读取完输入后会强制插入
为了使用Text_iterator,我们需要为Document定义begin()和end()函数。
现在,我们可以这样迭代文档的字符:
void print(Document& d) {
for (auto c : d) cout << c;
}
将文档表示为行的链表(内存角度)/字符序列(迭代器角度)对于很多操作都是有用的。例如,函数erase_line()删除文档的第n行:
erase_line()
标准库函数advance(p, n)将迭代器p向前(或向后)移动n个元素;next(p, n)与advance(p, n)类似,但返回移动后的迭代器。
对于双向迭代器(可以向前和向后移动),比如list<T>::iterator,advance()的参数为正将向前移动,参数为负将向后移动。对于随机访问迭代器(支持与整数加减),比如vector<T>::iterator,advance()将直接移动到指定位置(等价于p += n),而不是使用++移动n次。
对于用户来说,查找可能是最直观的一种迭代。下面实现在Document中查找一个字符串。我们使用一种简单的、但不是最优的算法:
- 在文档中查找字符串的第一个字符。
- 判断后续字符是都与查找的字符串匹配。
- 如果是,则结束;否则,继续查找字符串的第一个字符。
为了通用性,我们采用STL约定,把待搜索的文本定义为一对迭代器表示的序列。如果在文档中找到了字符串,则返回其第一个字符的迭代器;否则返回序列结尾的迭代器。
find_txt()
返回序列结尾迭代器来表示“未找到”是一个重要的STL约定。 我们可以这样使用find_txt():
auto p = find_txt(my_doc.begin(), my_doc.end(), "secret\nhomestead");
if (p == my_doc.end())
cout << "not found";
else {
// do something
}
注意:自定义的迭代器类型可以用于range-for循环,但不能直接用于STL算法,还需要指定迭代器类别(iterator category),否则函数find_txt()中的find()调用会报错 “In template: no matching function for call to ‘__iterator_category’”。迭代器类别用于标准库内部选择最优的算法(例如advance()对于list和vector迭代器的不同实现),见Named Requirements - Iterator。为自定义迭代器指定类别有两种方法:
(1)(使用using或typedef)定义以下5个成员类型(缺一不可):
| 成员类型 | 含义 |
|---|---|
iterator_category | 迭代器类别 |
value_type | 元素类型 |
difference_type | 表示迭代器之间距离的类型(通常为ptrdiff_t) |
pointer | 元素指针类型(通常为value_type*) |
reference | 元素引用类型(通常为value_type&) |
其中,迭代器类别从标准库头文件<iterator>中定义的迭代器标签中选择。例如:
#include <iterator>
class Text_iterator {
public:
using iterator_category = std::forward_iterator_tag;
using value_type = char;
using difference_type = ptrdiff_t;
using pointer = char*;
using reference = char&;
// ...
};
由于Text_iterator只提供了*和++操作,因此属于前向迭代器(forward iterator)。
(2)继承std::iterator,该类型只是提供了以上5个成员类型的定义,通过模板参数指定(后3个类型可省略)。例如:
#include <iterator>
class Text_iterator : public std::iterator<std::forward_iterator_tag, char> {
public:
// ...
};
这种方法更简单(毕竟谁会需要自定义元素指针和引用类型呢),但奇怪的是这个类在C++17中弃用了。








![[Halcon3D] 3D手眼标定理论与示例解析](https://img-blog.csdnimg.cn/8706fc5749a1487faa1dc389b324b6ee.png#pic_center)