The Linux Kernel Module Programming Guide
- Peter Jay Salzman, Michael Burian, Ori Pomerantz, Bob Mottram, Jim Huang
- 译 断水客(WaterCutter)
- 源 LKMPG

10 系统调用
到目前为止,我们所做的唯一一件事就是使用定义明确的内核机制来注册/proc文件和设备处理程序。如果你想做内核程序员认为你会想做的事情,比如编写设备驱动程序,这很好。但如果你想做一些不寻常的事情,以某种方式改变系统的行为呢?那就只能靠自己了。
如果你不理智地使用虚拟机,那么这就是内核编程变得危险的地方。在编写下面的示例时,我关闭了open()系统调用。这意味着我不能打开任何文件,不能运行任何程序,也不能关闭系统。我不得不重新启动虚拟机。虽然没有重要文件丢失,但如果我在关键任务系统上这样做的话,可能会出现这样的结果。为了确保不丢失任何文件,即使是在测试环境中,请在进行insmod和rmmod之前运行同步。
忘记/proc文件,忘记设备文件。它们只是一些小细节。在浩瀚无垠的宇宙中只是细枝末节。真正的进程到内核的通信机制,也就是所有进程都使用的机制,是系统调用。当一个进程请求内核提供服务时(例如打开一个文件,分叉到一个新的进程,或者请求更多内存),使用的就是这种机制。如果你想以有趣的方式改变内核的行为,这就是实现的地方。顺便说一下,如果你想查看一个程序使用了哪些系统调用,运行strace 。
一般来说,进程不应该能够访问内核。它不能访问内核内存,也不能调用内核函数。CPU的硬件会强制执行这一点(这就是它被称为 "protected mode "或 "page protection "的原因)。
系统调用是这一一般规则的例外。系统调用的过程是,进程用适当的值填充寄存器,然后调用一条特殊指令,跳转到内核中先前定义的位置(当然,用户进程可以读取该位置,但不能写入)。在Intel CPU中,这是通过中断0x80完成的。硬件知道,一旦您跳转到这个位置,您就不再是在受限的用户模式下运行,而是作为操作系统内核运行,因此您可以为所欲为。
进程可以跳转到的内核位置称为system_call。在该位置的过程检查系统调用号,它告诉内核进程请求什么服务。然后,它查看系统调用表(sys_call_table)来查看要调用的内核函数的地址。然后调用函数,返回后做一些系统检查,然后返回到进程(如果进程时间用完了,则返回到另一个进程)。如果你想阅读这段代码,可以在源文件arch/$(architecture)/kernel/entry.S中ENTRY(system_call)行之后找到。
因此,如果我们想改变某个系统调用的工作方式,我们需要做的是编写我们自己的函数来实现它(通常是通过添加一些我们自己的代码,然后调用原来的函数),然后改变sys_call_table的指针指向我们的函数。因为我们以后可能会被移除,我们不想让系统处于不稳定的状态,所以cleanup_module恢复表的原始状态是很重要的。
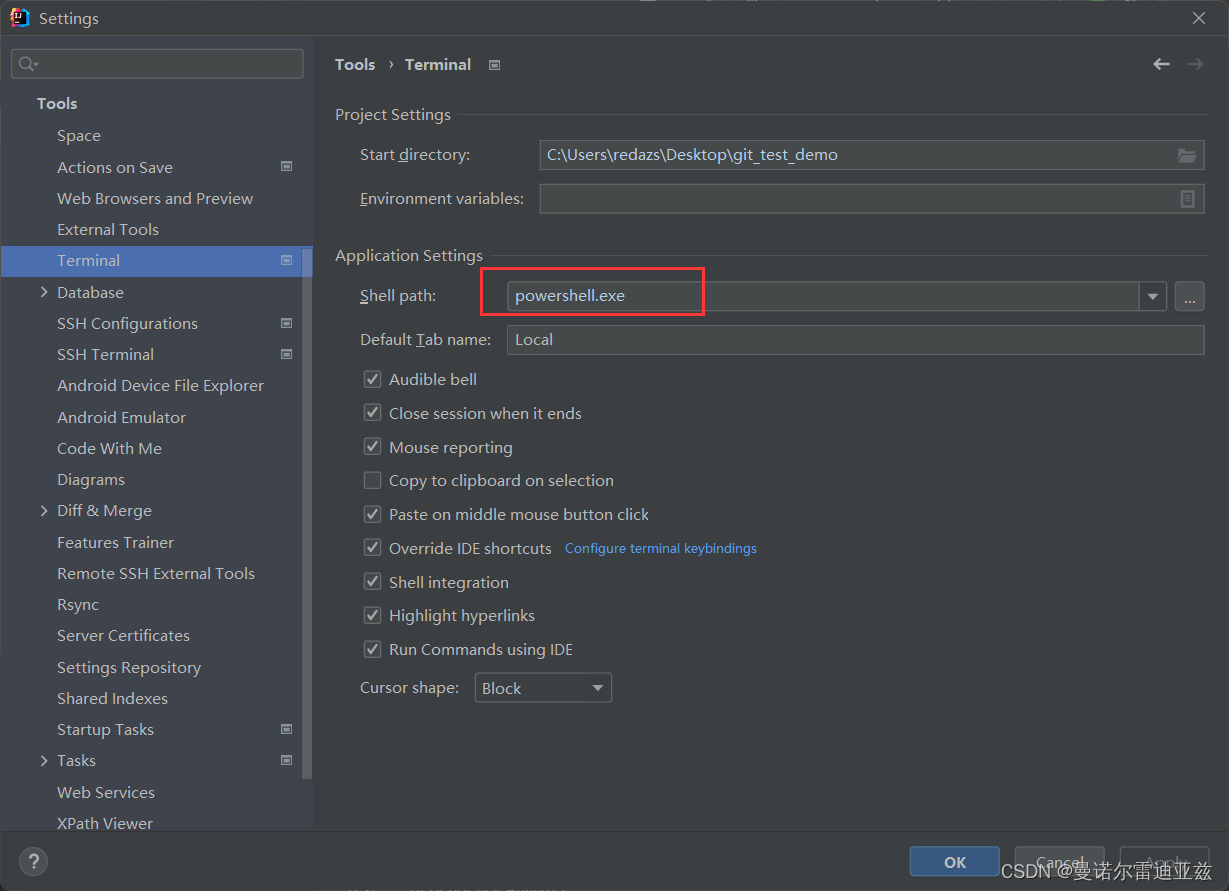
要修改sys_call_table的内容,我们需要考虑控制寄存器。控制寄存器是一个处理器寄存器,用于改变或控制CPU的一般行为。在x86架构中,cr0寄存器具有各种控制标志,用于修改处理器的基本操作。cr0中的WP标志代表写保护。因此,在修改sys_call_table之前,我们必须禁用WP标志。从Linux v5.3版本开始,write_cr0函数就不能使用了,因为cr0位被安全问题锁定,攻击者可能会写入CPU控制寄存器来禁用CPU保护,如写保护。因此,我们必须提供自定义的汇编例程来绕过它。
然而,为了防止误用,sys_call_table符号是未导出的。但是有几种方法可以获得符号,手动符号查找和kallsyms_lookup_name。这里我们根据内核版本使用这两种方法。
由于控制流的完整性,这是一种防止攻击者重定向执行代码的技术,以确保间接调用到预期的地址,并且返回地址不会被改变。自Linux v5.7以来,内核为x86打上了一系列控制流执行(CET)的补丁,GCC的某些配置,如Ubuntu中的GCC 9和10版本,将默认在内核中添加CET(-fcf-protection选项)。在关闭retpoline的情况下使用该GCC编译内核可能会导致CET在内核中被启用。你可以使用下面的命令来检查-fcf-protection选项是否启用:
$ gcc -v -Q -O2 --help=target | grep protection
Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/lib/gcc/x86_64-linux-gnu/9/lto-wrapper
...
gcc version 9.3.0 (Ubuntu 9.3.0-17ubuntu1~20.04)
COLLECT_GCC_OPTIONS='-v' '-Q' '-O2' '--help=target' '-mtune=generic' '-march=x86-64'
/usr/lib/gcc/x86_64-linux-gnu/9/cc1 -v ... -fcf-protection ...
GNU C17 (Ubuntu 9.3.0-17ubuntu1~20.04) version 9.3.0 (x86_64-linux-gnu)
...
但是CET不应该在内核中启用,因为它可能会破坏Kprobes和bpf。因此,从v5.11开始禁用CET。为了保证手动符号查找的有效性,我们只使用到v5.4。
不幸的是,从Linux v5.7开始,kallsyms_lookup_name也是未导出的,需要一些技巧来获取kallsyms_lookup_name的地址。如果启用了CONFIG_KPROBES,我们就可以通过Kprobes来获取函数地址,从而动态地进入特定的内核例程。Kprobes通过替换探测指令的第一个字节,在函数入口处插入一个断点。当CPU碰到断点时,寄存器被保存,控制权将传递给Kprobes。它将保存的寄存器地址和Kprobe结构传递给您定义的处理程序,然后执行它。Kprobes可以通过符号名或地址注册。在符号名中,地址将由内核处理。
否则,请在sym参数中指定/proc/kallsyms和/boot/System.map中的sys_call_table地址。下面是/proc/kallsyms的示例用法:
$ sudo grep sys_call_table /proc/kallsyms
ffffffff82000280 R x32_sys_call_table
ffffffff820013a0 R sys_call_table
ffffffff820023e0 R ia32_sys_call_table
$ sudo insmod syscall.ko sym=0xffffffff820013a0
使用/boot/System.map中的地址时,请注意KASLR(内核地址空间布局随机化)。KASLR可能会在每次启动时随机化内核代码和数据的地址,例如/boot/System.map中列出的静态地址会被一些熵抵消。KASLR的目的是保护内核空间不受攻击。如果没有KASLR,攻击者很容易在固定地址中找到目标地址。如果没有KASLR,攻击者可能很容易在固定地址中找到目标地址,然后攻击者可以使用面向返回的编程方式插入一些恶意代码,通过篡改指针来执行或接收目标数据。KASLR减轻了这类攻击,因为攻击者无法立即知道目标地址,但暴力破解攻击仍然可以奏效。如果/proc/kallsyms中的符号地址与/boot/System.map中的地址不同,则表明KASLR已在系统运行的内核中启用。
$ grep GRUB_CMDLINE_LINUX_DEFAULT /etc/default/grub
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash"
$ sudo grep sys_call_table /boot/System.map-$(uname -r)
ffffffff82000300 R sys_call_table
$ sudo grep sys_call_table /proc/kallsyms
ffffffff820013a0 R sys_call_table
# Reboot
$ sudo grep sys_call_table /boot/System.map-$(uname -r)
ffffffff82000300 R sys_call_table
$ sudo grep sys_call_table /proc/kallsyms
ffffffff86400300 R sys_call_table
If KASLR is enabled, we have to take care of the address from /proc/kallsyms each time we reboot the machine. In order to use the address from /boot/System.map, make sure that KASLR is disabled. You can add the nokaslr for disabling KASLR in next booting time:
$ grep GRUB_CMDLINE_LINUX_DEFAULT /etc/default/grub
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash"
$ sudo perl -i -pe 'm/quiet/ and s//quiet nokaslr/' /etc/default/grub
$ grep quiet /etc/default/grub
GRUB_CMDLINE_LINUX_DEFAULT="quiet nokaslr splash"
$ sudo update-grub
欲了解更多信息,请查看以下内容:
[Unexporting the system call table
Cook: Security things in Linux v5.3
Control-flow integrity for the kernel
Unexporting kallsyms_lookup_name()
Kernel Probes (Kprobes)
Kernel address space layout randomization
这里的源代码就是这样一个内核模块的例子。我们希望 "监视 "某个用户,并在该用户打开文件时发送pr_info()消息。为此,我们用自己的函数our_sys_openat来代替打开文件的系统调用。这个函数检查当前进程的uid(用户id),如果等于我们监视的uid,它就调用pr_info()来显示要打开的文件名。然后,无论哪种方式,它都会调用原始的openat()函数,并使用相同的参数,来实际打开文件。
init_module函数替换了sys_call_table中的相应位置,并在一个变量中保留了原来的指针。cleanup_module函数使用该变量将一切恢复正常。这种方法很危险,因为两个内核模块有可能改变同一个系统调用。设想我们有两个内核模块,A和B,A的openat系统调用是A_openat,B的是B_openat。现在,当A被插入到内核中时,系统调用被替换为A_openat,它将调用原来的sys_openat。接下来,B被插入到内核中,用B_openat替换系统调用,完成后它将调用它认为是原始的系统调用A_openat。
现在,如果先删除B,一切都会好起来–它将简单地恢复系统调用A_openat,调用原来的调用。但是,如果先删除A,然后再删除B,系统就会崩溃。删除A会将系统调用恢复到原来的sys_openat,将B从循环中删除。然后,当B被移除时,系统会将系统调用恢复到它认为是原始的A_openat,而A_openat已经不在内存中了。乍一看,我们似乎可以通过检查系统调用是否等于我们的open函数来解决这个特殊的问题,如果是,就完全不改变系统调用(这样B在被移除时就不会改变系统调用),但是这会导致一个更糟糕的问题。当A被移除时,它看到系统调用被改成了B_openat,因此它不再指向A_openat,所以它不会在从内存中移除之前将其恢复到sys_openat。不幸的是,B_openat仍然会试图调用已经不存在的A_openat,因此即使不删除B,系统也会崩溃。
请注意,所有相关的问题使得系统调用窃取在生产使用中不可行。为了防止人们做潜在的有害事情,sys_call_table不再被导出。这意味着,如果你想做一些比这个例子更多的事情,你必须修补你当前的内核,以便导出sys_call_table。
/*
* syscall.c
*
* System call "stealing" sample.
*
* Disables page protection at a processor level by changing the 16th bit
* in the cr0 register (could be Intel specific).
*
* Based on example by Peter Jay Salzman and
* https://bbs.archlinux.org/viewtopic.php?id=139406
*/
#include <linux/delay.h>
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/moduleparam.h> /* which will have params */
#include <linux/unistd.h> /* The list of system calls */
#include <linux/cred.h> /* For current_uid() */
#include <linux/uidgid.h> /* For __kuid_val() */
#include <linux/version.h>
/* For the current (process) structure, we need this to know who the
* current user is.
*/
#include <linux/sched.h>
#include <linux/uaccess.h>
/* The way we access "sys_call_table" varies as kernel internal changes.
* - Prior to v5.4 : manual symbol lookup
* - v5.5 to v5.6 : use kallsyms_lookup_name()
* - v5.7+ : Kprobes or specific kernel module parameter
*/
/* The in-kernel calls to the ksys_close() syscall were removed in Linux v5.11+.
*/
#if (LINUX_VERSION_CODE < KERNEL_VERSION(5, 7, 0))
#if LINUX_VERSION_CODE <= KERNEL_VERSION(5, 4, 0)
#define HAVE_KSYS_CLOSE 1
#include <linux/syscalls.h> /* For ksys_close() */
#else
#include <linux/kallsyms.h> /* For kallsyms_lookup_name */
#endif
#else
#if defined(CONFIG_KPROBES)
#define HAVE_KPROBES 1
#include <linux/kprobes.h>
#else
#define HAVE_PARAM 1
#include <linux/kallsyms.h> /* For sprint_symbol */
/* The address of the sys_call_table, which can be obtained with looking up
* "/boot/System.map" or "/proc/kallsyms". When the kernel version is v5.7+,
* without CONFIG_KPROBES, you can input the parameter or the module will look
* up all the memory.
*/
static unsigned long sym = 0;
module_param(sym, ulong, 0644);
#endif /* CONFIG_KPROBES */
#endif /* Version < v5.7 */
static unsigned long **sys_call_table;
/* UID we want to spy on - will be filled from the command line. */
static uid_t uid = -1;
module_param(uid, int, 0644);
/* A pointer to the original system call. The reason we keep this, rather
* than call the original function (sys_openat), is because somebody else
* might have replaced the system call before us. Note that this is not
* 100% safe, because if another module replaced sys_openat before us,
* then when we are inserted, we will call the function in that module -
* and it might be removed before we are.
*
* Another reason for this is that we can not get sys_openat.
* It is a static variable, so it is not exported.
*/
#ifdef CONFIG_ARCH_HAS_SYSCALL_WRAPPER
static asmlinkage long (*original_call)(const struct pt_regs *);
#else
static asmlinkage long (*original_call)(int, const char __user *, int, umode_t);
#endif
/* The function we will replace sys_openat (the function called when you
* call the open system call) with. To find the exact prototype, with
* the number and type of arguments, we find the original function first
* (it is at fs/open.c).
*
* In theory, this means that we are tied to the current version of the
* kernel. In practice, the system calls almost never change (it would
* wreck havoc and require programs to be recompiled, since the system
* calls are the interface between the kernel and the processes).
*/
#ifdef CONFIG_ARCH_HAS_SYSCALL_WRAPPER
static asmlinkage long our_sys_openat(const struct pt_regs *regs)
#else
static asmlinkage long our_sys_openat(int dfd, const char __user *filename,
int flags, umode_t mode)
#endif
{
int i = 0;
char ch;
if (__kuid_val(current_uid()) != uid)
goto orig_call;
/* Report the file, if relevant */
pr_info("Opened file by %d: ", uid);
do {
#ifdef CONFIG_ARCH_HAS_SYSCALL_WRAPPER
get_user(ch, (char __user *)regs->si + i);
#else
get_user(ch, (char __user *)filename + i);
#endif
i++;
pr_info("%c", ch);
} while (ch != 0);
pr_info("\n");
orig_call:
/* Call the original sys_openat - otherwise, we lose the ability to
* open files.
*/
#ifdef CONFIG_ARCH_HAS_SYSCALL_WRAPPER
return original_call(regs);
#else
return original_call(dfd, filename, flags, mode);
#endif
}
static unsigned long **acquire_sys_call_table(void)
{
#ifdef HAVE_KSYS_CLOSE
unsigned long int offset = PAGE_OFFSET;
unsigned long **sct;
while (offset < ULLONG_MAX) {
sct = (unsigned long **)offset;
if (sct[__NR_close] == (unsigned long *)ksys_close)
return sct;
offset += sizeof(void *);
}
return NULL;
#endif
#ifdef HAVE_PARAM
const char sct_name[15] = "sys_call_table";
char symbol[40] = { 0 };
if (sym == 0) {
pr_alert("For Linux v5.7+, Kprobes is the preferable way to get "
"symbol.\n");
pr_info("If Kprobes is absent, you have to specify the address of "
"sys_call_table symbol\n");
pr_info("by /boot/System.map or /proc/kallsyms, which contains all the "
"symbol addresses, into sym parameter.\n");
return NULL;
}
sprint_symbol(symbol, sym);
if (!strncmp(sct_name, symbol, sizeof(sct_name) - 1))
return (unsigned long **)sym;
return NULL;
#endif
#ifdef HAVE_KPROBES
unsigned long (*kallsyms_lookup_name)(const char *name);
struct kprobe kp = {
.symbol_name = "kallsyms_lookup_name",
};
if (register_kprobe(&kp) < 0)
return NULL;
kallsyms_lookup_name = (unsigned long (*)(const char *name))kp.addr;
unregister_kprobe(&kp);
#endif
return (unsigned long **)kallsyms_lookup_name("sys_call_table");
}
#if LINUX_VERSION_CODE >= KERNEL_VERSION(5, 3, 0)
static inline void __write_cr0(unsigned long cr0)
{
asm volatile("mov %0,%%cr0" : "+r"(cr0) : : "memory");
}
#else
#define __write_cr0 write_cr0
#endif
static void enable_write_protection(void)
{
unsigned long cr0 = read_cr0();
set_bit(16, &cr0);
__write_cr0(cr0);
}
static void disable_write_protection(void)
{
unsigned long cr0 = read_cr0();
clear_bit(16, &cr0);
__write_cr0(cr0);
}
static int __init syscall_start(void)
{
if (!(sys_call_table = acquire_sys_call_table()))
return -1;
disable_write_protection();
/* keep track of the original open function */
original_call = (void *)sys_call_table[__NR_openat];
/* use our openat function instead */
sys_call_table[__NR_openat] = (unsigned long *)our_sys_openat;
enable_write_protection();
pr_info("Spying on UID:%d\n", uid);
return 0;
}
static void __exit syscall_end(void)
{
if (!sys_call_table)
return;
/* Return the system call back to normal */
if (sys_call_table[__NR_openat] != (unsigned long *)our_sys_openat) {
pr_alert("Somebody else also played with the ");
pr_alert("open system call\n");
pr_alert("The system may be left in ");
pr_alert("an unstable state.\n");
}
disable_write_protection();
sys_call_table[__NR_openat] = (unsigned long *)original_call;
enable_write_protection();
msleep(2000);
}
module_init(syscall_start);
module_exit(syscall_end);
MODULE_LICENSE("GPL");