说明:
系统:centos9 stream
K8S版本:V1.25.11(不要装最新的,后续的可视化界面安装的是个坑,基本上不支持,时间:2023年7月14日)
Docker版本:20.10.16 (不要随便安装版本,后面我会说明,怎么看和K8S之间的版本之间的关系)
一、基础设置
1.1 安装centos9 stream系统
比较简单,省略
配置:CPU :2核, 内存:2GB/台
数量:3台
| hostname | ip | 角色 |
| docker1.acthat.com | 10.211.55.16 | master |
| docker2.acthat.com | 10.211.55.17 | node |
| docker3.acthat.com | 10.211.55.18 | node |
1.2 修改yum源为阿里yum源
参考:CentOS Stream 9配置阿里yum源_centos stream 源_彭于晏Yan的博客-CSDN博客
1.3 基础设置
(1)时间同步[三台机器执行]
yum install chrony -y
systemctl start chronyd
systemctl enable chronyd
chronyc sources
(2)关闭防火墙[三台机器执行]
systemctl stop firewalld
systemctl disable firewalld(3)关闭 swap[三台机器执行]
# 临时关闭;关闭swap主要是为了性能考虑
swapoff -a
# 可以通过这个命令查看swap是否关闭了
free
# 永久关闭 【推荐】
sed -ri 's/.*swap.*/#&/' /etc/fstab
(4)禁用 SELinux[三台机器执行]
# 临时关闭
setenforce 0
# 永久禁用【推荐】
sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config二、安装Docker
2.1 安装docker [三台机器执行]
docker安装步骤参考:https://docs.docker.com/engine/install/centos/
docker选择版本,先去看看k8s支持的版本,比如,我们装的1.25.11,可以去下面这个地址:https://github.com/kubernetes/kubernetes/releases/tag/v1.25.11
点击CHANGELOG,全局查找docker,可以看到下面这句话
github.com/docker/docker: v20.10.12+incompatible → v20.10.17+incompatible
我们就选低于v20.10.17,高于v20.10.12的就行,低于 v20.10.12的行吗?行!原则不要太低,不要太高,所以选择了v20.10.16版本
yum install -y yum-utils
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 找到版本号3:20.10.16-3.el9
yum list docker-ce --showduplicates | sort -r
sudo yum install docker-ce-20.10.16-3.el9 docker-ce-cli-20.10.16-3.el9 containerd.io
systemctl start docker
systemctl enable docker2.2 设置配置文件 [三台机器执行]
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://xxxxxxx.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
registry-mirrors:需要改成自己的阿里源或者其他源
exec-opts:可以后面设置,未来方便,现在就设置了吧
三、安装K8S
3.1 设置K8S yum源 [三台机器执行]
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF3.2 配置 containerd cgroup 驱动程序 systemd [三台机器执行]
containerd config default > /etc/containerd/config.toml
grep sandbox_image /etc/containerd/config.toml
sed -i 's#registry.k8s.io/pause#registry.aliyuncs.com/google_containers/pause#g' /etc/containerd/config.toml
grep sandbox_image /etc/containerd/config.toml
#kubernets 自v1.24.0 后,就不再使用 docker.shim,替换采用 containerd 作为容器运行时端点。因此需要安装 containerd(在 docker 的基础下安装),上面安装 docker 的时候就自动安装了 containerd 了。这里的 docker 只是作为客户端而已。容器引擎还是 containerd。
sed -i 's#SystemdCgroup = false#SystemdCgroup = true#g' /etc/containerd/config.toml
# 应用所有更改后,重新启动containerd
systemctl restart containerd3.3 开始安装 kubeadm,kubelet 和 kubectl [master机器执行]
yum install -y kubelet-1.25.11 kubeadm-1.25.11 kubectl-1.25.11 --disableexcludes=kubernetes
# disableexcludes=kubernetes:禁掉除了这个kubernetes之外的别的仓库
# 设置为开机自启并现在立刻启动服务 --now:立刻启动服务
systemctl enable --now kubelet
# 查看状态,这里需要等待一段时间再查看服务状态,启动会有点慢
systemctl status kubelet
# 查看版本!很重要!
kubectl version
yum info kubeadm3.4 pull kubeadm需要的镜像[master机器执行]
执行:
kubeadm config images list --kubernetes-version=v1.25.11结果如下:
registry.k8s.io/kube-apiserver:v1.25.11
registry.k8s.io/kube-controller-manager:v1.25.11
registry.k8s.io/kube-scheduler:v1.25.11
registry.k8s.io/kube-proxy:v1.25.11
registry.k8s.io/pause:3.8
registry.k8s.io/etcd:3.5.6-0
registry.k8s.io/coredns/coredns:v1.9.3先把这些镜像下载下来,不过开头先变一变,会快很多,执行:
docker pull registry.aliyuncs.com/google_containers/kube-apiserver:v1.25.11
docker pull registry.aliyuncs.com/google_containers/kube-controller-manager:v1.25.11
docker pull registry.aliyuncs.com/google_containers/kube-scheduler:v1.25.11
docker pull registry.aliyuncs.com/google_containers/kube-proxy:v1.25.11
docker pull registry.aliyuncs.com/google_containers/pause:3.8
docker pull registry.aliyuncs.com/google_containers/etcd:3.5.6-0
docker pull registry.aliyuncs.com/google_containers/coredns/coredns:v1.9.33.5 init [master机器执行]
【执行方式一】:个人失败了!!
kubeadm init \
--apiserver-advertise-address=10.211.55.16 \
--image-repository registry.aliyuncs.com/google_containers \
--control-plane-endpoint=cluster-endpoint \
--kubernetes-version v1.25.11 \
--service-cidr=10.1.0.0/16 \
--pod-network-cidr=10.244.0.0/16 \
--v=5
# –image-repository string: 这个用于指定从什么位置来拉取镜像(1.13版本才有的),默认值是k8s.gcr.io,我们将其指定为国内镜像地址:registry.aliyuncs.com/google_containers
# –kubernetes-version string: 指定kubenets版本号,默认值是stable-1,会导致从https://dl.k8s.io/release/stable-1.txt下载最新的版本号,我们可以将其指定为固定版本(v1.22.1)来跳过网络请求。
# –apiserver-advertise-address 指明用 Master 的哪个 interface 与 Cluster 的其他节点通信。如果 Master 有多个 interface,建议明确指定,如果不指定,kubeadm 会自动选择有默认网关的 interface。这里的ip为master节点ip,记得更换。
# –pod-network-cidr 指定 Pod 网络的范围。Kubernetes 支持多种网络方案,而且不同网络方案对 –pod-network-cidr有自己的要求,这里设置为10.244.0.0/16 是因为我们将使用 flannel 网络方案,必须设置成这个 CIDR。
# --control-plane-endpoint cluster-endpoint 是映射到该 IP 的自定义 DNS 名称,这里配置hosts映射:10.211.55.13 cluster-endpoint。 这将允许你将 --control-plane-endpoint=cluster-endpoint 传递给 kubeadm init,并将相同的 DNS 名称传递给 kubeadm join。 稍后你可以修改 cluster-endpoint 以指向高可用性方案中的负载均衡器的地址。【执行方式二】:成功!
kubeadm config print init-defaults > kubeadm-init.yaml #修改kubeadm-init.yaml
vim kubeadm-init.yaml 修改结果如下,注意查看修改的地方
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 10.211.55.16 # 修改地方1
bindPort: 6443
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
imagePullPolicy: IfNotPresent
name: docker1.acthat.com
taints: null
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers # 修改地方2
kind: ClusterConfiguration
kubernetesVersion: v1.25.11 # 修改地方3
networking:
dnsDomain: cluster.local
podSubnet: 10.244.0.0/16 # 修改地方4
serviceSubnet: 10.96.0.0/12
scheduler: {}执行:
kubeadm init --config kubeadm-init.yaml如果执行失败了怎么办?
kubeadm reset
rm -fr ~/.kube/ /etc/kubernetes/* /var/lib/etcd/*执行后,重新进行(init)!!!
怎么查看日志?下面三个方式选择一个,我个人更多的是看tail -f /var/log/messages
#查看日志
journalctl -xeu kubelet
systemctl status kubelet
tail -f /var/log/messages查看节点需要全部running状态
#查看节点需要全部running状态
kubectl get pods -A【错误1】:
"Container runtime network not ready" networkReady="NetworkReady=false reason:NetworkPluginNotReady message:Network plugin returns error: cni plugin not initialized"
【解决1】:
docker pull quay.io/coreos/flannel:v0.14.0
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
# 修改kube-flannel.yml中的镜像仓库地址为国内源
sed -i 's/quay.io/quay-mirror.qiniu.com/g' kube-flannel.yml
# 安装网络插件
kubectl apply -f kube-flannel.yml
【错误2】:
"Error syncing pod, skipping" err="failed to \"KillPodSandbox\" for \"d4fdd149-02b3-4b73-aaec-e6a023044094\" with KillPodSandboxError: \"rpc error: code = Unknown desc = failed to destroy network for sandbox \\\"6c80e411993881859f78e05a9836845bcdb5ead4289f8433059b98f42c58b1e9\\\": plugin type=\\\"flannel\\\" name=\\\"cbr0\\\" failed (delete): failed to find plugin \\\"flannel\\\" in path [/opt/cni/bin]\"" pod="kube-system/coredns-c676cc86f-nzx62" podUID=d4fdd149-02b3-4b73-aaec-e6a023044094
【解决2】:
wget https://github.com/containernetworking/plugins/releases/download/v0.8.6/cni-plugins-linux-arm64-v0.8.6.tgz
mkdir temp
tar -zxvf cni-plugins-linux-amd64-v0.8.6.tgz -C temp/
cd temp/
cp flannel /opt/cni/bin【错误3】:
633c7a03777e1accf014bf530d165a9401abb4784bdc1\": plugin type=\"flannel\" name=\"cbr0\" failed (add): open /run/flannel/subnet.env: no such file or directory" pod="kube-system/coredns-c676cc86f-krvf5"
Jul 14 00:59:14 docker1 kubelet[10713]: E0714 00:59:14.530446 10713 pod_workers.go:965] "Error syncing pod, skipping" err="failed to \"CreatePodSandbox\" for \"coredns-c676cc86f-krvf5_kube-system(54228d84-9026-46ed-8ed9-3fbaf1f2b504)\" with CreatePodSandboxError: \"Failed to create sandbox for pod \\\"coredns-c676cc86f-krvf5_kube-system(54228d84-9026-46ed-8ed9-3fbaf1f2b504)\\\": rpc error: code = Unknown desc = failed to setup network for sandbox \\\"e1288a46239e8247ff2633c7a03777e1accf014bf530d165a9401abb4784bdc1\\\": plugin type=\\\"flannel\\\" name=\\\"cbr0\\\" failed (add): open /run/flannel/subnet.env: no such file or directory\"" pod="kube-system/coredns-c676cc86f-krvf5" podUID=54228d84-9026-46ed-8ed9-3fbaf1f2b504
【处理3】:
mkdir /run/flannel/
cat <<EOF> /run/flannel/subnet.env
FLANNEL_NETWORK=10.244.0.0/16
FLANNEL_SUBNET=10.244.0.1/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=true
EOF注意: FLANNEL_NETWORK和FLANNEL_SUBNET和kubeadm-init.yaml中的networking保持一致
四、 node节点加入
4.1 安装kubeadm[node机器执行]:
yum install -y kubelet-1.25.11 kubeadm-1.25.11 kubectl-1.25.11 --disableexcludes=kubernetes
# disableexcludes=kubernetes:禁掉除了这个kubernetes之外的别的仓库
# 设置为开机自启并现在立刻启动服务 --now:立刻启动服务
systemctl enable --now kubelet
# 查看状态,这里需要等待一段时间再查看服务状态,启动会有点慢
systemctl status kubelet
# 查看版本
kubectl version
yum info kubeadm4.2 docker pull kubeadm需要的镜像[node机器执行]:
docker pull registry.aliyuncs.com/google_containers/kube-apiserver:v1.25.11
docker pull registry.aliyuncs.com/google_containers/kube-controller-manager:v1.25.11
docker pull registry.aliyuncs.com/google_containers/kube-scheduler:v1.25.11
docker pull registry.aliyuncs.com/google_containers/kube-proxy:v1.25.11
docker pull registry.aliyuncs.com/google_containers/pause:3.8
docker pull registry.aliyuncs.com/google_containers/etcd:3.5.6-0
docker pull registry.aliyuncs.com/google_containers/coredns/coredns:v1.9.34.3 修改cgroup [node机器执行]
vim /etc/sysconfig/kubelet
#内容如下
KUBELET_EXTRA_ARGS=--cgroup-driver=systemd查看docker是否已经更改systemd
[root@docker2 ~]# cat /etc/docker/daemon.json
{
"registry-mirrors": ["https://xxxxxxx.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"]
}
有设置exec-opts这个就行!!
4.4 TOKEN生成与传递
(1) 生成token和查看token [master机器执行]:
生成方式有好多种:
#方式1:(token会过期)
kubeadm token create
#方式2:(token会过期)
kubeadm token create --print-join-command
#方式3:(token不会过期)
kubeadm token create --ttl 0 --print-join-command
选择执行:
kubeadm token create --ttl 0 --print-join-command结果如下:
[root@docker1 ~]# kubeadm token create --ttl 0 --print-join-command
kubeadm join 10.211.55.13:6443 --token 2r62t4.et5jk6gre73latp1 --discovery-token-ca-cert-hash sha256:4cb085eb3bb208b91d6479f0f40e6e282ccefd345504fdede02dcaca3b171978 输出的就是node节点加入的命令,复制命令到node节点执行,不过在之前之前需要拷贝一个东西[master机器执行]:
scp /etc/kubernetes/admin.conf docker2.acthat.com:/etc/kubernetes/
scp /etc/kubernetes/admin.conf docker3.acthat.com:/etc/kubernetes/[node机器执行]
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bash_profile然后再执行命令[node机器执行]
kubeadm join 10.211.55.13:6443 --token 2r62t4.et5jk6gre73latp1 --discovery-token-ca-cert-hash sha256:4cb085eb3bb208b91d6479f0f40e6e282ccefd345504fdede02dcaca3b171978 (2)token查询[master机器执行]:
kubeadm token list【错误1】
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR CRI]: container runtime is not running: output: time="2023-07-11T12:56:17+08:00" level=fatal msg="validate service connection: CRI v1 runtime API is not implemented for endpoint \"unix:///var/run/containerd/containerd.sock\": rpc error: code = Unimplemented desc = unknown service runtime.v1.RuntimeService"
, error: exit status 1
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
【处理1】
#查看状态是否是active
systemctl status containerd
#修改文件
vim /etc/containerd/config.toml
#将disabled_plugins = ["cri"] 修改为 disabled_plugins = []
#重启容器运行时
systemctl restart containerd
#重置:
kubeadm reset
rm -fr ~/.kube/ /etc/kubernetes/* /var/lib/etcd/*【错误2】
W0711 13:05:51.112575 4777 loader.go:222] Config not found: /etc/kubernetes/admin.conf
【处理2】
原因:kubectl命令需要使用kubernetes-admin来运行,需要admin.conf文件;而admin.conf 文件是通过 “kubeadmin init” 命令在 /etc/kubernetes 中创建的,从节点没有该配置文件;因此需要将admin.conf复制到从节点
【master机器执行】
scp /etc/kubernetes/admin.conf docker2.acthat.com:/etc/kubernetes/#【node机器执行】
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bash_profile过几分钟就好了
五、清理node
【master机器执行】
kubectl drain docker3.acthat.com --delete-local-data --force --ignore-daemonsets
kubectl delete nodes docker3.acthat.com【node机器执行】
kubeadm reset
rm -fr ~/.kube/ /etc/kubernetes/* /var/lib/etcd/*六、使用kubernetes-dashboard
5.1 安装kubernetes-dashboard【master机器执行】
可以参考:https://gitcode.net/mirrors/kubernetes/dashboard 注意版本支持,我们安装的2.7.0
docker pull docker.io/kubernetesui/dashboard:v2.7.0
docker pull docker.io/kubernetesui/metrics-scraper:v1.0.8可能下载不下来,修改:删除阿里源,如下:
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://5cl47byb.mirror.aliyuncs.com"], # 这个删除
"exec-opts": ["native.cgroupdriver=systemd"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart dockerwget https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yaml
vim recommended.yaml----
spec:
type: NodePort #修改的地方
ports:
- port: 443
targetPort: 8443
nodePort: 30001 #修改的地方
type: NodePort
selector:
k8s-app: kubernetes-dashboard
----kubectl apply -f recommended.yaml1
kubectl get pods -n kubernetes-dashboard
kubectl get pods,svc -n kubernetes-dashboard【错误1】
无法访问
【处理1】
如果没法访问,将 type: ClusterIP 修改成 type: NodePort 即可:
kubectl -n kubernetes-dashboard edit service kubernetes-dashboard处理结果如下:443:31928/TCP,出现这个31928就好
[root@docker1 ~]# kubectl -n kubernetes-dashboard get service kubernetes-dashboard
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
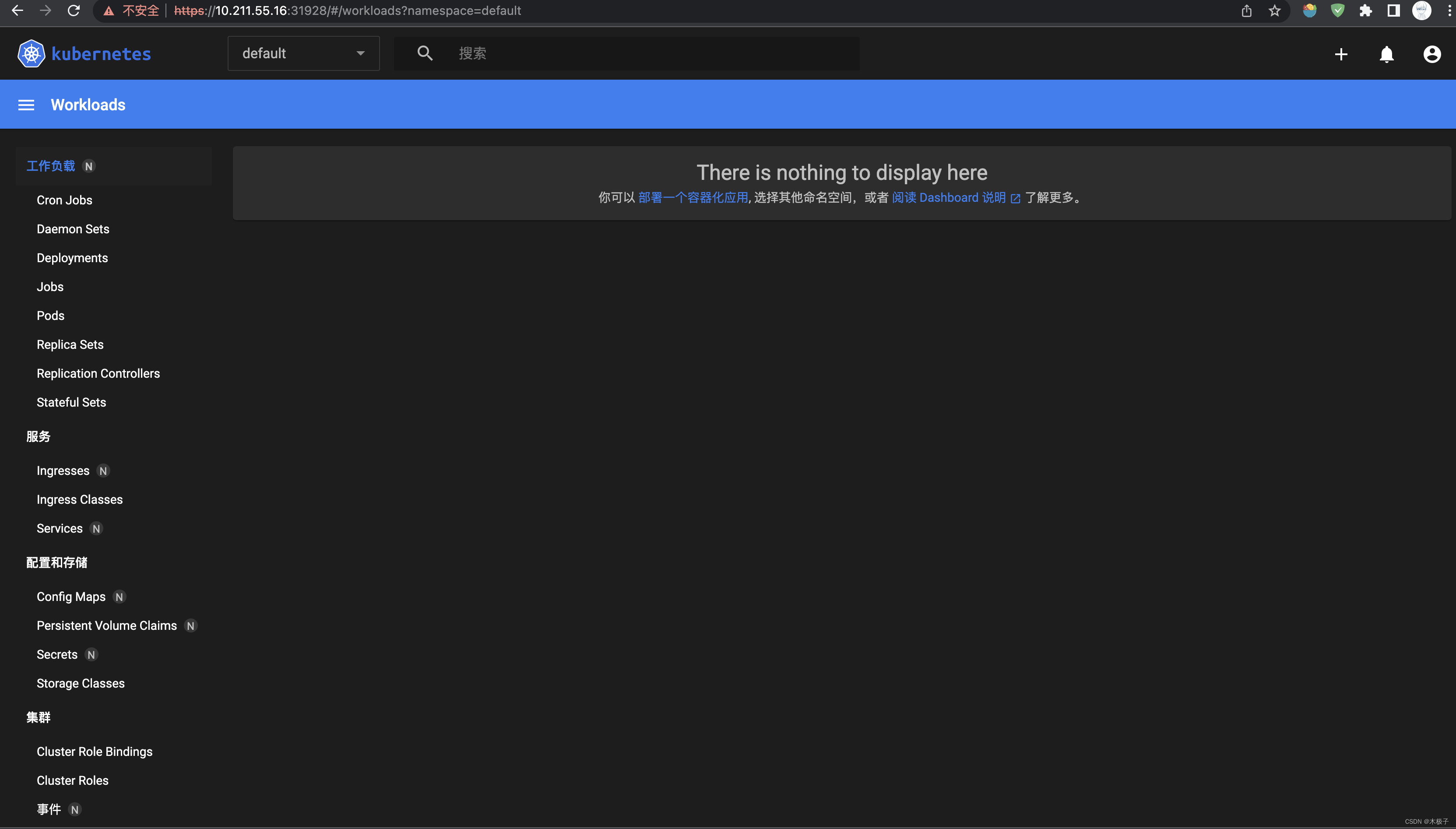
kubernetes-dashboard NodePort 10.104.185.134 <none> 443:31928/TCP 9m25s然后访问:https://10.211.55.16:31928/#/login,一定要https!
5.2 创建账号和token
(1)创建账号和角色
cat >ServiceAccount.yaml<<EOF
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard
EOF
kubectl apply -f ServiceAccount.yaml(2) 生成token
kubectl -n kubernetes-dashboard create token admin-user结果如下:
[root@docker1 ~]# kubectl -n kubernetes-dashboard create token admin-user
eyJhbGciOiJSUzI1NiIsImtpZCI6IjB0OXRUclA0NG1Va3VVYmNLQUNKNXk4eVpjdjA2aXpVTlhOUEFUQV9FcGMifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjLmNsdXN0ZXIubG9jYWwiXSwiZXhwIjoxNjg5MzE0NTkwLCJpYXQiOjE2ODkzMTA5OTAsImlzcyI6Imh0dHBzOi8va3ViZXJuZXRlcy5kZWZhdWx0LnN2Yy5jbHVzdGVyLmxvY2FsIiwia3ViZXJuZXRlcy5pbyI6eyJuYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsInNlcnZpY2VhY2NvdW50Ijp7Im5hbWUiOiJhZG1pbi11c2VyIiwidWlkIjoiMTIwNDQwNzUtOWI1YS00NGEzLTk0MWMtNDk0NDgyNjExYmVlIn19LCJuYmYiOjE2ODkzMTA5OTAsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDprdWJlcm5ldGVzLWRhc2hib2FyZDphZG1pbi11c2VyIn0.K-9iGAfJ28MIq7PinZkKymjf4WZ7zV9V7mrvxd0uYhTHi8blC6yOfVMIM6MHHLBSXeu6HB9YJc6wDkg67GV4demNumuoDbchZymhufevF6oVmJCiZle8wBjoVh9SW-zLTKaX0AUz_FefnCfF8mT5AUybtWmYOnQGpXoyATUc9GwiTWzGNf_1xb7IkR_3b0NBHvWrm9sjSqTHhhVrGV2wKzsMIUF-ebLwG005oQrz7OEZ-940LD76I9ySg2zMAhd4IWRlTR5Qw-YHtvaODDSzbqnu_ZF2N-HL1Y3z1dhellGicQULWollOenTGKLYkQMUEcH87_9wasYMftmpKcg0jw在https://10.211.55.16:31928/#/login页面输入token就好了!
5.3、 卸载kubernetes-dashboard【master机器执行】
# 查询pod
kubectl get pods --all-namespaces | grep "dashboard"
# 删除pod
kubectl delete deployment kubernetes-dashboard --namespace=kubernetes-dashboard
kubectl delete deployment dashboard-metrics-scraper --namespace=kubernetes-dashboard
# 查询service
kubectl get service -A
# 删除service
kubectl delete service kubernetes-dashboard --namespace=kubernetes-dashboard
kubectl delete service dashboard-metrics-scraper --namespace=kubernetes-dashboard
# 删除账户和密钥
kubectl delete sa kubernetes-dashboard --namespace=kubernetes-dashboard
kubectl delete secret kubernetes-dashboard-certs --namespace=kubernetes-dashboard
kubectl delete secret kubernetes-dashboard-key-holder --namespace=kubernetes-dashboard





![C++ 指向vector[0]的指针](https://img-blog.csdnimg.cn/e7c89b409da945fdbd4ddf171b43d796.png)