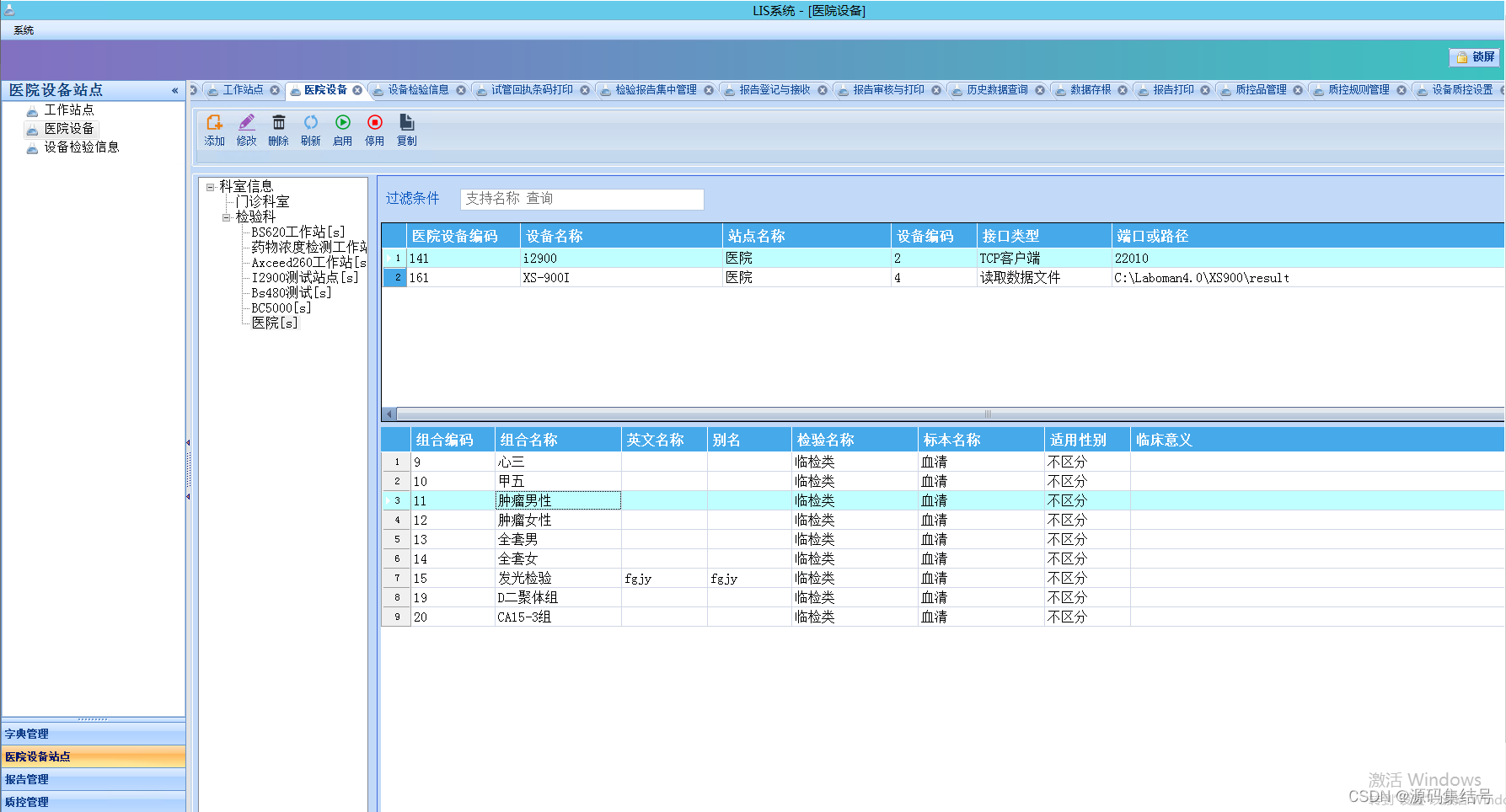
作者:Quentin Herreros, Thomas Veasey

在上一篇博文中,我们介绍了 Elastic Learned Sparse Encoder,这是一种经过训练可有效进行零样本文本检索的模型。 Elasticsearch® 还具有强大的词汇检索功能和丰富的工具来组合不同查询的结果。 在本博客中,我们介绍了混合检索的概念,并探讨了 Elasticsearch 中可用的两种具体实现。 特别是,我们探索如何通过使用倒数排名融合(Reciprocal Rank Fusion - RRF)和加权分数和将 Elastic 学习稀疏编码器(Learned Sparse Encoder)与 BM25 相结合来提高其性能。
我们还讨论了为探索一些一般性研究问题而进行的实验。 其中包括如何最好地参数化倒数排名融合以及如何校准分数的加权和。
混合检索
尽管现代训练管道产生了在零样本场景中具有良好性能的检索器模型,但众所周知,词汇检索器(例如 BM25)和语义检索器(例如 Elastic Learned Sparse Encoder)在某种程度上是互补的。 具体来说,如果假设检索到的相关文档比检索到的不相关文档出现更多匹配,那么结合检索方法的结果将提高相关性。
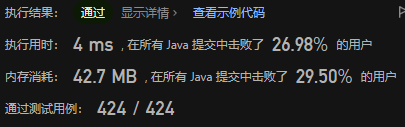
对于使用非常不同的检索机制的方法来说,这种假设是合理的,因为对于大多数查询和语料库来说,不相关的文档比相关文档多得多。 如果方法独立且统一地随机检索相关和不相关文档,这种不平衡意味着相关文档比不相关文档匹配的可能性更大。 我们进行了一些重叠测量 ,以检 Elastic Learned Sparse Encoder、BM25 和各种密集检索器之间的这一假设,如表 1 所示。这为使用所谓的混合搜索提供了一些基本原理。 接下来,我们研究混合搜索的两种具体实现。
倒数排名融合 - Reciprocal Rank Fusion
本文提出了倒数排名融合。 它易于使用,完全无人监督,甚至不需要分数校准。 它的工作原理是使用 BM25 和模型对文档进行排名,并根据两种方法的排名位置计算其分数。 文档按分数降序排序。 分数定义如下:
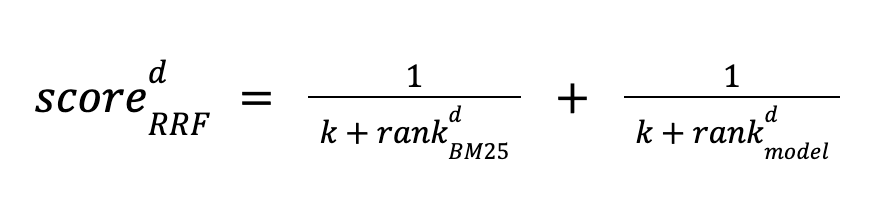
该方法使用常数 k 来调整低排名文档的重要性。 它应用于每种方法检索到的前 N 个文档集。 如果任一方法的该集中缺少文档,则该项设置为零。
介绍倒数排名融合的论文建议 k 值为 60,并且没有讨论要检索多少个文档 N。 显然,增加 N 会影响排名质量,而对于任一方法,recall@N 都会增加。 定性地讲,k 越大,排名较低的文档对最终顺序越重要。 然而,对于现代词汇语义混合检索来说,k 和 N 的最佳值是什么并不清楚。 此外,我们想了解结果对这些参数的选择有多敏感,以及最优值是否可以在数据集和模型之间推广。 这对于在零样本设置中对方法有信心非常重要。
为了探索这些问题,我们进行了网格搜索,以最大化各种模型的 BEIR 基准子集的加权平均值 NDCG@10。 在本实验中,我们使用 Elasticsearch 进行检索,通过单个文本字段和向量表示每个文档。 BM25 搜索是使用 match 查询和使用带有 script_score 查询的精确向量搜索的密集检索来执行的。

参考表2,我们看到对于 roberta-base-ance-firstp,k 和 N 的最佳值分别是 20 和 1000。 我们强调,对于大多数单独的数据集,相同的参数组合是最佳的。 我们对 distilbert-base-v3 和 minilm-l12-v3 进行了相同的网格搜索,每个模型都得出相同的结论。 还值得注意的是,最好和最差参数组合之间的差异仅为 5% 左右; 因此错误设置这些参数的惩罚相对较小。
我们还想看看是否可以使用倒数排名融合在零样本设置中提高 Elastic Learned Sparse Encoder 的性能。 BEIR 基准测试的结果如表 3 所示。

与单独的 Elastic Learned Sparse Encoder 相比,Reciprocal Rank Fusion 将平均 NDCG@10 提高了 1.4%,比单独的 BM25 提高了 18%。 此外,重要的是,对于所有测试数据集,结果都优于或类似于单独的 BM25。 无需模型调整、训练数据集或特定校准即可实现改进的排名。 唯一的缺点是,目前,由于两个查询在 Elasticsearch 中顺序执行,查询延迟会增加。 BM25 检索通常比语义检索更快,这一事实缓解了这一问题。
我们的研究结果表明,倒数排名融合可以安全地用作有效的 “即插即用” 策略。 此外,值得回顾一下使用 BM25、Elastic Learned Sparse Encoder 以及它们在你自己的数据上的排名融合获得的结果的质量。 如果要在 BEIR 套件中的每个单独数据集上选择性能最佳的方法,则平均 NDCG@10 的增长分别比 Elastic Learned Sparse Encoder 和 BM25 单独提高 3% 和 20%。
作为这项工作的一部分,我们还执行了一些简单的查询分类来区分关键字和自然问题搜索。 这是为了尝试了解导致给定方法表现最佳的机制。 到目前为止,我们对此还没有明确的解释,并计划进一步探索。 然而,我们确实发现,当两种方法具有相似的整体精度时,混合搜索表现强劲。
最后,倒数排名融合可以与两种以上的方法一起使用,或者可以用于组合来自不同领域的排名。 到目前为止,我们还没有探索过这个方向。
分数加权总和
Elasticsearch 支持的另一种混合检索方法是使用线性函数组合 BM25 分数和模型分数。 本文研究了这种方法,结果表明,在校准良好的情况下,它比倒数秩融合更有效。 我们通过分数的凸线性组合探索混合搜索,定义如下:
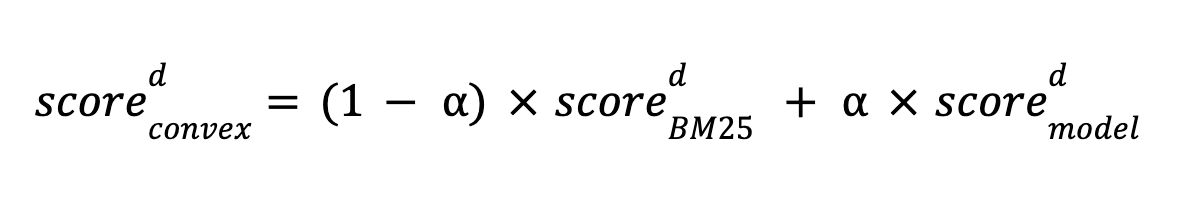
其中 α 是模型得分权重,介于 0 和 1 之间。
线性组合的理想校准并不简单,因为它需要类似于用于微调模型的注释。 给定一组查询和关联的相关文档,我们可以使用任何优化方法来找到检索这些文档的最佳组合。 在我们的实验中,我们使用 BEIR 数据集和贝叶斯优化来寻找最佳组合,针对 NDCG@10 进行优化。 理论上,分数尺度的比率可以纳入到α的学习值中。 然而,在接下来的实验中,我们使用最小-最大归一化对每个数据集的 BM25 分数和 Elastic Learned Sparse Encoder 分数进行归一化,计算每个数据集上一些代表性查询的前 1,000 个分数的最小值和最大值。 我们希望通过标准化分数获得最佳的转会价值(value of transfer)。 我们没有找到这方面的证据,但它更加一致,因此归一化确实可能提高校准的稳健性。
获取注释的成本很高,因此了解需要收集多少数据才能有信心击败倒数排名融合 (RRF)。 图 1 显示了 BM25 和 Elastic Learned Sparse Encoder 分数线性组合的 NDCG@10 作为 ArguAna 数据集带注释查询数量的函数。 作为参考,还显示了 BM25、Elastic Learned Sparse Encoder 和 RRF NDCG@10。 这种曲线在数据集中很常见。 在我们的实验中,我们发现大约 40 个带注释的查询可以超越 RRF,尽管不同数据集的确切阈值略有不同。

我们还观察到,不同数据集(见图 2)以及不同检索模型的最佳权重差异很大。 即使在标准化分数之后也是如此。 人们可能会想到这一点,因为最佳组合将取决于各个方法在给定数据集上的执行情况。
为了探索零样本参数化的可能性,我们尝试为基准集中的所有数据集选择单个权重 α。 尽管我们使用相同的监督方法来做到这一点,但这次选择权重来优化全套数据集的平均 NDCG@10,我们认为数据集之间存在足够的变化,我们的发现可能代表零样本表现。
总之,这种方法比 RRF 产生更好的平均 NDCG@10。 然而,我们还发现结果不如 RRF 一致,并且我们强调最佳权重是特定于模型的。 因此,即使针对特定模型进行了校准,我们也不太有信心将该方法转移到新设置。 我们认为,线性组合并不是 “即插即用” 的方法。 相反,我们认为仔细评估组合在你自己的数据集上的性能以确定最佳设置非常重要。 然而,正如我们将在下面看到的,如果校准得当,它会产生非常好的结果。

标准化对于比较不同数据集和模型之间的分数至关重要,因为如果没有标准化,分数可能会有很大差异。 这并不总是那么容易做到,特别是对于 Okapi BM25,在进行查询之前分数范围是未知的。 密集模型分数更容易标准化,因为它们的矢量可以标准化。 然而,值得注意的是,一些密集模型是在没有标准化的情况下进行训练的,并且使用点积(dot products)可能会表现得更好。
Elastic Learned Sparse Encoder 经过训练可以复制跨编码器得分范围。 我们通常会看到它产生 0 到 20 范围内的分数,尽管不能保证这一点。 一般来说,查询历史记录及其前 N 个文档分数可用于近似分布并使用最小和最大估计值对任何评分函数进行标准化。 我们注意到,非线性归一化可能会导致线性组合的改进,例如,如果存在分数异常值,尽管我们没有对此进行测试。
至于倒数排序融合,我们希望了解 BM25 和 Elastic Learned Sparse Encoder 线性组合的准确性 —— 不过,这一次是在最好的情况下。 在这种情况下,我们对每个数据集优化一个权重 α,以使用线性组合获得理想的 NDCG@10。 我们使用 300 个查询进行校准 —— 我们发现这足以估计所有数据集的最佳权重。 在生产中,这种情况实际上很难实现,因为它需要精确的最小 - 最大归一化和具有代表性的注释数据集来调整权重。 如果文档和查询发生显着变化,也需要刷新。 尽管如此,限制最佳情况性能仍然有助于了解这种努力是否值得。 结果如表 4 所示。与单独的 Elastic Learned Sparse Encoder 相比,该方法的平均 NDCG@10 提高了 6%,比单独的 BM25 提高了 24%。

结论
我们表明可以结合不同的检索方法来提高其性能,特别是词汇和语义检索相互补充。 我们探索的一种方法是倒数排序融合。 这是一种简单的方法,通常可以产生良好的结果,而不需要任何注释或分数分布的先验知识。 此外,我们发现其性能特征在模型和数据集上都非常稳定,因此我们相信我们观察到的结果将推广到其他数据集。
另一种方法是分数加权总和,这种方法更难设置,但在我们的实验中,通过正确的设置产生了非常好的排名。 要使用这种方法,应该对分数进行归一化,这对于 BM25 来说需要典型查询的分数分布,此外还应该使用一些带注释的数据来训练方法权重。
在本系列的最后一篇计划博客中,我们将介绍在我们向 text_expansion 功能迈向 GA 的过程中,我们围绕推理和索引性能所做的工作。
原文:Improving information retrieval in the Elastic Stack: Hybrid retrieval | Elastic Blog

![C++ 指向vector[0]的指针](https://img-blog.csdnimg.cn/e7c89b409da945fdbd4ddf171b43d796.png)