Zomato Complete EDA and LSTM model
背景
分析Zomato数据集的基本思想是为了公平地了解影响在班加罗尔不同地方建立不同类型餐厅的因素,每个餐厅的总评级,班加罗尔是这样一个城市,拥有超过12,000家餐厅,餐厅供应来自世界各地的菜肴。每天都有新的餐馆开业,这个行业还没有饱和,需求也在与日俱增。然而,尽管需求不断增加,新餐馆却很难与老牌餐馆竞争。大多数餐厅都供应同样的食物。班加罗尔是印度的IT之都。这里的大多数人主要依靠餐馆的食物,因为他们没有时间自己做饭。由于对餐馆的需求如此巨大,因此研究一个地方的人口统计学就变得很重要。
在一个地方哪种食物更受欢迎?
整个地方的人都喜欢吃素吗?如果是,那么该地区是否有特定的人群居住?耆那教徒、马尔瓦尔人、古吉拉特邦人,他们大多是素食主义者。这些类型的分析可以通过数据来完成,通过研究因素,如:
- 餐厅的位置•食品的大致价格主题餐厅与否
- 在那个城市的哪个地方提供这种菜系的餐馆最多?那些努力得到附近最好的菜系
- 的人的需求?是否是一个以自己的食物而闻名的特定社区?
导入模块
import numpy as np
import pandas as pd
import os
import seaborn as sns
print(os.listdir("../input"))
import matplotlib.pyplot as plt
plt.style.use('ggplot')
import plotly.offline as py
import plotly.graph_objs as go
from plotly.offline import init_notebook_mode
init_notebook_mode(connected=False)
from wordcloud import WordCloud
from geopy.geocoders import Nominatim
from folium.plugins import HeatMap
import folium
from tqdm import tqdm
import re
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers import Dense, Embedding, LSTM, SpatialDropout1D
from sklearn.model_selection import train_test_split
from nltk import word_tokenize
from sklearn.feature_extraction.text import TfidfVectorizer
import gensim
from collections import Counter
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
import matplotlib.colors as mcolors
from sklearn.manifold import TSNE
from gensim.models import word2vec
import nltk
# Any results you write to the current directory are saved as output.
加载数据
df=pd.read_csv("../input/zomato.csv")
数据集格式
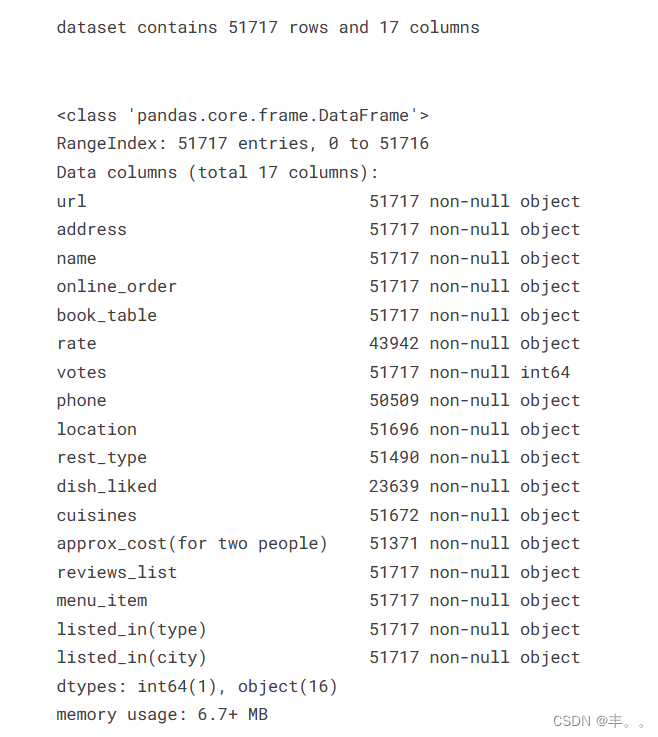
数据集描述
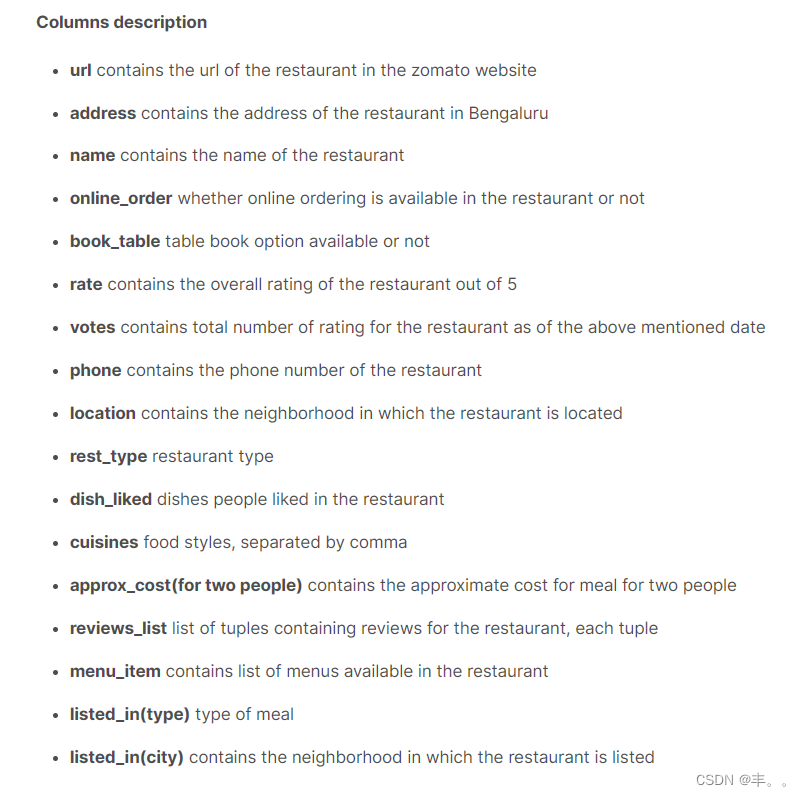
列描述
Url包含zomato网站中餐厅的Url
address包含班加罗尔餐厅的地址
Name包含餐厅的名称
Online_order餐厅是否提供在线点餐
Book_table表图书选项是否可用
Rate包含餐厅的整体评分,满分为5分
Votes包含截至上述日期该餐厅的评分总数
Phone包含餐厅的电话号码
Location包含餐厅所在的社区
Rest_type餐厅类型
餐馆里人们喜欢的菜
菜系的食物风格,用逗号分隔
Approx_cost(对于两人)包含两人用餐的大致费用
Reviews_list包含餐厅评论的元组列表,每个元组
Menu_item包含餐厅中可用的菜单列表
listd_in (type)餐的类型
listd_in (city)包含餐馆所在的社区
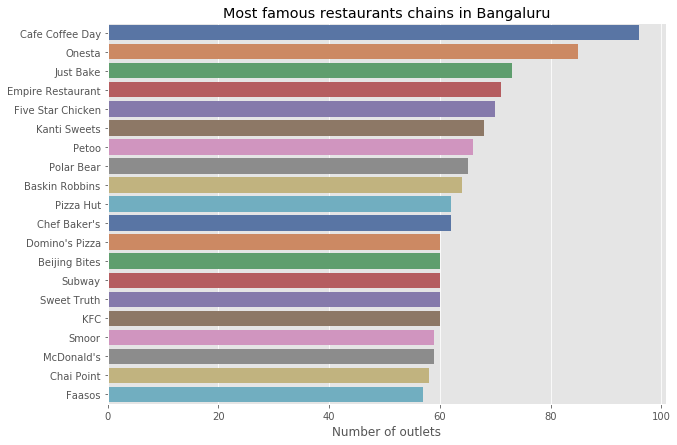
正如你所看到的Cafe coffee day,Onesta,Just Bake在班加罗尔及其周边拥有最多的门店。
这是相当有趣的,我们将在后面逐一检查。
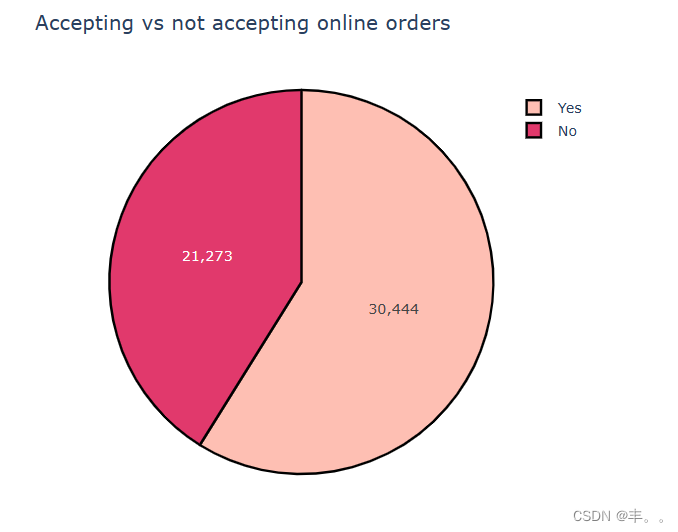
30444
21273
接受与不接受网上订单
正如明确指出的那样,班加罗尔近60%的餐馆接受网上订餐。
近40%的餐厅不接受网上订餐。
这可能是因为这些餐厅无法支付给zomoto网上订单的佣金。如果Zomato想要增加在线服务客户的餐厅数量,他们可能会考虑给他们更多的好处。
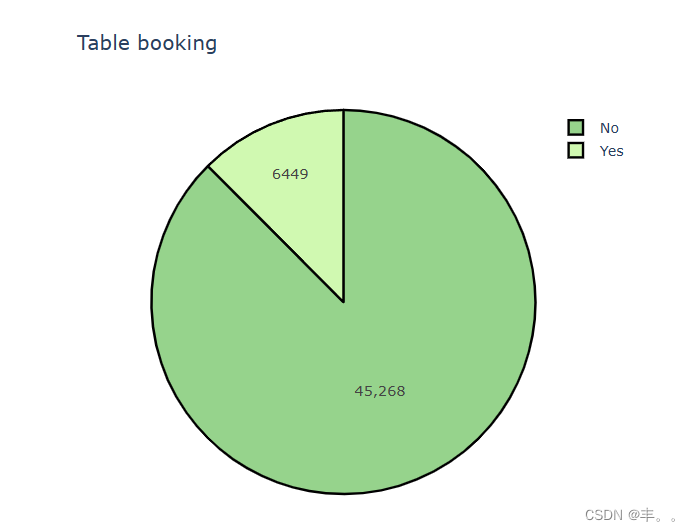
在班加罗尔,几乎90%的餐馆不提供订座服务。
在印度,一般的餐厅都找不到订座设施,通常只有五星级餐厅才提供订座服务。
我们将进一步检查。
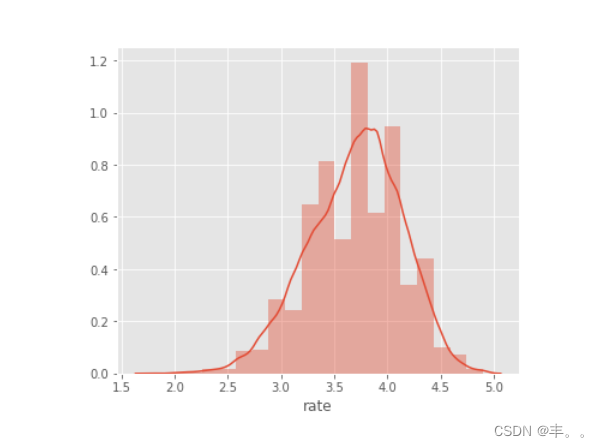
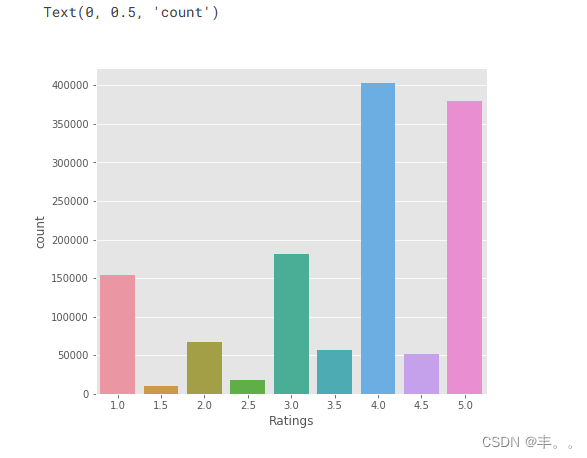
几乎50%以上的餐厅的评级在3到4之间。
评分超过4.5的餐厅非常罕见。
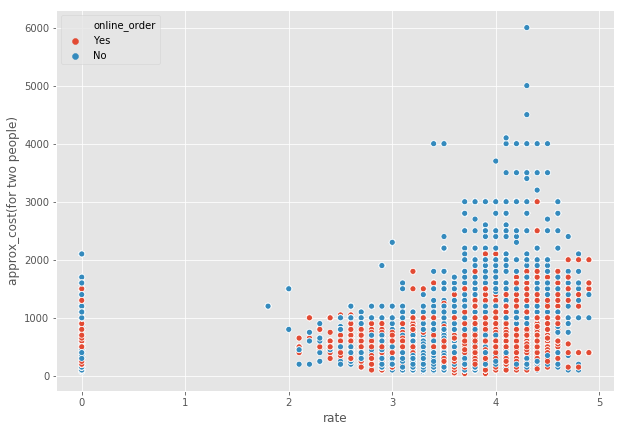
cost_dist=df[['rate','approx_cost(for two people)','online_order']].dropna()
cost_dist['rate']=cost_dist['rate'].apply(lambda x: float(x.split('/')[0]) if len(x)>3 else 0)
cost_dist['approx_cost(for two people)']=cost_dist['approx_cost(for two people)'].apply(lambda x: int(x.replace(',','')))
plt.figure(figsize=(10,7))
sns.scatterplot(x="rate",y='approx_cost(for two people)',hue='online_order',data=cost_dist)
plt.show()
plt.figure(figsize=(6,6))
sns.distplot(cost_dist['approx_cost(for two people)'])
plt.show()

我们可以看到,如果分布偏左。
这意味着几乎90%的餐馆提供的食物预算低于1000印度卢比(15美元)。
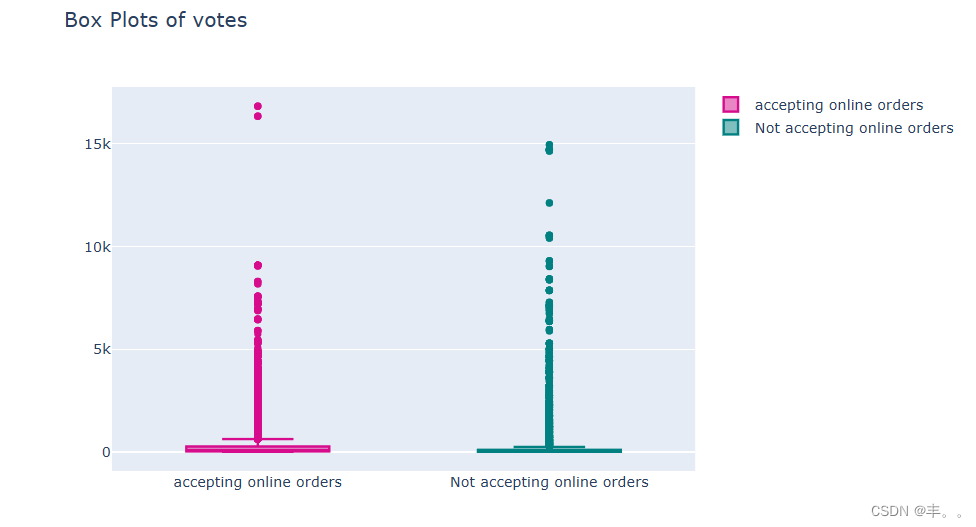
是的,你可以观察到两个类别的中位数是不同的。
接受在线订餐的餐厅往往会得到更多的顾客投票,因为通过zomato应用程序,每点一份订单后都会弹出一个评级选项。
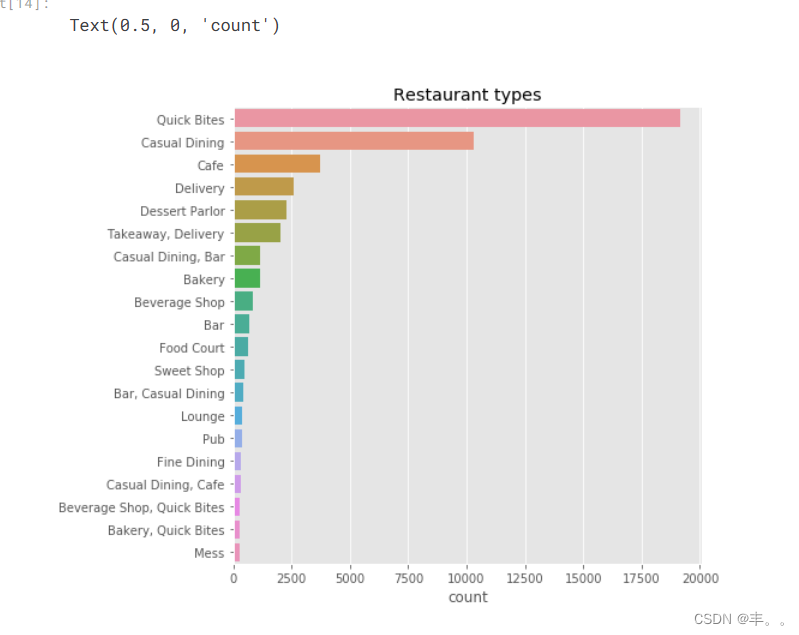
毫无疑问,班加罗尔是印度的科技之都,忙碌和现代生活的人们更喜欢速食。
我们可以观察到速食类型的餐馆占主导地位。
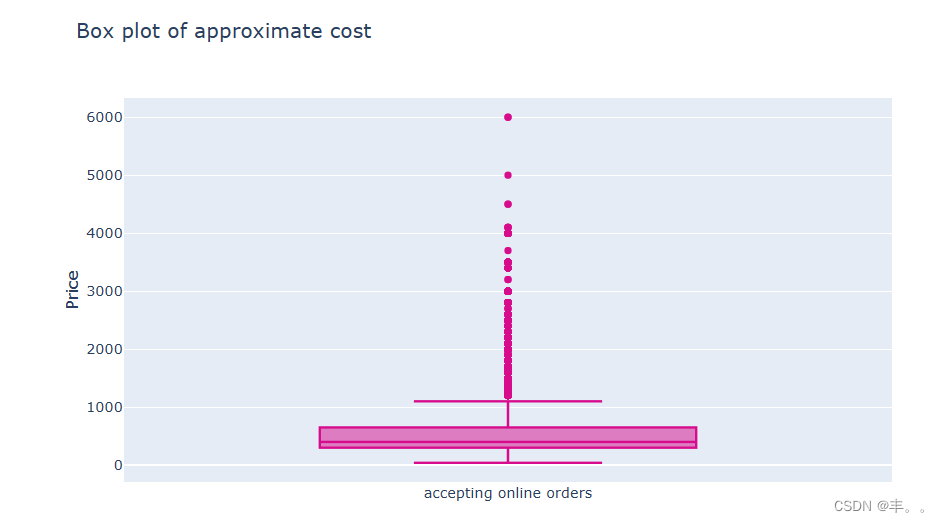
两个人一顿饭的费用中位数大约是400英镑。
50%的餐厅双人单餐收费在300 - 650美元之间。
我实现了一个简单的过滤机制,可以在班加罗尔的任何地方找到最好的经济型餐厅。
你可以传递位置和餐厅类型作为参数,函数将返回餐厅的名称。
return_budget('BTM',"Quick Bites")

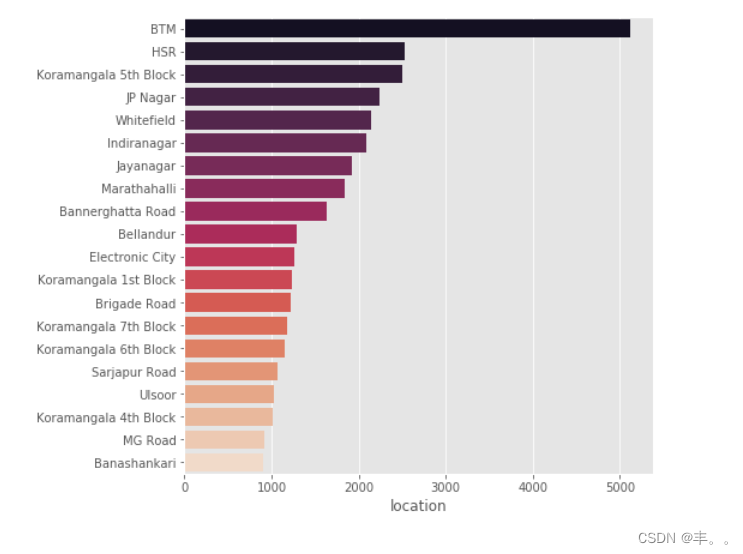
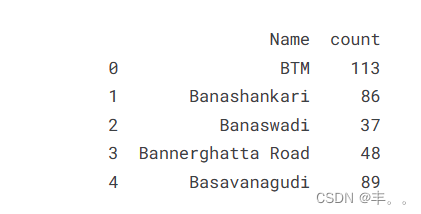
我们可以看到BTM,HSR和Koranmangala第5街区的餐厅数量最多。
BTM以拥有5000多家餐厅而占据主导地位。
data.head(10)

我们已经使用地理数据找到了数据集中列出的每个位置的经纬度。
这是用来绘制地图的。
热力图
basemap
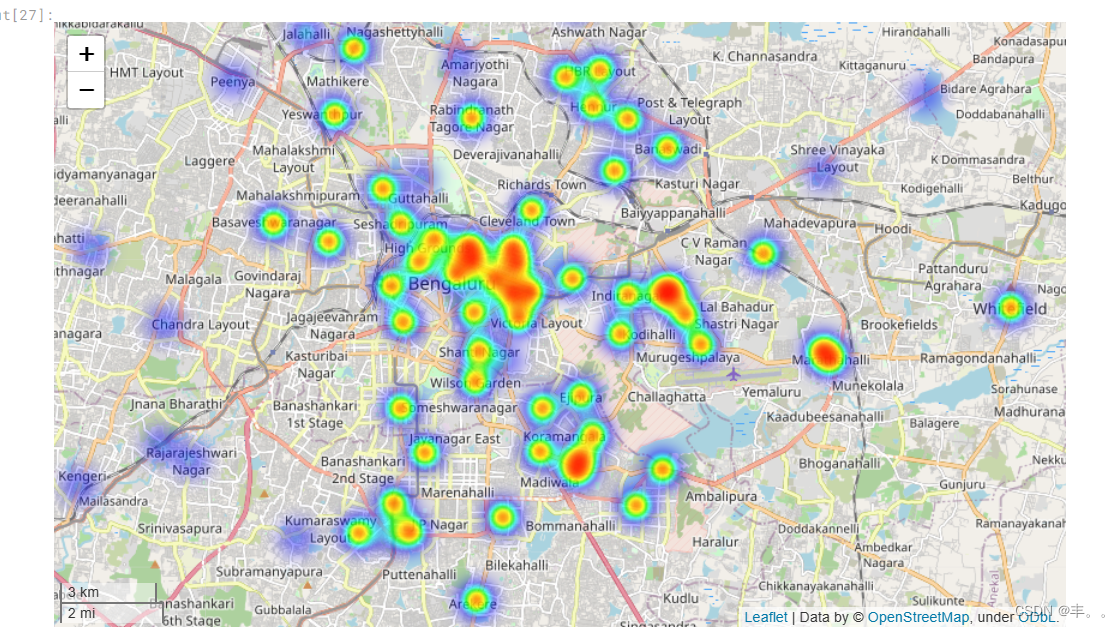
很明显,餐馆往往集中在班加罗尔市中心地区。
当我们离开市中心时,杂乱的餐厅就会减少。
因此,潜在的餐馆企业家可以参考这一点,找到适合他们创业的好地方。
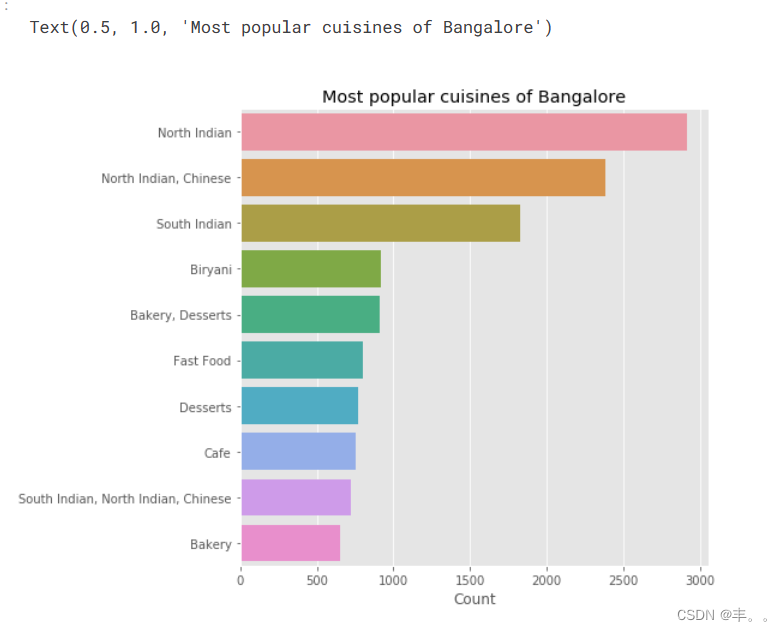
我们可以观察到,北印度人、中国人、南印度人和比亚尼人最常见。
这是否意味着班加罗尔比南印度更受北印度文化的影响?
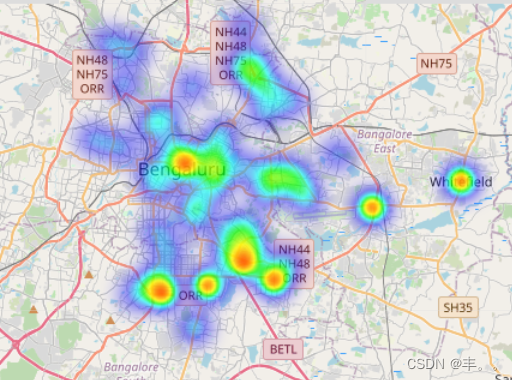
在南班加罗尔地区看到一群北印度餐馆很有趣!
这可能表明这些地区有更多的北印度人居住。
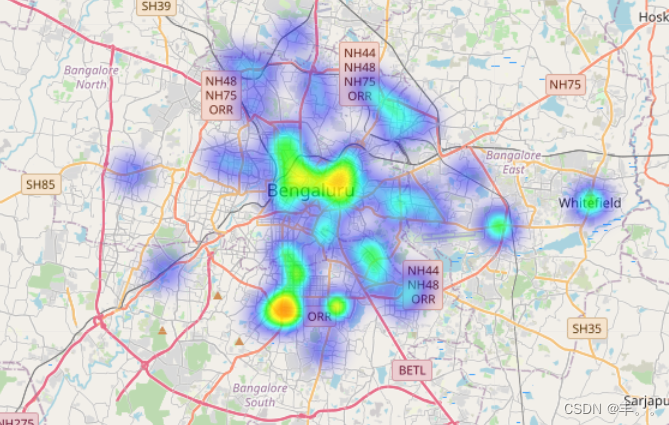
它们往往遍布整个班加罗尔。
南印度美食往往集中在班加罗尔市中心附近。
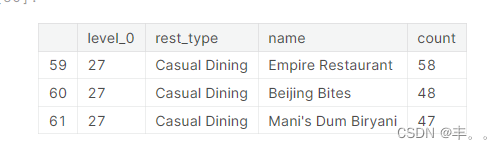
我们可以看到,Empire餐厅、Beijing bites和Mani’s dum biriyani是班加罗尔最受欢迎的休闲餐饮连锁店。
我们将进一步检查……

我们可以看到,Mani’s dum biriyani餐厅有一半的餐厅位于班加罗尔市中心。
帝国餐厅目前在整个班加罗尔。
Mani’s dum Biriyani在乌尔苏尔有12家分店,是一个地方最多的。
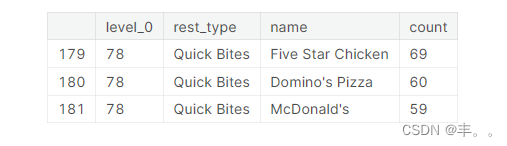
令人惊讶的是,五星鸡肉在快餐餐厅中占据了主导地位,超过了著名的达美乐披萨和麦当劳。
五星鸡是正大集团食品公司的一个分支,正大集团是一家泰国跨国企业集团,在农业和食品行业拥有超过120亿美元的业务。五星鸡的特色炸鸡。
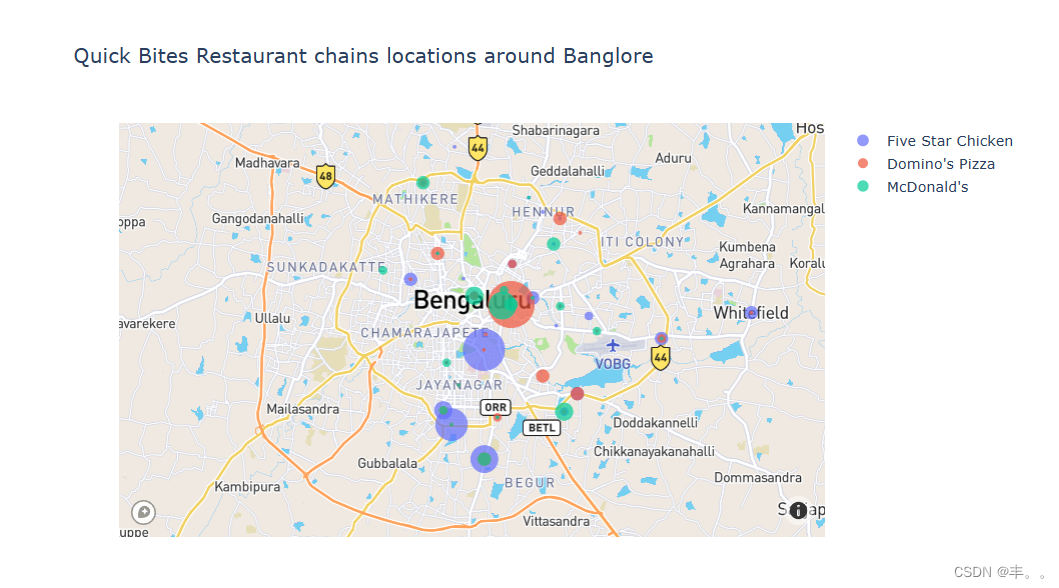
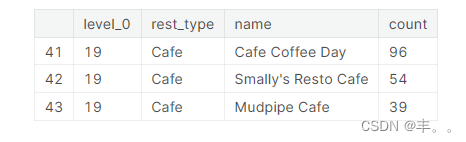
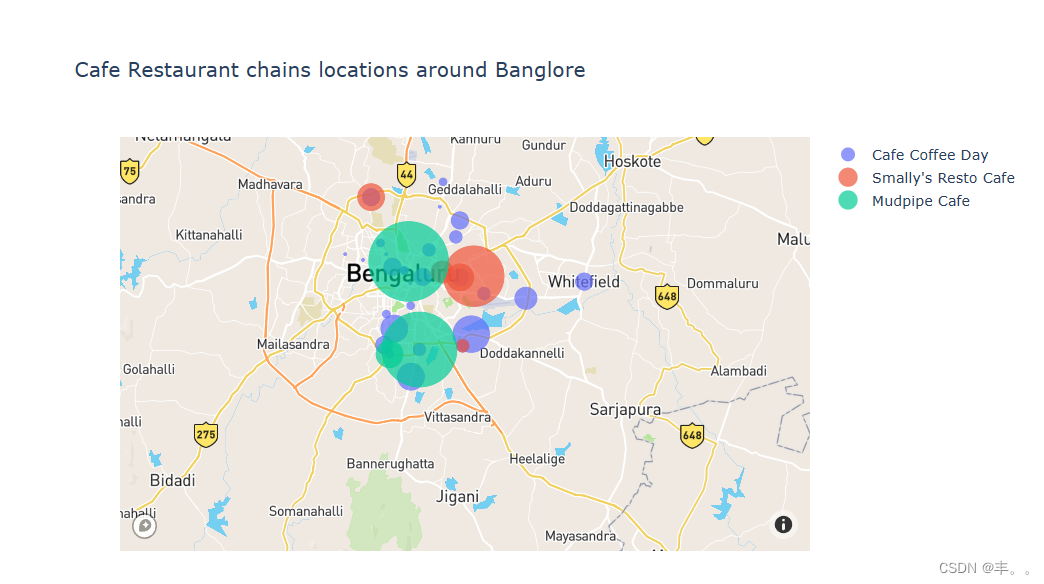
毫不奇怪,Cafe coffee day餐厅在班加罗尔的其他连锁咖啡馆中占据主导地位。
Cafe coffee day在班加罗尔有96家分店。
caf<s:1>咖啡日于1996年作为一家零售餐厅开始。第一个CCD出口于1996年7月11日在卡纳塔克邦班加罗尔的旅路设立。
词云图挖掘

在本节中,我们将继续准备评审数据框架。
我们将提取每个餐厅的评论和评级,并用它创建一个数据框架。
all_ratings = []
for name,ratings in tqdm(zip(df['name'],df['reviews_list'])):
ratings = eval(ratings)
for score, doc in ratings:
if score:
score = score.strip("Rated").strip()
doc = doc.strip('RATED').strip()
score = float(score)
all_ratings.append([name,score, doc])
rating_df=pd.DataFrame(all_ratings,columns=['name','rating','review'])
rating_df['review']=rating_df['review'].apply(lambda x : re.sub('[^a-zA-Z0-9\s]',"",x))

我们将分别对正面评论和负面评论进行主题建模,以了解两种类型之间的差异。
作为第一步,我们将根据所提供的评级将评论分为负面和正面。
评分低于2.5的评论被归类为负面,高于2.5的评论被归类为正面。
rating_df['sent']=rating_df['rating'].apply(lambda x: 1 if int(x)>2.5 else 0)
现在,
我们将删除停顿词
把每个单词按词序排列
创建语料库
标记他们
现在我们将使用Termfrequency Inverse doc frequency(Tfidf)对标记进行矢量化。
主题关键词字数统计
当涉及到主题中的关键字时,关键字的重要性(权重)很重要。除此之外,这些词在文档中出现的频率也很有趣。
让我们在同一图表中绘制单词计数和每个关键字的权重。
你要注意那些在多个主题中出现的单词,以及那些相对频率大于权重的单词。通常情况下,这样的话被证明不那么重要。我在下面绘制的图表是在开始时将几个这样的单词添加到停止单词列表并重新运行训练过程的结果。
counter=Counter(corpus)
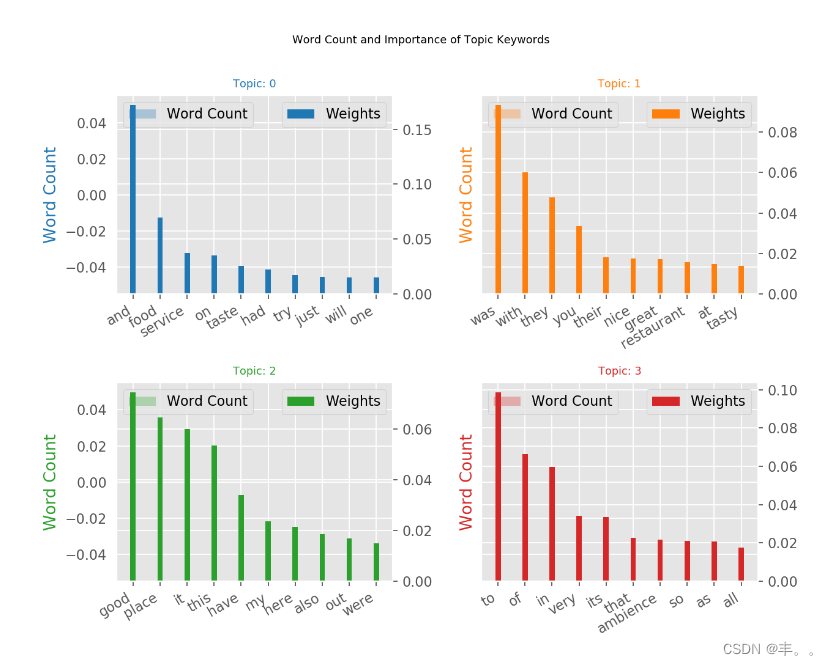
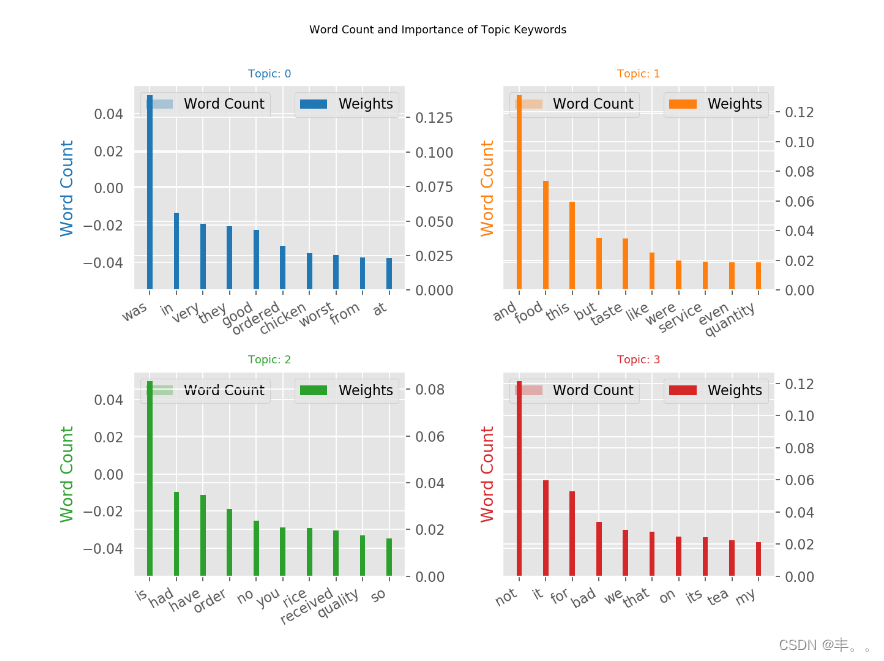
我们可以清楚地观察到这两种评论的区别
所使用的词语清晰可辨。
在负面评论中使用的词语显然是批评。
在积极的评论中使用的词显然是赞赏的。
t分布随机邻域嵌入是一种用于探索高维数据的非线性降维算法。它将多维数据映射到适合人类观察的两个或多个维度。在t-SNE算法的帮助下,下次处理高维数据时,您可能需要绘制更少的探索性数据分析图。
在本节中,我们将在二维空间中可视化评论中使用的单词。
为此,我们将首先对每个评论进行词序化和标记化,并从中构建一个语料库。
现在我们将使用word2vec将每个单词表示为一个向量。
tsne_plot(model)
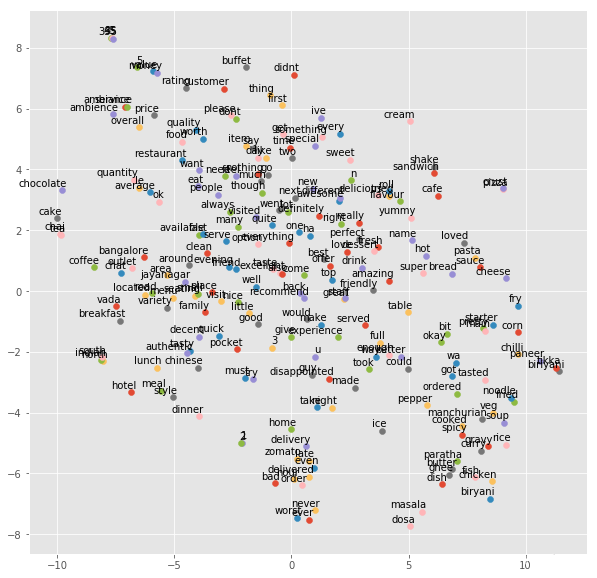
哇,我们可以在2D空间中观察到正面评价中使用的所有形容词。
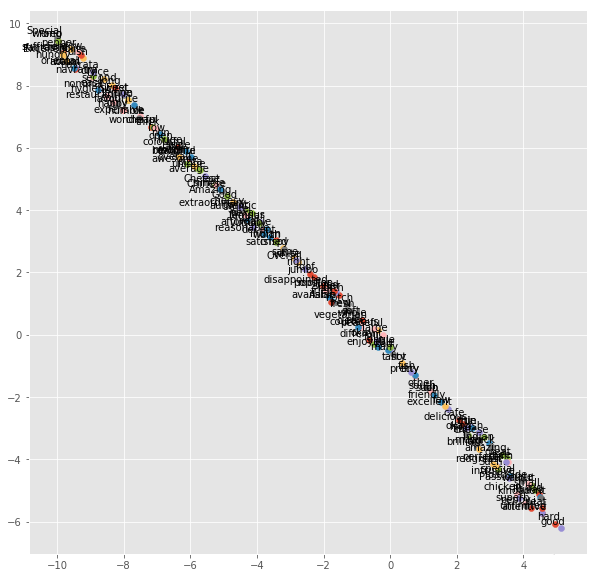
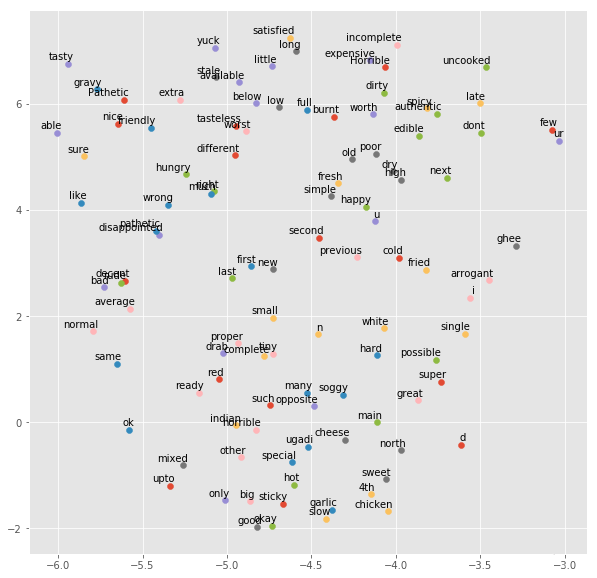
情感分析是通过计算确定一篇文章是积极的、消极的还是中立的过程。它也被称为观点挖掘,获取说话者的观点或态度。
数据预测
对用户提供的评论进行情感分析。我们必须以适当的格式准备资料。我们将根据每个用户提供的评分将评论划分为正面和负面。因此,如果给出的评分小于2.5,我们将把评论映射为负面,如果评分大于2.5,我们将把评论映射为正面
rating_df['sent']=rating_df['rating'].apply(lambda x: 1 if int(x)>2.5 else 0)
接下来,我们将标记数据并对评论进行矢量化,以将其提供给我们的模型。
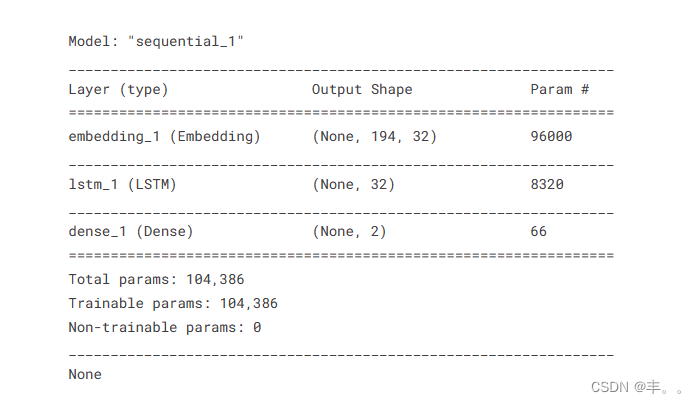
现在我们将对目标变量进行编码。pd。Get_dummies用于on-hot编码。
33%的数据保留用于测试我们的模型
batch_size = 3200
model.fit(X_train, Y_train, epochs = 5, batch_size=batch_size)

我们将使用1500行来验证我们的模型。我们选择准确性作为我们的评价标准。