目录
- 一、什么是训练热身
- 二、常见的训练热身
- 1. Constant Warmup
- 2. Linner Warmup
- 2. Cosine Warmup
- 三、yolov5的训练热身代码
一、什么是训练热身
众所周知学习率是一个非常重要的超参数,直接影响着网络训练的速度和收敛情况。通常情况下,网络开始训练之前,我们会随机初始化权重,设置学习率过大会导致模型振荡严重,学习率过小,网络收敛太慢。
那这个时候该怎么做呢?是不是有人会说,我前面几十个或者几百个epoch学习率设置小一点,后面正常后,设置大一点呢,没错这就是最简单的Warmup。
我们可以把Warmup的过程想成,模型最开始是一个小孩,学习率太大容易认识事物太绝对了,这个时候需要小的学习率,摸着石头过河,小心翼翼地学习,当他对事物有一定了解和积累,认知有了一定地水平,这个时候步子再迈大一点就没问题了。
二、常见的训练热身
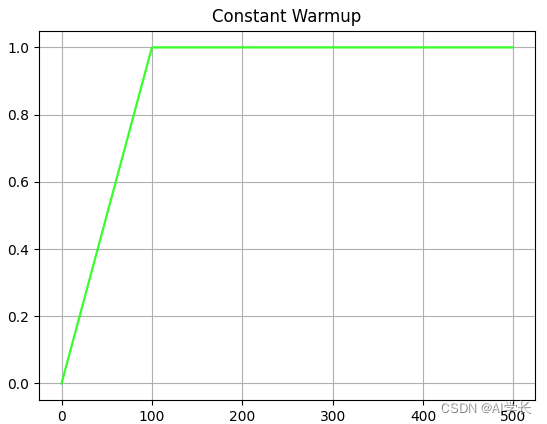
1. Constant Warmup
在前面100epoch里,学习率线性增加,大于100epoch以后保持不变,整个过程如下如所示:
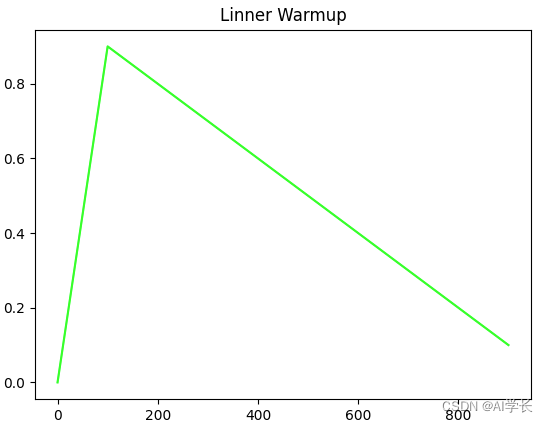
2. Linner Warmup
在前面100epoch里,学习率线性增加,大于100epoch以后保持线性下降,整个过程如下如所示:
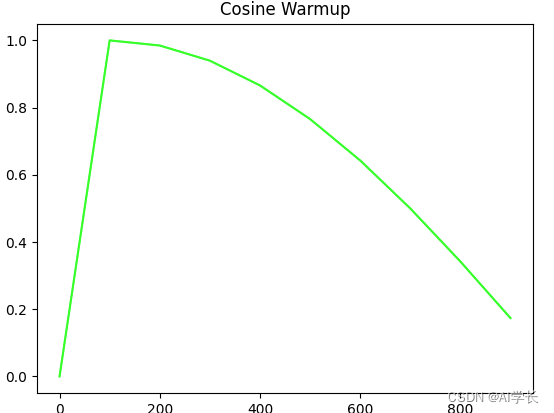
2. Cosine Warmup
在前面100epoch里,学习率线性增加,大于100epoch以后保持x余弦方式下降,整个过程如下如所示:
三、yolov5的训练热身代码
nb表示训练集划分的批次数量,例如nb=60,在超参数中warmup_epochs=3,则nw = 3 * 60= 180批次迭代,就是3个epoch。
意思是前3个epoch都是处于热身阶段。
要注意的代码中最少热身训练100批次迭代,要不然热身都还没有做完,运动就结束了。
# number of batches 数据集一共划分的批次
nb = len(train_loader)
# number of warmup iterations 热身的批次迭代次数, max(3 epochs, 100 iterations)
nw = max(round(self.hyp['warmup_epochs'] * nb), 100)
# 训练热身
for i, (imgs, targets, ...) in train_loader:
ni = i + nb * epoch # number integrated batches (since train start) 第几批次
self.warmup(epoch, ni, nw) # Warmup 热身阶段
# 热身函数
def warmup(self, epoch, ni, nw):
"""
训练热身(前nw次迭代中)
在前nw次迭代中, 根据以下计算获取accumulate、lr、momentum
"""
if ni <= nw:
xi = [0, nw] # x interp
self.accumulate = max(1, np.interp(ni, xi, [1, self.nbs / self.batch_size]).round())
for j, x in enumerate(self.optimizer.param_groups):
"""
bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0
bias的学习率从warmup_bias_lr=0.1下降到lr0
其他参数的学习率从0.0增长到lr0
动量momentum从warmup_momentum=0.8变化到hyp momentum=0.937
"""
fp = [self.hyp['warmup_bias_lr'] if j == 0 else 0.0, x['initial_lr'] * self.lr_lambda(epoch)]
x['lr'] = np.interp(ni, xi, fp)
if 'momentum' in x:
fp = [self.hyp['warmup_momentum'], self.hyp['momentum']]
x['momentum'] = np.interp(ni, xi, fp)