参考教程:
论文:https://arxiv.org/pdf/2010.04159.pdf
源码:https://github.com/fundamentalvision/Deformable-DETR
文章目录
- Deformable Conv
- Deformable DETR
- 计算量
- Method
- Deformable Attention Module
- DeformAttn计算量
- Multi-scale Deformable Attention Module
- Deformable Transformer
- 代码实现
- DeformableDETR
- __init__()
- forward()
- backbone 和 position encoding
- transformer
- MSDeformAttn
- init()
- forward()
- Encoder和Decoder
Deformable Conv
首先来简单的介绍一下可变形卷积。
代码链接: torchvison.DeformConv2d
deformable conv 可变形卷积认为CNN固定的几何结构不能适应图像中复杂的物体。普通的卷积是在固定的、规则的网络点上进行数据采样,感受野的形状是受限的,网络对几何形变的适应力也是受限制的。
所以可变形卷积就给卷积核的每个采样点增加一个可学习的偏移量,让采样点不再受限于规则的网格上。
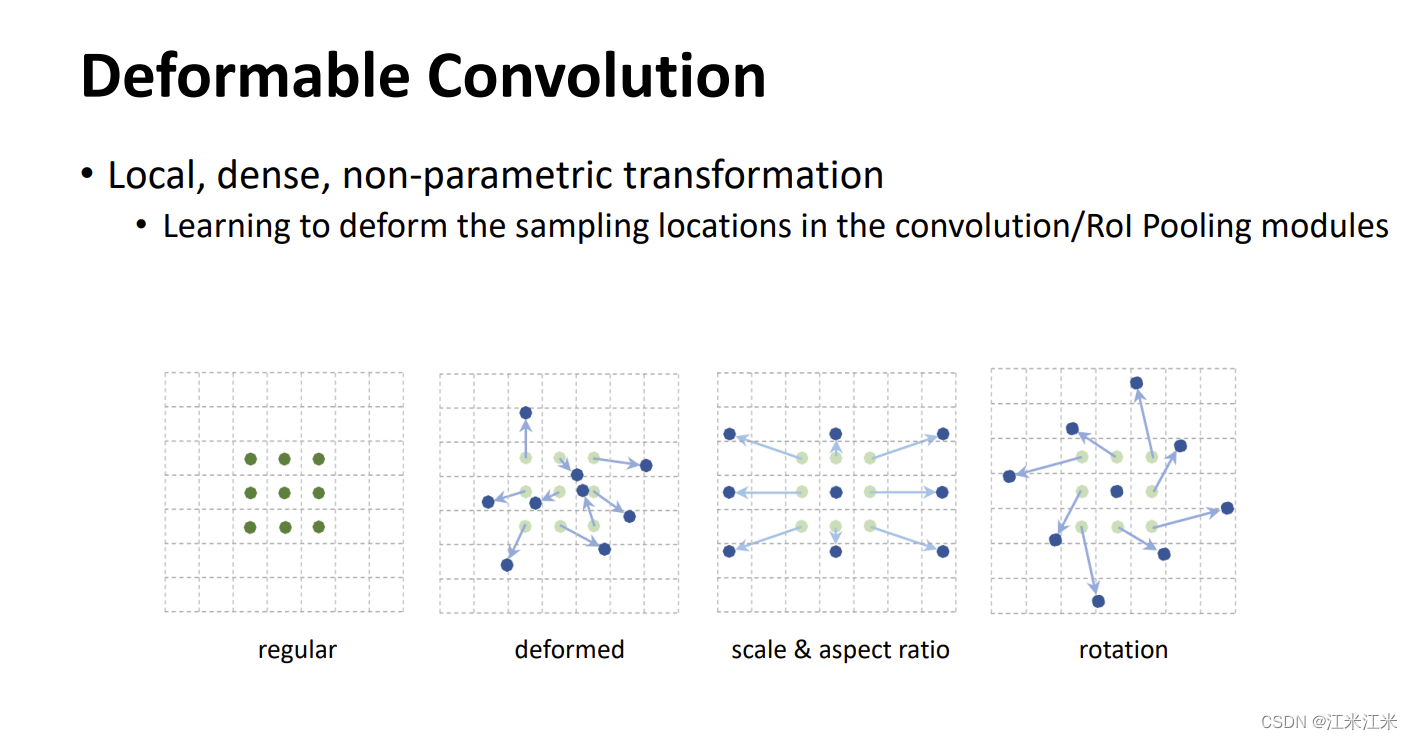
普通的卷积网络在处理一张图的不同位置时,感受野大小都是相同的,这不太合适。对编码了位置信息的神经网络来说,不同位置对应的应该是不同的元素或形变的物体。它不应该是固定的一个框。
在上图中举了几个可变形卷积的例子。第一个是我们标准的方方正正的普通卷积。第二个是deformed 卷积,可以看到它的采样点都有着不同方向和距离的偏移。第三个图比较规整,它更像是我们常说的空洞卷积。第四个图是角度的旋转。
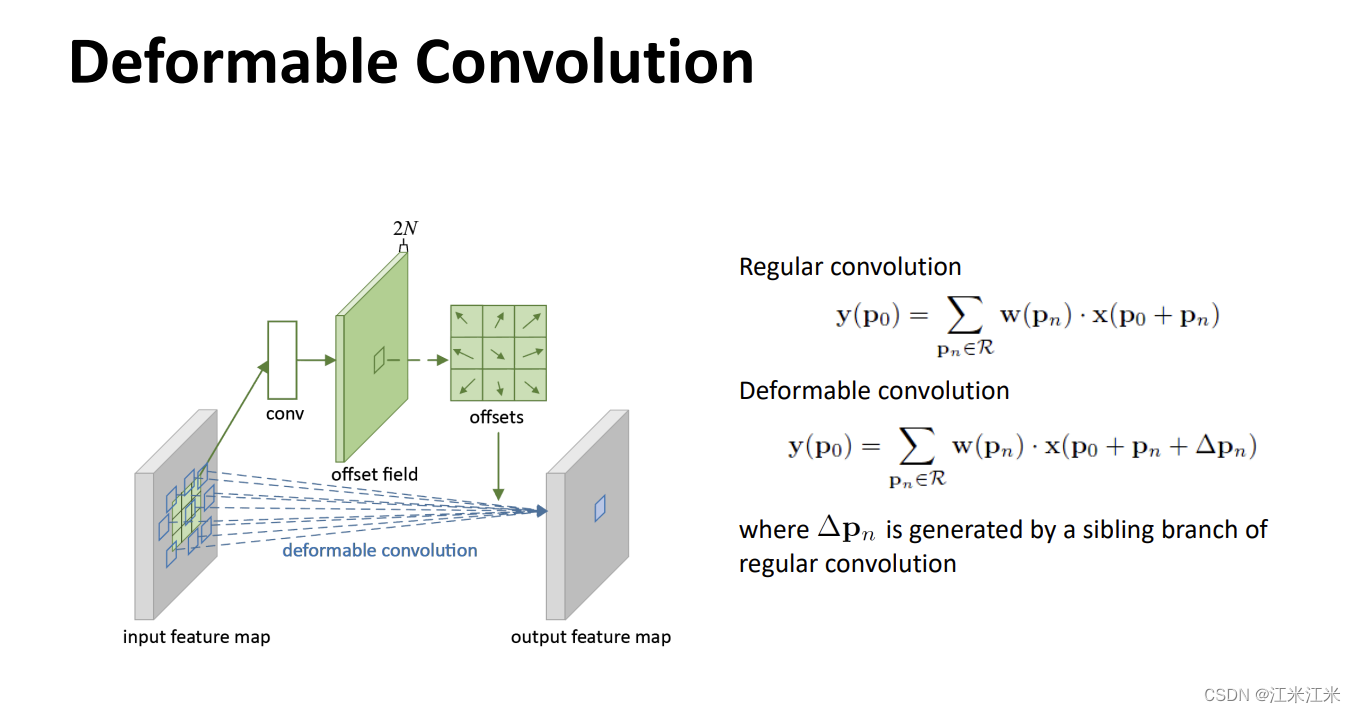
上面这个图是比较直白的deformable convolution的原理图。regular的卷积是某个位置上的值是通过输入的对应位置和卷积核的加权结合得到的。在deformable convolution中,它给每个位置
p
n
p_n
pn增加了一个偏移量
Δ
p
n
\Delta p_n
Δpn。而这个偏移量则是由另一个卷积得到的。
也就是说deformable convolution其实是由两个卷积组成的,一个走正常的卷积,一个用于计算偏移量。
Deformable DETR
DETR作为一个省去了很多比如NMS这些处理工作的目标检测方法,不仅可以实现端到端的检测,检测的效果还非常好。
但是它也是有一些问题的。
- 首先它的收敛速度非常慢。这个问题之前VIT也有说过,算是基于self-attention训练的常见问题。它相当于自己学习感受野和元素间的关系,更加flexible,所以收敛时间也就更长。
- 它检测小物体的效果比较差。因为他是基于backbone得到的feature map做的检测,所以也受到feature map的resolution的限制。假如你想用high-resolution的featuremap来做预测,那么使用DETR的计算复杂度也太高了,是不可接受的。
作者在论文中说,上面这两个问题归根到底都是transformer自身的缺陷。在初始化的时候,这个attention module对feature map上的每一个像素施加了均匀的注意力权重,所以需要长时间的寻来你来关注到稀疏的有意义的位置。
deformable convolution呢,则是一个非常有效的关注稀疏空间位置的方法,它天然地能避免上面这个问题,但是它呢缺乏元素相对关系的建模,而这又是transformer能给它的。所以才会想把两者结合起来。
计算量
之前我们有计算过MSA的计算量,这里来复习一下。
- C代表token的维度,假设我们的输入大小是 A h ∗ w , C A^{h*w,C} Ah∗w,C。在进行Q\K\V计算时唯独没有发生变化,那么进行三次矩阵乘法 A h ∗ w , C ∗ W C , C A^{h*w,C}*W^{C,C} Ah∗w,C∗WC,C,每次计算量是 h w C 2 hwC^2 hwC2,计算了三次,总的计算量是 3 h w C 2 3hwC^2 3hwC2。
- 然后计算 Q h ∗ w , C Q^{h*w,C} Qh∗w,C和 K h ∗ w , C K^{h*w,C} Kh∗w,C的内积,计算结果为 X h ∗ w , h ∗ w X^{h*w,h*w} Xh∗w,h∗w,内积计算需要点对点进行计算,所以计算量是 h 2 w 2 C h^2w^2C h2w2C。
- 再下一步计算 X h ∗ w , h ∗ w ∗ V h ∗ w , C X^{h*w,h*w}*V^{h*w,C} Xh∗w,h∗w∗Vh∗w,C,计算量为 h 2 w 2 C h^2w^2C h2w2C。
- 因为是多头自注意力,所以还需要增加一步 B h ∗ w , C ∗ W C , C B^{h*w,C}*W^{C,C} Bh∗w,C∗WC,C,计算量为 h w C 2 hwC^2 hwC2
- 加起来的总的计算量是:
4 h w C 2 + 2 h 2 w 2 C 4hwC^2 + 2h^2w^2C 4hwC2+2h2w2C
假设我们以backbone的最后一层featuremap为输出,送入encoder中进行MSA。假如你的输入图像大小为480*480*3,那么经过backbone后得到的featuremap大小为15*15*2048,2048的通道数还需要经过1*1卷积降维变成C,直接代入数字:
4
h
w
C
2
+
2
h
2
w
2
C
=
4
×
15
×
15
×
C
2
+
2
×
1
5
2
×
1
5
2
×
C
=
900
C
2
+
101250
C
\begin{align} &4hwC^2 + 2h^2w^2C \\ = &4\times15\times15\times C^2+ 2\times15^2\times15^2\times C\\ =&900C^2 + 101250C \end{align}
==4hwC2+2h2w2C4×15×15×C2+2×152×152×C900C2+101250C
你想要用多尺度、多层featuremap,比如你使用倒数第二层,那么这时得到的featuremap大小时30*30*1024。也就是h和w都翻倍了,这带来的计算量的提升是很恐怖的。
所以说不太可能使用比较低层的featuremap来作transformer的输入。
Method
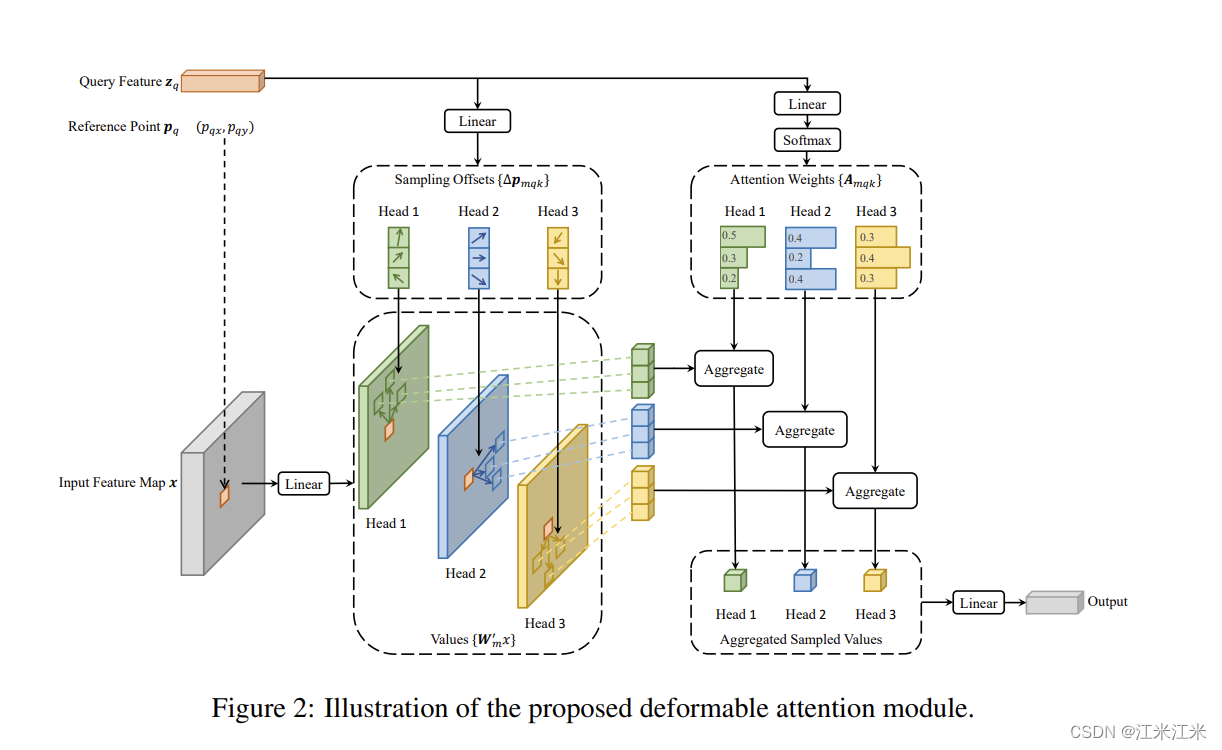
Deformable Attention Module
transformer的一个问题是对于一个输入的feature map,它会看一遍所有的点。所以作者提出了deformable attention module,只关注目标点附近的一小部分点集,而不是整个feature map。
原本的MSA公式如下:
M
u
l
t
i
H
e
a
d
A
t
t
n
(
z
q
,
x
)
=
∑
m
=
1
M
W
m
[
∑
k
∈
Ω
k
A
m
q
k
∗
W
m
′
x
k
]
MultiHeadAttn(z_q,x) = \sum^M_{m=1}W_m[\sum_{k\in\Omega_k}A_{mqk}*W'_mx_k]
MultiHeadAttn(zq,x)=m=1∑MWm[k∈Ωk∑Amqk∗Wm′xk]
其中m表示第m个head。head的个数是M个。
x
k
x_k
xk是输入特征,也就是通俗的讲的token。一共有N个输入。
W
m
′
x
k
W'_mx_k
Wm′xk可以理解成从输入的token转变成MSA中的Value的过程。
A
m
q
k
A{mqk}
Amqk是求得的attention matrix。表示第m个head上的第q个Query和第k个Key之间的attention。
而作者提出的deformable attention的公式如下:
D
e
f
o
r
m
A
t
t
n
(
z
q
,
p
q
,
x
)
=
∑
m
=
1
M
W
m
[
∑
k
=
1
K
A
m
q
k
∗
W
m
′
x
(
p
q
+
Δ
p
m
q
k
]
DeformAttn(z_q,p_q,x) = \sum^M_{m=1}W_m[\sum^K_{k=1}A{mqk}*W'_mx(p_q+\Delta p_{mqk}]
DeformAttn(zq,pq,x)=m=1∑MWm[k=1∑KAmqk∗Wm′x(pq+Δpmqk]
两者相比有明显的差别:
- 在MSA中k是从全局取的,而在DeformAttn中k是有限制的。K是取样的总数。每个Query只和K个Key进行注意力的计算。
- 在DeformAttn中使用了一个 Δ p m q k \Delta p_{mqk} Δpmqk来代表采样的偏移量。
此外,通过前面的module流程图,也能看到在deformAttn中,attention matrix不再是Query和Key进行内积得到的,而是通过linear的线性变化得到的。
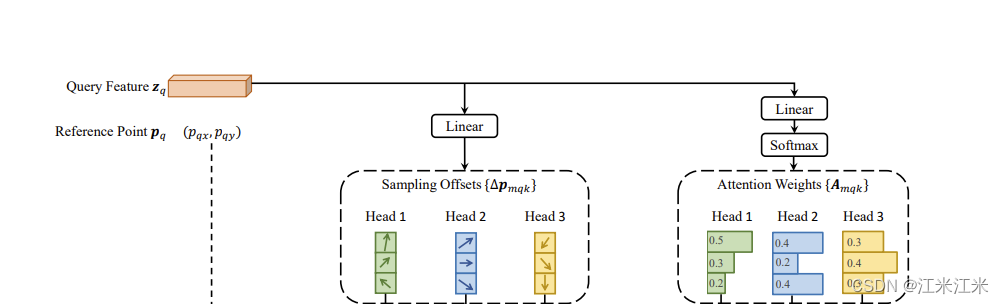
在实际实验中,feature
z
q
z_q
zq会通过一个线性映射来得到通道数为3MK的结果,其中前2MK是用来代表偏移量
Δ
p
m
q
k
\Delta p_{mqk}
Δpmqk的,最后一个MK会送入softmax操作来获得我们的attention matrix。
DeformAttn计算量
理一下这个过程,并算一下计算量。
假设输入大小为 H ∗ W , C H*W,C H∗W,C,M代表head的个数,K代表选取的样本点的个数。
以下指的是encoder的过程,在decoder中没有HW的概念,直接使用的是object query的数量。
- 计算attention matrix需要 H ∗ W ∗ C ∗ M K H*W*C*MK H∗W∗C∗MK
- 计算偏移量需要 2 ∗ H ∗ W ∗ C ∗ M K 2*H*W*C*MK 2∗H∗W∗C∗MK
- 进行Value值的计算有两种方法:
- 一种是采样前进行计算,需要 H ∗ W ∗ C 2 H*W*C^2 H∗W∗C2
- 一种是采样后计算,需要 H ∗ W ∗ K ∗ C 2 H*W*K*C^2 H∗W∗K∗C2
- 计算输出的时候需要 H ∗ W ∗ C ∗ K H*W*C*K H∗W∗C∗K
- 用的是多头,还需要增加一步 B H ∗ W , C ∗ W C , C B^{H*W,C}*W^{C,C} BH∗W,C∗WC,C,计算量为 H W C 2 HWC^2 HWC2
- 在偏移量计算的时候,要用到插值的方式,带来了比较多的计算量,计为 4 ∗ H ∗ W ∗ C ∗ K 4*H*W*C*K 4∗H∗W∗C∗K
所以总的计算量是:
3
H
W
C
M
K
+
5
H
W
C
K
+
H
W
C
2
+
m
i
n
H
W
C
2
,
H
W
K
C
2
3HWCMK + 5HWCK + HWC^2 + min{HWC^2, HWKC^2}
3HWCMK+5HWCK+HWC2+minHWC2,HWKC2
在decoder中因为输入的token个数不是HW,所以要进行一些替换。N代表object query的数量,在decoder中的计算量如下。
3
N
C
M
K
+
5
N
C
K
+
N
C
2
+
m
i
n
H
W
C
2
,
N
K
C
2
3NCMK + 5NCK + NC^2 + min{HWC^2, NKC^2}
3NCMK+5NCK+NC2+minHWC2,NKC2
Multi-scale Deformable Attention Module
为了便于在多尺度多层次的feature map上应用,作者又提出了DeformAttn的扩展:Multi-scale deformable attention。
M
S
D
e
f
o
r
m
A
t
t
n
(
z
q
,
p
^
q
,
{
x
l
}
l
=
1
L
)
=
∑
m
=
1
M
W
m
[
∑
l
=
1
L
∑
k
=
1
K
A
m
l
q
k
∗
W
m
′
x
l
(
ϕ
(
p
^
q
)
+
Δ
p
m
l
q
k
)
]
MSDeformAttn(z_q,\hat{p}_q,\{x^l\}^L_{l=1}) = \sum^M_{m=1}W_m[\sum^L_{l=1}\sum^K_{k=1}A{mlqk}*W'_mx^l(\phi(\hat{p}_q)+\Delta p_{mlqk})]
MSDeformAttn(zq,p^q,{xl}l=1L)=m=1∑MWm[l=1∑Lk=1∑KAmlqk∗Wm′xl(ϕ(p^q)+Δpmlqk)]
m还代表第几个head,l代表第几个feature level。
Δ
p
m
l
q
k
\Delta p_{mlqk}
Δpmlqk和
A
m
l
q
k
A_{mlqk}
Amlqk代表了第m个head上第l个feature level下第k个采样点的偏移量和attention。并且满足不同层不同head的权重和为1。
对于多尺度的feature map,要求是将它们的通道数映射成一致。如下图:所有feature map的通道数都被映射为256。
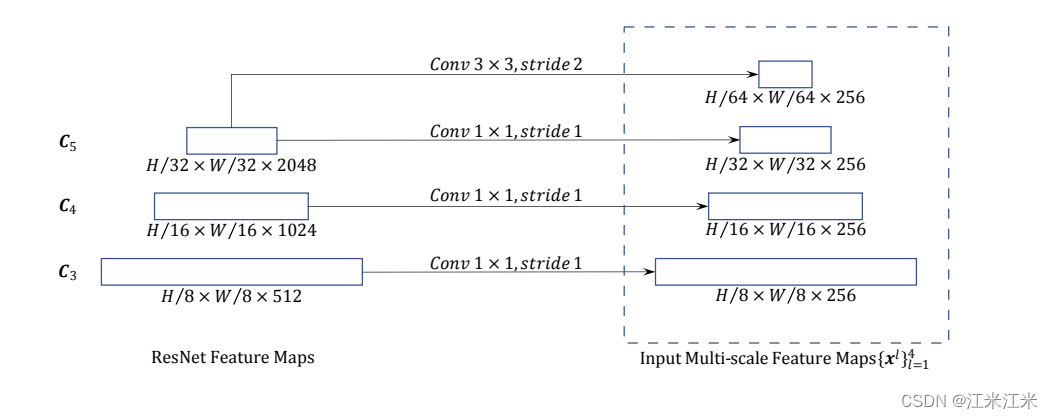
假如你想要的feature map数量比backbone给的要多怎么办呢,就要使用stride = 2的3*3卷积来获得更小的feature map,同时通道数还要保持一致。
Deformable Transformer
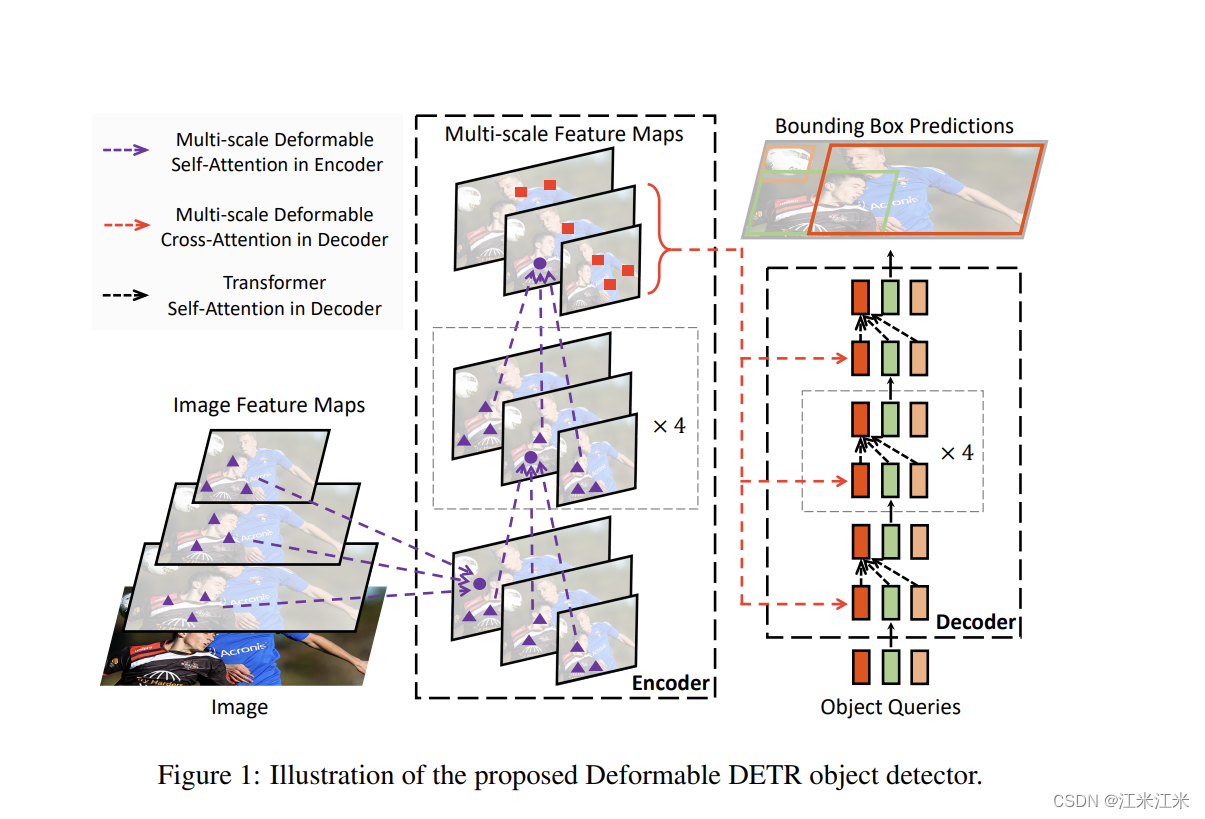
看一下整体结构。
在encoder部分,所有的attention模块都用的是multi-scale deformable attention。并且用的也是多尺度的输入和输出。
在decoder中,它的cross-attention的部分被换成了multi-scale deformable attention,self-attention的部分用的还是普通的MSA。
代码实现
源码链接:
https://github.com/fundamentalvision/Deformable-DETR
我们用和DETR一样的顺序来看Deformable DETR的代码。
Deformable DETR的代码和DETR代码整体上其实大差不大,没有很大的区别。
DeformableDETR
我们首先来看DeformableDETR这个类。
init()
class DeformableDETR(nn.Module):
""" This is the Deformable DETR module that performs object detection """
def __init__(self, backbone, transformer, num_classes, num_queries, num_feature_levels,
aux_loss=True, with_box_refine=False, two_stage=False):
它的传入参数和DETR的也很一致。
- backbone:你打算使用的backbone
- transformer:构造好的transformer
- num_classes:数据集中物体种类的数量。
- num_feature_levels 你想要使用的feature层数
- num_queries:object queries的数量,也就代表了每张图中能预测的物体的最大数量。
- aux_loss:是否要使用aux_loss。
在此基础上增加了with_box_refine和two-stage,这是deformable DETR做的扩展内容,我们先忽略。
它的构造函数部分,我们忽略掉扩展内容后,看看剩下的代码。
self.num_queries = num_queries # object query的数量
self.transformer = transformer # 你的transformer
hidden_dim = transformer.d_model
self.class_embed = nn.Linear(hidden_dim, num_classes) # 分类预测头
self.bbox_embed = MLP(hidden_dim, hidden_dim, 4, 3) # bbox预测头
self.backbone = backbone # 你的backbone
self.aux_loss = aux_loss # 是否使用aux_loss
self.num_feature_levels = num_feature_levels
if not two_stage:
self.query_embed = nn.Embedding(num_queries, hidden_dim*2)
self.class_embed = nn.ModuleList([self.class_embed for _ in range(num_pred)])
self.bbox_embed = nn.ModuleList([self.bbox_embed for _ in range(num_pred)])
前几行和DETR中一样。多了个num_feature_levels来控制是否使用多尺度。
假如说你打算使用多尺度,因为不同尺度下的feature map的通道数不一样,所以要将它们映射到一样的通道数。
假如你想要的feature map数量比num_backbone_outs要多,那么就需要用stride=2的3*3卷积自己再做出来一点。
下面的代码就是实现了这个功能。
假如num_feature_levels = 1,就直接将最后一层映射过去就行。
假如num_feature_levels>1,对于num_backbone_outs范围内的部分,使用1*1卷积进行降维,超过的部分,就用3*3卷积创造新的feature map。
if num_feature_levels > 1:
num_backbone_outs = len(backbone.strides)
input_proj_list = []
for _ in range(num_backbone_outs):
in_channels = backbone.num_channels[_]
input_proj_list.append(nn.Sequential(
nn.Conv2d(in_channels, hidden_dim, kernel_size=1),
nn.GroupNorm(32, hidden_dim),
))
for _ in range(num_feature_levels - num_backbone_outs):
input_proj_list.append(nn.Sequential(
nn.Conv2d(in_channels, hidden_dim, kernel_size=3, stride=2, padding=1),
nn.GroupNorm(32, hidden_dim),
))
in_channels = hidden_dim
self.input_proj = nn.ModuleList(input_proj_list)
else:
self.input_proj = nn.ModuleList([
nn.Sequential(
nn.Conv2d(backbone.num_channels[0], hidden_dim, kernel_size=1),
nn.GroupNorm(32, hidden_dim),
)])
这一部分也就是对应着DETR中的。
nn.Conv2d(backbone.num_channels, hidden_dim, kernel_size=1)
forward()
在DETR中这部分代码也是比较简单的,在DeformableDETR中变长了不少。
因为这里是考虑了multi-scale feature map的。在DETR的backbone中拿出的features,直接经过projection后就送进transformer了。在这里还需要按顺序每个都projection一下。
features, pos = self.backbone(samples)
srcs = []
masks = []
for l, feat in enumerate(features):
src, mask = feat.decompose()
srcs.append(self.input_proj[l](src))
masks.append(mask)
assert mask is not None
假如你想要的featuremap比backbone给的多,这时候还要多处理一下。多出来的第一个featuremap还是在backbone的输出上进行卷积,后面的都要在前一个的基础上进行卷积。
并且也要专门生成position embedding。
if self.num_feature_levels > len(srcs):
_len_srcs = len(srcs)
for l in range(_len_srcs, self.num_feature_levels):
if l == _len_srcs:
src = self.input_proj[l](features[-1].tensors)
else:
src = self.input_proj[l](srcs[-1])
m = samples.mask
mask = F.interpolate(m[None].float(), size=src.shape[-2:]).to(torch.bool)[0]
pos_l = self.backbone[1](NestedTensor(src, mask)).to(src.dtype)
srcs.append(src)
masks.append(mask)
pos.append(pos_l)
然后这些东西,才一股脑地放进transformer里面去。
hs, init_reference, inter_references, enc_outputs_class, enc_outputs_coord_unact = self.transformer(srcs, masks, pos, query_embeds)
之前DETR中的transformer的输入是tensor,这里变成了list,说明transformer中肯定也有比较大的改动。
backbone 和 position encoding
和DETR中没有什么区别,仍然是使用了IntermediateLayerGetter来获取不同层的输出。
在backbone的部分增加了一些attributes。主要是因为在DeformDETR的forward()中会用到。
if return_interm_layers:
# return_layers = {"layer1": "0", "layer2": "1", "layer3": "2", "layer4": "3"}
return_layers = {"layer2": "0", "layer3": "1", "layer4": "2"}
self.strides = [8, 16, 32]
self.num_channels = [512, 1024, 2048]
else:
return_layers = {'layer4': "0"}
self.strides = [32]
self.num_channels = [2048]
backbone里面的len(self.strides)也就代表了你输出的featuremap的个数。
在刚刚DeformDETR的forward()中,当num_feature_level = 1的时候,它的projection用的是nn.Conv2d(backbone.num_channels[0], ,我解释说这代表输入是最后一层的通道数,其实就是我们的backbone的num_channels数量只有1,所以[0]也是最后一层。
transformer
这一部分变复杂了好多啊。
DeformableTransformer的整体结构仍是由n个encoderlayer组成的一个Encoder和n个decoderlayer组成的一个Decoder拼成的。
一个区别是这里还增加了一个level embedding 还有一个reference_points。
self.level_embed = nn.Parameter(torch.Tensor(num_feature_levels, d_model))
self.reference_points = nn.Linear(d_model, 2)
然后我们来看一下forward()的部分。
bs, c, h, w = src.shape
src = src.flatten(2).permute(2, 0, 1)
pos_embed = pos_embed.flatten(2).permute(2, 0, 1)
query_embed = query_embed.unsqueeze(1).repeat(1, bs, 1)
mask = mask.flatten(1)
这里的src在flatten()后使用permute(2,0,1)是因为nn.MultiheadAttention中默认的batch_size不是在最前面的。
在DETR中只有一层feature map,所以都是直接算的。但是在这里有多个,所以要遍历list后每一个都处理一下。
for lvl, (src, mask, pos_embed) in enumerate(zip(srcs, masks, pos_embeds)):
bs, c, h, w = src.shape
spatial_shape = (h, w)
spatial_shapes.append(spatial_shape)
src = src.flatten(2).transpose(1, 2)
mask = mask.flatten(1)
pos_embed = pos_embed.flatten(2).transpose(1, 2)
lvl_pos_embed = pos_embed + self.level_embed[lvl].view(1, 1, -1)
lvl_pos_embed_flatten.append(lvl_pos_embed)
src_flatten.append(src)
mask_flatten.append(mask)
单个比较来看,src, mask的处理和之前没有区别,pos_embedding上额外加上了level_embed,进行了level位置的区分。
然后这些东西就被一股脑地送进encoder中去。
memory = self.encoder(src_flatten, spatial_shapes, level_start_index, valid_ratios, lvl_pos_embed_flatten, mask_flatten)
假如说你用的不是two-stage的扩展的话。
query_embed, tgt = torch.split(query_embed, c, dim=1)
query_embed = query_embed.unsqueeze(0).expand(bs, -1, -1)
tgt = tgt.unsqueeze(0).expand(bs, -1, -1)
reference_points = self.reference_points(query_embed).sigmoid()
init_reference_out = reference_points
获取我们的decoder的输入还有reference_points。然后将这些东西和encoder的输出一起,一股脑送进decoder里。
hs, inter_references = self.decoder(tgt, reference_points, memory, spatial_shapes, level_start_index, valid_ratios, query_embed, mask_flatten)
MSDeformAttn
forward部分比较复杂,大致看一下流程。细节不管了。
init()
相比于一般的attention的输入d_model, nhead,这里增加了一个n_levels和n_points。
n_levels就是我们之前公式里的L,你想要在多少个feature level上进行attention。
n_points就是我们之前公式里的K,采样点的数量。
class MSDeformAttn(nn.Module):
def __init__(self, d_model=256, n_levels=4, n_heads=8, n_points=4):
super().__init__()
self.im2col_step = 64
self.d_model = d_model
self.n_levels = n_levels
self.n_heads = n_heads
self.n_points = n_points
self.sampling_offsets = nn.Linear(d_model, n_heads * n_levels * n_points * 2)
self.attention_weights = nn.Linear(d_model, n_heads * n_levels * n_points)
self.value_proj = nn.Linear(d_model, d_model)
self.output_proj = nn.Linear(d_model, d_model)
self._reset_parameters()
偏移量和attention matrix都通过线性映射得到。
偏移量的维度是 2 ∗ M ∗ K ∗ L 2*M*K*L 2∗M∗K∗L, attention matrix的维度是 M ∗ K ∗ L M*K*L M∗K∗L
forward()
forward()部分的输入有点多。
配合着transformer的输入看了一下之后,大致了解了这部分都是什么。
def forward(self, query, reference_points, input_flatten, input_spatial_shapes, input_level_start_index, input_padding_mask=None):
- query: 我们输入的带位置编码的query。
- input_flatten:在encoder的输入部分其实就是不带位置编码的query,原始的flatten的feature。在decoder的cross_attn部分就是encoder的输出。
- 剩下的先不管,记住这两个就可以。
我们的value是对input_flatten进行projection得到的,这个在整体流程图中也是可以看到的。
value = self.value_proj(input_flatten)
而我们的偏移量和attention weight都是基于query计算的。
sampling_offsets = self.sampling_offsets(query).view(N, Len_q, self.n_heads, self.n_levels, self.n_points, 2)
attention_weights = self.attention_weights(query).view(N, Len_q, self.n_heads, self.n_levels * self.n_points)
attention_weights = F.softmax(attention_weights, -1).view(N, Len_q, self.n_heads, self.n_levels, self.n_points)
这里的attention weights要保证和为1,所以也要做softmax。
然后这些会经过一个MSDeformAttnFunction的处理,这里面也包括了前向和后向的计算。源码位置:ms_deform_attn_func.py
最后的输出还要经过projection:
output = self.output_proj(output)
Encoder和Decoder
如果忽略MSA到DeformAttn的变化,encoder和decoder中的改动其实挺小的。
我们直接来看一下encoder layer的forward():
def forward(self, src, pos, reference_points, spatial_shapes, level_start_index, padding_mask=None):
# self attention
src2 = self.self_attn(self.with_pos_embed(src, pos), reference_points, src, spatial_shapes, level_start_index, padding_mask)
src = src + self.dropout1(src2)
src = self.norm1(src)
# ffn
src = self.forward_ffn(src)
return src
简洁明了:
- 加pos_embedding
- self-attention得到src2
- src2和src残差和 然后norm
- 经过MLP(这里面已经包括了残差和+norm)
再来看一下decoder的forward()
首先进行decoder的自注意力计算,这里用的还是普通的MSA,因为这一部分没有涉及到feature。
self.self_attn = nn.MultiheadAttention(d_model, n_heads, dropout=dropout)
这里的q,k,tgt进行transpose也是因为默认batch_first=False的原因。
q = k = self.with_pos_embed(tgt, query_pos)
tgt2 = self.self_attn(q.transpose(0, 1), k.transpose(0, 1), tgt.transpose(0, 1))[0].transpose(0, 1)
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
然后再用自注意力的结果和encoder的输出做cross_attn,这里用的就是DeformAttn了。
tgt2 = self.cross_attn(self.with_pos_embed(tgt, query_pos),
reference_points,
src, src_spatial_shapes, level_start_index, src_padding_mask)
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
# ffn
tgt = self.forward_ffn(tgt)