前言
LightGBM也属于Boosting集成学习模型(还有前面文章的XGBoost),LightGBM和XGBoost同为机器学习的集大成者。相比越来越流行的深度神经网络,LightGBM和XGBoost能更好的处理表格数据,并具有更强的可解释性,还具有易于调参、输入数据不变性等优势。
机器学习实践(1.2)XGBoost回归任务
❤️ 本文完整脚本点此链接 百度网盘链接 获取 ❤️
结论先行:
当使用 from lightgbm import LGBMClassifier 的模型进行训练时,使用的是sklearn中的XGBClassifier类,该方法中无需特意指定分类类别,方法自带类别数量_n_classes的计算,并根据数量指定了_objective参数,简而言之:该方法会自动判别是多分类还是二分类任务,无需特殊说明。
之所以特殊强调from lightgbm import LGBMClassifier 是要区别于import lightgbm as lgb 的调用,本人更建议使用前者。
下方代码取自 sklearn.py 的 class LGBMModel(_LGBMModelBase)…和class LGBMClassifier(_LGBMClassifierBase, LGBMModel)…
# class LGBMModel(_LGBMModelBase)......
"""
objective : str, callable or None, optional (default=None)
Specify the learning task and the corresponding learning objective or
a custom objective function to be used (see note below).
Default: 'regression' for LGBMRegressor, 'binary' or 'multiclass' for LGBMClassifier, 'lambdarank' for LGBMRanker.
"""
# class LGBMClassifier(_LGBMClassifierBase, LGBMModel)......
def fit(self, X, y,
# ......
self._classes = self._le.classes_
self._n_classes = len(self._classes)
if self._n_classes > 2:
# Switch to using a multiclass objective in the underlying LGBM instance
ova_aliases = {"multiclassova", "multiclass_ova", "ova", "ovr"}
if self._objective not in ova_aliases and not callable(self._objective):
self._objective = "multiclass"
# ......
一.轻松实现多分类
1.1导入第三方库、数据集
# 导入第三方库,包括分类模型、数据集、数据集分割方法、评估方法
from lightgbm import LGBMClassifier
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, roc_auc_score, precision_score, recall_score, f1_score, \
classification_report
import lightgbm as lgb
# 导入sklearn的鸢尾花卉数据集,作为模型的训练和验证数据
data = datasets.load_iris()
# 数据划分,按照7 3分切割数据集为训练集和验证集,其中最终4个结果依次为训练数据、验证数据、训练数据的标签、验证数据的标签
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.3,random_state=123)
sklearn的鸢尾花卉数据集共150个数据样本,73切分后,训练集105个数据样本,验证集45个数据样本。数据集中包括 样本特征data(4个特征)、样本标签target(3类标签)、标签名称target_names([‘setosa’, ‘versicolor’, ‘virginica’])、特征名称feature_names([‘sepal length (cm)’, ‘sepal width (cm)’, ‘petal length (cm)’, ‘petal width (cm)’])、以及数据集位置filename(~~~\anaconda\lib\site-packages\sklearn\datasets\data\iris.csv)
数据集的 部分数据 如下:
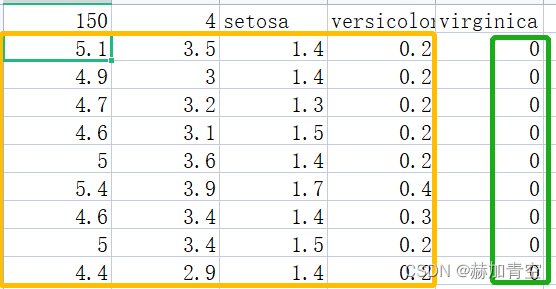
数据集的 标签数据 及 标签名称 如下:
数据集文件所在本地地址
1.2原参数模型训练、验证
# 默认参数的模型
model = LGBMClassifier()
# 模型训练
model.fit(X_train, y_train)
# 模型对验证数据做预测 y_pred 预测结果,y_proba 预测各类别概率,y_pred 是softmax(y_proba) 的结果
y_pred = model.predict(X_test)
y_proba = model.predict_proba(X_test)
# print(y_pred)
# print(y_test.tolist())
# 为了便于观察验证数据的预测结果,写个循环传个参
for m, n, p in zip(y_proba, y_pred, y_test):
if n == p:
q = '预测正确'
else:
q = '预测错误'
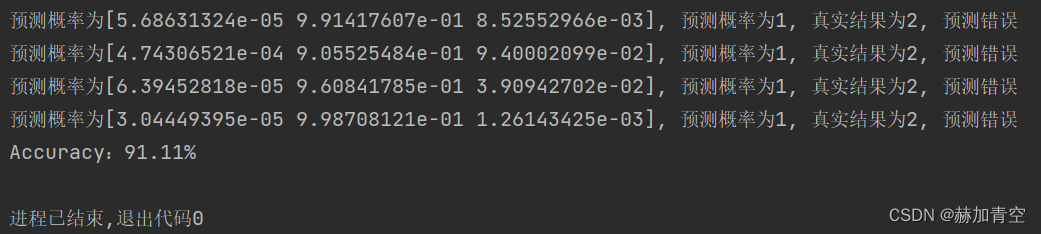
print('预测概率为{0}, 预测概率为{1}, 真实结果为{2}, {3}'.format(m, n, p, q))
# 准确率
accuracy = accuracy_score(y_test, y_pred)
print('Accuracy:%.2f%%' % (accuracy * 100))
打印运行结果如下
1.3修改模型参数、训练、保存、加载、验证
"""修改模型参数"""
model = LGBMClassifier(
boosting_type='dart', # 基学习器 gbdt:传统的梯度提升决策树; dart:Dropouts多重加性回归树
n_estimators=20, # 迭代次数
learning_rate=0.1, # 步长
max_depth=5, # 树的最大深度
min_child_weight=1, # 决定最小叶子节点样本权重和
min_split_gain=0.1, # 在树的叶节点上进行进一步分区所需的最小损失减少
subsample=0.8, # 每个决策树所用的子样本占总样本的比例(作用于样本)
colsample_bytree=0.8, # 建立树时对特征随机采样的比例(作用于特征)典型值:0.5-1
random_state=27, # 指定随机种子,为了复现结果
importance_type='gain', # 特征重要性的计算方式,split:分隔的总数; gain:总信息增益
)
"""模型训练"""
model.fit(X_train, y_train)
"""模型保存"""
model.booster_.save_model('lgb_multi_model.txt')
"""模型加载"""
clf = lgb.Booster(model_file='lgb_multi_model.txt')
# 设置模型的类别数
# 在 LightGBM 中,lgb.Booster 的 load_model() 方法加载的模型默认情况下无法进行 predict_proba() 操作。predict_proba() 方法用于获取预测样本属于各个类别的概率。
# 如需使用 predict_proba() 方法,需要在保存模型时使用参数 num_class 来指定模型的类别数,以便正确加载模型
num_class = n_classes # 假设模型共有两个类别
clf.params['num_class'] = num_class
"""预测验证数据"""
def soft_max(pred, n_class):
if n_class == 2:
max_index = 0 if pred < 0.5 else 1
else:
max_value = max(pred)
max_index = pred.index(max_value)
return max_index
# 结果预测
y_pred = clf.predict(X_test).tolist()
y_pred = [soft_max(y, n_classes) for y in y_pred]
# 预测概率
y_proba = clf.predict(X_test, num_iteration=clf.best_iteration)
# 为了便于观察验证数据的预测结果,写个循环传个参
for m, n, p in zip(y_proba, y_pred, y_test):
if n == p:
q = '预测正确'
else:
q = '预测错误'
print('预测概率为{0}, 预测概率为{1}, 真实结果为{2}, {3}'.format(m, n, p, q))
# 准确率
accuracy = accuracy_score(y_test, y_pred)
print('Accuracy:%.2f%%' % (accuracy * 100))
模型验证结果如下

模型参数可见保存的模型文件 lgb_multi_model.txt

1.4模型调参
这里采用mutual_info_score作为网格搜索GridSearchCV中的多分类调参评分标准,二分类可以使用roc_auc。更详细内容见 附加1 的文章内容,XGBoost调参和LightGBM调参并没有什么两样。
"""模型调参"""
def parameters():
# learning_rate[default=0.3, alias: eta],range: [0,1]
# learning_rate:一般这时候要调小学习率来测试,学习率越小训练速度越慢,模型可靠性越高,但并非越小越好
params = {'learning_rate': [0.01, 0.05, 0.07, 0.1, 0.2, 0.25, 0.3, 0.4]}
# 其他参数设置,每次调参将确定的参数加入
fine_params = {'n_estimators': 20, 'max_depth': 5}
return params, fine_params
def model_adjust_parameters(cv_params, other_params):
# 模型调参
model_ap = LGBMClassifier(**other_params)
# sklearn提供的调参工具,训练集k折交叉验证(消除数据切分产生数据分布不均匀的影响)
optimized_param = GridSearchCV(estimator=model_ap, param_grid=cv_params, scoring='mutual_info_score', cv=5, verbose=1)
# 模型训练
optimized_param.fit(X_train, y_train)
# 对应参数的k折交叉验证平均得分
means = optimized_param.cv_results_['mean_test_score']
params = optimized_param.cv_results_['params']
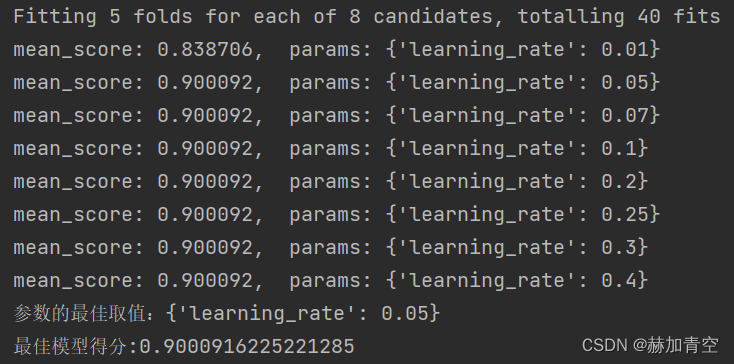
for mean, param in zip(means, params):
print("mean_score: %f, params: %r" % (mean, param))
# 最佳模型参数
print('参数的最佳取值:{0}'.format(optimized_param.best_params_))
# 最佳参数模型得分
print('最佳模型得分:{0}'.format(optimized_param.best_score_))
params_v, fine_params_v = parameters()
model_adjust_parameters(params_v, fine_params_v)
简单调参结果如下:
二.实现二分类同样简单
2.1导入数据集、训练、验证
导入数据集、训练、验证 与多分类完全一样,唯一需要改变的是将数据标签由n_classes>2转为n_classes=2
# 数据划分
X_train, X_test, y_train, y_test = ......
# 接
# 训练集和验证集的标签都改成0和1
y_train = [1 if y > 0 else 0 for y in y_train]
y_test = [1 if y > 0 else 0 for y in y_test]
# 计算训练数据类别
n_classes = len(set(y_train))
# 接
# 默认参数的模型
model = LGBMClassifier()
......
2.2再做模型训练和验证
内容与1.2和1.3完全一致,不再赘述,直接看结果
二分类任务预测概率有两个,预测概率通过sigmoid做出预测结果。多分类预测概率有多个,预测概率通过softmax做出预测结果。
2.3重要结论映证
"""模型保存"""
model.booster_.save_model('lgb_multi_model.txt')
"""模型加载"""
clf = lgb.Booster(model_file='lgb_multi_model.txt')
"""模型参数打印"""
model_params = clf.dump_model()
print('模型参数值-开始'.center(20, '='))
# lightgbm模型参数直接打开模型文件查看更为方便
print(model_params)
print('模型参数值-结束'.center(20, '='))
下图展示 lgb_multi_model.txt 模型参数 objective=binary sigmoid:1 明显区别于多分类任务,映证了最前面的结论。
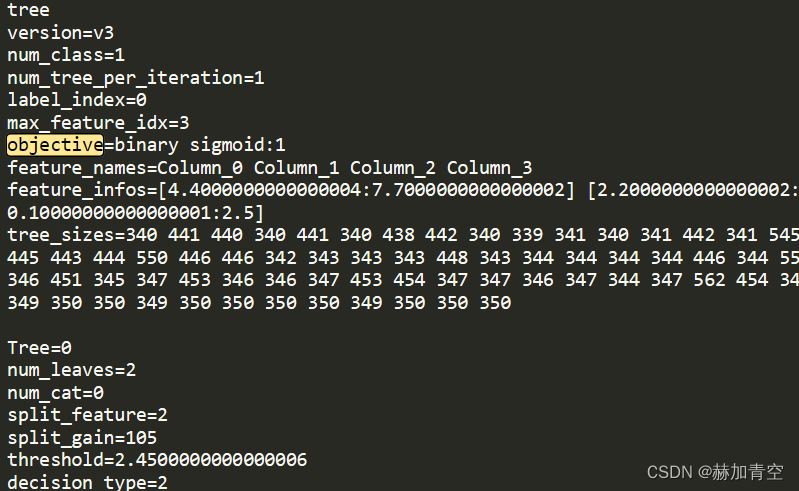
三.模型评估
评估方法更详细解释,见附加3的文章内容
def metrics_sklearn(class_num, y_valid, y_pred_, y_prob):
"""模型效果评估"""
# 准确率
# 准确度 accuracy_score:分类正确率分数,函数返回一个分数,这个分数或是正确的比例,或是正确的个数,不考虑正例负例的问题,区别于 precision_score
# 一般不直接使用准确率,主要是因为类别不平衡问题,如果大部分是negative的 而且大部分模型都很容易判别出来,那准确率都很高, 没有区分度,也没有实际意义(因为negative不是我们感兴趣的)
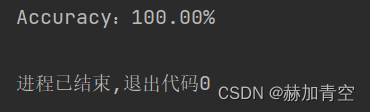
accuracy = accuracy_score(y_valid, y_pred_)
print('Accuracy:%.2f%%' % (accuracy * 100))
# 精准率
if class_num == 2:
precision = precision_score(y_valid, y_pred_)
else:
precision = precision_score(y_valid, y_pred_, average='macro')
print('Precision:%.2f%%' % (precision * 100))
# 召回率
# 召回率/查全率R recall_score:预测正确的正样本占预测正样本的比例, TPR 真正率
# 在二分类任务中,召回率表示被分为正例的个数占所有正例个数的比例;如果是多分类的话,就是每一类的平均召回率
if class_num == 2:
recall = recall_score(y_valid, y_pred_)
else:
recall = recall_score(y_valid, y_pred_, average='macro')
print('Recall:%.2f%%' % (recall * 100))
# F1值
if class_num == 2:
f1 = f1_score(y_valid, y_pred_)
else:
f1 = f1_score(y_valid, y_pred_, average='macro')
print('F1:%.2f%%' % (f1 * 100))
# auc曲线下面积
# 曲线下面积 roc_auc_score 计算AUC的值,即输出的AUC(二分类任务中 auc 和 roc_auc_score 数值相等)
# 计算auc,auc就是曲线roc下面积,这个数值越高,则分类器越优秀。这个曲线roc所在坐标轴的横轴是FPR,纵轴是TPR。
# 真正率:TPR = TP/P = TP/(TP+FN)、假正率:FPR = FP/N = FP/(FP+TN)
# auc:不支持多分类任务 计算ROC曲线下的面积
# 二分类问题直接用预测值与标签值计算:auc = roc_auc_score(Y_test, Y_pred)
# 多分类问题概率分数 y_prob:auc = roc_auc_score(Y_test, Y_pred_prob, multi_class='ovo') 其中multi_class必选
if class_num == 2:
auc = roc_auc_score(y_valid, y_pred_)
else:
auc = roc_auc_score(y_valid, y_prob, multi_class='ovo')
# auc = roc_auc_score(y_valid, y_prob, multi_class='ovr')
print('AUC:%.2f%%' % (auc * 100))
# 评估效果报告
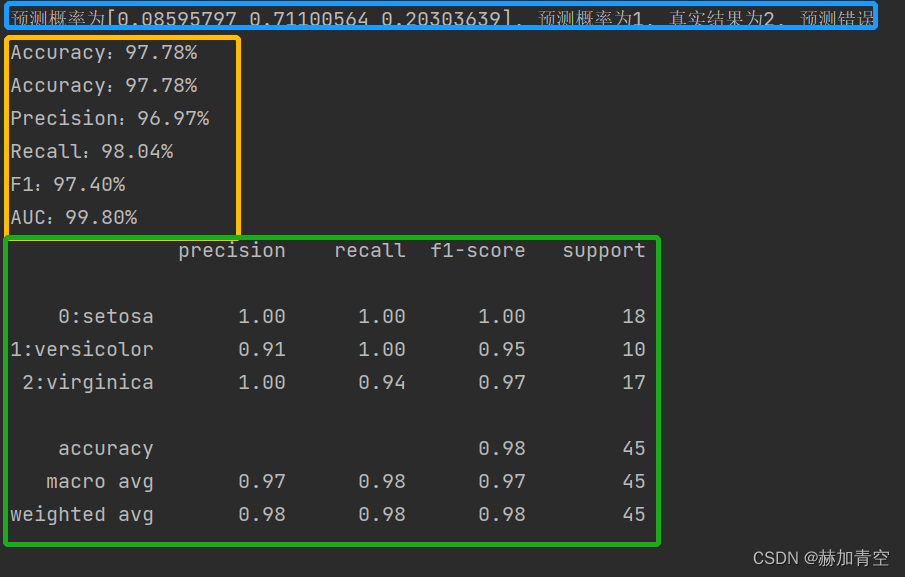
print(classification_report(y_test, y_pred, target_names=['0:setosa', '1:versicolor', '2:virginica']))
"""模型效果评估"""
metrics_sklearn(n_classes, y_test, y_pred, y_proba)
多分类模型效果评估结果入下图所示
本文完整脚本点此链接 百度网盘链接 获取
附加——深入学习XGBoost
附加1.模型调参、训练、保存、评估和预测
见《XGBoost模型调参、训练、评估、保存和预测》 ,包含模型脚本文件
附加2.算法原理
见《XGBoost算法原理及基础知识》 ,包括集成学习方法,XGBoost模型、目标函数、算法,公式推导等
附加3.分类任务的评估指标值详解
见《分类任务评估1——推导sklearn分类任务评估指标》,其中包含了详细的推理过程;
见《分类任务评估2——推导ROC曲线、P-R曲线和K-S曲线》,其中包含ROC曲线、P-R曲线和K-S曲线的推导与绘制;
附加4.模型中树的绘制和模型理解
见《Graphviz绘制模型树1——软件配置与XGBoost树的绘制》,包含Graphviz软件的安装和配置,以及to_graphviz()和plot_trees()两个画图函数的部分使用细节;
见《Graphviz绘制模型树2——XGBoost模型的可解释性》,从模型中的树着手解释XGBoost模型,并用EXCEL构建出模型。
附加5.XGBoost实践
见机器学习实践(1.1)XGBoost分类任务,包含二分类、多分类任务以及多分类的评估方法。
见机器学习实践(1.2)XGBoost回归任务,包含回归任务模型训练、评估(R2、MSE)
❤️ 机器学习内容持续更新中… ❤️
声明:本文所载信息不保证准确性和完整性。文中所述内容和意见仅供参考,不构成实际商业建议,可收藏可转发但请勿转载,如有雷同纯属巧合。