0.briefly speaking
终于到这里了,我们在之前阅读很多地方的内核代码时,总是习惯性地绕开CPU调度的部分(比如yield函数)。现在我们总算可以深入进去一探究竟了,这次总算是将整个操作系统中的一块重要拼图拼上去了。
有操作系统相关基础概念的人应该知道,操作系统的其中一个重要功能是虚拟化(Virtulization)。这是OSTEP(Operating System : Three Easy Pieces,中译名:操作系统导论)提出的操作系统三大主题之一,另外两个是并发(Concurrency)和持久性(Consistency)。虚拟化主要指两个方面,第一是CPU虚拟化(或者广义上理解为计算资源虚拟化),其中一个最重要的方法就是CPU的复用和调度,使得每一个进程都产生了自己独立占有CPU的假象。
第二个方面我们之前已经深入研究过,就是物理内存虚拟化,通过引入页表和请求分页机制,使得操作系统可以动态和灵活地完成虚拟地址到物理地址的映射。这样给每个进程也造成了一种它可以操纵一大片空闲内存的假象,事实上它只占据一小部分真实的物理内存,但虚拟寻址空间却非常大。
最后打一个广告,我想推荐一下上面的OSTEP这本书。这是由威斯康星大学的雷姆兹和安德莉亚夫妇写的一本完全开源免费的操作系统教材。文中以UNIX系统(甚至包括大量Xv6的内核源码)为分析对象,带领大家一点一点拨开操作系统的面纱。如果只让我推荐一本操作系统的教材,那一定会是OSTEP。
言归正传,在Xv6内核中有两种情况会导致CPU发生调度:
- 第一种,也是我们之前就已经见过的,时钟中断导致的当前进程让出CPU使用权,这是一种非常常见的调度算法,我们通常称其为时间片轮转调度算法(Round Robin)
- 第二种,我们在之前研究自旋锁(spinlock)的实现时曾说过,自旋锁是一种十分不经济的做法,它会阻塞式的调用Test&Set原子指令原地等待,进而造成严重的CPU资源空耗。为此Xv6引入了睡眠锁(sleeplock),进而催生出了Sleep&Wakeup机制,在这种机制下也会发生CPU的调度。
这篇文章的关注点是第一种情况,即时钟中断导致的CPU调度,第二种情况我们下一次就会谈到,
本篇博客涉及到要阅读的内核代码如下:
1.kernel/proc.c
2.kernel/swtch.S
3.kernel/main.c
1.填坑——深入理解时钟中断导致的CPU调度(yield)
1.1 回忆——yield何时被触发
我们在有关内核陷阱与时钟中断的博客中讲述了时钟中断的触发和响应过程。它是一种特殊的中断,响应过程分为两个阶段:第一个阶段在M-Mode下首先触发一个S-Mode下的软中断,然后在第二阶段再去响应软中断,通过devintr函数的转发和识别,最终会在usertrap或kerneltrap函数中根据devintr的返回值为2,进而触发yield()函数让出当前CPU的使用权。代码骨架如下(以usertrap为例):
void
usertrap(void)
{
int which_dev = 0;
if(r_scause() == 8){
// system call
} else if((which_dev = devintr()) != 0){
// ok
} else {
// exception
}
if(p->killed)
exit(-1);
// give up the CPU if this is a timer interrupt.
// 译:如果是时钟中断,则让出当前CPU的使用权
if(which_dev == 2)
yield();
// 从用户陷阱中准备返回
usertrapret();
}
我们假设当前有一个进程P响应了这次时钟中断,那么它的控制流就会从上述地方会陷入到yield()函数中,所以接下来故事就到了yield函数中。
1.2 yield函数
yield函数非常简单,代码如下。首先它会获取当前进程以及锁,因为执行操作系统的平台有4+1个核心(1个moniter core和4个application core),所以多个核心在访问进程时也有可能产生并发的问题,故每一个进程结构体也需要锁的保护。所以在修改进程状态为RUNNNABLE时(进程状态本质上维持了一个不变量,它对应到进程的某种状态,修改状态但并未实际进入对应状态之前,我们应该加锁保持不变量的安全性),所以需要首先获取进程的锁。
// Give up the CPU for one scheduling round.
// 译:放弃CPU来开启一个调度轮
void
yield(void)
{
// 获取当前进程并上锁,加锁是为了保护进程状态结构体的访问互斥性
// 防止在修改进程状态时导致的不变量临时为假的情况
// 这个锁在scheduler中被释放(跨进程)
struct proc *p = myproc();
acquire(&p->lock);
// 首先修改进程状态为RUNNABLE
p->state = RUNNABLE;
// 调用sched完成当前进程上下文的保存
// 控制流自此会转向调度(scheduler)线程
sched();
// 进程再次返回时才可以释放之前持有的锁
// 这个锁之前由scheduler函数获取,在这里释放(跨进程)
release(&p->lock);
}
顺带一提,Xv6中进程有6个状态,在这篇以及后面的博客中,我们会看到这些状态之间的切换,如果可以,我会在最后给出这些进程状态切换的概览图。
// Xv6中定义的6个状态
// 未使用、已使用、睡眠、可运行、正在运行、僵尸
enum procstate { UNUSED, USED, SLEEPING, RUNNABLE, RUNNING, ZOMBIE };
1.3 sched——交换旧用户进程和内核进程的上下文
这里在深入研究sched函数之前,我们非常有必要对Xv6中有关上下文切换的一些特殊概念进行说明,比如进程上下文、内核进程等。另外,非常有必要搞明白swtch函数交换的本质是什么,所以本节分为若干小节,对上述问题进行一一说明。
1.3.1 进程上下文(context)
在进入分析sched之前,必须有必要对Xv6的内核线程切换机理做一些简单且必要的说明。我们在操作系统原理中经常说切换进程时要保存和恢复上下文(context),Xv6中也做了相同的工作,有一个结构体context专门用来存放一些通用寄存器,定义如下所示(kernel/proc.h:2):
// Saved registers for kernel context switches.
// 译:内核上下文切换时保存的寄存器
struct context {
// 返回地址寄存器和内核栈指针
// 单独列出来,这是上下文切换的关键
// 它们本质上控制着控制流和内核栈
uint64 ra;
uint64 sp;
// callee-saved
// 译:callee-saved寄存器
// 这些是被调用者应该保存的寄存器
uint64 s0;
uint64 s1;
uint64 s2;
uint64 s3;
uint64 s4;
uint64 s5;
uint64 s6;
uint64 s7;
uint64 s8;
uint64 s9;
uint64 s10;
uint64 s11;
};
这个结构体中声明的s0-s11寄存器属于被调用者保存的寄存器(Callee-Saved Registers),简单插入一些背景知识,在函数调用时寄存器组中的所有寄存器可以分为调用者保存(Caller-Saved)和被调用者保存(Callee-Saved)两种:
- 调用者保存的寄存器,就是在函数调用发生之前,C编译器会自动将本次函数中会用到的寄存器自动入栈保存,等到从函数返回后这些寄存器会自动弹栈恢复,所以被调用者可以在函数内放心使用这些寄存器,之所以不用在context中保存caller-saved registers,就是因为在运行swtch(下面讲到)函数时,编译器自动帮我们将它们做了保存。
- 被调用者保存的寄存器,则需要被调用的函数在函数开头主动将自己会用到的函数入栈保存,在函数功能执行完成返回之前逐一弹栈恢复,最后再返回。RISC-V的标准对不同寄存器的保存职责规定如下:
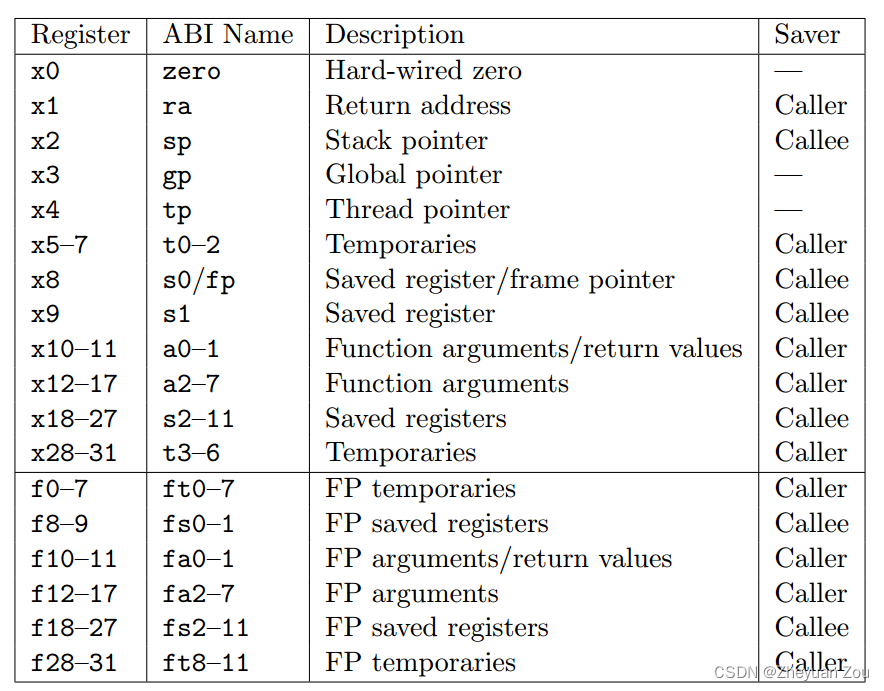
我们可以看到s0-s11都是被调用者保存的寄存器,我们切换到新进程之后一定会用到这些寄存器,所以context保存它们是应该的。保存堆栈指针sp是为了可以在以后进程重新被调度时内核栈可以被成功恢复,保存返回地址ra则是为了让进程恢复调度时指令可以连续执行,因为上下文切换会使得指令流切换到另一个进程中去,所以原有的ra寄存器的内容会被篡改,我们一会儿就会在swtch汇编代码中看到:)
所以我们可以得出这样一个简单的结论:在Xv6中,context = callee-saved registers + ra + sp,虽然我们看过不少操作系统教材,但我第一次如此清晰地认识到何谓进程上下文,我们经常认为进程上下文就是全部寄存器构成的集合,但显然这里推翻了我们的认知。
1.3.2 两次交换来实现线程调度和切换——swtch函数
Xv6中是通过多次交换的方式来实现进程切换的,调用一次swtch函数完成一次交换动作,这是一段汇编写成的代码(kernel/swtch.S:8),如下所示:
# Context switch
#
# void swtch(struct context *old, struct context *new);
#
# Save current registers in old. Load from new.
# 译:上下文切换
# 函数原型如下:void swtch(struct context *old, struct context *new);
# 向old指向的context存放寄存器,从new指向的context加载寄存器
.globl swtch
swtch:
# 向old指向的context存放寄存器
sd ra, 0(a0)
sd sp, 8(a0)
sd s0, 16(a0)
sd s1, 24(a0)
sd s2, 32(a0)
sd s3, 40(a0)
sd s4, 48(a0)
sd s5, 56(a0)
sd s6, 64(a0)
sd s7, 72(a0)
sd s8, 80(a0)
sd s9, 88(a0)
sd s10, 96(a0)
sd s11, 104(a0)
#----------------以上是汇编的前半段---------------------
#----------------以下是汇编的后半段---------------------
# 从new指向的context加载寄存器
ld ra, 0(a1)
ld sp, 8(a1)
ld s0, 16(a1)
ld s1, 24(a1)
ld s2, 32(a1)
ld s3, 40(a1)
ld s4, 48(a1)
ld s5, 56(a1)
ld s6, 64(a1)
ld s7, 72(a1)
ld s8, 80(a1)
ld s9, 88(a1)
ld s10, 96(a1)
ld s11, 104(a1)
# 注意:因为修改了ra寄存器,这里执行ret
# 之后,会切换到新线程上次被调度出去的地方继续执行
# 同时因为修改了sp寄存器,内核栈也切换到了新的进程内核栈
ret
这里的代码逻辑似乎看上去很清晰,无非是存了一批寄存器,载入了一批寄存器。其中ra寄存器和sp寄存器是最重要的部分,它们的切换本质上完成了控制流和内核栈的切换。但上述这段代码实质上涉及到三个进程上下文,一个硬件上下文,两个软件上下文(其中有一个是特殊的内核进程的上下文)。
内核进程在Xv6中是独立于应用进程组proc(kernel/proc.c:11)的特殊进程,拥有独立的、静态分配的内核栈stack0(kernel/start.c:11),并且和CPU内核强绑定(比如,内核进程的上下文存放在cpu结构体中,而不像普通的进程一样存放在proc结构体中)。它在启动时就开始运行并完成本核心的初始化任务,在系统启动完成之后则作为调度进程,参与本CPU调度的中间过程,挑选下一个要调度的新进程并完成进程切换。
转回swtch函数,首先要有一个概念,上述我们所说的context是一个软件概念,对应的存储空间在内存里。而CPU硬件核心内部本身也有一个寄存器组,而这是由硬件实现的,如果将Xv6的整个进程切换过程绘制成更加通俗易懂的图片,会是这样:
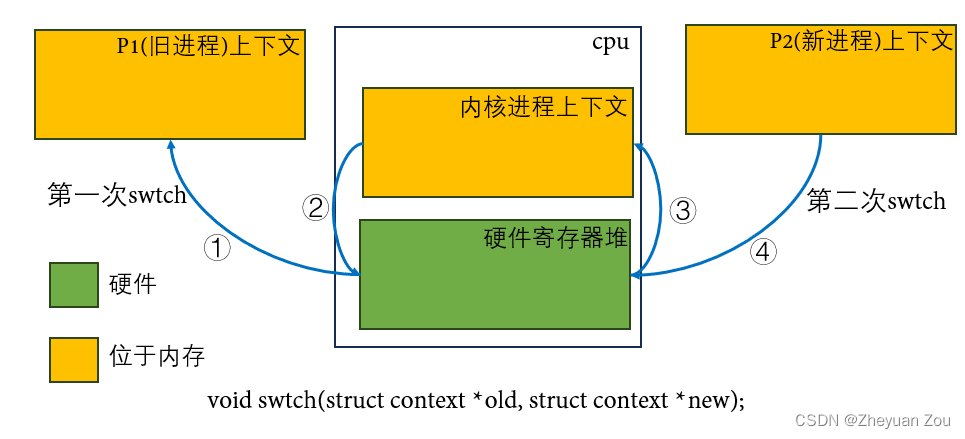
- ①:在发生调度之前,旧进程P1的上下文正占据着CPU核心中的硬件寄存器堆,在执行着自己的逻辑。发生调度之后,swtch的第一个动作(对应于汇编的前半段),就是将原本正在硬件寄存器堆中执行的上下文存回位于内存的P1上下文结构体中。
- ②:CPU将内核进程的上下文载入硬件寄存器堆,开始调度过程,这对应于swtch代码的后半段。
- ③:调度器找到了合适的可以调度的进程,内核进程再次被换出,硬件寄存器堆中的值被存回内核进程上下文,这对应于第二次调用swtch时前半段代码做的事情。
- ④:新进程上下文被载入硬件寄存器堆,这对应于第二次调用swtch时后半段代码,自此核心开始在新进程上运行。
所以,Xv6中通过上述的两次交换过程(两次swtch)成功实现了进程的调度和切换,下面我们从代码的角度形式仔细研究一下上图中涉及到的细节。
1.3.3 sched函数的实现(第一次swtch)
回到大标题,下面我们再来看sched函数的实现,sched函数的代码逻辑还是非常简单的,首先它做了一系列的合法性检查,随后它记录了当前CPU在进行调度之前的原始中断状态以备返回时恢复,随后调用swtch函数,成功将控制流切换到内核线程,在那里将进行线程的选择和调度。
// Switch to scheduler. Must hold only p->lock
// and have changed proc->state. Saves and restores
// intena because intena is a property of this
// kernel thread, not this CPU. It should
// be proc->intena and proc->noff, but that would
// break in the few places where a lock is held but
// there's no process.
// 译:切换到scheduler线程,必须持有旧进程的锁
// 并且已经改变了进程的执行状态
// 保存并恢复intena,intena是内核线程的属性,而不是CPU的属性
// 这本来应该是proc->intena和proc->noff表示的,但在有些罕见情况下
// 比如持有锁却无进程可以调度时,这个规律是不成立的
void
sched(void)
{
int intena;
struct proc *p = myproc();
// sched函数会先做一系列的合法性检查
// 是否持有当前进程的锁
if(!holding(&p->lock))
panic("sched p->lock");
// 锁链长度是否为1
// 这是为了确认当前CPU除了持有当前进程锁之外
// 释放了其他所有的的锁
if(mycpu()->noff != 1)
panic("sched locks");
// 如果当前进程状态为仍在运行,则出错
if(p->state == RUNNING)
panic("sched running");
// 中断是否关闭?事实上,在我们成功获取进程锁之后
// 在正常情况下中断就已经关闭了
if(intr_get())
panic("sched interruptible");
// 记录当前CPU原始的中断开关状态
// 新进程可能会影响这个标志
intena = mycpu()->intena;
// 第一次调用swtch,换入内核线程,并换出当前的旧线程
// 请注意:旧进程下一次再次被调度时,应当从下一行代码开始执行
swtch(&p->context, &mycpu()->context);
// 下一次再次返回时恢复进程在此CPU的原始中断开关状态
mycpu()->intena = intena;
}
1.4 新进程的调度与换入——scheduler函数(第二次swtch)
上面的故事中,我们的控制流成功切换到了内核进程中,那么内核进程将会从哪里开始执行呢?这里我们先给出一个结论,从scheduler函数中的一个地方开始,你可能会问,内核进程的代码是怎么会在scheduler函数中等着呢?这是我们在第二大部分(回溯——故事的开始)要详细讲的部分,这里先卖个关子:)
我们研究一下scheduler函数(kernel/proc.c:437)的实现,这个函数中有很多需要我们仔细琢磨的地方,我会在下面展开讲解,首先给出完整的代码展示和注释:
// Per-CPU process scheduler.
// Each CPU calls scheduler() after setting itself up.
// Scheduler never returns. It loops, doing:
// - choose a process to run.
// - swtch to start running that process.
// - eventually that process transfers control
// via swtch back to the scheduler.
// 译:每个CPU都有一个的进程的调度器
// 每个CPU都会在初始化完成之后调用scheduler()函数
// scheduler函数永不返回,而是保持死循环做以下事情:
// -选择一个进程执行
// -调用swtch(第二次调用swtch)来执行新进程
// -最终进程会将控制权通过swtch再次转回scheduler(即下一次调度)
void
scheduler(void)
{
// 获取当前CPU,这是在系统完成初始化首次
// 进入此函数时才会执行的代码
struct proc *p;
struct cpu *c = mycpu();
// 设置当前CPU核心正在运行的进程为空
// 这条设置至关重要,它保证了内核进程不会被时钟中断打断
// 事实上在系统刚启动时,所有核心都没有进程在运行
c->proc = 0;
// 永不退出的死循环
for(;;){
// Avoid deadlock by ensuring that devices can interrupt.
// 译:通过允许设备中断来避免死锁
// 这个地方非常的细节和困难,分成两个部分来说:
// 1.假设当前进程组中有一个进程,它正好沉睡着等待一个设备中断:
// 一个典型的例子是在我们之前讲的串口通信中的uartputc函数
// 一个进程可能会发现当前UART发送缓冲区已满,而开始睡眠并让出CPU
// 这时候它在等待一个uartstart函数来唤醒它
// 因为uartstart函数可以读取发送缓冲区中的字符并让出空间
// 此时只有允许设备中断(uart中断),才可以在uartintr函数中调用uartstart函数
// 进而唤醒这个进程,否则这个进程会一直沉睡下去
// 2.你可能会问,那时钟中断会打断这个内核进程吗?内核进程会发生自交换吗?
// 事实上,在内核陷阱程序kerneltrap中调用yield前
// 会首先判断当前是否是内核进程在执行(myproc()!=0)
// 所以内核线程不会触发yield()函数
intr_on();
// 扫描一次进程组,找出其中可以被调度的进程
for(p = proc; p < &proc[NPROC]; p++) {
// 调度之前先获取此进程的锁
// 这个锁将会在返回新进程的yield时释放(跨进程)
acquire(&p->lock);
if(p->state == RUNNABLE) {
// Switch to chosen process. It is the process's job
// to release its lock and then reacquire it
// before jumping back to us.
// 译:切换到选中的进程,释放它自己的锁
// 并在下次跳回到本函数之前再次获取锁都是进程本身的职责
// 修改进程状态,并调用swtch(第二次调用)
// 此时新进程将被调度
p->state = RUNNING;
c->proc = p;
swtch(&c->context, &p->context);
// Process is done running for now.
// It should have changed its p->state before coming back.
// 译:进程至此已经完成运行
// 它应该在返回之前将其状态p->state改变
// c->proc=0表示运行在内核进程
c->proc = 0;
}
// 释放yield函数中持有的进程锁,否则可能导致死锁(跨进程)
release(&p->lock);
}
}
}
上述函数的乍看上去非常简单,但是其中值得细究的点非常多。简单来说这个函数实现了CPU的调度,但是调度算法非常的朴素,就是一次次遍历进程组,找出其中第一个满足RUNNABLE状态的进程开始调度。每一次循环都会接着上一次结束的位置向后扫描,这样保证了相对公平性,否则ID号小的进程就会被持续调度。
除此之外有两个难点需要我们注意,如下:
1.4.1 注意点1——scheduler与yield中的跨进程锁机制
scheduler函数和yield函数中出现了不同寻常的锁机制,它首先由一个进程获取锁,而由另外一个进程释放。将这个过程画成图片效果如下:

旧进程在让出当前CPU时,首先要获取进程的锁,防止并发错误。然后通过sched函数会调度到内核进程,内核进程恢复的地方正是上一次退出的地方(即:c->proc=0是即将执行的指令)。接下来内核进程的操作就是释放锁(release(&p->lock)),这个所谓的p正是之前在CPU上运行的旧进程。
你也许对此感到费解,甚至质疑这个结论的正确性,那么我们想一想如果不释放或者释放的是其他进程而不是旧进程的锁会怎么样?让我们假设这样一种场景,当前系统中只有一个进程可以执行,如果这里不释放进程锁。那么当内核进程扫描进程组的时候,它会发现这个唯一可以调度的进程,并尝试获取它的锁,进而与yield函数冲突而陷入死循环。我们知道Xv6内核是相对正确的,所以上述这种情况不成立,反证法可知这里释放的就是旧进程的锁。
同样的,scheduler()在尝试调度一个新进程之前也会先获取它的锁,这把锁在返回新进程执行时,将会在新进程返回到yield()函数处时释放这把由内核进程加上的锁,这种跨进程的锁机制使用非常少见,这里值得引起我们的重视。
1.4.2 注意点2——scheduler函数中的开中断动作
注意内核线程并不一定一直在scheduler中执行,因为它开了中断。开中断是非常有必要的行为,否则可能会引起死锁,具体例子我们在上述代码中已经举例过了,这里不再赘述。值得注意的地方在于,开中断也会响应时钟中断,时钟中断可能会让出当前CPU。
在内核陷阱kerneltrap中,是如下这样处理的(kernel/trap.c:152),它会使得内核进程不响应时钟中断,进而很好地规避了这个问题:
// interrupts and exceptions from kernel code go here via kernelvec,
// on whatever the current kernel stack is.
void
kerneltrap()
{
// 以上代码从略...
// give up the CPU if this is a timer interrupt.
// 译:如果是时钟中断则放弃当前CPU
// 注意这里判断了myproc() != 0,筛去了内核进程的可能
if(which_dev == 2 && myproc() != 0 && myproc()->state == RUNNING)
yield();
// 以下代码从略...
}
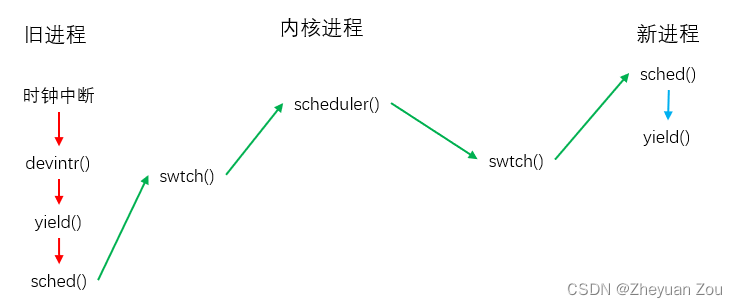
1.5 概览——时钟中断导致的CPU调度
给出一张图来表示完整的调度流程,如下:
2.回溯——故事的开始
上面我们卖了一个关子,那就是内核进程为何会一直在scheduler函数中等待。这是所有问题的源头,事实上这部分代码在main.c种可以相对容易地看见。我们转入文件kenrel/main.c,执行main函数的进程都是内核进程,我们可以在下面的代码中看到,monitor core和application core在最后都会转入scheduler函数。所以后面我们因为时钟中断而让出CPU时,内核进程会一直在scheduler函数中等待着我们。至此,整个故事就完全完整了。
// start() jumps here in supervisor mode on all CPUs.
void
main()
{
if(cpuid() == 0){
// monitor core负责整个操作系统的初始化
// 此处详细步骤从略
started = 1;
} else {
// application core的初始化步骤
while(started == 0)
;
__sync_synchronize();
printf("hart %d starting\n", cpuid());
kvminithart(); // turn on paging
trapinithart(); // install kernel trap vector
plicinithart(); // ask PLIC for device interrupts
}
// 无论是monitor core还是application core上的内核进程
// 自此都转入scheduler函数,在scheduler函数中偶尔的中断并不会让
// 内核进程让出当前CPU,它会一直扫描可以调度的用户进程
scheduler();
}