1. JDK 1.8 主要进行了哪些优化?
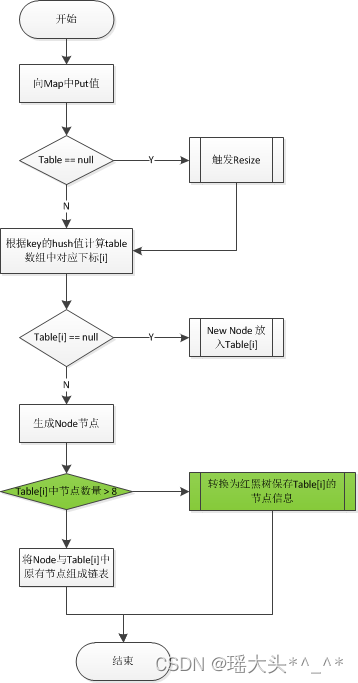
1)底层数据结构从“数组+链表”改成“数组+链表+红黑树”,主要是优化了 hash 冲突较严重时,链表过长的查找性能:O(n) -> O(logn)。
2)计算 table 初始容量的方式发生了改变,老的方式是从1开始不断向左进行移位运算,直到找到大于等于入参容量的值;新的方式则是通过“5个移位+或等于运算”来计算。
// JDK 1.7.0
public HashMap(int initialCapacity, float loadFactor) {
// 省略
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
// ... 省略
}
// JDK 1.8.0_191
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
3)优化了 hash 值的计算方式,老的通过一顿瞎JB操作,新的只是简单的让高16位参与了运算。
// JDK 1.7.0
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
// JDK 1.8.0_191
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
4)扩容时插入方式从“头插法”改成“尾插法”,避免了并发下的死循环。
5)扩容时计算节点在新表的索引位置方式从“h & (length-1)”改成“hash & oldCap”,性能可能提升不大,但设计更巧妙、更优雅。
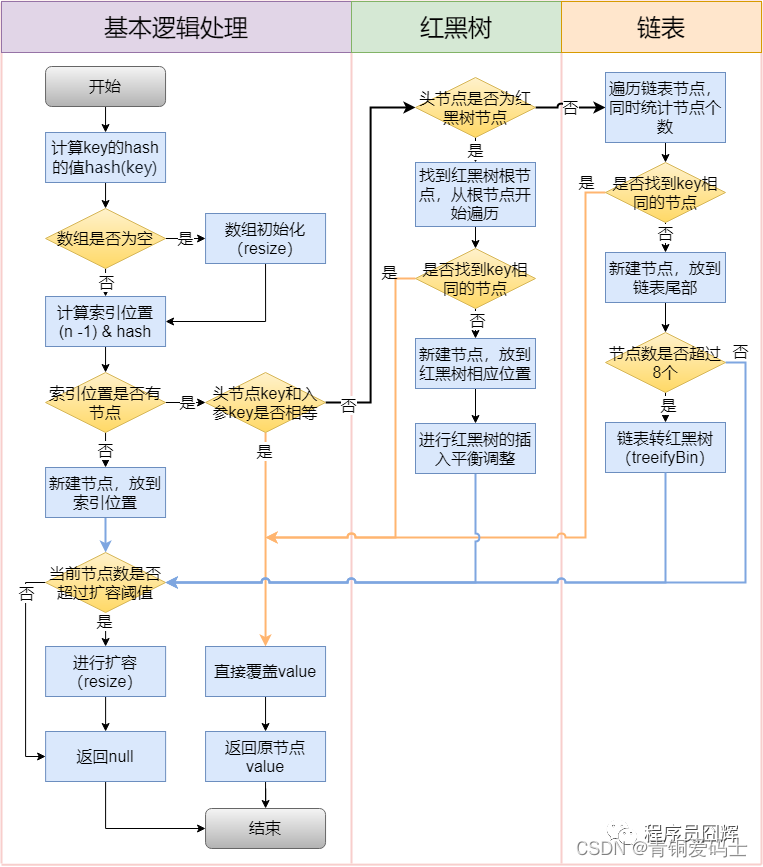
2. put流程
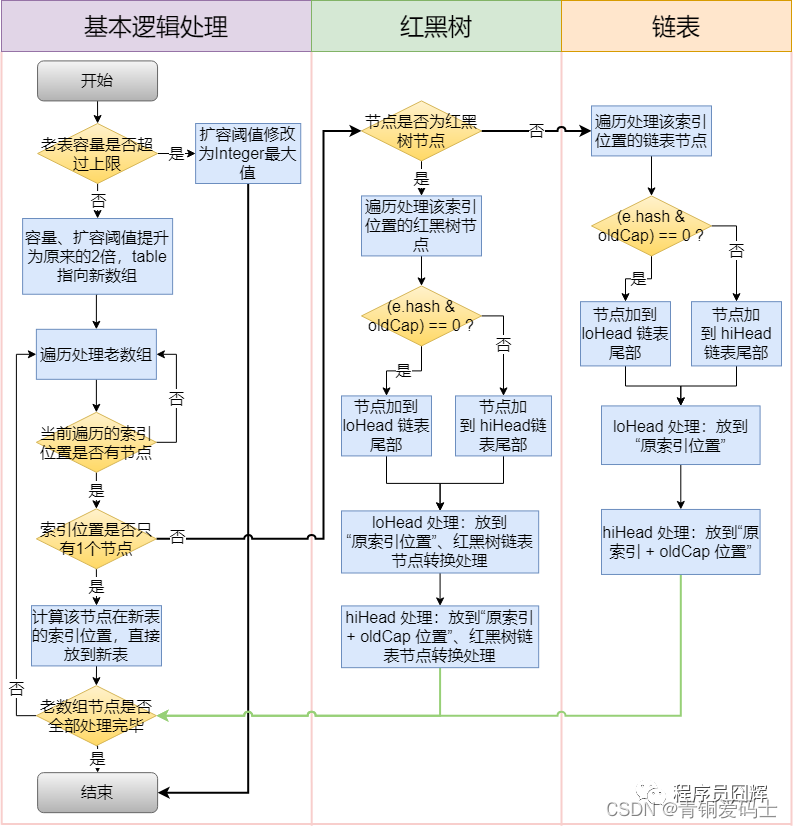
3. 扩容
4. HashMap 的容量必须是 2 的 N 次方,这是为什么?
(n - 1) & hash,当 n 为 2 的 N 次方时,n - 1 为低位全是 1 的值,此时任何值跟 n - 1 进行 & 运算的结果为该值的低 N 位,达到了和取模同样的效果,实现了均匀分布。实际上,这个设计就是基于公式:x mod 2^n = x & (2^n - 1),因为 & 运算比 mod 具有更高的效率。
5. HashMap是线程安全问题
在多线程环境下,1.7 会产生死循环、数据丢失、数据覆盖的问题,1.8 中会有数据覆盖的问题,以1.8为例,当A线程判断index位置为空后正好挂起,B线程开始往index位置的写入节点数据,这时A线程恢复现场,执行赋值操作,就把A线程的数据给覆盖了;还有++size这个地方也会造成多线程同时扩容等问题。
6. 解决线程不安全的问题
HashTable、Collections.synchronizedMap、以及ConcurrentHashMap可以实现线程安全的Map。
HashTable是直接在操作方法上加synchronized关键字,锁住整个数组,粒度比较大,
Collections.synchronizedMap是使用Collections集合工具的内部类,通过传入Map封装出一个SynchronizedMap对象,内部定义了一个对象锁,方法内通过对象锁实现;
ConcurrentHashMap使用分段锁,降低了锁粒度,让并发度大大提高。