目录
1.赛题简介
1.1.赛题目标
1.2.地图介绍
1.3.规则介绍
2.环境介绍
2.1.观测空间(Observation Space)
2.1.1.原始数据:
2.1.2.特征数据
2.1.3.特征提取
2.2.动作空间(Action Space)
2.3.坐标介绍(Coordinate)
2.4.玩法配置(Setup)
2.5.积分规则(Score)
2.6.奖励机制(Reward)
3.代码包介绍
3.1.目录介绍
3.2.代码入口&流程介绍
3.3.建议修改的代码
3.4.网络结构
3.5.重要API介绍
3.5.1.Class DQNModel
3.5.2.Class Game
4.训练介绍
4.1.监控介绍
4.1.1.查看监控
4.1.2.Algorithm - DQN
4.1.3.查看日志
5.代码更新说明
6.KaiwuDRL强化学习框架
6.1.简介
6.2.Gamecore & Battle Server
6.3.AI Server
6.4.Actor/Learner
6.5.Model pool
1.赛题简介
1.1.赛题目标
峡谷漫步v1场景的目标是:通过算法训练一个智能体,让其在对地图不断的探索中学习移动策略,减少碰撞障碍物,以最少的步数从起点走到终点并且收集宝箱。
本赛题支持的框架为:
PyTorch是一个开源的机器学习框架。
PyTorch是一个由Facebook开发的深度学习框架,它主要针对GPU加速的深度神经网络(DNN)编程,并且可以用于其他数学密集型应用2。
PyTorch的特点:
-
简洁:PyTorch的设计追求最少的封装,尽量避免重复造轮子。
-
可以顺畅的在 eager 和 graph 模式下切换。
-
加速了科研到生产的道路。
本赛题支持的算法为:DQN
DQN算法指深度Q网络(Deep Q-network),是一种基于深度学习的Q-Learing算法。
DQN算法原理是将强化学习任务所面临的状态空间是连续的,存在无穷多个状态,这种情况就不能再使用表格的方式存储价值函数。在这种情况下,我们可以用一个函数Q(s,a;w)来近似动作-价值Q(s,a),这个函数是由神经网络来生成的,称为Q网络(Deep Q-network),其中w是神经网络训练的参数。
1.2.地图介绍
峡谷漫步v1使用64*64的网格化的地图(智能体每步移动的距离是一网格),地图中包含起点、终点、道路、障碍物和宝箱。

1.3.规则介绍
本赛题的基本目标是控制智能体,使用尽量少的步数,从起点走到终点,并且尽可能多的收集宝箱。
在地图中,智能体没有全图视角,通过向前、后、左、右四个方向移动进行试探,遇到障碍物时无法继续前进,需要调整方向开启新的试探。任务启动时,地图中会随机出现宝箱,智能体通过探索可以获得宝箱里的奖励。
训练过程中,若在最大步数内没有走到终点,则判定为任务超时(即超过最大步数后智能体仍未走到终点,最大步数默认为2000)。
这是局部的判断,智能体只能看到周围的事物,不能观察到全局的。
智能体只能上下左右4个方向进行移动,遇到障碍物无法移动。
2.环境介绍
2.1.观测空间(Observation Space)
2.1.1.原始数据:
以下是从环境中获取的原始数据:
| 数据名 | 数据类型 | 数据描述 |
|---|---|---|
| step_no | int32 | 当前步数 |
| heroes | GorgeWalkHero | 英雄信息 |
| organs | GorgeWalkOrgan | 物件信息 |
| score | int32 | 每一步的即时得分 |
| total_score | int32 | 累计得分 |
其中 GorgeWalkHero 和 GorgeWalkOrgan 的数据类型定义如下
| GorgeWalkHero | 数据类型 | 数据描述 |
|---|---|---|
| hero_id | int32 | 英雄ID(默认使用鲁班) |
| treasure_count | int32 | 收集到的宝箱数量 |
| pos | (int32, int32) | 英雄位置坐标 |
峡谷漫步v1不支持更换英雄,所以hero_id默认固定为112(鲁班七号)
| GorgeWalkOrgan | 数据类型 | 数据描述 |
|---|---|---|
| sub_type | int32 | 物件类型(目前只有“宝箱”一种) |
| config_id | int32 | 物件ID |
| pos | (int32, int32) | 物件位置坐标 |
| status | bool | 物件状态(1已收集, 0未收集) |
| reward | int32 | 物件奖励 |
sub_type用来区分物件的类型,比如宝箱,buff,防御塔等。峡谷漫步v1只支持宝箱,所以sub_type默认固定为1
2.1.2.特征数据
GorgeWalkFeature是对原始数据经过简单的特征处理得到的特征信息(包含位置信息,宝箱收集信息,视野域信息)。不同算法所使用的特征不尽相同,比如像Q-learning这类value-based的TD算法,更倾向于使用整型的网格坐标作为状态之一;而像DQN这类深度强化学习算法涉及到微分计算,则倾向于使用浮点数的位置坐标,另外一种方式是采用one-hot vector的形式来表征位置。总而言之,下面列出的特征只是为同学们提供一个参考,除了直接使用提供的特征以外,建议同学们通过原始数据生成自己需要的特征。
| GorgeWalkFeature | 数据类型 | 数据维度 | 数据描述 |
|---|---|---|---|
| positions | PositionPack | 2*3=6 | 位置信息 |
| treasure | int32的list | 10 | 宝箱收集信息(1表示可收集,0表示不可收集) |
| feature_map | FeatureMap | 25*3=75 | 视野域的特征图 |
| location_memory | float | 64x64=4096 | 地图探索的历史记忆 |
下面是对三种特征更详细的描述:
位置信息
| PositionPack | 数据类型 | 数据维度 | 数据描述 | 举例 |
|---|---|---|---|---|
| position | (int32, int32) | 2 | 网格坐标 | (29, 9) |
| pos_norm | (float32, float32) | 2 | 归一化后的网格坐标 | (0.453125, 0.140625) |
| pos_polar | (float32, float32) | 2 | 归一化后的极坐标 | (0.335483, 0.191572) |
对于坐标的介绍请查看坐标介绍。
宝箱收集信息
峡谷漫步v1的宝箱总共有10个可能出现的位置,每个位置对应了一个config_id(即宝箱id)。宝箱收集信息(treasure)是一个长度为10的list,宝箱的config_id对应了该宝箱在list里的index。初始状态时,treasure为[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],当游戏启动时,会随机生成宝箱,生成的宝箱状态会变为1。比如前5个宝箱被生成了,那treausre为[1, 1, 1, 1, 1, 0, 0, 0, 0, 0], 假如宝箱2和宝箱4被收集,则treasure变为[1, 1, 0, 1, 0, 0, 0, 0, 0, 0]。
视野域信息
| FeatureMap | 数据类型 | 数据维度 | 数据描述 |
|---|---|---|---|
| obstacle_map | bool的list | 5*5=25 | 障碍物信息 |
| treasure_map | bool的list | 5*5=25 | 宝箱信息 |
| end_map | bool的list | 5*5=25 | 终点信息 |
视野域是指以英雄所在位置为中心,分别向上下左右四个方向拓宽VIEW(default=2)格数的一个正方形观察域(defualt=5x5)。
视野域中会标注出障碍物、宝箱、终点的位置,分别存储在obstacle_map, treasure_map, end_map三个向量中。以obstacle_map为例,VIEW=2时,obstacle_map向量长度为25,是5x5的矩阵视野域的一维展开,有阻挡的位置为1,无阻挡的位置为0。
历史记忆信息
为了避免多余的探索加速模型的训练,可以考虑加入智能体对环境探索的历史记忆信息,用一个64x64的矩阵来表示。矩阵里的每一个元素对应的就是地图里的一个坐标,值限制在[0, 1],初始化为0。智能体每走到一个位置,该坐标下的值+0.1,最大为1,即到达同一位置的次数大于等于10。
2.1.3.特征提取
特征的使用见仁见智,不同的算法特征也不尽相同,下面的特征输入仅供参考,相关的代码参见app/gorge_walk/env/gorge_walk_state.py里的parse_from_proto_to_state(req_pb)函数
| Feature | 数据类型 | 数据维度 | 数据描述 |
|---|---|---|---|
| pos_row | one-hot list | 64 | 位置信息-行 |
| pos_col | one-hot list | 64 | 位置信息-列 |
| obstacle_map | int list | 5*5=25 | 障碍物信息(Local) |
| treasure_map | int list | 5*5=25 | 宝箱信息(Local) |
| walked_map | int list | 5*5=25 | 历史信息(Local) |
| list_treasure | int list | 10 | 宝箱收集信息 |
向量特征
-
坐标:采用64*2的one-hot list的方式来表示位置信息
# 横坐标 pos_row = [0] * 64 pos_row[int(pos.x)] = 1 observation.extend(pos_row) # 纵坐标 pos_col = [0] * 64 pos_col[int(pos.z)] = 1 observation.extend(pos_col)
-
宝箱: 采用一个10维的list来表示宝箱收集信息
list_treasure = req_pb.ai_req.frame_state.features.treasure observation.extend(list_treasure)
矩阵特征
-
特征图:采用3个5*5的矩阵来表示障碍物,宝箱,以及历史记忆信息的局部观察信息,分别存储在obstacle_map, treasure_map, walked_map中。
observation = list() feature_map = req_pb.ai_req.frame_state.features.feature_map # 局部障碍物信息 obstacle_map = feature_map.obstacle_map observation.extend([0 if x == False else 1 for x in obstacle_map]) # 局部宝箱信息 treasure_map = feature_map.treasure_map observation.extend([0 if x == False else 1 for x in treasure_map]) # 长度为64x64=4096的一维向量,记录了地图探索的历史记忆,value=min(1, count/10) location_memory = req_pb.ai_req.frame_state.features.location_memory # 局部历史记忆信息 walked_map = list() for i in range(5): idx_start = (x - 2 + i) * 64 + (z - 2) walked_map.extend( [1 if k != 0 else 0 for k in location_memory[idx_start:idx_start+5]])
-
特征提取(神经网络):利用神经网络的特征提取和抽象的能力进行特征提取,当前示例将向量特征concat起来,仅使用全连接网络进行特征提取,当然也可以使用CNN等技术进行特征提取。这部分的代码参见
app/gorge_walk/algorithm/torch_network.py
self.layers = [ nn.Linear(np.prod(state_shape), 256), nn.ReLU(inplace=True)] self.layers += [nn.Linear(256, 256), nn.ReLU(inplace=True)] self.layers += [nn.Linear(256, 128), nn.ReLU(inplace=True)]
2.2.动作空间(Action Space)
峡谷漫步v1的动作空间非常简单,仅仅只有上下左右四个动作,操作智能体以网格为单位进行四个方向的移动,每次移动一格。
合法指令包含:
['UP', 'DOWN', 'RIGHT', 'LEFT', 0, 1, 2, 3]
对应关系如下
UP = 0; // 向上移动一格 DOWN = 1; // 向下移动一格 LEFT = 2; // 向左移动一格 RIGHT = 3; // 向右移动一格
2.3.坐标介绍(Coordinate)
峡谷漫步v1中共有两种坐标:绝对坐标和网格坐标
注意,这里不考虑y轴,所有的二维坐标均默认为[x, z]
绝对坐标:指智能体在网格化之前的地图中的坐标,地图左上角为原点[0,0]
网格坐标:是相对坐标,指将地图网格化之后生成的坐标,地图左下角为原点[0, 0],对应的绝对坐标为[0, -64000]
坐标间的换算:
以起点位置为例,绝对坐标 = [x, z] = [29500, -54500]
网格坐标 = [x', z'] = [29, 9]
[x', z'] = [x/1000 - 0.5, z/1000 + 63.5] [x′,z′]=[x/1000−0.5,z/1000+63.5]
[x, z] = [(x' + 0.5) * 1000, (z' - 63.5) * 1000] [x',z]=[(* x * ′+0.5)∗1000,(z′−63.5)∗1000]
2.4.玩法配置(Setup)
以下坐标均为网格坐标,宝箱后的数字为宝箱的config_id
| 描述(description) | 网格坐标(grid position) | 分数(score) |
|---|---|---|
| 起点(start) | [29, 9] | 0 |
| 终点(end) | [11, 55] | 150 |
| 宝箱-0 | [19, 14] | 50 |
| 宝箱-1 | [9, 28] | 100 |
| 宝箱-2 | [9, 44] | 100 |
| 宝箱-3 | [42, 45] | 100 |
| 宝箱-4 | [32, 23] | 50 |
| 宝箱-5 | [49, 56] | 200 |
| 宝箱-6 | [35, 58] | 100 |
| 宝箱-7 | [23, 55] | 50 |
| 宝箱-8 | [41, 33] | 100 |
| 宝箱-9 | [54, 41] | 150 |
游戏启动时的一个必要参数为treasure_num,指该局游戏宝箱的数量,默认n = 5n=5。然后从宝箱池(N=10)中不重复地随机抽取n个宝箱作为这局游戏的可收集宝箱。
2.5.积分规则(Score)
游戏环境会实时反馈出智能体的总分数,初始分数为0,分数的计算基于以下三个规则
-
宝箱积分:每获得一个宝箱,便能增加该宝箱对应的积分,宝箱积分的大小与获取难度相关,范围在[50, 200]
-
终点积分:到达终点+150积分
-
步数积分:当智能体到达终点后,根据剩余的步数额外增加积分,计算公式如下:
步数积分 = 剩余步数 * 奖励系数(0.2), 其中 剩余步数 = 最大步数 - 完成步数
注意:以上的得分属于环境给出的游戏得分,积分是游戏用于衡量玩家在游戏中的表现,也作为衡量强化学习训练后的模型的优劣,与强化学习里的奖励要区别开。
2.6.奖励机制(Reward)
这里的奖励指强化学习中的Reward,reward的设计以及权重的分配一直都是强化学习里的重要一环,我们这里提供三个思路:
-
直接使用游戏的得分作为Reward
-
修改积分规则的奖励值,将修改后的即时得分作为Reward
-
自定义Reward(下面提供几个思路)
-
游戏的三种积分已经体现了对于宝箱,终点,以及更少步数这三点的奖励
-
撞墙惩罚:如果撞墙要给予负奖励
-
重复探索惩罚:如果反复探索已经探索过的区域要给予负奖励
-
距离奖励:可以通过判断连续两帧与终点的距离差值来给予奖励或惩罚
-
注意:峡谷漫步v1的游戏环境非常简单,我们鼓励同学们在算法侧自己去定义Reward,如果遇到了数据不足的情况请及时与我们沟通,我们非常愿意为同学们提供更加丰富的数据来支持多样化的Reward
3.代码包介绍
3.1.目录介绍
本实验代码包的根目录下有两个子目录:
app/gorge_walk为主要代码目录,包括:
-
algorithm: 强化学习中的模型和算法,
torch_network.py实现了神经网络模型,torch_dqn_model.py实现了DQN算法。 -
env: 对应于强化学习里的Environment,包含了特征处理(feature_process),样本处理(sample_process),协议(protocl)等等。
-
tools: 工具集合。
conf/gorge_walk_v1为配置文件,主要为一些配置参数。
3.2.代码入口&流程介绍
整体框架的流程及详细内容可以查看强化学习框架部分,这里简单讲解一下峡谷漫步v1代码的入口以及流程。
下图是Battlesrv的主要逻辑实现,battlesrv也是整个流程的发起者。其中NatureClient作为中间件,负责沟通game core和AI Server。
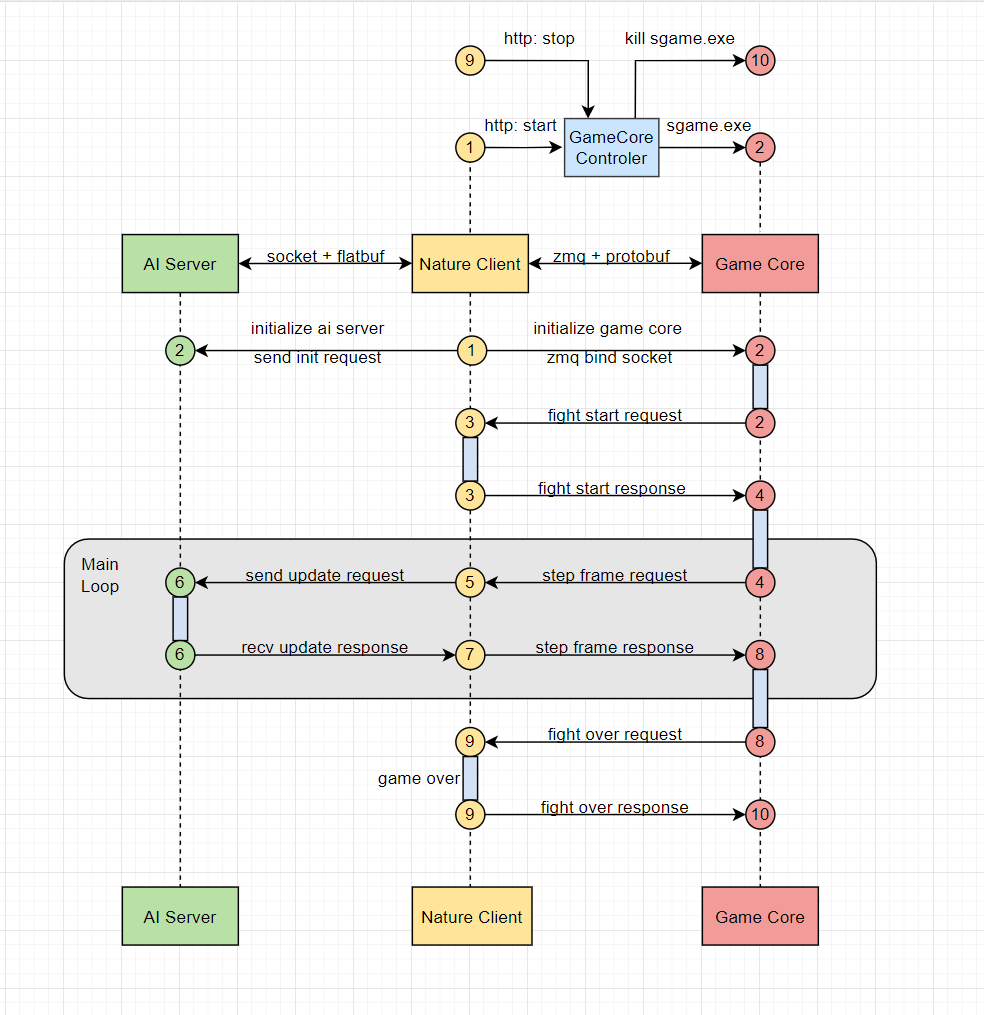
如果感兴趣具体的实现细节,可以按照以下顺序阅读代码:
-
app/gorge_walk/env/client/battlesrv.py
battlesrv的主要功能是调用NatureClient,开始训练/评估,分别用train(), test()函数来实现。除此之外,battlesrv还负责配置文件的初始化,日志,监控,alloc服务等功能。
-
app/gorge_walk/env/client/nature_client.py
NatureClient的功能主要包含:
-
与game core和AI Server的通信和数据传输
-
主循环,通过
run()函数实现,包含start_game(),on_update(), 以及stop_game() -
游戏结束后的统计数据,通过
save_game_stat()实现
-
app/gorge_walk/env/client/gamecore_controller.py
NatureClient调用的一个控制器,负责向game core发送游戏启动和游戏结束的命令
-
app/gorge_walk/env/client/game.py
峡谷漫步v1游戏环境的离散化/网格化处理,game.py本身可以作为峡谷漫步v1的一个本地测试环境,其中的run()函数可以实现玩家在terminal下的一个简单的带有可视化的游戏体验。
-
app/gorge_walk/env/gorge_walk_state.py
-
parse_from_proto_to_state( )函数负责把从NatureClient里传来的proto数据进行解析,并生成state
-
parse_from_proto_to_reward( )函数负责生成reward
注意:同学们如果需要修改特征(state)或奖励(reward),可以在上述位置进行相应修改
3.3.建议修改的代码
我们建议可以从以下五个方向进行代码的修改,用以测试不同的强化学习效果:
-
Reward
conf/gorge_walk_v1/gorge_walk_config.json里的XXX_REWARD标签定义了强化学习中的回报,同学们可以在这里修改各个回报的权重,去训练出玩法风格截然不同的agent。同学们可以通过消融实验的方法,去测试每个reward对agent训练的影响。但是不同reward之间不是相互独立的,同时修改多个reward的效果不能简单的用单个reward的实验结果进行简单的线性叠加。如何能达到一个相对平衡的点并取得游戏的胜利,是同学们可以思考的方向。
注意:
conf/gorge_walk_v1/gorge_walk_config.json里的其他参数请同学们不要修改。
另外,同学们也可以直接在app/gorge_walk/env/client/game.py里的move( )函数里修改reward的生成逻辑。默认的奖励设计并非最优,我们鼓励同学们自己设计reward。
简单总结,可以修改reward的地方:
-
app/gorge_walk/env/gorge_walk_state.py里的 parse_from_proto_to_reward -
conf/gorge_walk_v1/gorge_walk_config.json里的 XXX_REWARD -
app/gorge_walk/env/client/game.py里的 move( )函数
-
Hyperparameters
建议同学们修改的超参数包含:
-
conf/gorge_walk_v1/config.py里的DimConfig, AlgoConfig, DQNConfig -
conf/actor.ini里的predict_batch_size -
conf/aisrv.ini里的send_sample_size -
conf/configure.ini里的train_batch_size, production_consume_ration -
conf/leaner.ini里的replay_buffer_capacity, preload_ratio, dump_model_freq
同学们需要首先学习并了解每个参数的含义以及对训练/推演的影响,判断出哪些是可以去优化的,再利用实验去验证。
注意:超参数的调整一直是深度学习中非常需要依靠研究员经验的部分,同样的算法,同样的参数,针对不同的应用场景都可能会有较大的表现差异。
-
Graph
app/gorge_walk/algorithm/torch_network.py里有对网络的定义,具体实现参考BaseNetwork类,同学们可以在这里进行修改网络的操作。
-
Model
app/gorge_walk/algorithm/torch_dqn_model.py里定义了model和算法,包括loss的计算和predict函数。同学们如果想修改算法,可以从这里进行操作。
-
State
app/gorge_walk/env/gorge_walk_state.py里包含了生成state的代码,修改特征可以在这里进行。
❗️注意:未在上述内容中提及的代码文件请勿擅自更改,有可能会使训练效果变差,甚至无法正常训练。例如,在app/gorge_walk/env/client目录下,除了game.py和game_test.py以外,其他代码文件涉及大量的通信逻辑和数据传输。
3.4.网络结构
网络为最简单的全连接层,网络的输出由配置控制是否输出多头网络、是否输出softmax网络
self.layers = [nn.Linear(np.prod(state_shape), 256),nn.ReLU(inplace=True)] self.layers += [nn.Linear(256, 256), nn.ReLU(inplace=True)] self.layers += [nn.Linear(256, 128), nn.ReLU(inplace=True)] if not multi_head: self.layers += [nn.Linear(128, np.prod(action_shape))] if use_softmax: self.layers += [nn.Softmax(dim=-1)] self.model = nn.Sequential(*self.layers).to(self.device)
3.5.重要API介绍
3.5.1.Class DQNModel
-
__init__(self, network, name, role='actor'):-
Introduction: dqn算法模型的实现:包括神经网络、模型预测、模型训练、模型保存、模型恢复
-
Parameters
-
networktorch_network.BaseNetwork类型,神经网络通过参数传入 -
namestring类型,该模型的名字,用于标识 -
rolestring类型,适配框架, 用于区分当前模型的使用场景(actor或learner), 当前模型不进行区分
-
-
-
update_target_q(self)-
Introduction: 该方法将网络参数更新到target网络
-
-
learn(self, g_data)-
Introduction: 该方法实现了dqn算法和模型的训练过程
-
Parameters
-
g_datalist类型,由reverb传送过来的一个batch的原始训练数据
-
-
Return: 训练过程中产生的数据, 用于统计
-
-
predict(self)-
Introduction: 该方法实现了模型的预测
-
Parameters
-
obsdict类型,由aisvr传送过来的一个observation数据
-
-
Return
-
format_actionlist类型, 预测得到的动作序列 -
network_sample_infolist类型,返回的其他信息,该算法无需返回有效信息 -
lstm_infolist类型,返回的lstm相关信息,该网络没有使用lstm,则返回None
-
-
-
__rdata2tdata(self, r_data)-
Introduction: 该方法将reverb传入的数据转换成可以训练的数据
-
Parameters
-
r_datalist类型,由reverb传入的原始数据
-
-
Return
-
t_datalist类型,训练数据
-
-
-
save_param(self, path=None, id='1')-
Introduction: 保存模型的方法
-
Parameters
-
pathstring类型,保存模型的路径 -
idint类型,保存模型的id
-
-
3.5.2.Class Game
❗️注意:
Game类主要负责游戏逻辑,在__init( )__和reset( )函数里进行了课程学习相关的操作来加速训练。在
move( )函数中,同学们可以进行reward的修改,但请勿修改score。关于score和reward的区别,在环境介绍一文中有详细说明。除非有特殊情况,我们建议同学们不要修改
Game类的其他函数和功能。请遵循这些指导原则,以确保训练和评估顺利进行。
-
__init__(self, map_path, treasure_path, max_steps, logger, idx_end=10, is_train=True):
-
Introduction: 初始化
-
Parameters
-
map_pathstring类型,网格化后的地图配置文件 -
treasure_pathstring类型,网格化后的宝箱配置文件 -
max_stepsint类型,最大步数
-
-
-
reset(self, treasure_id):
-
Introduction: 重启一局游戏
-
Parameters
-
treasure_idint类型的list,传入该局游戏需要生成的宝箱id
-
-
-
_reset_treasure_data(self, treasure_id):
-
Introduction: 重启游戏时重新设置新的宝箱位置
-
Parameters
-
treasure_idint类型的list,传入该局游戏需要生成的宝箱id
-
-
-
_get_distance(self, pos):
-
Introduction: 返回当前位置距离终点的最短路径距离
-
Parameters
-
pos: int类型的list,当前位置坐标(2维的网格坐标)
-
-
-
__build_obs(self):
-
Introduction: 本地拼装observation(仅用于本地测试,实际训练并没有调用)
-
-
step(self, action):
-
Introduction: 外部调用的接口,执行每一步的移动操作,若大于最大步数,则游戏结束
-
Parameters
-
action: Command类型,这一步需要执行的动作
-
-
-
run(self, interactive=False, visualization=False, cmd_list=None):
-
Introduction: 本地mini-game的实现,实际训练中并未调用
-
Parameters
-
interactive: bool类型,设置为True则通过命令行读取用户输入指令来执行每一步的动作,设置为False则通过读取cmd_list来执行动作 -
visualization: bool类型,设置成True则会在terminal里打印当前位置的局部观察信息 -
cmd_list: Command类型的list,命令列表,顺序执行
-
-
-
move(self, direction, score_decay=False):
-
Introduction: 每一步动作的执行逻辑,更新英雄位置,同时包含了score和reward的计算及更新
-
Parameters
-
direction: Commandl类型,这一步需要执行的动作 -
score_decay: bool类型,设置成True则宝箱分数会随步数增大而衰减
-
-
-
_bump(self, loc):
-
Introduction: 撞墙检测,如果撞墙则返回True,否则返回False
-
Parameters
-
loc: int类型的list,当前位置坐标(2维的网格坐标)
-
-
-
_check_treasure(self):
-
Introduction: 宝箱检测,如果当前位置有宝箱,则返回该宝箱的分数,否则返回0
-
-
_update_local_view(self):
-
Introduction: 更新局部观察域
-
Return
-
local_map: string类型,大小为5x5(view=2)的矩阵
-
-
-
_get_raw_state(self):
-
Introduction: 重新编码局部观察域
-
Return
-
raw_state: int类型,大小为5x5(view=2)的矩阵
-
-
-
_update_location_memory(self):
-
Introduction: 更新历史记忆信息
-
Return
-
location_memory: float类型,大小为64x64的矩阵(全局记忆信息)
-
-
-
__visualize(self)
-
Introduction: 将当前的局部观察域打印出来
-
4.训练介绍
4.1.监控介绍
4.1.1.查看监控
在训练管理页面,提供了“查看监控”功能,如下图所示。同学们可以通过查看监控数据实时的定位自己的模型训练流程,从而帮助大家更快更准确的找到问题所在。

监控页面包含了四个模块的数据:Algorithm, Battle, Learner, Actor。
注意:训练开启10分钟后监控才有记录
需要同学们重点关注的两个监控数据(Learner的train以及Actor的predict_succ_cnt)被展开显示在了页面的顶端。以下是各个监控模块的重要指标的简要介绍。
Learner
Learner主要负责训练,监控数据主要反映了训练流程的健康度,重点关注以下指标。
train:训练次数,即训练成功的次数。
Actor
Actor主要负责预测,监控数据主要反映了预测流程的健康度,重点关注下面这一个指标。
predict_succ_cnt: 预测次数,即推演成功的帧数,正常情况下应该呈现为一个斜向上的直线。
Battle
Battle负责的是对战,采用self-play的模式,监控数据主要反映了对战过程的评估指标。
step:游戏步数
treasure_count:获得的宝箱数量
treasure_score:通过宝箱获得的奖励值
total_score:游戏总分
4.1.2.Algorithm - DQN
Algorithm负责强化学习算法,监控数据主要反映了几个重要的算法指标。
loss:损失函数计算出的损失值,包含policy_loss,entropy_loss, 和value_loss,随时间推移,loss应该呈下降趋势。
all_loss_value: 上述三个loss的加权求和
reward:奖励值,随时间推移,reward应该呈上升趋势。
4.1.3.查看日志
在训练过程中或训练完成后,你都可以点击开悟客户端本地训练页面的【训练日志】按钮来打开本地日志文件。
5.代码更新说明
| 版本 | 更新内容 |
|---|---|
| v0.4.20-dev.1 | 开放了目录app/gorge_walk/env/client,你能够进行编辑保存该目录下的代码 |
| v0.4.18-dev.1 | 初始代码包 |
6.KaiwuDRL强化学习框架
6.1.简介
KaiwuDRL框架是开悟基于python研发的用于异步的off-policy强化学习训练的分布式框架,可以稳定高效地完成王者荣耀场景下的强化学习相关任务。KaiwuDRL的前身是SAIL,关于SAIL框架的详细信息见参考文档,并且已经在github开源。
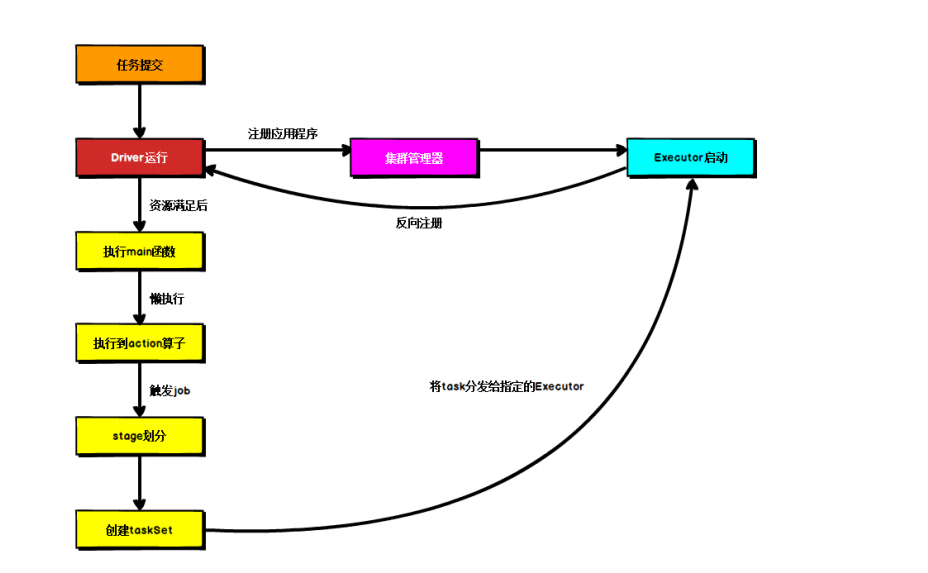
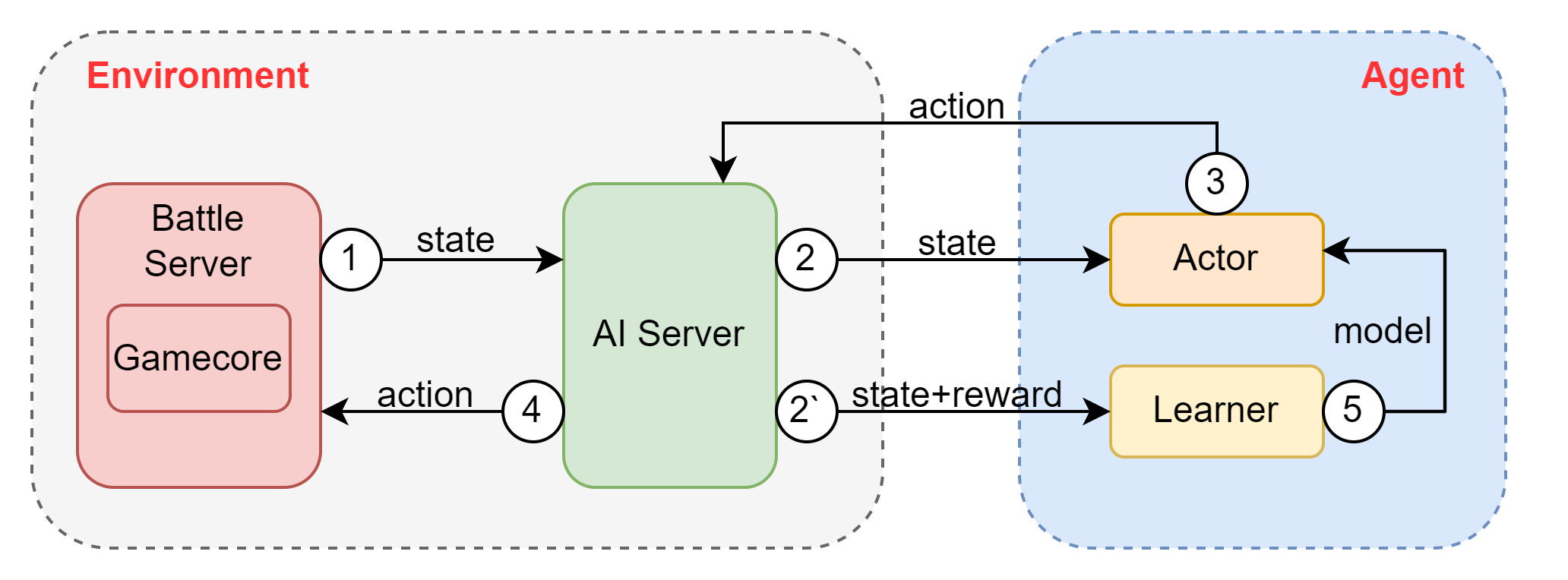
下图展示了KaiwuDRL框架的核心功能模块,主要分为Battle Server, AI Server, Learner和Actor。Learner和Actor对应于强化学习算法中的Agent,其中Actor负责与环境交互产生训练样本,Learner负责消耗样本数据训练模型。Battle Server和AI Server对应于强化学习算法中的Environment,其中Battle Server能够发送每一帧的State数据,接收返回的Action指令并执行。AI Server可以视为一个中间桥梁,游戏侧负责与Battle Server交互,框架内负责与Actor,Learner交互。
6.2.Gamecore & Battle Server
-
Gamecore可以理解为游戏引擎,负责处理游戏逻辑,生成游戏帧数据。当接收到action指令后,gamecore会执行该指令并生成新的帧数据。
-
Battle Server可以理解为游戏服务器,对内会调用gamecore进行state的上报和驱动游戏获取state的更新,对外Battle Server只与AI Server进行交互,负责把处理后的帧数据发送给AI Server并接收新的Action指令。
总体来说,可以把Gamecore和Battle Server打包理解成强化学习里的环境(Environment)。
6.3.AI Server
AiServer是一个中间桥梁,沟通Gamecore与Actor/Learner,并实现业务相关的功能。这部分内容与强化学习课程关系不大,而且也不建议同学们修改,为了同学们对框架能有个更全面的理解,下面给出了简单的解释供大家参考。
-
AI Server <--> Battle Server
-
游戏启动时,AI Server会从Battle Server收到三个请求,分别为:
-
init_req: AI Server与Battle Server建立连接
-
ep_start_req: 一局游戏的开始(ep对应强化学习里的episode)
-
agent_start_req: 一局游戏里agent的开始(如王者荣耀里的英雄,多个agent需多次调用)
-
-
游戏过程中,main loop里会不断处理AI Server与Battle Server之间的请求与响应,采用一问一答的方式:
-
update_req: Battle Server将当前的state数据发送给AI Server
-
update_rsp: AI Server将从Actor获得的预测响应(Action)返回给Battle Server
-
-
游戏结束时,Battle Server会向AI Server发送game_over的信号,AI Server收到了包含有game_over信号的帧数据后立即跳出main loop
-
采用TCP通信
-
-
AI Server <--> Actor
-
AiServer从Gamecore拿到state数据后向Actor发起模型预测请求
-
Actor将模型预测响应(Action)返回给AiServer
-
采用zmq通信,其中actor是ZmqServer,Aisrv是ZmqClient
-
-
AI Server <--> Learner
-
AiServer从Gamecore拿到state数据后向Learner发送模型训练样本,即[State, Reward]
-
注意AiServer不会从Learner得到回答,Learner会定期将模型参数同步给Actor,这里的细节可参考下面的Model pool部分
-
采用Reverb通信,其中Aisrv是ReverbClient,与ReverbServer通信,同时ReverbServer和Learner之间采用ReplayBuffer,支持reverb,tf_uniform等
-
-
sample_processor
-
样本生产相关逻辑,负责样本的生成,存储,拼接和发送
-
这一部分不建议同学们进行修改
-
-
protocl
-
包含了aisrv与battlesrv的通信协议,部分场景还包含了battlesrv和gamecore之间的通信协议
-
Protocol buffers 是 Google 开发的语言中立、平台中立、可扩展的结构化数据序列化机制,与XML类似,但更小、更快、更简单。用户定义了一次数据的结构化方式,然后可以使用特殊生成的源代码轻松地将结构化数据写入各种数据流并使用各种语言从中读取结构化数据。想要更多的了解protobuf可以参考官网
-
原始的协议文件均以.proto结尾,编译后的协议文件以pb2.py结尾
-
-
feature_process
-
主要包含以下特征处理方式,包含了机器学习里一些传统的特征值处理方法:
-
图像特征通道化:输出了6个channels,注意这里的channel和计算机视觉中的常见的RBG channels是不一样的,这6个channel是抽象出来的,每个通道代表了某一方面的信息,比如小地图信息,草丛信息等
-
连续特征归一化:把连续特征的值归一化到[0, 1]的区间
-
离散特征用one-hot
-
-
1v1,3v3场景下不建议同学们修改特征,因为特征工程本身是一个相对繁琐并且依赖丰富工程经验的过程,我们这里给出的特征值处理方式可以认为已经达到了王者荣耀相关训练任务的实验最优,同学们直接沿用即可
-
6.4.Actor/Learner
Actor/Learner对应于强化学习里的agent ,但各有分工。其中Actor主要负责推理,先从Learner获取模型,根据模型参数与state数据推理出预测动作(Action);Learner主要负责训练模型并更新模型参数。
以1v1场景为例,Actor/Learner会调用同一个model(model.py),通过Model类里[actor, learner]的mode选择来区别。PPO算法的主要实现均在model.py里,其中包括loss的计算以及inference函数(注意actor和learner虽然会调用同一个_inference函数,但是对于输出的处理是不一样的)。Actor/Learner共享模型的配置文件config.py(common/config.py),这里包含了所有模型/算法/训练超参数的定义,同学们可以在此进行修改。 GameController(actor_learner/game_controller.py)里定义了Graph,包含gradient的生成以及forward/backward propagation的逻辑。GameController里还实现了actor/learner的模型初始化,actor的predict函数以及learner的train函数。
Actor/Learner是框架的核心,详细信息请同学们阅读代码。
6.5.Model pool
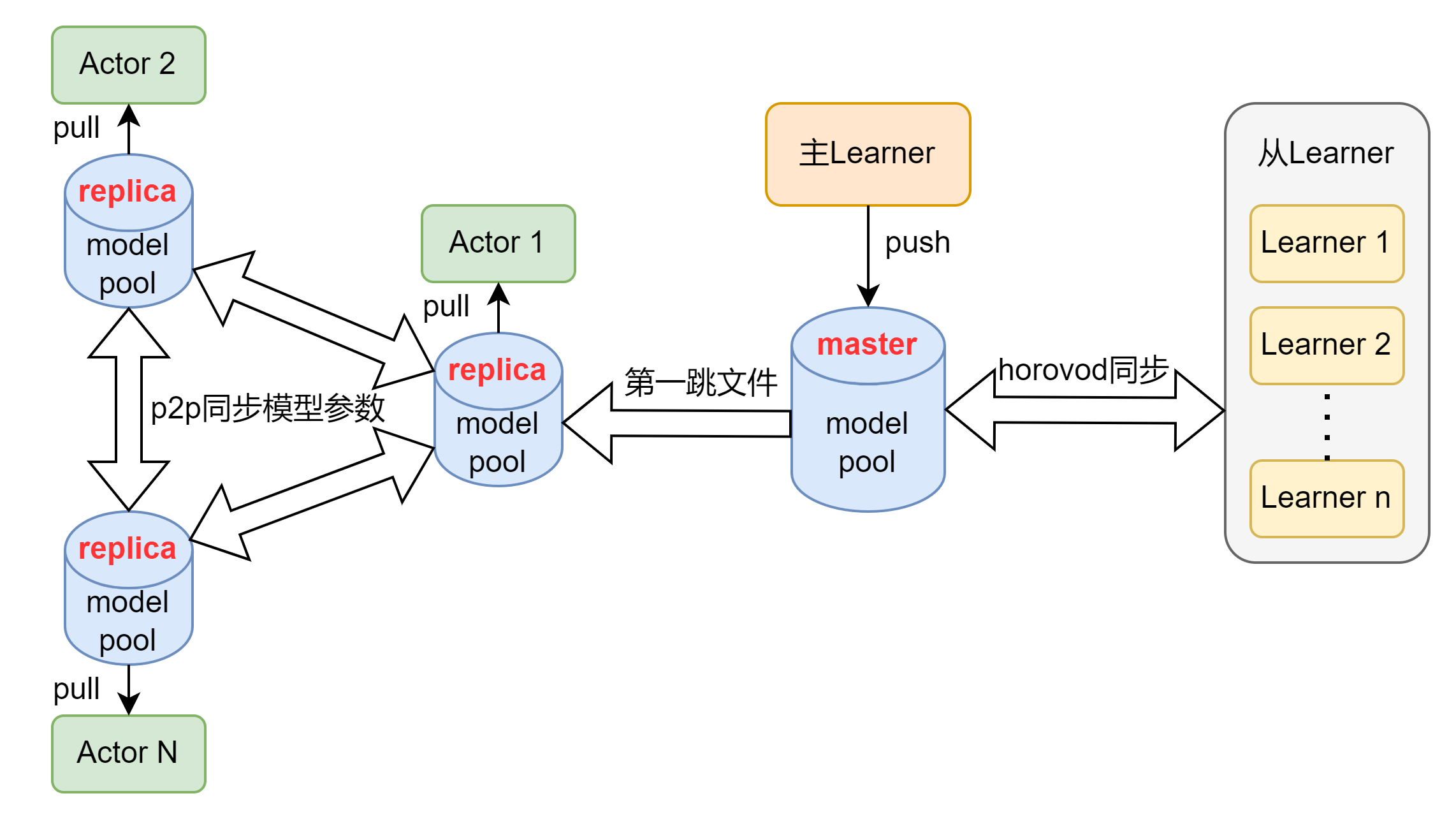
Actor和Learner之间的模型同步采用model pool的方式,如上图所示
-
主Learner定时push最新模型到master的model pool中
-
只有主Learner才能上传model,主Learner负责训练,上传COS,上传model
-
从Learner主要负责训练,并且和主Learner之间同步模型参数信息
-
主Learner和从Learner之间采用horovod框架同步信息
-
-
Actor可以在各自的replica model pool中选择pull最新模型或某个历史模型
-
各个Actor的model pool之间采用p2p的方式同步模型参数
-