细节内容请关注微信公众号:运筹优化与数据科学
ID: pomelo_tree_opt
outline
1. Linear regression
2. Support vector regression
3. SVR vs. SVM
4. Linear SVR
5. Kernel SVR
------------------------------------
1. Linear regression
OR里最常使用的两件东西(OR的两样利器)
-
从优化的观念来看是,linear programming
-
从stochastic或statistic的观念来看,最常用的就是regression.
Linear regression:
A model that assumes a linear relationshipbetween the input variables (x) and the single output variable (y) such that y can be calculated from a linear combination of the input variables (x).

=====================
2. Support Vector Regression
Basic idea:
Find a hyperplane centering around the data by boxing as many data points as possible in a given tube around the hyperplane.

其实就是找个tube,来把尽可能多的点都包含进去
-
Tube里的点越多越好,外面的点越少越好
-
外面的点距离边界的距离越短越好(这个距离可以是总距离,也可以是平均距离)
这根管子就叫做epsilon-tube
=============================
3. SVR vs SVM

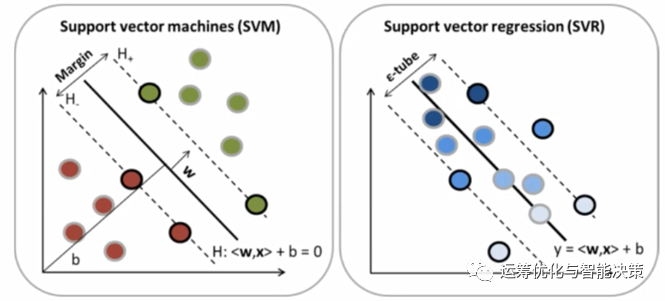


比如左边这个linear regression的图,横坐标是x,纵坐标是y,这个其实x是1维的。
而右边的linear classification的图,x是二维的。要是再加上颜色的话,是3维的info.
=============================
4. Linear soft SVR









-------------------------------

Dual model的目标函数第一个term,是个左乘右乘的东西,中间是个数,所以是二次的。而且因为两边是对称的,所以是convex的。其他的term都是linear的。2N个变量约束,像box一样,有上下界。1个等式约束。所以总体上是个convex quadratic programing.
--------------------
Dual与n无关,n其实是被内积操作给吸收掉了。
所以当n很大时,dual model就很占便宜。现实例子,n很容易很大,比如信用卡公司,会收集很多资料,就是很多维度,全景画像什么的,数据经常被abuse。
------------------
相比之下,primal model是n+1个自由变量,N个非负变量,2N个线性约束
整体上primal model既与data-point有关,又与data的dimension也有关。
Dual model比primal model而言,是占优势的。
------------------------------------------


=============================
5. Kernel soft SVR
From linear to nonlinear