文章目录
- 一、Propmt tuning
- 1. peft库中的tuning
- 2. prompt tuning怎么搞
- 二、Prompt tuning代码实战
- 1. tuning训练
- 2. 模型推理比较
- 3. 其他tuning技术
- Reference
一、Propmt tuning
1. peft库中的tuning
- 之前提到过可以借助
peft库(Parameter-Efficient Fine-Tuning)进行微调,支持如下tuning:- Adapter Tuning(固定原预训练模型的参数 只对新增的adapter进行微调)
- Prefix Tuning(在输入token前构造一段任务相关的virtual tokens作为prefix,训练时只更新Prefix不分的参数,而Transformer的其他不分参数固定,和构造prompt类似,只是prompt是人为构造的即无法在模型训练时更新参数,而Prefix可以学习<隐式>的prompt)
- Prompt Tuning(Prefix Tuning的简化版,只在输入层加入prompt tokens,并不需要加入MLP)
- P-tuning(将prompt转为可学习的embedding层,v2则加入了prompts tokens作为输入)
- LoRA(Low-Rank Adaption,为了解决adapter增加模型深度而增加模型推理时间、上面几种tuning中prompt较难训练,减少模型的可用序列长度)
- 该方法可以在推理时直接用训练好的AB两个矩阵和原预训练模型的参数相加,相加结果替换原预训练模型参数。
- 相当于用LoRA模拟full-tunetune过程
2. prompt tuning怎么搞
- 给出好的prompt可以让LLM生成更好的答案,反过来想通过LLM帮我们找到好的prompt就是prompt tuning的思路,训练让模型看到新的例子生成prompt,并把该段prompt作为前缀拼接到我们自己的prompt上,送入LLM得到结果
- prompt tuning训练的前缀是向量,所以解释性略差
- 和few show比较:LLM的上下文context长度是有限的(prompt中给出有限的例子,业务复杂时难让模型学习足够多知识),prompt tuning就没有这个限制,只需在训练LLM时给他看足够多例子,之后提问带上一个短的prompt前缀(一般8~20个token)即可
- 和fine tuning比较:prompt tuning是完全冻结LLM模型参数,只需训练一个几个token的prompt前缀;但是fine tuning精调一个模型很耗资源
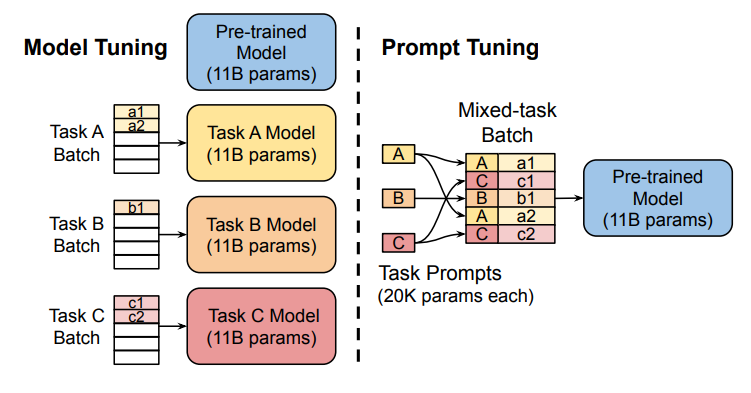
- 为每一个任务额外添加一个或多个embedding,之后拼接query正常输入LLM,并只训练这些embedding。如下图,左图为单任务全参数微调,右图为prompt tuning。
- prompt tuning将fine tune任务转为mlm任务。自动学习模板:离散的主要包括 Prompt Mining, Prompt Paraphrasing, Gradient-based Search, Prompt Generation 和 Prompt Scoring;连续的则主要包括Prefix Tuning, Tuning Initialized with Discrete Prompts 和 Hard-Soft Prompt Hybrid Tuning。
- 正常微调举例:[cls]今天天上都出太阳了,阳光明媚。[SEP]
prompt输入举例:[cls]今天天气是[MASK]。[SEP] 今天天上都出太阳了,阳光明媚。[SEP]
二、Prompt tuning代码实战
1. tuning训练
- 数据:twitter_complaints
- 模型:bigscience/bloomz-560m模型
PromptTuningConfig设置Prompt tuning配置,下面num_virtual_tokens设置prompt前缀的token数,因为token初始化用任务相关文字效果更好,所以下面用Classify if the tweet is a complaint or not:初始化,
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Author : andy
@Date : 2023/7/10 20:37
@Contact: 864934027@qq.com
@File : prompt_tuning.py
"""
from transformers import AutoModelForCausalLM, AutoTokenizer, default_data_collator, get_linear_schedule_with_warmup
from peft import get_peft_config, get_peft_model, PromptTuningInit, PromptTuningConfig, TaskType, PeftType
import torch
from datasets import load_dataset
import os
from torch.utils.data import DataLoader
from tqdm import tqdm
device = "mps"
# device = "cuda"
model_name_or_path = "bigscience/bloomz-560m"
tokenizer_name_or_path = "bigscience/bloomz-560m"
peft_config = PromptTuningConfig(
task_type=TaskType.CAUSAL_LM,
prompt_tuning_init=PromptTuningInit.TEXT,
num_virtual_tokens=8,
prompt_tuning_init_text="Classify if the tweet is a complaint or not:",
tokenizer_name_or_path=tokenizer_name_or_path,
)
dataset_name = "twitter_complaints"
text_column = "Tweet text"
label_column = "text_label"
max_length = 64
learning_rate = 3e-2
num_epochs = 20
batch_size = 8
output_dir = './output'
# 1. load a subset of the RAFT dataset at https://huggingface.co/datasets/ought/raft
dataset = load_dataset("ought/raft", dataset_name)
# get lable's possible values
label_values = [name.replace("_", "") for name in dataset["train"].features["Label"].names]
# append label value to the dataset to make it more readable
dataset = dataset.map(
lambda x: {label_column: [label_values[label] for label in x["Label"]]},
batched=True,
num_proc=1
)
# have a look at the data structure
dataset["train"][0]

# 2. dataset
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = tokenizer.eos_token_id
def preprocess_fn(examples):
tweets = examples[text_column]
# pad labels with a pad token at the end
labels = [str(x) + tokenizer.pad_token for x in examples[label_column]]
# concatenate the tweet with it label
inputs = [f"{text_column} : {tweet}\nLabel :{label}"
for tweet, label in zip(tweets, labels)]
# tokenize input
model_inputs = tokenizer(inputs,
padding='max_length',
max_length=max_length,
truncation=True,)
# tokenize label, as -100 not a valid token id, do the padding manually here
labels_input_ids = []
for i in range(len(labels)):
ids = tokenizer(labels[i])["input_ids"]
padding = [-100] * (max_length - len(ids))
labels_input_ids.append(padding + ids)
model_inputs["labels"] = labels_input_ids
# make model inputs tensor
model_inputs["input_ids"] = [torch.tensor(ids) for ids in model_inputs["input_ids"]]
model_inputs["attention_mask"] = [torch.tensor(ids) for ids in model_inputs["attention_mask"]]
model_inputs["labels"] = [torch.tensor(ids) for ids in model_inputs["labels"]]
return model_inputs
# have a look at the preprocessing result
# print(preprocess_fn(dataset["train"][:2]))
processed_datasets = dataset.map(
preprocess_fn,
batched=True,
num_proc=1,
remove_columns=dataset["train"].column_names, #remove unprocessed column for training
load_from_cache_file=False,
desc="Running tokenizer on datasset"
)
test_size = round(len(processed_datasets["train"]) * 0.2)
train_val = processed_datasets["train"].train_test_split(
test_size=test_size, shuffle=True, seed=42)
train_data = train_val["train"]
val_data = train_val["test"]
# 3. model
model = AutoModelForCausalLM.from_pretrained(model_name_or_path)
model = get_peft_model(model, peft_config)
print(model.print_trainable_parameters())
trainable params: 8192 || all params: 559222784 || trainable%: 0.0014648902430985358
从上面打印结果看出,模型的参数有5.6亿左右,但是需要训练的参数只占0.001%,只有8192个。
# 4. trainer
from transformers import Trainer, TrainingArguments
trainer = Trainer(
model=model,
train_dataset=train_data,
eval_dataset=val_data,
data_collator=default_data_collator,
args=TrainingArguments(
output_dir='./output',
per_device_train_batch_size=batch_size,
num_train_epochs=num_epochs,
learning_rate=learning_rate,
load_best_model_at_end=True,
logging_strategy='steps',
logging_steps=10,
evaluation_strategy='steps',
eval_steps=10,
save_strategy='steps',
save_steps=10,
)
)
trainer.train()

2. 模型推理比较
# 5. inference
def inference():
def generate(inputs, infer_model):
with torch.no_grad():
inputs = {k: v.to(device) for k, v in inputs.items()}
outputs = infer_model.generate(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
max_new_tokens=20,
eos_token_id=3
)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True)[0])
# (1) base model_inference
base_model = AutoModelForCausalLM.from_pretrained(model_name_or_path)
base_model.to(device)
inputs = tokenizer(
f'{text_column} : {"@denny the grocery price is soaring, even milk is becoming unaffordable, could you do something?"}\nLabel :',
return_tensors="pt", # Return PyTorch torch.Tensor objects.
)
generate(inputs, base_model)
print("----------------------------------------")
shot1 = f'{text_column} : {"@nationalgridus I have no water and the bill is current and paid. Can you do something about this?"}\nLabel :complaint\n'
shot2 = f'{text_column} : {"@HMRCcustomers No this is my first job"}\nLabel :no complaint\n'
input = f'{text_column} : {"@denny the grocery price is soaring, even milk is becoming unaffordable, could you do something?"}\nLabel :'
inputs_few_shot = tokenizer(
shot1 + shot2 + input,
return_tensors="pt",
)
generate(inputs_few_shot, base_model)
# (2) prompt-tuned model_inference
from peft import PeftModel, PeftConfig
path = "/content/drive/MyDrive/prompt_tuning"
config = PeftConfig.from_pretrained(path)
pretrained_model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path)
prompt_tuned_model = PeftModel.from_pretrained(pretrained_model, path)
prompt_tuned_model.to(device)
inputs = tokenizer(
f'{text_column} : {"@denny the grocery price is soaring, even milk is becoming unaffordable, could you do something?"}\nLabel :',
return_tensors="pt", # Return PyTorch torch.Tensor objects.
)
generate(inputs, prompt_tuned_model)
inference()
- 上面base model推理结果:
Tweet text : @denny the grocery price is soaring, even milk is becoming unaffordable, could you do something?
Label : @denny the grocery<?php
/**
* Copyright © 2016 Google Inc.
----------------------------------------
Tweet text : @nationalgridus I have no water and the bill is current and paid. Can you do something about this?
Label :complaint
Tweet text : @HMRCcustomers No this is my first job
Label :no complaint
Tweet text : @denny the grocery price is soaring, even milk is becoming unaffordable, could you do something?
Label :complaint<?php
/**
* Copyright © Magento, Inc. All rights reserved.
- prompt-tuned model推理结果:
Tweet text : @denny the grocery price is soaring, even milk is becoming unaffordable, could you do something?
Label :complaint
3. 其他tuning技术
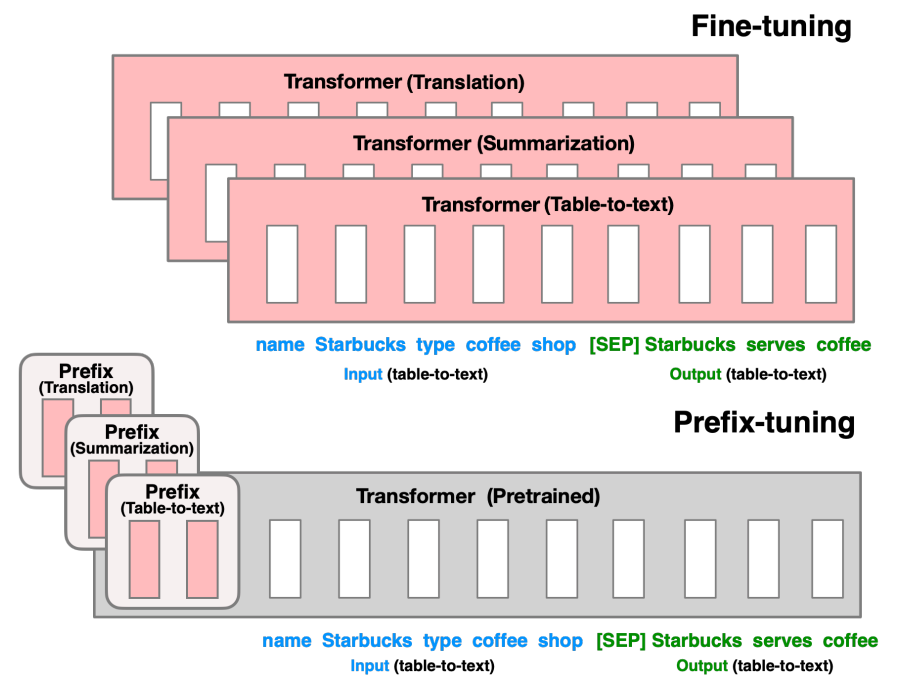
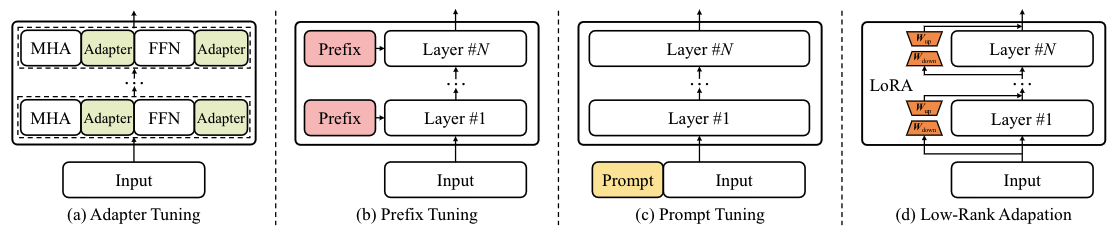
- prefix tuning和prompt tuning都不需要改LLM模型参数本身,但prefix tuning不进在用户输入该层找到一个前缀,还要在LLM的每层都找到一个前缀并加上,训练成本明显更高
- p-tuning则不仅可在用户输入的开头加附加信息,也可以在中间或结尾附加信息
- lora tuning如下图,上一篇博客也讲过
Reference
[1] https://github.com/jxhe/unify-parameter-efficient-tuning
[2] Continuous Optimization:从Prefix-tuning到更强大的P-Tuning V2