今天一早发现ceph集群出错,根据报错,可以判断出是时间不同步和一个存储池没有起来导致的
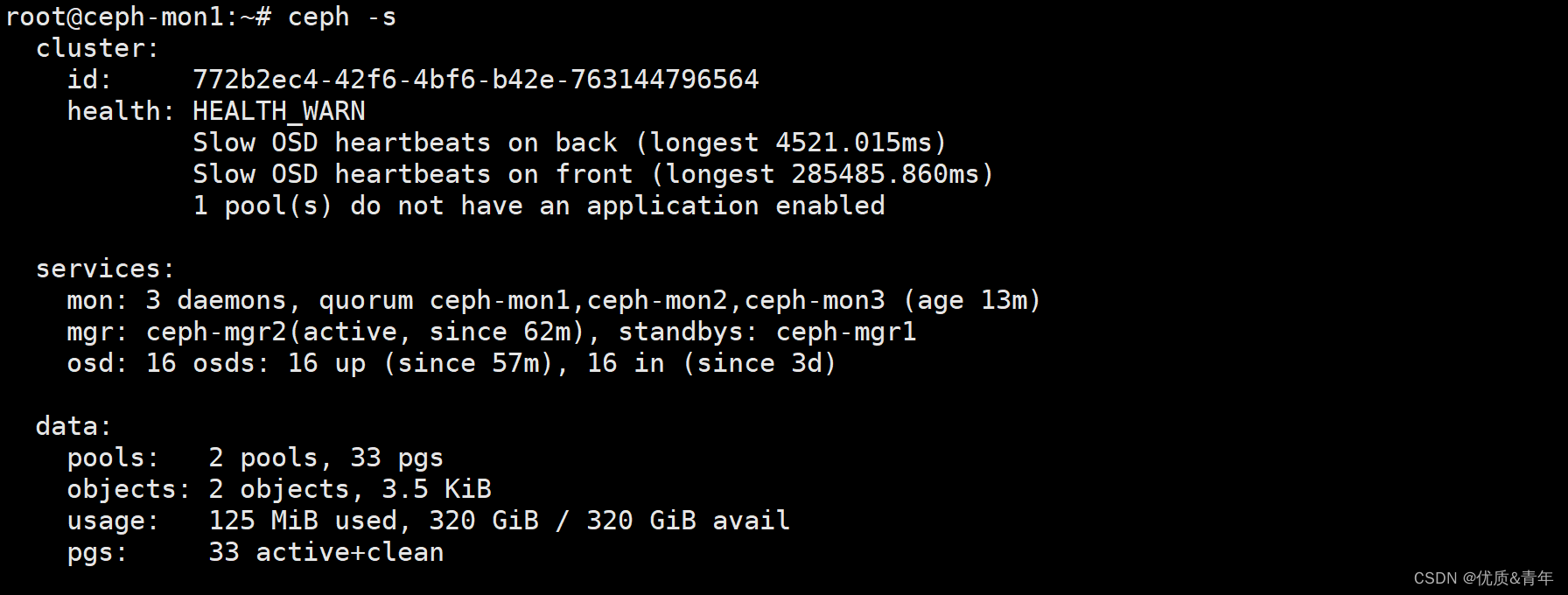
一、解决时间同步
1.1检查时间同步的ntp服务是否启动(发现有两台服务器的ntp服务关闭了)
systemctl status ntp
1.2 重启ntp服务(重启服务后发现报错还在)
systemctl restart ntp
1.3 在确定是时间同步没问题后,推测是ceph时间偏差阈值设置的太小导致的,故修改了阈值。
在部署节点修改ceph.conf
vim ceph.conf
mon clock drift allowed = 2
mon clock drift warn backoff = 30
再推送给其他mon节点
ceph-deploy --overwrite-conf config push ceph-mon{1,2,3}
再重启mon服务
systemctl restart ceph.mon.target
二、根据报错,有个存储池没有起来
2.1 查看ceph集群的详细信息
cephadmin@ceph-mon1:~/ceph-cluster$ ceph health detail
HEALTH_WARN 1 pool(s) do not have an application enabled
[WRN] POOL_APP_NOT_ENABLED: 1 pool(s) do not have an application enabled
application not enabled on pool 'mypool'
use 'ceph osd pool application enable <pool-name> <app-name>', where <app-name> is 'cephfs', 'rbd', 'rgw', or freeform for custom applications
#会发现mypool这个存储池没有启动
cephadmin@ceph-mon1:~/ceph-cluster$ ceph osd pool application enable mypool rgw
#此时集群恢复成功
cephadmin@ceph-mon1:~/ceph-cluster$ ceph -s
cluster:
id: 772b2ec4-42f6-4bf6-b42e-763144796564
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-mon1,ceph-mon2,ceph-mon3 (age 16m)
mgr: ceph-mgr2(active, since 87m), standbys: ceph-mgr1
osd: 16 osds: 16 up (since 82m), 16 in (since 3d)
data:
pools: 2 pools, 33 pgs
objects: 2 objects, 3.5 KiB
usage: 126 MiB used, 320 GiB / 320 GiB avail
pgs: 33 active+clean








![[入门必看]数据结构6.2:图的存储及基本操作](https://img-blog.csdnimg.cn/a108619f478844ba95ac20240d06b66a.png#pic_center)


