目录
- 前言
- 1. 共享内存
- 2. shared memory案例
- 3. 补充知识
- 总结
前言
杜老师推出的 tensorRT从零起步高性能部署 课程,之前有看过一遍,但是没有做笔记,很多东西也忘了。这次重新撸一遍,顺便记记笔记。
本次课程学习精简 CUDA 教程-共享内存
课程大纲可看下面的思维导图

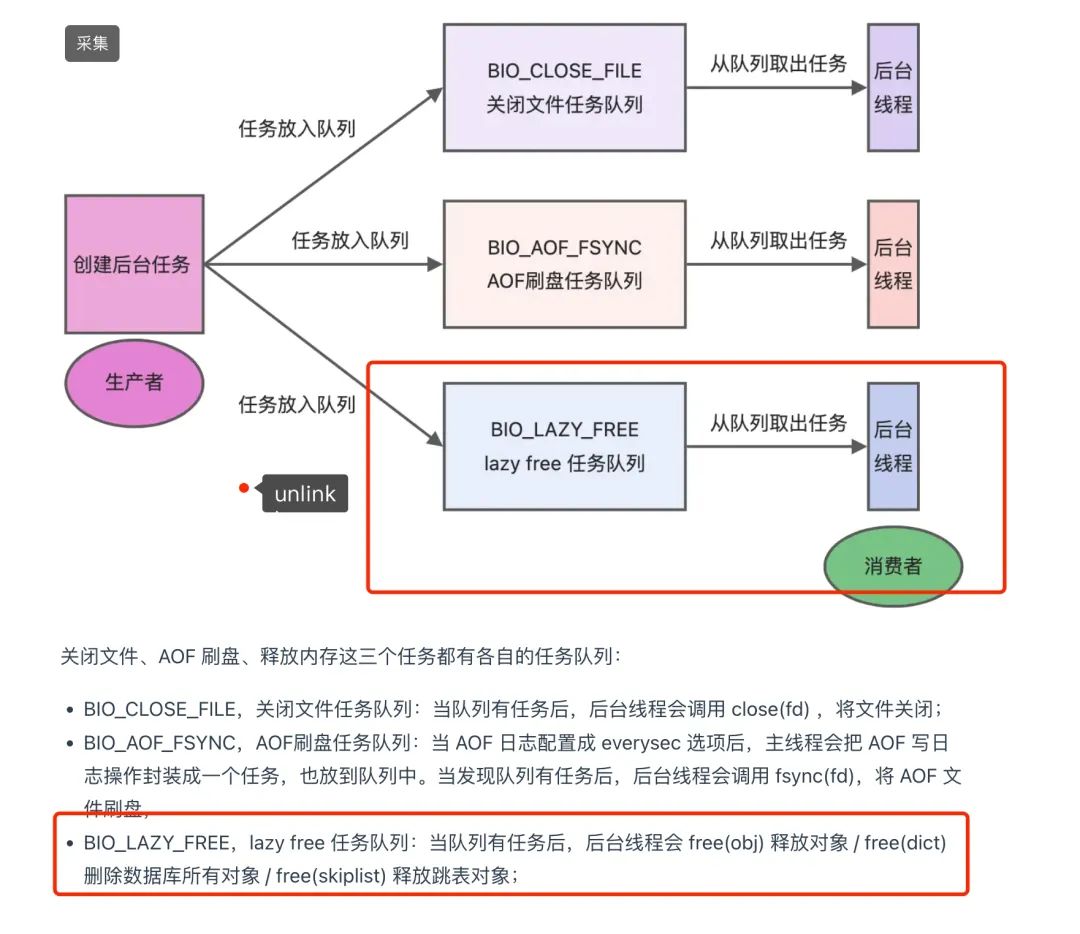
1. 共享内存
对于共享内存(shared_memory)你需要知道:
- 共享内存因为更靠近计算单元,所以访问速度更快(越近越快,越近越贵)
- 共享内存通常可以作为访问全局内存的缓存使用
- 可以利用共享内存是实现线程间的通信
- 通常与
__syncthreads()同时出现,这个的函数是同步 block 内的所有线程,全部执行到这一行才往下走- 常用方式,通常是在线程 ID 为 0 的时候从 global memory 取值,然后 syncthreads,然后再使用
2. shared memory案例
shared memory 案例的 main.cpp 示例代码如下:
#include <cuda_runtime.h>
#include <stdio.h>
#define checkRuntime(op) __check_cuda_runtime((op), #op, __FILE__, __LINE__)
bool __check_cuda_runtime(cudaError_t code, const char* op, const char* file, int line){
if(code != cudaSuccess){
const char* err_name = cudaGetErrorName(code);
const char* err_message = cudaGetErrorString(code);
printf("runtime error %s:%d %s failed. \n code = %s, message = %s\n", file, line, op, err_name, err_message);
return false;
}
return true;
}
void launch();
int main(){
cudaDeviceProp prop;
checkRuntime(cudaGetDeviceProperties(&prop, 0));
printf("prop.sharedMemPerBlock = %.2f KB\n", prop.sharedMemPerBlock / 1024.0f);
launch();
checkRuntime(cudaPeekAtLastError());
checkRuntime(cudaDeviceSynchronize());
printf("done\n");
return 0;
}
shared memory 案例的 main.cpp 示例代码如下:
#include <cuda_runtime.h>
#include <stdio.h>
//demo1 //
/*
demo1 主要为了展示查看静态和动态共享变量的地址
*/
const size_t static_shared_memory_num_element = 6 * 1024; // 6KB
__shared__ char static_shared_memory[static_shared_memory_num_element];
__shared__ char static_shared_memory2[2];
__global__ void demo1_kernel(){
extern __shared__ char dynamic_shared_memory[]; // 静态共享变量和动态共享变量在kernel函数内/外定义都行,没有限制
extern __shared__ char dynamic_shared_memory2[];
printf("static_shared_memory = %p\n", static_shared_memory); // 静态共享变量,定义几个地址随之叠加
printf("static_shared_memory2 = %p\n", static_shared_memory2);
printf("dynamic_shared_memory = %p\n", dynamic_shared_memory); // 动态共享变量,无论定义多少个,地址都一样
printf("dynamic_shared_memory2 = %p\n", dynamic_shared_memory2);
if(blockIdx.x == 0 && threadIdx.x == 0) // 第一个thread
printf("Run kernel.\n");
}
/demo2//
/*
demo2 主要是为了演示的是如何给 共享变量进行赋值
*/
// 定义共享变量,但是不能给初始值,必须由线程或者其他方式赋值
__shared__ int shared_value1;
__global__ void demo2_kernel(){
__shared__ int shared_value2;
if(threadIdx.x == 0){
// 在线程索引为0的时候,为shared value赋初始值
if(blockIdx.x == 0){
shared_value1 = 123;
shared_value2 = 55;
}else{
shared_value1 = 331;
shared_value2 = 8;
}
}
// 等待block内的所有线程执行到这一步
__syncthreads();
printf("%d.%d. shared_value1 = %d[%p], shared_value2 = %d[%p]\n",
blockIdx.x, threadIdx.x,
shared_value1, &shared_value1,
shared_value2, &shared_value2
);
}
void launch(){
demo1_kernel<<<1, 1, 12, nullptr>>>();
demo2_kernel<<<2, 5, 0, nullptr>>>();
}
运行效果如下:

在主函数中我们通过调用 cudaGetDeviceProperties 函数获取当前设备的属性,并打印出设备的共享内存的大小,一般为 48KB。
上述示例代码依次展示了使用共享内存 (shared memory)的两个示例:demo1_kernel 和 demo2_kernel
demo1_kernel:
这个示例主要用于展示静态共享变量和动态共享变量的地址。在这个示例中,我们使用了两个静态共享变量和两个动态共享变量,二者在 kernel 函数内外定义都行,没有限制。我们启动的核函数只有一个线程块,每个线程块只有一个线程,因此只有一个线程会执行这个 kernel 函数,并打印对应的共享变量的地址。
通过打印语句,我们可以看到静态共享变量的地址会依次增加,而动态共享变量的地址始终是一样的。
demo2_kernel:
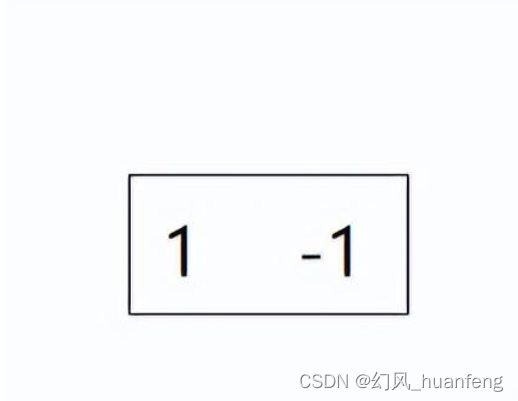
这个示例主要演示如何给共享变量赋值,可看 图2-2 的示意图

在这个示例中,我们定义的两个共享变量 shared_value1 和 shared_value2,我们启动的核函数有两个线程块,每个线程块有 5 个线程,每个线程块的第一个线程会进行共享变量的赋值操作,因此当执行到 __syncthreads() 这一步时,每个 block 的其它 4 个线程会等待第一个线程完成赋值操作。
第一个 block 对应的共享变量赋值为 123 和 55,第二个 block 对应的共享变量赋值为 331 和 8,又由于共享内存(shared memory)是在块(block)级别上进行共享的,因此第一个 block 中所有线程打印的共享变量结果为 123 和 55,第二个 block 中所有线程打印的共享变量结果为 331 和 8,这点可以从运行结果中看到。
共享内存案例展示了使用共享内存的基本概念和用法。共享内存可以在同一个线程块中的线程之间共享数据,并且具有低延迟和高带宽的特性。在实际的 CUDA 程序中,共享内存常用于提高访存效率和实现协作式算法。
3. 补充知识
关于共享内存的知识点:(from 杜老师)
- sharedMemPerBlock 指示了 block 中最大可用的共享内存
- 所以可用使得 block 内的 threads 可以相互通信
- sharedMemPerBlock的应用例子如下图
- 共享内存是片上内存,更靠近计算单元,因此比 globalMem 速度更快,通常可以充当缓存使用
- 数据先读入到 sharedMem,做各类计算时,使用 sharedMem 而非 globalMem
demo_kernel<<<1, 1, 12, nullptr>>>();其中第三个参数 12,是指定动态共享内存 dynamic_shared_memory 的大小
- dynamic_shared_memory 变量必须使用
extern __shared__开头- 并且定义为不确定大小的数组 []
- 12 的单位是 bytes,也就是可以安全存放 3 个 float
- 变量放在函数外面和里面是一样的
- 其指针由 cuda 调度器执行时赋值
- static_shared_memory 作为静态分配的共享内存
- 不加 extern,以
__shared__开头- 定义时需要明确数组的大小
- 静态分配的地址比动态分配的地址低
- 动态共享变量,无论定义多少个,地址都一样
- 静态共享变量,定义几个地址随之叠加
- 如果配置的各类共享内存总和大于 sharedMemPerBlock,则核函数执行错误,Invalid argument
- 不同类型的静态共享变量定义,其内存划分并不一定是连续的
- 中间会有内存对齐策略,使得第一个和第二个变量之间可能存在间隙
- 因此你的变量之间如果存在空隙,可能小于全部大于的共享内存就会报错


总结
本次课程学习了共享内存的使用,shared memory 可以在一个线程块共享数据,由于它靠近计算单元,因此访问速度相比于 global memory 更快。共享内存通常与 __syncthreads 同时出现,为了同步 block 中的所有线程。共享内存变量有静态和动态之分,静态共享内存变量,定义几个地址随之叠加,而动态共享变量,无论定义多少个,地址都一样。定义的共享变量并不能给初始值,必须由线程或者其它方式赋值。