问题
del 和 unlink 有啥区别啊?为什么String类型删除不会做异步删除?
彬彬回答
DEL 和 UNLINK 都是同步的释放 key 对象,区别是怎么释放后面的 value 对象
DEL 每次都是同步释放 value 部分,如果 value 很大,例如一个 list 里很多元素,这会阻塞 Redis 工作线程。
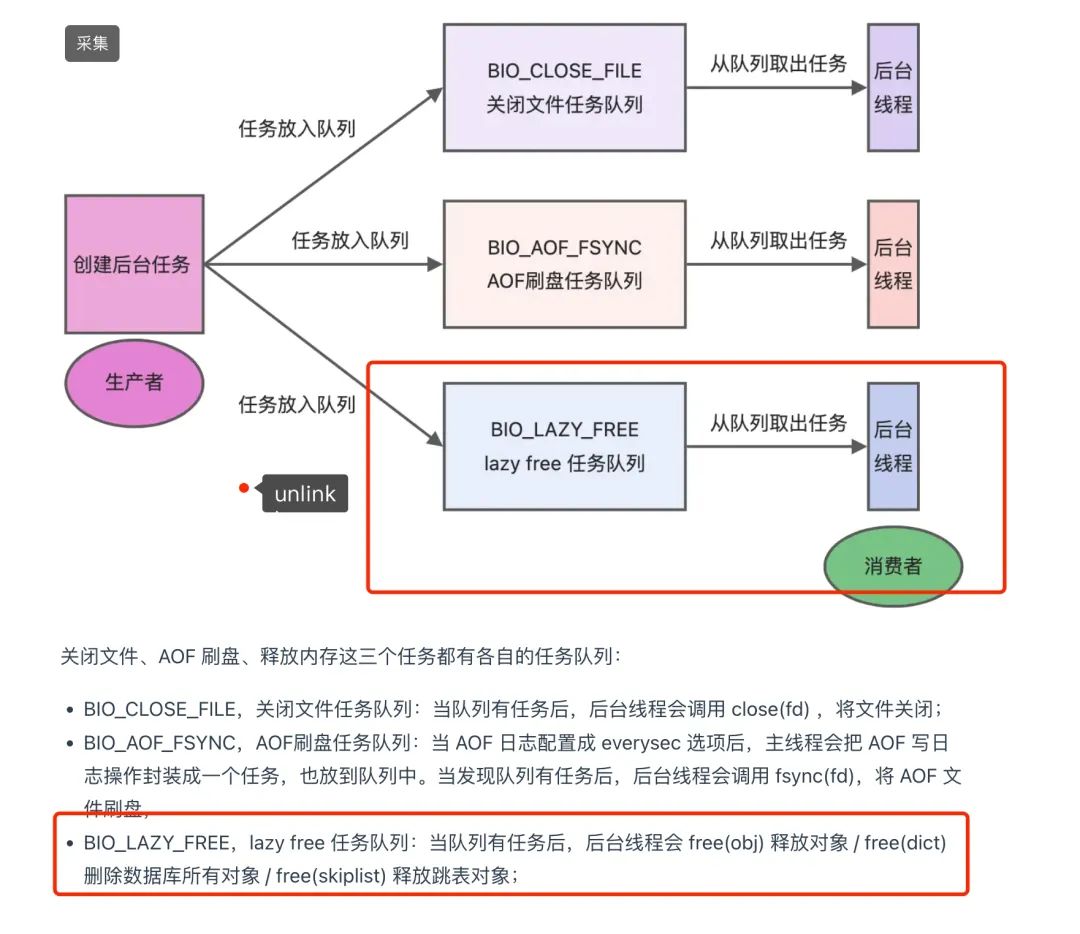
为了规避这个问题,4.0 里引出了 UNLINK 命令,可以异步释放 value 对象,放到一个子线程中。
这边需要引出一个释放的阈值,见后面解释。
目前默认的阈值是 64,例如只有一个 list 里面含有超过 64 个元素,才会异步释放,否则也是会同步释放 不同的数据结构的计算阈值的方式不一样,不过大致遵循一个原则:就是要释放多少块内存 即在小对象上使用 UNLINK 效果等同于 DEL,也是同步释放,区别就是要多走几个函数调用,例如判断 list 里需要判断列表的长度等
大 value 对象的释放是异步的,放在一个子线程上,小对象之所以不异步释放,是因为异步释放,主线程和子线程 之间需要做一些同步操作(这是有代价的),然后小对象释放,本身也很快就也不值得进行异步释放,内存释放也更及时。
即可能异步释放,实际上会比同步释放更慢,所以作者设置了个 64 的经验值
所以如果是一个小对象,DEL 和 UNLINK 其实一样;如果是一个大对象,UNLINK 会更加好。
所以大部分情况下都可以用 UNLINK 代替 DEL,而 Redis 其实也有个配置项,可以控制将 DEL 默认转换为 UNLINK(实现上都是同一个函数,只是入口 async 参数不同) 不过我们需要知道异步释放的好处(不阻塞主线程)和它的坏处(需要进行一些线程同步相关的操作,内存释放不及时)。
至于说 string 为啥不异步释放,主要是作者认为它是一整块内存空间,计算阈值的时候 string 的结果固定是 1,那么就 <= 64,就是同步释放。
在补充一点,前面举例是说的 list,底层是用的 quicklist,严格来说统计的是 quicklistNode 的节点数量,就不是列表元素数量。
像 zset 那些如果用的 ziplist/listpack 编码的话,这种计算出来的阈值是 1,就也不是元素数量。如果是跳表编码的话就是统计的元素数量。
然后至于选择的话,大部分情况可以无脑用 UNLINK,不过需要知道坏处。
例如对于每一次的 async delete,主线程给子线程提交任务时需要加锁解锁,bio 子线程消费任务的时候也要加锁解锁,要做一些线程同步,还有线程上下文切换,这些都是可能会有的潜在的问题,如果小元素都异步释放的话,的确代价可能会大,多线程做事情的确是会有这些麻烦。
可以多做压测来验证环境里到底哪个好,不过大部分情况这些我们不用关系,只要写代码的时候有意识的注意大 key 的释放就好。