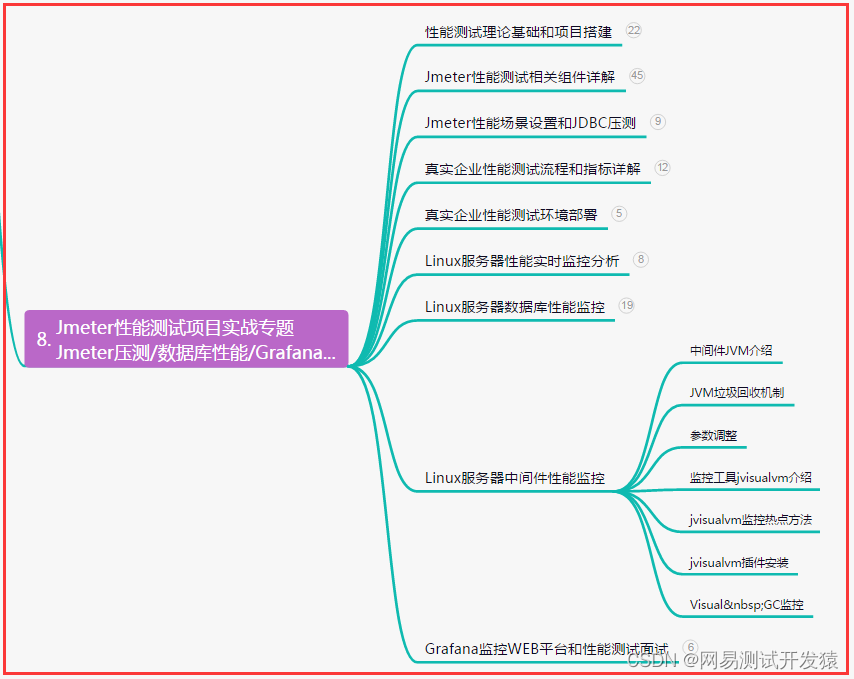
Coggle 30 Days of ML(23年7月)任务五:XGBoost训练与预测
任务五:使用TFIDF特征和XGBoost完成训练和预测
- 说明:在这个任务中,你需要使用TFIDF特征和XGBoost算法完成训练和预测,进一步提升文本分类的性能。
- 实践步骤:
- 准备TFIDF特征矩阵和相应的标签。
- 划分训练集和测试集。
- 使用Sklearn中的XGBoost算法进行训练,并使用训练好的模型对测试集进行预测。
- 评估模型的性能,如准确率、精确率、召回率等指标。
对于这一部分来说,我们只需要换一下模型即可,从线性模型换成一个比较强大的XGBoost模型即可完成,所以主要在评估结果中
TFIDF提取特征
首先使用任务三中的方法先提取特征
tfidf = TfidfVectorizer(token_pattern=r'(?u)\b\w\w+\b', max_features=4000, ngram_range=(1, 2))
train_tfidf = tfidf.fit_transform(train_data['content'])
test_tfidf = tfidf.fit_transform(test_data['content'])
这样我们就一句得到了TFIDF的特征矩阵,接下来我们就可以进行下一步的训练和测试了
训练XGBoost
这里修改为训练XGBoost模型
model = xgb.XGBClassifier()
model.fit(train_tfidf, train_data['label'])
训练完以后,我们就得到了一个不错的XGB模型,接下来我们可以进行评估模型的性能
评估模型
首先我们可以计算一下准确率,从结果上来看,准确率很圆满为100%
predictions = model.predict(train_tfidf)
accuracy = accuracy_score(train_data['label'], predictions)
print("Accuracy:", accuracy)
Accuracy: 1.0
我们还计算了精确率和召回率的指标,均为100%
from sklearn.metrics import precision_score, recall_score
precision = precision_score(train_data['label'], predictions)
recall = recall_score(train_data['label'], predictions)
print("Precision:", precision)
print("Recall:", recall)
Precision: 1.0
Recall: 1.0
模型预测及提交
最后利用模型对测试集进行预测,得到结果文件
submit = pd.read_csv('ChatGPT/sample_submit.csv')
submit = submit.sort_values(by='name')
submit['label'] = model.predict(test_tfidf).astype(int)
submit.to_csv('ChatGPT/xgb.csv', index=None)
经过提交以后,最后的分数为0.8848,从结果上来看,还是存在一些过拟合的,还是需要对其进行一些调参以得到更好的结果,并且可能还是需要一个验证集来检测结果是否过拟合,减小过拟合应该可以得到不错的分数