文章目录
- 1 慢日志实验环境准备
- 2 开始实验
- 2.1 实验 1:超过查询时间相关慢日志并观察
- 2.2 实验 2:不使用索引相关慢日志并观察
- 2.3 实验 3:打印额外的慢日志信息
- 2.4 实验 4:使用 mysqldumpslow 工具分析日志文件
- 2.5 实验 5:修改慢日志目的地为表并观察
- 3 分析实验结果
- 4 参考资料
实验的 mysql 版本是 8.0.26 MySQL Community Server - GPL,如果读者是 5.7 版本也关系不大,只是有些微小差别
1 慢日志实验环境准备
-
准备数据表
create table t( a int unsigned not null auto_increment, b char(200), primary key(a) ) engine = InnoDB charset = UTF8; -
创建生成数据的存储过程 load_t
-- 关闭事务自动提交 set autocommit = off; -- 创建存储过程 load_t(这个符号是随便的,只要对称) delimiter // create procedure load_t (count int unsigned) begin set @c = 0; while @c < count do -- 生成随机的 10 个重复的英文字符 insert into t select null, repeat(char(97+rand()*26),200); set @c=@c+1; end while; end; // -
执行生成 10w 数据的存储过程
备注:反复执行 10 次该存储过程。当然你也可以一次性指定生成 10w 条数据。只是开发规范中要求在存储过程中不写提交而把提交控制交给用户,用户提交要做到多次提交少量提交(不要一次几万数据量)
begin; call load_t(10000); commit; -
检验生成的数据量
mysql> select count(*) from t; +----------+ | count(*) | +----------+ | 100000 | +----------+ 1 row in set (0.06 sec)mysql 太快了,10w 数据的全表扫描也只要 0.06 秒,看来我们的慢查询的时间要设置的小一些
2 开始实验
慢查询日志 (slow log) 可帮助 DBA 定位可能存在问题的 SQL 语句,从而进行 SQL 语句层面的优化。因为慢查询日志是影响性能的,所以一般也是临时使用慢查询日志,在默认情况下,MySQL 数据库并不启动慢查询日志,用户需要手工将这个参数设为 ON
与慢查询相关的系统变量如下:
-
slow_query_log是否开启慢查询日志,默认是 OFF,需要开启
-
slow_query_log_file慢查询日志文件的名称,默认是:*
host_name*-slow.log -
log_output日志的输出目的地,默认是 FILE,可选的值有 TABLE、FILE、NONE,可以配置多个
-
long_query_time慢查询阈值,默认是 10 秒。实验可以设置小一点因为 10w 数据量对 mysql 没压力,呜呜
-
min_examined_row_limit最小达到多少行限制才会被记录,默认是 0
-
log_queries_not_using_indexes是否记录不使用索引的查询,默认是 OFF
-
log_throttle_queries_not_using_indexes不使用的查询记录阈值,默认是 0。当不使用索引的查询太多会导致频繁记录日志,可以设置为每分钟只记录多少条,超过的条数会在日志有警告⚠️
-
log_slow_extra在日志文件中记录慢查询的额外信息。这个比普通的记录多了很多信息,更加有助于我们分析慢的原因
2.1 实验 1:超过查询时间相关慢日志并观察
-
开启慢查询并设置慢查询的时间
-- 开启慢查询 mysql> set global slow_query_log = on; Query OK, 0 rows affected (0.00 sec) -- 设置慢查询时间为 0.01 秒 mysql> set long_query_time = 0.01; Query OK, 0 rows affected (0.00 sec) -
查看日志文件名称并监控日志文件
mysql> show variables like 'slow_query_log%'; +---------------------+-----------------------------------+ | Variable_name | Value | +---------------------+-----------------------------------+ | slow_query_log | ON | | slow_query_log_file | /var/lib/mysql/server120-slow.log | +---------------------+-----------------------------------+ 2 rows in set (0.00 sec)# 监控日志文件 tail -f /var/lib/mysql/server120-slow.log -
触发时间慢查询
select sleep(1); select count(*) from t;
-
实验结果
超过设置时间的查询会被记录到慢日志文件中,日志的格式下文会简单说明
2.2 实验 2:不使用索引相关慢日志并观察
-
开启慢查询,设置记录不使用索引的查询
-- 开启慢日志 set global slow_query_log = on; -- 设置超时时间为 10 秒,排除时间对不使用索引记录日志的影响 set long_query_time = 10; -- 设置记录不使用索引的查询 set global log_queries_not_using_indexes = on; -
不使用索引查询并观察日志变化
-- 设置结果不打印到屏幕 pager less -S; -- 执行全表查询,必然不会使用索引 select count(*) from t;
即使查询的时间没有超过设定的 10 秒,但是因为没有索引还是会被记录下来
-
通过
log_throttle_queries_not_using_indexes控制不使用索引的查询被频繁记录到日志该系统变量指定没分钟只记录多少条不使用索引的查询,超过的只会打印条数警告
-- set global log_throttle_queries_not_using_indexes = 5; pager less -S; -- 快速执行 8 条如下语句观察结果 select count(*) from t;
-
实验结果
1、超过设置时间的查询 跟 没有使用索引的查询 会分别记录到慢日志文件中,它们相互独立
2、如设置了不使用索引查询的阈值,那么只会记录指定条数,超过的条数会通过警告打印在慢日志文件中,可以通过警告了解到还有多少不使用索引的查询供以后分析
2.3 实验 3:打印额外的慢日志信息
-
在实验 1 或实验 2 的基础上继续
-
开启
log_slow_extraset global log_slow_extra = on; -
执行一条查询并观察
select count(*) from t where b like 'aaaaaaa%';
-
实验结果
比不设置变量后多了很多的信息,每个字段的含义会在下文简单说明
2.4 实验 4:使用 mysqldumpslow 工具分析日志文件
DBA 可以通过慢查询日志来找出有问题的 SQL 语句,对其进行优化。然而随着 MySQL 数据库服务器运行时间的增加,可能会有越来越多的 SQL 查询被记录到了慢查询日志文件中,此时要分析该文件就显得不是那么简单和直观的了。而这时 MySQL 数据库提供 mysqldumpslow 命令,可以很好地帮助 DBA 解决该问题
-
查看命令帮助
mysqldumpslow --help -
执行命令分析
# 按平均查询时间排序列出最高的 10 条记录 mysqldumpslow -s at -n 10 /var/lib/mysql/server120-slow.log -
观察结果

-
实验结果
1、上图按平均查询时间列出了前 10 条记录
2、mysqldumpslow 分析工具对慢日志进行了总体的分析,把相似查询进行了合并
3、字符
N、S表示数字和字符串,有点占位符变量的意思;如果我们需要知道具体代表的数字完全可以去日志中模糊匹配找到具体的数字
2.5 实验 5:修改慢日志目的地为表并观察
比较简单。在实验 1 的基础上进行
-
把日志输出目的地改为表
set global log_output = 'TABLE'; set long_query_time = 1; -
执行一条超时查询并观察表中的内容
select sleep(1.2);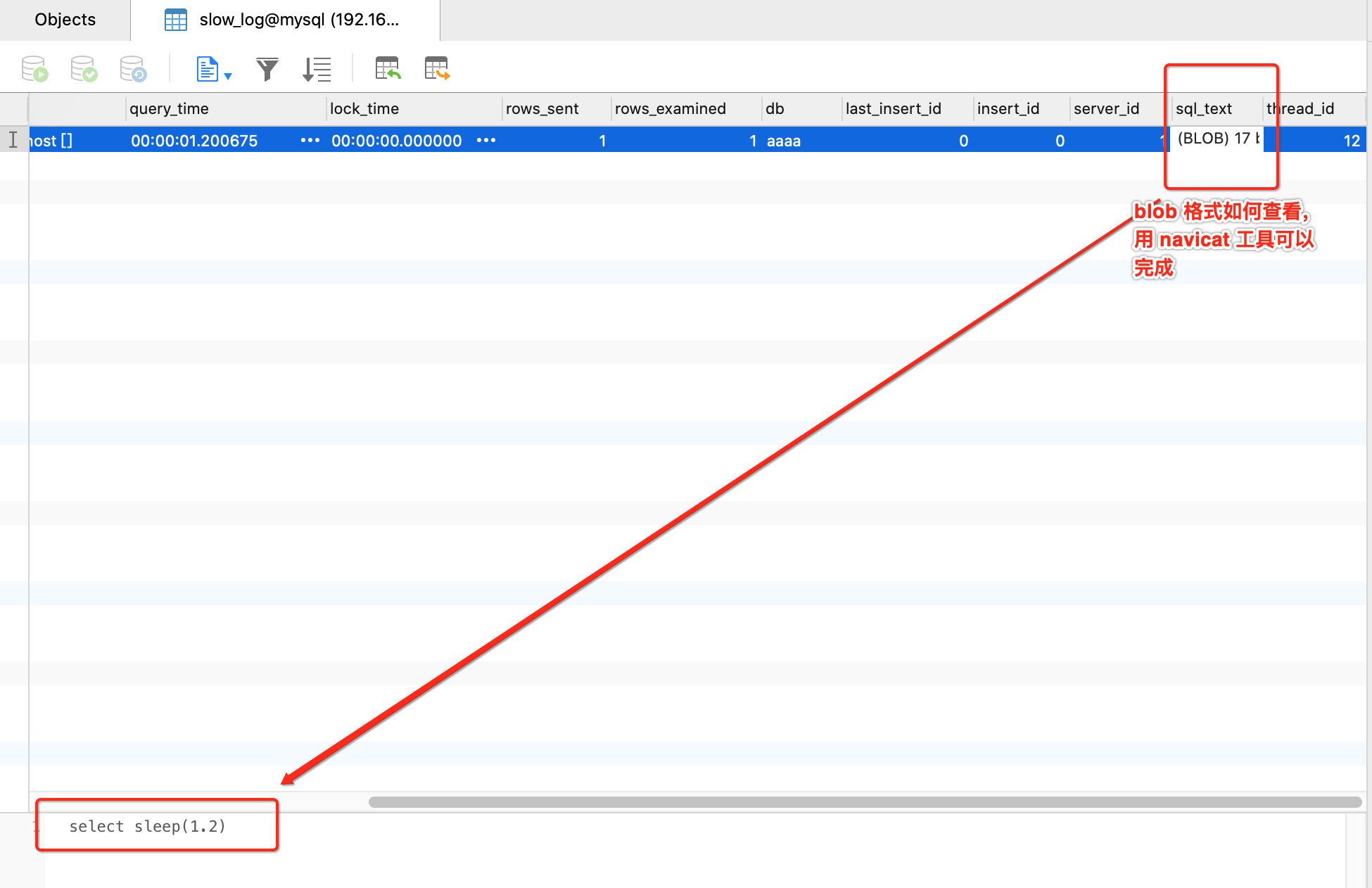
-
结果分析
比慢日志更加直观更利于查询,但可能相对信息会少一点
3 分析实验结果
通过指定以上的 3 个实验比较直观的可以得出的实验结果有:
- 超过查询时间的查询会被记录到日志文件中
- 超过时间的查询 与 不使用索引的查询 相互独立互不影响
- 通过设置
log_slow_extra可以获取许多额外信息
如下是对日志文件的打印格式简单说明:
-
Query_time:
duration查询时间
-
Rows_sent:
N发送给客户端的行数
-
Rows_examined:
服务器扫描的行数。这个值一般比 Rows_sent 小,如果是全表扫描一般就是表的行数,但是发送给客户端可能就 1 条,如:上面的实验 3
4 参考资料
官网: https://dev.mysql.com/doc/refman/8.0/en/slow-query-log.html
日志文件输出目的地:参考我的文章:《5.4.1 Selecting General Query Log and Slow Query Log Output Destinations.md》
navicat 如何查看 BLOB 格式:参考我的文章:《Navicat 查看字段类型为 BLOB 的内容.md》