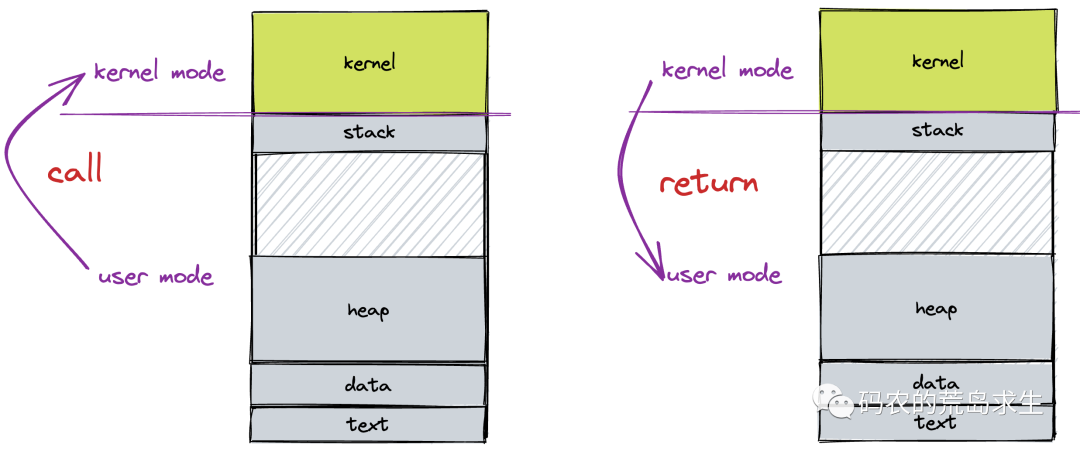
| 题目 | MARLIN: Masked Autoencoder for facial video Representation LearnINg |
|---|---|
| 译题 | MARLIN:用于面部视频表示的 maked 自动编码器 LearnINg |
| 时间 | 2023年 |
| 期刊/会议 | CVPR |
论文链接:MARLIN_MASKED_Autoencoder_for_Facial_Video_Representation_Learning
MARLIN:用于面部视频表示的 maked 自动编码器 Learning
摘要:本文提出了一种从视频中学习通用面部表示的自监督方法,该方法可以在各种面部分析任务中进行转换,如面部属性识别(FAR)、面部表情识别(FER)、深度伪造检测(DFD)和嘴唇同步(LS)。我们提出的框架名为 MARLIN ,是一种面部视频屏蔽自动编码器,它从大量可用的无注释网络爬行面部视频中学习高度鲁棒和通用的面部嵌入。作为一项具有挑战性的辅助任务,MARLIN 从主要包括眼睛、鼻子、嘴巴、嘴唇和皮肤的密集面部区域重建面部的时空细节,以捕捉局部和全局方面,进而帮助编码通用和可转移特征。通过对不同下游任务的各种实验,我们证明 MARLIN 是一款出色的面部视频编码器和特征提取器,在各种情况下都能始终如一地表现良好,包括FAR(比监督基准增益1.13%)、FER(比无监督基准增益2.64%)、DFD(比无监管基准增益1.86%),LS(Frechet Inception Distance 增益29.36%),甚至在低数据状态下也是如此。
1 Introduction
面部分析任务[34,43,70,85]为人类非言语行为分析提供了基本线索,并有助于展开关于社交[36]、沟通[40]、认知[68]的有意义的见解,在人机交互(HCI)和情感计算领域具有潜在应用。最近,我们见证了深度神经网络模型在解决面部分析任务方面的重大进展,如面部属性识别(FAR)[34,85]、面部表情识别(FER)[48]、深度伪造检测(DFD)[70]和嘴唇同步(LS)[43]。虽然这些深度模型可以实现可注释的性能,但它们通常需要大规模的注释数据集,这不仅是一个资源昂贵和耗时的过程,而且对于一些需要领域专业知识进行注释的应用程序(例如 FER )来说也是不可行的。
为此,自监督预训练[26,37,71]最近成为解决完全监督方法局限性的有效策略,因为它能够从非注释数据中进行通用表示学习,然后可以在具有有限标签的任务之间进行转移。对于自然场景和物体的图像,使用自蒸馏[14]、对比学习[18,19]、解决拼图等文本前任务[53]以及最近的自动编码[37,71]的自监督学习方法甚至优于监督学习方法。
尽管这些自监督方法在学习自然场景图像和视频的可伸缩和通用表示方面做出了承诺,但尚未对这些方法从面部视频数据中学习表示进行研究。面部表示学习需要跟踪精细的面部特定细节,而线性管掩蔽可能无法完美捕捉这些细节[71]。到目前为止,大多数与面部分析任务相关的现有方法都是高度专业化的,并开发了以完全监督的方式训练的任务特定模型[46,54,63],而最近很少有人致力于学习基于图像的通用面部编码[10,84]。这些密切相关的工作[10,84]要么专注于探索训练数据集在大小和质量方面的属性[10],要么以视觉语言的方式进行预训练[84]。这些工作[10,84]很难缩放,因为它们使用静态图像级的面部信息,并且图像字幕对与上下文信息而不是面部高度相关。

在本文中,我们的目标是以自监督的方式学习人脸相关下游任务的通用和任务无关表示(见图1)。为此,我们使用了一种具有面部引导掩蔽策略的掩蔽自动编码器[37,71],该策略学习使用未注释的视频从密集掩蔽的面部区域重建面部的时空细节。与现有的自然场景视频方法[71]不同,在现有方法中,tubemasking 是用没有任何语义信息的视频的静态部分初始化的,我们的方法动态跟踪面部,然后使用现成的面部解析器(即 FaceXZoo [75])开发面部部分引导的 Tubemask 策略。因此,我们提出了一项更具挑战性的任务,鼓励模型学习时空表示,以覆盖局部和全局信息。受先前工作[27,60]的启发,这些工作显示了高质量的重建结果以及丰富和通用的潜在特征,我们在掩蔽编码的基础上加入了对抗性损失,以提高重建质量。我们的实验结果表明,我们提出的框架 MARLIN 学习了高度通用的面部编码,该编码可以在不同的面部分析任务(如 FER、DFD、FAR 和 LS )之间很好地扩展和传输,并相对于最先进的基准实现了有利的性能增益。总之,我们的主要贡献是:
- 我们提出了 MARLIN ,这是一种通用的、与任务无关的面部编码器,它以自监督的方式从大量可用的无注释网络爬行面部视频中学习鲁棒和可转移的面部表示。
- 作为一项具有挑战性的辅助任务,我们建议从密集的面部区域重建面部的时空细节。所提出的面部区域引导管掩蔽(又名 Fasking )策略旨在从面部视频中学习局部和全局方面,这反过来又有助于对通用和可转移特征进行编码。
- 通过广泛的定量和定性分析,我们发现 MARLIN 学习了丰富、通用、可转移和鲁棒的面部表示,它在各种下游任务中始终表现良好,包括 FAR (比监督基准提高1.13%)、FER(比无监督基准提高2.64%)、DFD(比无监管基准提高1.86%),LS(Frechet Inception Distance增益29.36%),甚至在少数镜头设置中也是如此。
2 Related work
屏蔽自动编码器。基于掩蔽区域重构的假设,掩蔽自动编码器学习鲁棒和可转移的表示。掩码自动编码的动机是上下文编码器[56]和去噪编码器[73]。在基于 BERT [26]的掩蔽成功后,视觉界还探索了掩蔽自动编码的不同设计选择,如像素级掩蔽[17,37,80]、令牌级掩蔽[29]和基于深度特征的掩蔽[6,77],使用视觉转换器[44,52]。类似地,为了对输入数据的时空模式进行建模,最近引入了掩蔽运动建模[69]和管掩蔽[71]策略。沿着这条线,MARLIN 掩蔽并重建特定领域的面部部分,以学习通用的面部表示。
面部表征学习。到目前为止,大多数现有的面部分析方法都是以特定任务的方式,以完全监督的方式[46,54,63]对手动注释的数据进行的,以提高性能。任何最先进的模型在基准数据集上的性能都会受到训练期间使用的注释数据的质量和数量的影响。表1显示了过去十年[1]中为促进面部验证( LFW[39]、MS-cele1M[34]、VGG-Face[54]、VGGFace2[13])、面部属性识别(CelebA[50]、CelebV-HQ[85])、面部情绪识别(CMU-MOSEI[83])、,深度伪造检测(FF++[62])和嘴唇同步(LRS2[22])。然而,数据管理遇到了一些挑战,例如对专用硬件的要求(例如,FER和行动单元数据),阻止多个数据集合并的数据分布差异[10],以及最重要的耗时和资源昂贵的注释过程。为了消除这些缺点,一些现有的方法[20,81,82]采用了通过图像或视频合成的数据增强策略,因为生成对抗性网络(GAN)[20,67,81,82]和其他生成技术[16,35]推动的人脸生成技术的激增有助于逼真的人脸生成,即使可以控制面部属性。这些生成技术在数量上增加了训练集的变化,但在某些情况下,由于特定领域的不一致性和更重要的是高网络复杂性,它在定性方面仍然滞后。

为此,最近很少有工作旨在在有限的监督下学习基于图像的任务特定面部编码[3,9,10,65,84,86,86]。最密切相关的现有工作[10,84]要么专注于探索训练数据集在大小和质量方面的属性[10],要么以视觉语言的方式进行预训练[84]。这些工作10,84]很难缩放,因为它们使用静态图像级的面部信息,并且图像字幕对与上下文信息而不是面部高度相关。在这项工作中,我们的目标是开发一种通用的、通用的、与任务无关的面部编码器,该编码器可以从网络抓取的无注释数据中学习。我们的实验分析表明,MARLIN 可以将潜在空间流形与任何所需的下游任务特定标签空间对齐。因此,MARLIN 有能力在许多低资源的现实世界应用中充当强大的面部编码器或特征提取器。
3 MARLIN
我们的目标是从大量可用的非注释面部视频数据中学习稳健和可转移的通用面部表示[78]。如果我们从整体上思考,面部特定任务涉及两个不同的方面:a)面部外观相关属性,如面部的部分(鼻子、眼睛、嘴唇、头发等)、面部形状和纹理,这些主要需要空间调查;以及b)面部动作,例如情绪、面部动作编码系统(FACS)、需要时间信息的嘴唇同步。因此,为了学习强、鲁棒和可转移的表示,时空建模是非常可取的。为此,我们提出的框架 MARLIN 采用了面部区域引导的掩蔽策略,这为自监督表示学习提出了一项具有挑战性的辅助重建任务(见图2)。为了便于从掩蔽自动编码器中学习,我们主要选择 YouTube Faces[78]数据集,该数据集使用来自具有变体的 YouTuber 的网络爬行面部视频,该视频在不同的现实生活条件下具有变化。
3.1 面部表示学习
准备工作。MARLIN 由编码器( F ϕ ϵ \mathcal{F}_{\phi_\epsilon} Fϕϵ)、解码器( F ϕ D \mathcal{F}_{\phi_\mathcal{D}} FϕD)和鉴别器( F ϕ Γ \mathcal{F}_{\phi_\Gamma} FϕΓ)组成,分别具有嵌入参数 ϕ ϵ \phi_\epsilon ϕϵ、 ϕ D \phi_\mathcal{D} ϕD 和 ϕ Γ \phi_\Gamma ϕΓ。给定训练数据集 D = { V i } i = 1 N \mathcal{D}=\{ V_i \}_{i=1}^N D={Vi}i=1N ,其中 N N N 是数据集中视频的数量, V ∈ R C ∗ T 0 ∗ H 0 ∗ W 0 V \in \mathcal{R}^{C*T_0*H_0*W_0} V∈RC∗T0∗H0∗W0, ( C , T 0 , H 0 , W 0 ) ( C, T_0, H_0, W_0 ) (C,T0,H0,W0) 分别是原始视频的通道、时间深度、高度和宽度。从原始输入视频 V V V 中,我们跟踪并裁剪面部区域[75],然后进行随机时间采样,表示为 V ∈ R ( C ∗ T ∗ H ∗ W ) V \in \mathcal{R}^{(C*T*H*W)} V∈R(C∗T∗H∗W) ( T , H , W T,H,W T,H,W 分别是导出视频剪辑的修改后的时间深度、高度和宽度)。导出的视频剪辑 v v v 进一步映射到 ( k − n ) (k−n) (k−n) 个可见的和 n n n 个掩蔽的令牌,通过具有预定义掩蔽比 r = n k r=\dfrac{n}{k} r=kn 的面域引导掩蔽策略 ( F ϕ f ) ( \mathcal{F}_{\phi_f} ) (Fϕf) 表示为 { X ~ v ∈ R ( k − n ) ∗ e , X ~ m ∈ R n ∗ e } \{ \tilde{X}_v \in \mathbb{R}^{(k-n)*e}, \tilde{X}_m \in \mathbb{R}^{n*e} \} {X~v∈R(k−n)∗e,X~m∈Rn∗e} 。这里, e e e 是嵌入维度, k k k 是从 v v v 导出的令牌的总数,即 k = T t ∗ H h ∗ W w k=\dfrac{T}{t}*\dfrac{H}{h}*\dfrac{W}{w} k=tT∗hH∗wW ,给定的三维立方体令牌的每个维度为 t ∗ h ∗ w t*h*w t∗h∗w 。因此, MARLIN 在上述令牌空间中注入面部区域特定的领域知识,以通过掩蔽来指导表示学习。
可见标记
X
~
v
\tilde{X}_v
X~v 通过以下映射函数
F
ϕ
ϵ
:
X
~
v
→
z
\mathcal{F}_{\phi_\epsilon} : \tilde{X}_v \to z
Fϕϵ:X~v→z 映射到潜在空间
z
z
z 。潜在空间特征
z
z
z 被进一步馈送到解码器
F
ϕ
D
\mathcal{F}_{\phi_\mathcal{D}}
FϕD,解码器
F
ϕ
D
\mathcal{F}_{\phi_\mathcal{D}}
FϕD 通过以下映射
F
ϕ
d
\mathcal{F}_{\phi_\mathcal{d}}
Fϕd :将
z
z
z 重构为
n
n
n 个掩蔽令牌
F
ϕ
d
:
z
→
X
m
′
\mathcal{F}_{\phi_d}: z \to X'_m
Fϕd:z→Xm′ 。在解码器中,相应的可见和掩蔽的 3D 立方体包含表示为
e
=
C
t
h
w
e=Cthw
e=Cthw 的平坦原始像素。简言之,给定可见令牌
X
~
v
\tilde{X}_v
X~v,我们通过以下函数重建掩蔽令牌:
X
m
′
=
F
ϕ
D
∘
F
ϕ
ϵ
(
X
~
v
)
(
1
)
X'_m = \mathcal{F}_{\phi_\mathcal{D}} \circ \mathcal{F}_{\phi_\epsilon}(\tilde{X}_v) \kern10em(1)
Xm′=FϕD∘Fϕϵ(X~v)(1)
从原始像素重建时空面部模式是非常具有挑战性的,我们部署了一个具有对抗性训练的鉴别器
F
ϕ
Γ
\mathcal{F}_{\phi_{\Gamma}}
FϕΓ 以进行更好的合成。
3.2 自监督的表征学习
MARLIN 的自监督预训练策略由以下三个主要组成部分组成:a)面部区域引导管式蒙面(Fasking)。为了捕捉时空对应关系,我们部署了面部区域特定的管道掩蔽策略,如下[71]。我们为每个时空立方体在时间轴上动态跟踪和掩盖面部成分。我们基于面部区域的管状掩蔽策略确保在整个时间立方体中掩蔽相同的面部区域,从而提出了一项具有挑战性的重建任务,并促进了局部和全局面部细节的学习(见Alg.1)。由于掩蔽的时空立方体看起来像可变形的弯曲管,我们将其称为面部区域引导管掩蔽,也称为 Fasking 。

我们从使用 FaceXZoo [75]库进行人脸解析开始,该库将面部区域划分为以下部分{左眼、右眼、鼻子、嘴巴、头发、皮肤、背景}(图第2(b)段)。在面部区域中,我们将以下集合
P
=
左眼、右眼、鼻子、嘴巴、头发
P={左眼、右眼、鼻子、嘴巴、头发}
P=左眼、右眼、鼻子、嘴巴、头发 优先于皮肤和背景,以保留面部特定的局部和稀疏特征。为了保持预定义的掩蔽比率
r
r
r,来自优先级集合
P
P
P 的面部区域在帧之间被掩蔽,首先是
{
b
a
c
k
g
r
o
u
n
d
,
s
k
i
n
}
\{background,skin\}
{background,skin} 掩蔽。因此,
F
a
s
k
i
n
g
Fasking
Fasking 生成
n
n
n 个掩蔽的和
(
k
−
n
)
(k−n)
(k−n) 个可见的令牌。在输入
v
v
v 的所有帧中,我们跟踪预定义集合中的特定面部区域,以编码和重建模型面部运动的时空变化。因此,在对特定主题的外观和细粒度细节进行编码的同时,时尚策略对重建提出了更多挑战。
b)屏蔽自动编码器。在 F a s k i n g Fasking Fasking 之后, ( k − n ) (k−n) (k−n)个可见令牌被输入到编码器 F ϕ ϵ \mathcal{F}_{\phi_\epsilon} Fϕϵ,编码器将令牌映射到潜在空间 z z z。可见令牌用作生成人脸的掩蔽对应物的参考。因此,解码 F ϕ D \mathcal{F}_{\phi_\mathcal{D}} FϕD 将潜在空间 z z z 映射到重新构建的掩蔽令牌 X m ′ X'_m Xm′。请注意,与 VideoMAE [71]类似,我们采用 V i T ViT ViT[28]架构作为 MARLIN 的主干。在掩蔽立方体 X m X_m Xm和它们的重构对应体 X m ′ X'_m Xm′ 之间施加重构损失( L r e c o n \mathcal{L}_{recon} Lrecon)以指导学习目标。
c) 对抗性适应战略。为了提高丰富表示学习的生成质量,我们在屏蔽自动编码器主干之上加入了对抗性自适应。根据先前的文献[27,60],对抗性训练提高了生成质量,这反过来又导致了丰富的潜在特征 z z z。如图2所示的鉴别器 F ϕ Γ \mathcal{F}_{\phi_\Gamma} FϕΓ 是一个基于MLP 的网络,它在 X m X_m Xm 和它们重构的对应物 X m ′ X'_m Xm′ 之间施加对抗性损失 L a d v \mathcal{L}_{adv} Ladv。
3.3 总的 MARLIN Loss
算法 2 总结了 MARLIN 框架的培训过程。MARLIN 主要施加(a)重建损失和(b)对抗性损失,以促进训练。
a)重构损失。给定输入掩码令牌
X
~
m
\tilde{X}_m
X~m,掩码自动编码器模块将其重构
X
′
m
X'm
X′m。为此,我们最小化 3D 令牌空间中的均方误差损失,以更新
(
F
ϕ
Γ
∘
F
ϕ
ϵ
∘
F
ϕ
f
)
(\mathcal{F}_{\phi_{\Gamma}} \circ \mathcal{F}_{\phi_\epsilon} \circ \mathcal{F}_{\phi_f})
(FϕΓ∘Fϕϵ∘Fϕf) 分支。损失定义为:
L
r
e
c
o
n
=
1
N
∑
i
=
1
N
∥
X
m
(
i
)
−
X
m
′
(
i
)
∥
2
(
2
)
\mathcal{L}_{recon}= \displaystyle\dfrac{1}{N} \displaystyle\sum_{i=1}^N \lVert X^{(i)}_m-X'^{(i)}_m \rVert_{2} \kern10em (2)
Lrecon=N1i=1∑N∥Xm(i)−Xm′(i)∥2(2)
其中
N
N
N 是
D
\mathbb{D}
D 中数据的总数,
X
m
(
i
)
X^{(i)}_m
Xm(i) 和
X
m
′
(
i
)
X'^{(i)}_m
Xm′(i) 是
D
\mathbb{D}
D 中第
i
i
i 个数据的掩码令牌和重构。
b)对抗性损失。对抗性自适应考虑了 Wassenstain GAN 损失[5],以更好地重建时空面部模态,这反过来又有助于学习丰富的表示。损失定义如下:
L
a
d
v
(
d
)
=
1
N
n
∑
i
=
1
N
(
)
(
3
)
L
a
d
v
(
g
)
=
1
N
n
∑
i
=
1
N
(
)
(
4
)
\mathcal{L}^{(d)}_{adv}=\displaystyle\dfrac{1}{Nn}\displaystyle\sum_{i=1}^N() \kern10em (3) \\ \mathcal{L}^{(g)}_{adv}=\displaystyle\dfrac{1}{Nn}\displaystyle\sum_{i=1}^N() \kern10em (4)
Ladv(d)=Nn1i=1∑N()(3)Ladv(g)=Nn1i=1∑N()(4)
因此,整体学习目标
L
\mathcal{L}
L 公式如下,其中
λ
W
λ_{W}
λW 是加权参数:
L
(
g
)
=
L
r
e
c
o
n
+
λ
W
L
a
d
v
(
g
)
(
5
)
L
(
d
)
=
L
a
d
v
(
d
)
(
6
)
\mathcal{L}^{(g)} = \mathcal{L}_{recon}+λ_{W}\mathcal{L}_{adv}^{(g)} \kern10em (5) \\ \mathcal{L}^{(d)} = \mathcal{L}^{(d)}_{adv} \kern10em (6)
L(g)=Lrecon+λWLadv(g)(5)L(d)=Ladv(d)(6)
在 MARLIN 的预训练阶段,
L
(
d
)
\mathcal{L}^{(d)}
L(d)更新参数
ϕ
d
i
s
\phi_{dis}
ϕdis ,
L
(
g
)
\mathcal{L}^{(g)}
L(g) 更新参数
ϕ
e
,
ϕ
d
\phi_{e}, \phi_{d}
ϕe,ϕd。
3.4 下游适应
我们提出的 MARLIN 框架以自监督的方式从面部视频中学习鲁棒和可转移的面部表示。根据标准评估协议,我们采用线性探测(LP)和微调(FT)对不同的人脸相关任务进行下游自适应(见图 2 推理模块)。给定任何特定于任务的下游数据集 D d o w n = { v j , y j } j = 1 N \mathbb{D}_{down} = \{ v_j, y_j \}^N_{j=1} Ddown={vj,yj}j=1N,我们部署具有嵌入参数 θ θ θ 的线性全连接(FC)层,以将潜在空间与编码器模块 F F F 的顶部的下游特定于任务标签空间对齐。对于线性探测,我们冻结骨干网络 F ϕ ϵ \mathcal{F}_{\phi_{\epsilon}} Fϕϵ,只更新 F θ \mathcal{F}_θ Fθ。另一方面,对于 F T FT FT,我们微调整个模块,即( F ϕ ϵ ∘ F θ \mathcal{F}_{\phi_{\epsilon}} \circ \mathcal{F}_θ Fϕϵ∘Fθ)。当 MARLIN 被用作 LP 的特征提取器时,它使用滑动时间窗口来提取输入人脸裁剪视频 V V V 的特征 Z Z Z,如图 2 所示。不同下游面部任务的细节如下所述:
面部属性识别(FAR)预测给定面部视频的外观和动作属性的存在,例如性别、种族、头发颜色和情绪。预测面部属性的问题可以被提出为一个高度依赖于丰富的空间编码的多标签学习问题。出于下游适应的目的,我们使用了来自 C e l e b V H Q CelebV HQ CelebVHQ[85]数据集的 28532 个训练、 3567 个验证视频和 3567 个测试视频。根据先前的工作[33,50,84],我们报告了平均精度(↑),曲线下面积(AUC↑) 所有属性。
面部表情识别(FER)任务对时空面部肌肉运动模式进行编码,以预测给定面部视频的相关对象的情绪(6类)和情绪(7类和2类)。我们在 C M U − M O S E I CMU-MOSEI CMU−MOSEI 数据集[7]上评估了 MARLIN 的性能,该数据集是一个会话语料库,具有 16726 个训练、1871 个验证数据和 4662 个测试数据。在之前的工作[7,25]之后,我们使用整体准确性(↑) 作为度量。
深度伪造检测(DFD)任务在给定来自 F F + + FF++ FF++(LQ)数据集的面部视频的情况下预测时空面部伪造[62]。对于下游适应,我们使用来自 F F + + FF++ FF++(LQ)数据集的 3600 个训练、 700 个验证样本和 700 个测试样本视频[62]。根据先前的文献[12,58,76],我们使用准确性(↑) 和AUC(↑) 作为评价指标。
嘴唇同步(LS)是另一个需要面部区域特定时空同步的研究领域。这种下游适应进一步阐述了 MARLIN 对人脸生成任务的适应能力。为了适应,我们用 MARLIN 替换了 Wav2Lip [57]中的面部编码器模块,并相应地调整时间窗口,即从 5 帧调整到 T T T 帧。为了进行评估,我们使用 L R S 2 LRS2 LRS2 [22]数据集,该数据集具有 45838 个训练、1082 个验证视频和 1243 个测试视频。根据先前的文献[57,74],我们使用唇同步误差距离(LSE-D↓), 唇同步误差置信度(LSE-C↑) 和 Frechet 起始距离(FID↓) [38]作为评估矩阵。
4.实验和结果
我们从定量(见第 4.2 节)和定性(见第 4.3 节)的角度全面比较了我们在不同下游适应任务上的方法。此外,我们还进行了广泛的消融研究,为我们的设计选择提供理由。
4.1 实验协议
数据集。我们在第 3.4 节中描述的不同面部分析任务上评估 MARLIN 框架。简言之,我们使用 C e l e b V − H Q CelebV-HQ CelebV−HQ [85]进行面部属性和动作预测,使用 C M U − M O S E I CMU-MOSEI CMU−MOSEI 数据集[7]进行会话情绪和情绪预测,使用 F F + + FF++ FF++(LQ)数据集[62]进行深度伪造检测,使用 L R S 2 LRS2 LRS2 [22]进行嘴唇同步。
设置。为了进行公平的比较,我们遵循特定于任务的先前文献[7,22,33,50,62,84]中提到的特定于数据集的实验协议。除了传统的评估之外,我们还执行了少镜头自适应策略,以显示 MARLIN 的鲁棒性和可转移性。
实现细节。我们用 N v i d i a R T X A 6000 G P U Nvidia RTX A6000 GPU NvidiaRTXA6000GPU 在 P y T o r c h PyTorch PyTorch[55]上实现了该方法。首先,给定面部视频的任何时间块,连续帧都是高度冗余的。因此,为了考虑在帧之间具有显著运动的语义上有意义的帧,我们采用最小时间步长值为 2 。给定输入视频(维度为3×16×224×224),立方体嵌入层生成维度为 2×16×16 的 8×14×14 个 3D 标记,以保存时空模式。使用 Fasking 策略(参见算法1), MARLIN 以预定义的掩蔽比率密集地掩蔽这些令牌。我们的经验分析表明, MARLIN 在高掩蔽率(90%)下工作良好。 MARLIN 的目标是从稀疏的可见标记生成掩蔽部分。在 Fasking 之后,每个令牌被映射到 768 的潜在空间嵌入维度。根据该潜在嵌入,在 3D 令牌空间中重建掩蔽部分,该 3D 令牌空间可以进一步映射到原始视频。为了进行公平的比较,我们使用 ViT-B 作为主干编码器,尽管消融研究中描述了其他 ViT 变体的影响。预训练超参数如下:基本学习率相对于整个批量大小线性缩放,学习率( lr )=基本学习率×批量大小/256。
对于自监督预训练,我们使用基本学习率为 1.5 e − 4 1.5e−4 1.5e−4,动量 β 1 = 0.9 , β 2 = 0.95 β_1=0.9,β_2=0.95 β1=0.9,β2=0.95 的 AdamW 优化器和学习率调度器(余弦衰减)[51]。对于线性探测,我们使用 Adam 优化器,其中 β 1 = 0.5 , β 2 = 0.9 β_1=0.5,β_2=0.9 β1=0.5,β2=0.9,基本学习率 1 e − 4 1e−4 1e−4,权重衰减 0 0 0。对于微调,我们使用 Adam 优化器,其中 β 1 = 0.5 , β 2 = 0.9 β_1=0.5,β_2=0.9 β1=0.5,β2=0.9,基本学习率 1 e − 4 1e−4 1e−4,没有任何权重衰减。
4.2定量分析
4.2.1 与最新(SOTA)面部分析任务的比较。
我们根据标准任务特定评估协议[7,22,33,50,62,84],比较了 MARLIN 与不同下游面部分析任务的性能。
面部属性。在表 2 中,我们比较了 MARLIN 与流行的反式异构体(即 MViT-v1 [30]和 MViT-v2 [49])和细胞神经网络(即 R3D [72])在 CelebV-HQ [85]数据集上的 LP 和 FT 适应性能。从表中可以看出,MARLIN 的 FT 版本比有监督的 MViT-v2 [49]变压器架构高1.13%(92.77%→ 93.90%)和0.33%(95.15%)→ 95.48%)。R3D CNN 模块也观察到了类似的模式。我们将 MARLIN 的性能增益归因于预训练策略,该策略对来自任何输入面部视频的通用、鲁棒和可转移特征进行编码。


情绪和情感。在表 3 中,我们同样比较了会话情感和情感在准确性方面的 LP 和 FT 适应表现(↑) 和 AUC (↑) 在 CMU-MOSEI [83]数据集上。请注意,MARLIN 是一种仅限视觉模态的编码器。结果表明,MARLIN 的表现与 SOTA 方法相比具有竞争力[25,45,49],尤其是它比无监督的 SOTA CAE-LR [45]强 2.64%(71.06%→ 73.70%)。对于情绪和 7 类情绪,它略微优于监督基准[49]。这些结果还表明,MARLIN 从预训练中学习到了高度通用、鲁棒和可转移的特征表示。


DeepFake检测。在表 4 中,我们比较了 FaceForensics++ [62]数据集上视频操作的性能,并根据视频级别的准确性报告了结果(↑) 和AUC(↑)。结果表明,MARLIN 的性能优于监督 SOTA 方法[2,8,15,21,24,32,47,59,61,72]。这是第一个只使用时空视觉信息异常来检测视频操纵的 SSL 工作。除非 F3Net, 它在时间维度上使用频率感知模式以监督的方式检测伪造品。而 MARLIN 与频率模式无关地学习面部表示,并可以从时空信号中检测异常。
嘴唇同步。为了进行公平的比较,我们采用了以下实验设置:1) W a v 2 L i p + V i T Wav2Lip+ViT Wav2Lip+ViT:比较 V i T ViT ViT 架构[28]对 S O T A C N N s SOTA CNNs SOTACNNs 和 MARLIN 的贡献,其中 V i T ViT ViT 的权重是在 L R S 2 LRS2 LRS2 [22]数据集上从头开始训练的。2) W a v 2 L i p + V i T + V i d e o M A E Wav2Lip+ViT+VideoMAE Wav2Lip+ViT+VideoMAE:比较香草 VideoMAE 与在 YTF [78]数据集上预先训练的 ViT 主干的贡献。2) W a v 2 L i p + V i T + M A R L I N Wav2Lip+ViT+MARLIN Wav2Lip+ViT+MARLIN:比较在 YTF [78]与 SOTA [57,66,74]和不同设计方面预先训练的 MARLIN 的贡献。实验结果如表 5 所示。LSE-D↓, LSE-C公司↑ 和FID↓ 作为遵循标准协议的评估指标[38,57,66,74]。唇同步分数的提高(LSE-D↓: 7.521→ 7.127;FID↓: 4.887→ 3.452)表明 MARLIN 学习了丰富的时空模式,这些模式是可转移的和鲁棒的。同样有趣的是, MARLIN 也适用于面部特有的细粒度特征。
4.2.2 很少镜头适应
最近很少有镜头适应受到关注,因为它的适应能力非常低[9,65,84,86]。根据标准评估协议[9,65,84,86],我们还研究了 MARLIN 的适应能力。给定任何下游数据集,我们使用有限的训练集标签来对齐输出歧管,同时通过 LP(MOSEI,CelebV-HQ)和 FT(FF+)策略保持测试集固定。从表 6 中可以看出,在不同的任务中,性能略有下降,这进一步表明 MARLIN 学习通用、可转移和自适应信息。

4.2.3消融实验
我们进行了广泛的消融研究,以显示每个组件的有效性。
1) 遮蔽比例。我们在 [0.05-0.95] 范围内使用不同的掩蔽比,并在 CMU-MOSEI [83]数据集上重复预训练,然后进行 LP 。从图 3 中,我们可以看出,大约 90% 的掩蔽比对于 MARLIN 来说是最佳的。在较小的掩蔽比(即≤0.5)下,重建任务可以获得更多的信息,这会降低特征质量。同样,超过 90% ,重建任务变得更具挑战性,导致性能下降。根据经验证据,我们在所有实验中都将掩蔽率设置为 90% 。

2) 蒙面策略。我们进一步将所提出的 Fasking 策略与现有的掩蔽策略[31,71]进行了比较,即帧掩蔽、随机掩蔽和管掩蔽。表 7 中的实证结果表明 Fasking 更好。
3) 不同的模块。我们逐步集成每个模块,并观察其对 CMU-MOSEI [83]和 FF++ [62]下游性能的影响,同时保持其他组件不变。从表 7 中,我们可以看出,Fasking 和对抗性训练(AT)的加入提高了性能,反映了每个组成部分的重要性。
4) 编码器架构。研究骨干编码器架构的影响,并比较 ViT-S、ViT-B 和 ViT-L(见表 7 )。我们观察到,更大的模型尺寸提高了性能。为了公平比较,我们使用了 ViT-B 编码器。

4.3 质量方面
为了了解学习特征的有效性,我们进一步进行了以下定性分析。
1) 面部属性。我们使用梯度加权类激活映射(Grad-CAM)[64]可视化 MARLIN 关注的重要区域。在图 4 顶部,热图结果基于 CelebV-HQ [85]数据集(外观任务)上 MARLIN 特征之上的 LP,表明 MARLIN 专注于面部属性,如头发、眼镜、帽子等。

2)嘴唇同步。在图 4 底部,我们给出了面部下部的生成结果,这是一项具有挑战性的任务。顶部、中间和底部的行分别显示了地面实况、香草 Wav2Lip [57]的输出和 MARLIN 的输出以及特写镜头。在这里,Wav2Lip 的 CNN 编码器未能定位唇部区域(如图 4 的 Wav2Lip 行所示,红色突出显示),而 MARLIN 尽管 fasking 策略上进行了预训练,但其自适应性足以为 MARLIN 的面部嘴唇同步任务生成更有效的结果。
5 总结
在本文中,我们旨在学习一种通用的面部编码器 MARLIN ,它具有自适应、鲁棒性和可转移性,适用于不同的面部分析任务。作为一项具有挑战性的辅助任务,MARLIN 从密集掩蔽的面部区域重建面部的时空细节,以捕捉局部和全局方面,这反过来又有助于编码通用和可转移特征。更广泛的影响。
我们相信 MARLIN 可以作为不同下游面部分析任务的良好特征提取器。由于其丰富的面部特征,可以很容易地将 MARLIN 部署在低资源(例如移动设备、Jetson Nano平台)设备中,用于现实世界的应用。局限性由于该模型是在 YouTube Face 数据集[78]上训练的,因此在身份的种族和文化背景方面可能存在潜在的偏见。当我们使用现有的人脸检测库[75]时,也可以在模型中引入潜在的偏差。我们将在更新后的版本中消除这些限制。