一、常用的网络模型训练技巧?
使用更大的 batch size。使用更大的 batch size 可以加快训练的进度。但是对于凸优化问题,收敛速度会随着 batch size 的增加而降低。所以在相同的 epoch 下,使用更大的 batch size 可能会导致验证集的 acc更低。所以可以使用以下技巧来解决问题。
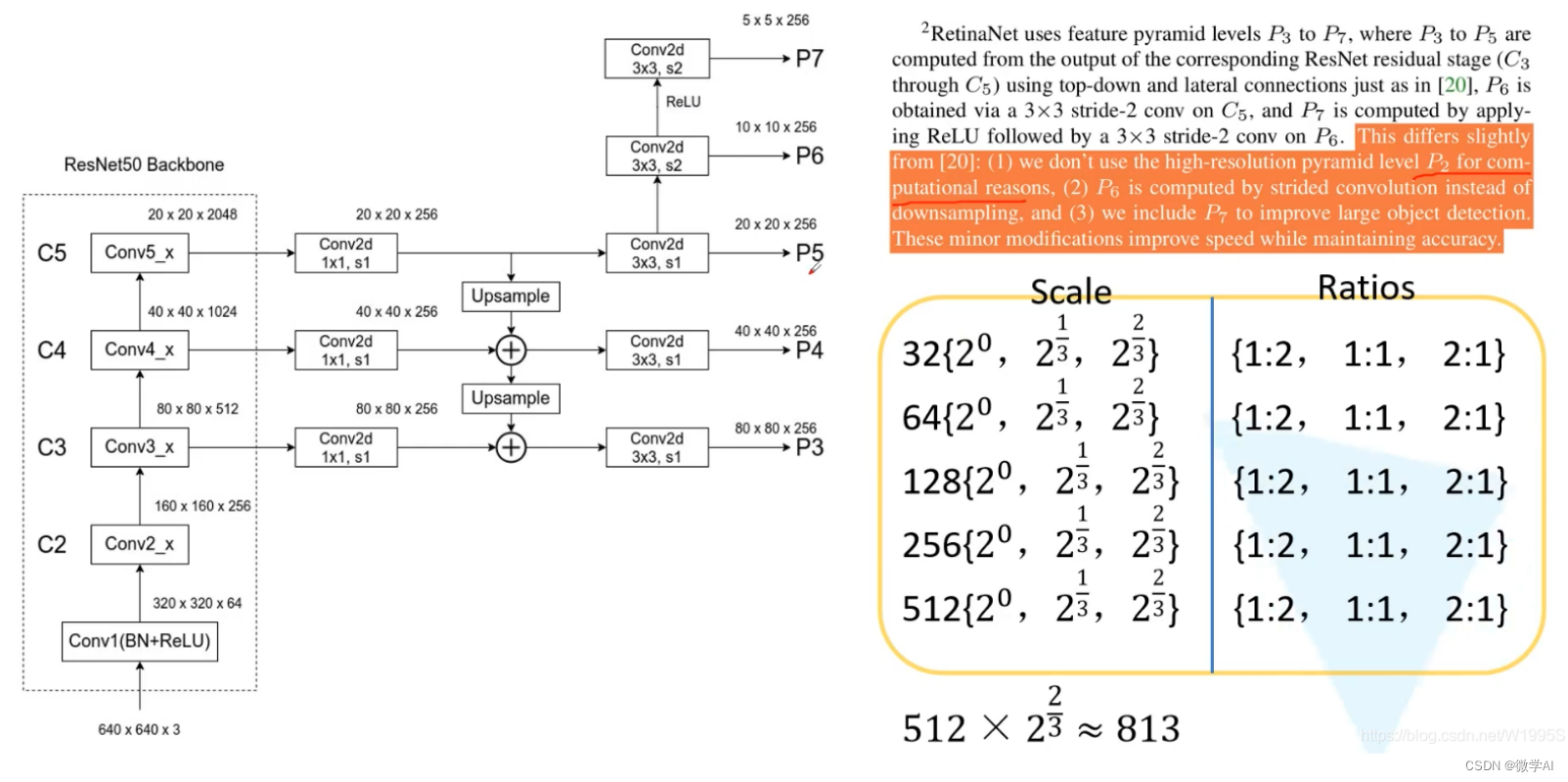
(1) linear scaling learning rate。使用更大的学习率,例如,当我们选择初始学习率为 0.1, batch size 为 256,当将 batch size 增大至 b 时,需要将初始学习率增加至 0.1 * b / 256
(2) learning rate warm up。选择前 n \mathrm{n} n 个 epoch 进行 warm up, 在这 n \mathrm{n} n 个 epoch 中线性地增加学习率至初始学习率, 在正常地进行 decay。
(3) zero γ \gamma γ 。在 residual block 中的 B N \mathrm{BN} BN 中, 首先进行标准化输入 x \mathrm{x} x, 得 到 x ^ \hat{x} x^, 再进行线性变化: γ x ^ + β \gamma \hat{x}+\beta γx^+β, 其中 γ \gamma γ 和 β \beta β 都是可以学习的参数, 其值被初始化为 1 和 0 , 而在这里, γ \gamma γ 被初始化为 0 。
(4) no bias decay。为了避免过拟合, 对于权重 weight 和 bias, 通常会使用 weight decay。但是在这里, 仅对 weight 使用 decay, 而不对 bias 进行 decay。
1、使用更低的数值精度。
2、cosine learning rate decay 。将学习率随着 epoch 的增大而不断衰减。
η
t
=
1
2
(
1
+
cos
(
t
π
T
)
)
η
\eta_{t}=\frac{1}{2}\left(1+\cos \left(\frac{t \pi}{T}\right)\right) \eta
ηt=21(1+cos(Ttπ))η
3、label smoothing。
4、knowledge distillation。
5、mixup training, cutout, random erase, data augmentation 等数据增强 方法。
二、过拟合问题
在机器学习中,过拟合(overfitting)会使模型的预测性能变差,通常发生在模型过于复杂的情况下,如参数过多等。在机器学习中,如果模型过于专注于特定的训练数据而错过了要点,那么该模型就被认为是过拟合。该模型提供的答案和正确答案相距甚远,即准确率降低。这类模型将无关数据中的噪声视为信号,对准确率造成负面影响。即使模型经过很好地训练使损失很小,也无济于事,它在新数据上的性能仍然很差。欠拟合是指模型未捕获数据的逻辑。因此,欠拟合模型具备较低的准确率和较高的损失。

如何确定模型是否过拟合?
构建模型时,数据会被分为 3 类:训练集、验证集和测试集。训练数据用来训练模型;验证集用于在每一步测试构建的模型;测试集用于最后评估模型。通常数据以 80:10:10 或 70:20:10 的比率分配。
在构建模型的过程中,在每个 epoch 中使用验证数据测试当前已构建的模型,得到模型的损失和准确率,以及每个 epoch 的验证损失和验证准确率。模型构建完成后,使用测试数据对模型进行测试并得到准确率。如果准确率和验证准确率存在较大的差异,则说明该模型是过拟合的。
如果验证集和测试集的损失都很高,那么就说明该模型是欠拟合的。
如何防止过拟合
交叉验证
交叉验证是防止过拟合的好方法。在交叉验证中,我们生成多个训练测试划分(splits)并调整模型。K-折验证是一种标准的交叉验证方法,即将数据分成 k 个子集,用其中一个子集进行验证,其他子集用于训练算法。
交叉验证允许调整超参数,性能是所有值的平均值。该方法计算成本较高,但不会浪费太多数据。交叉验证过程参见下图:

用更多数据进行训练
用更多相关数据训练模型有助于更好地识别信号,避免将噪声作为信号。数据增强是增加训练数据的一种方式,可以通过翻转(flipping)、平移(translation)、旋转(rotation)、缩放(scaling)、更改亮度(changing brightness)等方法来实现。
移除特征
移除特征能够降低模型的复杂性,并且在一定程度上避免噪声,使模型更高效。为了降低复杂度,我们可以移除层或减少神经元数量,使网络变小。
早停
对模型进行迭代训练时,我们可以度量每次迭代的性能。当验证损失开始增加时,我们应该停止训练模型,这样就能阻止过拟合。
下图展示了停止训练模型的时机:

正则化
正则化可用于降低模型的复杂性。这是通过惩罚损失函数完成的,可通过 L1 和 L2 两种方式完成,数学方程式如下:

L1 惩罚的目的是优化权重绝对值的总和。它生成一个简单且可解释的模型,且对于异常值是鲁棒的。

L2 惩罚权重值的平方和。该模型能够学习复杂的数据模式,但对于异常值不具备鲁棒性。
这两种正则化方法都有助于解决过拟合问题,读者可以根据需要选择使用。
Dropout
Dropout 是一种正则化方法,用于随机禁用神经网络单元。它可以在任何隐藏层或输入层上实现,但不能在输出层上实现。该方法可以免除对其他神经元的依赖,进而使网络学习独立的相关性。该方法能够降低网络的密度,如下图所示:

总结
过拟合是一个需要解决的问题,因为它会让我们无法有效地使用现有数据。有时我们也可以在构建模型之前,预估到会出现过拟合的情况。通过查看数据、收集数据的方式、采样方式,错误的假设,错误表征能够发现过拟合的预兆。为避免这种情况,请在建模之前先检查数据。但有时在预处理过程中无法检测到过拟合,而是在构建模型后才能检测出来。我们可以使用上述方法解决过拟合问题。
三、模型不收敛
1、忘记对你的数据进行归一化
2、忘记检查输出结果
3、没有对数据进行预处理
4、没有使用任何的正则化方法
5、使用了一个太大的 batch size
6、使用一个错误的学习率
7、在最后一层使用错误的激活函数
8、网络包含坏的梯度
9、网络权重没有正确的初始化
10、使用了一个太深的神经网络
11、隐藏层神经元数量设置不正确
对应的解决办法分别是:
对数据进行归一化,常用的归一化包括零均值归一化和线性函数归一化方法;
检测训练过程中每个阶段的数据结果,如果是图像数据可以考虑使用可视化的方法;
1、对数据进行预处理,包括做一些简单的转换;
2、采用正则化方法,比如 L2 正则,或者 dropout;
3、在训练的时候,找到一个可以容忍的最小的 batch 大小。可以让 GPU 并行使用最优的 batch 大小并不一定可以得到最好的准确率,因为更大的 batch 可能需要训练更多时间才能达到相同的准确率。所以大胆的从一个很小的 batch 大小开始训练,比如 16,8,甚至是 1。
4、不采用梯度裁剪。找出在训练过程中不会导致误差爆炸的最大学习率。将学习率设置为比这个低一个数量级,这可能是非常接近最佳学习率。
5、如果是在做回归任务,大部分情况下是不需要在最后一层使用任何激活函数;如果是分类任务,一般最后一层是用 sigmoid 激活函数;
6、如果你发现你的训练误差没有随着迭代次数的增加而变化,那么很可能就是出现了因为是 ReLU 激活函数导致的神经元死亡的情况。可以尝试使用如 leaky ReLU 或者 ELUs 等激活函数,看看是否还出现这种情况。
7、目前比较常用而且在任何情况下效果都不错的初始化方式包括了“he”,“xaiver”和“lecun”。所以可以任意选择其中一种,但是可以先进行实验来找到最适合你的任务的权值初始化方式。
8、从256到1024个隐藏神经元数量开始。然后,看看其他研究人员在相似应用上使用的数字