本文概要
本文讲主要从光场硬件结构设计以及软件处理方式的层面来介绍一下光场的相关内容,关于光场的优势和具体应用点并不在本文的主要范围内。
光场1.0
1. 结构原理说明
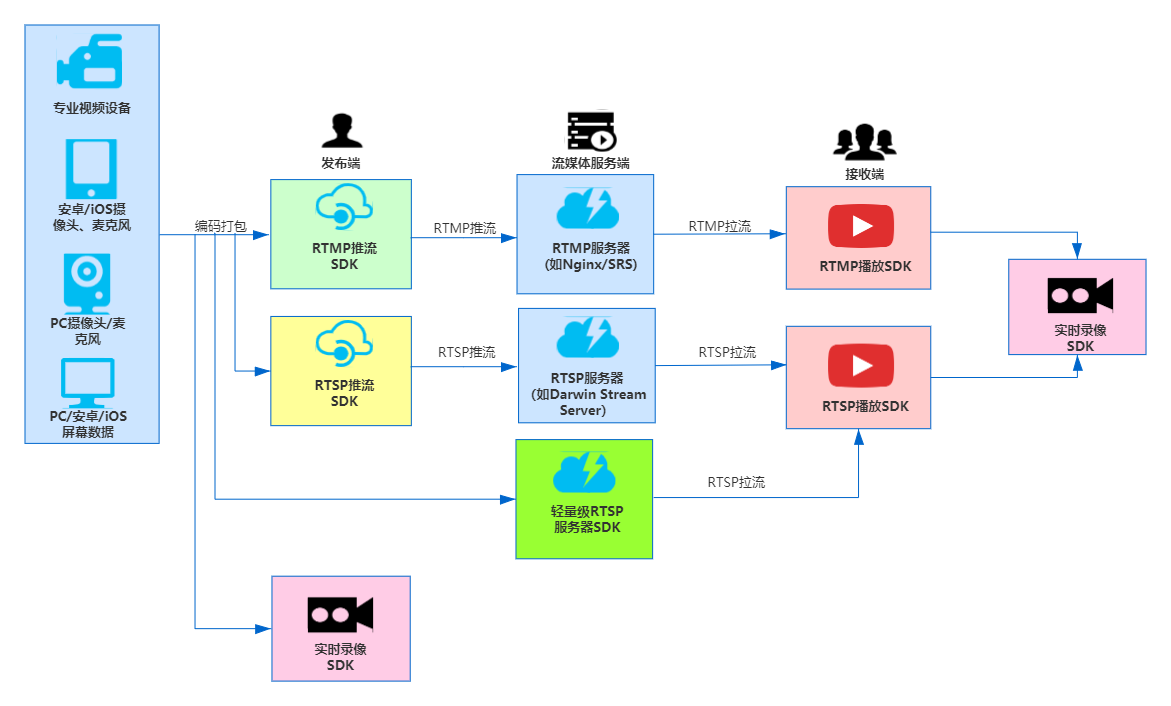
首先来介绍一下光场相机,那么什么是光场相机呢,光场相机经历了两代的发展,首先我们来介绍一下一代光场相机的主要结构及内容,以下简称“光场1.0”。接下来,让我们回到2005年2月,重温以下光场相机刚被发明出来的那篇论文——Light Field Photography with a Hand-held Plenoptic Camera ,该论文第一次提出了光场相机的概念,该论文提到的相机概念示意图如下图所示:
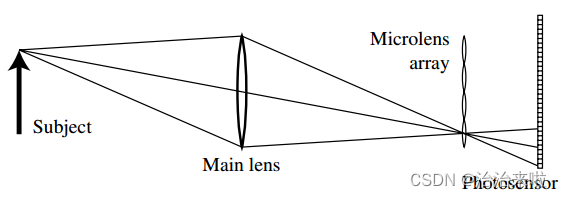
该相机由三部分组成:主镜头、微透镜阵列和对应的CCD(即上图中的Photosensor)。其中MLA(microlens array)放置在主透镜的成像面上(注意是成像面,不是焦平面,这也是很多初学者经常混淆的一个概念),CCD放置在对应的MLA的焦平面上。相机的这种布置有哪些优点呢?它又是如何做到可以记录光线的方向信息的呢?为了便于说明,我在图上添加了一些标记便于后续说明:1,2,3表示三条从物面发出的光线;4表示如果把ccd挪到mla的位置三条光线相交的像素点,5,6,7表示ccd在当前位置上面的三个像素点。
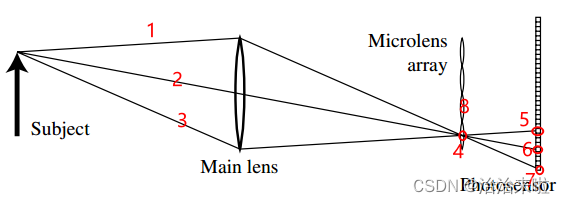
我们从上图可以看出:物面的Subject在Main lens的后面呈的是一个实像,假如我们把CCD放在对应的MLA的位置,那么上图中的subject发出的三条光线是不是就交互在了对应的ccd的一个像素4上,这样子通过这个像素4就无法分辨到底是三条光线的哪一条了,也就是一句常说的:传统相机成像是积分成像,可以说是三条光线的信息积分相加最终才是该点的像素的采集到的信息。
如果是把ccd后移到焦距位置,那么会有什么样的效果呢,5,6,7三个像素点分别代表交互在实像面位置的三条光线1,2,3的信息,这样子是不是就还原出了交互在4点的不同方向的光线信息,这就是一种在二维平面捕获光线的三维信息的方法。
但是难道不会出现8那个位置的光线也打到4对应的子透镜后面的像素区域造成混乱么,当然会啦,但是如果控制好对应的数值孔径匹配就行,该论文也提到了这一点内容如下图所示:
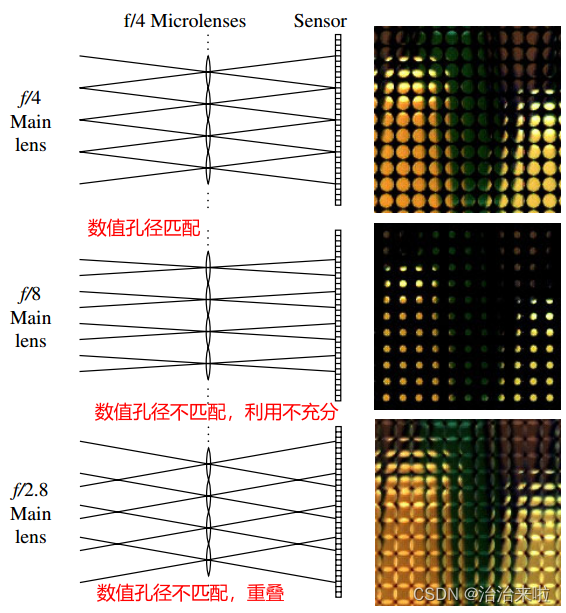
主透镜有对应的通光口径,只要保证主透镜的通光孔径正确就可以实现上图的数值孔径匹配的效果,即每个宏像素(指的是上图的每一个小圆形的大的像素块)之间既不重叠,又刚好相切。数值孔径匹配的规则为:
其中:D为主透镜的通光孔径(再直白点叫主透镜的直径),L表示主透镜和MLA的距离(又叫做像距,因为MLA放在主透镜的像面位置。!!!此处千万注意,L不一定是焦距,很多人经常犯得一个错误!!!),d为mla的小透镜的直径,f为小透镜的焦距。
2. 算法处理
接下来我将给大家介绍一下一些图像预处理和五维光场函数处理相关的内容。我们先来找一个光场相机捕获的原始图像吧,这里我们可以访问斯坦福大学的光场相机拍摄的数据集,数据集链接:斯坦福光场数据集主页链接
Step1:

Step2:

Step3:
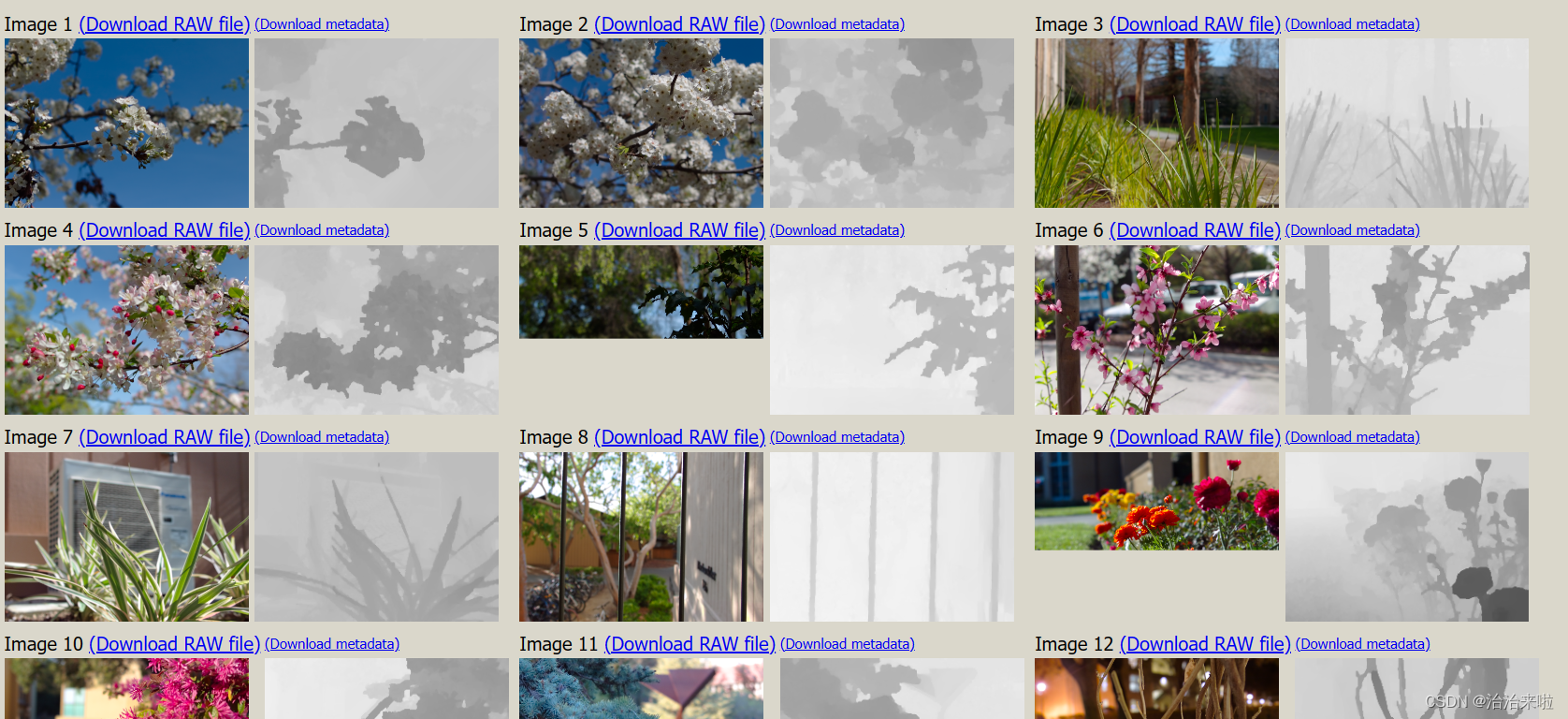
单击可以下载对应的Raw Data,文件比较大,打开后可以看到利用上述的结构拍摄到的原始光场图像(下左),放大后可以看到每一个对应的宏像素(下右)。


接下来我将告诉大家如何处理这个原始光场图像,提取出对应的五维光场函数。首先我们要确定一下对应的图像参数:7574*5264的图像。接下来先放代码,然后具体讲解代码的含义(个人水平有限,代码仅供参考),此处仅提供部分核心代码。
main.py
def test_StanfordLF():
'''
加载并处理斯坦福大学的光场数据集
'''
lytroRawImagePath = 'flowers_plants_14_eslf.png'
if os.path.exists(lytroRawImagePath) is False:
print('start to download light field png...')
toolsImageProcess.request_download('http://lightfields.stanford.edu/images/flowers_plants/raw/flowers_plants_1_eslf.png',
'', lytroRawImagePath)
print('png download successfully. ')
print('start to load Stanford Lytro Light Field Archive image {}'.format(lytroRawImagePath))
t = time.time() # load time about 20s
LF = toolsImageProcess.LFReadRawImage(lytroRawImagePath)
print("Stanford Lytro Light Field Archive image load successfully, time cost: {}s".format(time.time() - t))
toolsImageProcess.LFSaveAllSubViewImages(LF, "SubView Images", "")toolsImageProcess.py
'''
根据对应的子孔径图像重构光场原始图片
参数:
LF 五维光场函数
返回值:
LF_Raw 原始的光场采集图像
'''
def LFReadRawImage(imgPath, width=None, height=None):
if os.path.exists(imgPath) is False:
return None
LF_Raw = np.array(Image.open(imgPath))
imgShape = LF_Raw.shape
if width is None or height is None:
maxCD = maxCommonDivisor(imgShape[0], imgShape[1])
uRange = int(imgShape[0] / maxCD)
vRange = int(imgShape[1] / maxCD)
else:
maxCD = imgShape[0]/width
if maxCD == imgShape[1]/height:
uRange = width
vRange = height
maxCD = int(maxCD)
else:
print("data check faild, process finished. ")
return None
LF = np.zeros((maxCD, maxCD, uRange, vRange, imgShape[2]))
print("light field data dimension: LF({},{},{},{},{})".format(maxCD, maxCD, uRange, vRange,imgShape[2]))
totalSubViewCount = maxCD*maxCD
start = time.time() # 下载开始时间
for x in range(maxCD):
for y in range(maxCD):
print('\rloading process: {:.2f}%'.format((x * maxCD + y)*100/totalSubViewCount), end=' ')
for u in range(uRange):
for v in range(vRange):
LF[x, y, u, v, :] = LF_Raw[u*maxCD+x, v*maxCD+y, :]
print('\rloading process: 100.00%')
print('the 4D light field load successfully, time cost: %.2fs' % (time.time() - start)) #输出下载用时时间
return LF.astype(np.uint8)def LFSaveAllSubViewImages(LF, dir, dir_name):
# 首先判断 LF 数据类型,如果是 float 类型需要预处理
LFShape = LF.shape
totalSubViewCount = LFShape[0]*LFShape[1]
path_save = os.path.join(dir, dir_name)
if dir != "" and os.path.exists(dir) is False:
os.mkdir(dir)
if os.path.exists(path_save) is False:
os.mkdir(path_save)
for i in range(LFShape[0]):
for j in range(LFShape[1]):
img = LF[i, j, :, :, :]
# plt.subplot(LFShape[2], LFShape[3], i*LFShape[2]+j+1)
# plt.imshow(img)
cv2.imwrite(os.path.join(path_save, "{}_{:0>2d}_{:0>2d}.png".format(dir_name, i, j)), img)
print('\rprocess progress: {}/{} image'.format(i*LFShape[1]+j+1, totalSubViewCount), end=' ')
print('\nall sub view images has been saved to {} successfully. '.format(path_save))'''
参数:
url: 下载的链接
path: 下载的文件存放路径
filename: 下载的文件名
# 可以可视化的动态显示下载进度,便于使用
'''
def request_download(url, path, filename):
if path!='' and (not os.path.exists(path)): # 看是否有该文件夹,没有则创建文件夹
os.mkdir(path)
start = time.time() #下载开始时间
response = requests.get(url, stream=True) #stream=True必须写上
size = 0 #初始化已下载大小
chunk_size = 1024 # 每次下载的数据大小
content_size = int(response.headers['content-length']) # 下载文件总大小
try:
if response.status_code == 200: #判断是否响应成功
print('Start download,[File size]:{size:.2f} MB'.format(size = content_size / chunk_size /1024)) #开始下载,显示下载文件大小
filepath = os.path.join(path, filename)
with open(filepath, 'wb') as file: #显示进度条
for data in response.iter_content(chunk_size = chunk_size):
file.write(data)
size +=len(data)
print('\r'+'[下载进度]:%s%.2f%%' % ('>'*int(size*50/ content_size), float(size / content_size * 100)) ,end=' ')
end = time.time() #下载结束时间
print('\nDownload completed!,times: %.2f秒' % (end - start)) #输出下载用时时间
except:
print('download error! ')部分代码的逻辑说明:
LFReadRawImage:
由于所有宏像素的长宽是相等的(圆形和方形的光阑必相等,其他形状目前没见过,不太可能),所以首先是如果不清楚图像解码的光场的LF(x,y,u,v)参数会首先计算图像长宽的最大公约数,以最大公约数作为对应的u和v的值,上述斯坦福大学的光场数据格式为LF(14,14,376,541,4)。
正常的运行结果(控制台输出):
start to download light field png...
Start download,[File size]:178.75 MB
[下载进度]:>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>100.00%
Download completed!,times: 60.19秒
png download successfully.
start to load Stanford Lytro Light Field Archive image flowers_plants_14_eslf.png
light field data dimension: LF(14,14,376,541,4)
loading process: 100.00%
the 4D light field load successfully, time cost: 32.53s
Stanford Lytro Light Field Archive image load successfully, time cost: 35.881481885910034s
process progress: 196/196 image
all sub view images has been saved to SubView Images\ successfully. 结果输出的多视角图像效果(采用gif录制了一下不同图像之间连续变化的效果):

现在已经拿到了五维光场函数,后续的许多操作例如EPI和重聚焦等操作就可以通过对LF操作来实现,本文讨论重心不在光场1.0,因此此内容此处不做过多赘述。