👍作者主页:进击的1++
🤩 专栏链接:【1++的C++初阶】
文章目录
- 一,浅谈string类
- 二,string 类常用接口
- 2.1 string的构造
- 2.2 string类对象的容量操作
- 2.3 string类对象的访问及遍历操作
- 2.4 string类对象的修改操作
- 2.5 getline函数
- 三,string 类的结构与大小
- 四,string类的实现
- 4.1 深拷贝
- 4.2 写时拷贝
- 4.3 string类实现代码
一,浅谈string类
在C语言中,字符串是以‘\0’结尾的一些字符的集合,并且在C的标准库里有专门一些库函数用来操作字符串,这些库函数与字符串是分离开的,不符合“面向对象”的思想,因此,我们在前面学习过类与对象,我们可以将这些字符串的操作函数以及保存字符串的变量,封装成类,类实例化成对象后,数据与方法也就不会分开,这样就极大的方便了我们的操作,而且在操作时还不容易出错。因此在C++中就有了string类。
还需要注意的是:
- string在底层实际是:basic_string模板类的别名,
typedef basic_string<char, char_traits, allocator> string; - 不能操作多字节或者变长字符的序列。
- 要包含头文件。
二,string 类常用接口
2.1 string的构造
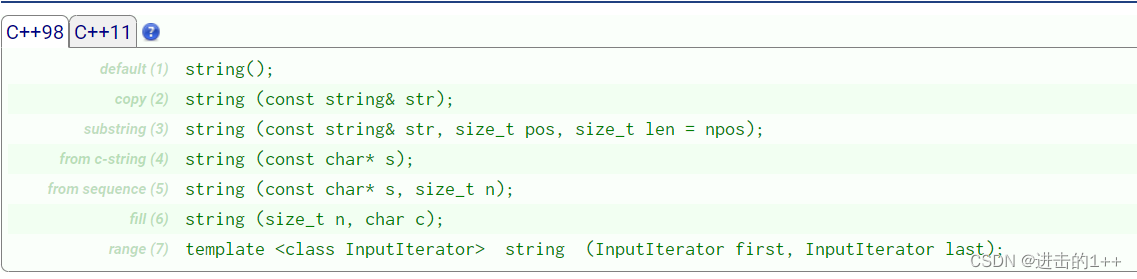
void Test2()
{
string s1;//空构造
const char* str = "jhstdg";
string s2("hellow world");//C语言字符串构造
string s3(str);//字符串构造
string s4(s3);//拷贝构造
//cout << s4 << endl;
string s5(s3, 0,10);//子串构造,当要拷贝的的长度超过子串的长度时,
//拷贝到子串最后一个字符就会结束
//cout << s5 << endl;
string s6(str, 1);//序列构造,从str中拷贝1个字符作为参数构造s6。
//cout << s6 << endl;
string s7(7, 'x');//用7个字符x填充字符串。
cout << s7 << endl;
}
2.2 string类对象的容量操作
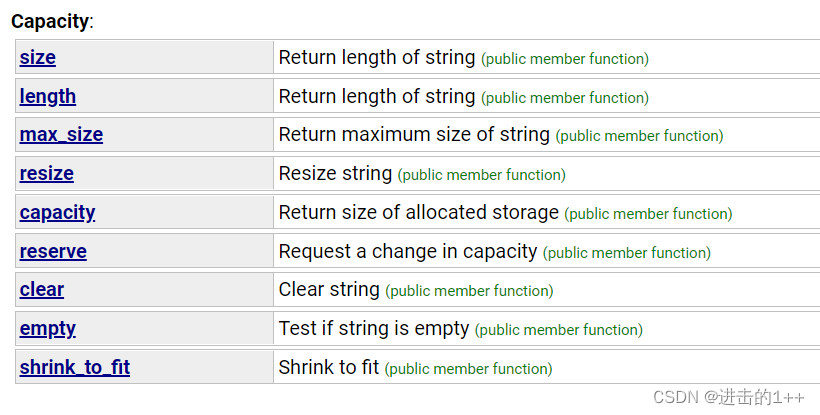
void Test3()
{
string s("hellow world");
string s1;
cout << s.size() << endl;//返回字符串的有效长度
cout << s.length()<< endl;//与size的作用相同
cout << s.capacity() << endl;//返回空间总大小,与动态顺序表中的容量功能类似
cout << s1.empty() << endl;//检测字符串是否为空串,是则返回1,不是返回0
//s.clear();//清空有效字符
cout << s.empty() << endl;
s.reserve(10);//为字符串预留空间
cout << s.capacity() << endl;
s.resize(17,'l');//将字符串的有效个数改为17,多出的空间用字符l填充。
cout << s << endl;
}
需要注意的是:
- clear是清空有效字符,但是底层空间大小并不会改变
- resreve(n) 是预留空间,当n小于底层空间大小是,预留的空间大小不一定会变。
- resize是将字符串中的有效字符个数改为n,其中resize(n)与resize(n,s)的区别是,前者将多出的空间用0填充,后者用s填充,并且,元素减少,底层空间不一定会减少。
2.3 string类对象的访问及遍历操作

void Test1()
{
string s1("hellow world");
string s2 = "hellow world";
//cout << s1[3] << endl;
//cout << s1.operator [](3) << endl;
s2[2] = '\0';
if (s2[s2.size()] == '\0')
{
cout << "YES" << endl;//运行结果为YES,证明,C++中字符串的结尾确实是'\0',
//但是,并不是以'\0’作为结束标志。
}
else
{
cout << "NO" << endl;
}
//cout << s2 << endl;
//string::iterator it = s1.begin();//获取第一个字符
//while (it != s1.end()) //end()为最后一个字符的下一个位置
//{
// cout << *it;
// it++;
//}
//cout << endl;
/*string::reverse_iterator rit = s1.rbegin();
while (rit != s1.rend())
{
cout << *rit ;
++rit;
}*/
//reverse(s1.rbegin(),s1.rend());//逆置函数
//string::reverse_iterator rit = s1.rbegin();//获取最后一个字符
//while (rit != s1.rend())//第一个字符的前一个位置
//{
// cout << *rit;
// ++rit;
//}
//范围for
for (auto it : s1)//范围for实质工作原理就是迭代器
{
cout << it;
}
}
总结:iterator提供一种统一的方式访问和修改容器的数据
2.4 string类对象的修改操作
string& insert(size_t pos, char c)
{
assert(pos <= _size);
//扩容
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
int begin = pos;
int end = _size;
while (end >= begin)
{
_str[end + 1] = _str[end];
end--;
}
_str[end+1] = c;
_size++;
return *this;
}
//
string& insert(size_t pos, const char* s)
{
assert(pos <= _size);
size_t len = strlen(s);
//扩容
if (_size+len > _capacity)
{
reserve(_size+len);
}
int begin = pos;
int end = _size + len;
int i = _size ;
while (end >= begin + len)
{
_str[end--] = _str[i--];
}
size_t j = 0;
while (j<len)
{
_str[++i] = s[j++];
}
_size += len;
return *this;
}
//
string& erase(size_t pos, size_t len=npos)
{
assert(pos < _size);
if (pos+len>=_size || len == npos)
{
_str[pos] = '\0';
_size = pos;
}
else
{
int end = _size;
strcpy(_str + pos, _str + pos + len);
_size -= len;
}
return *this;
}
//
size_t find(char c, size_t pos=0)
{
assert(pos <= _size);
while (pos < _size)
{
if (_str[pos] == c)
return pos;
pos++;
}
return npos;
}
//
size_t find( const char* sub, size_t pos=0)const
{
assert(sub);
assert(pos < _size);
char* _pos = std::strstr(_str, sub);
if (_pos == nullptr)
return npos;
else
return _pos - _str;
}
//
string& push_back(char c)
{
insert(_size, c);
return *this;
}
//
string& append(const char* s)
{
insert(_size, s);
return *this;
}
//
string& operator+=(char c)
{
push_back(c);
return *this;
}
string& operator+=(const char* s)
{
append(s);
return *this;
}
//
string substr(size_t pos, size_t len = npos)const
{
assert(pos < _size);
string tmp;
size_t reallen = len;
if (len == npos || pos + len > _size)
{
reallen = _size - pos;
}
for (size_t i = pos; i < pos + reallen; i++)
{
tmp += _str[i];
}
return tmp;
}
//
string substr(size_t pos, size_t len = npos)const
{
assert(pos < _size);
string tmp;
size_t reallen = len;
if (len == npos || pos + len > _size)
{
reallen = _size - pos;
}
for (size_t i = pos; i < pos + reallen; i++)
{
tmp += _str[i];
}
return tmp;
}
//
string operator+(const char* s)
{
string tmp(*this);
tmp += s;
return tmp;
}
2.5 getline函数
void Test1()
{
string s2;
cin >> s2 ;
cout << s2 << endl;
}
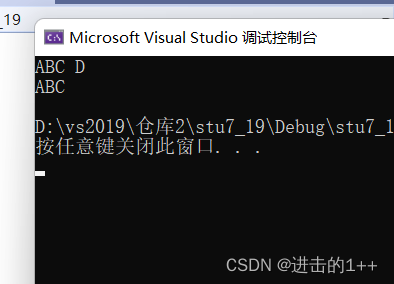
通过观察上述代码及其运行结果我们发现当用cin进行输入后,cin遇到空格就会将缓冲区中的变量刷入变量中,而空格后的字符仍留在缓冲区中,所以其分隔字符为 ’ ‘(空格) ,getline()函数可以自定义分隔字符,这就解决了某些输入上的问题。

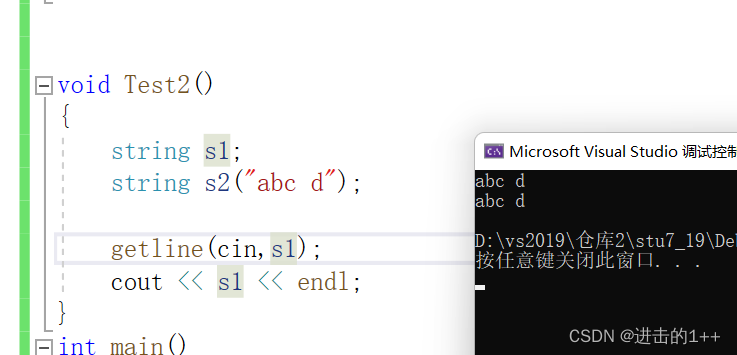
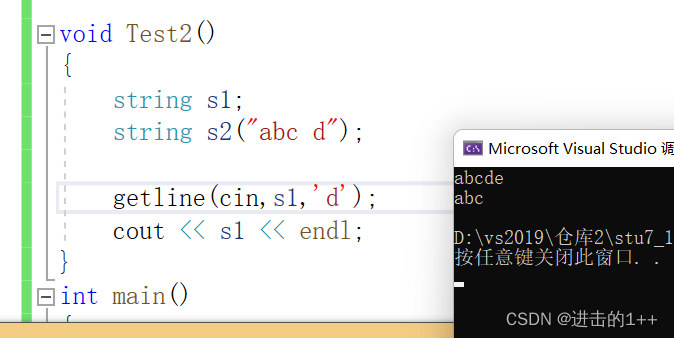
getline默认的分割符为‘\n’。
三,string 类的结构与大小
我们先说结论,string 总共占28字节。好多人可能会有疑问,为什么是28,而不是12。
在细说之前,我们不妨再次来谈谈什么是内存对齐。
先来说需要内存对齐的原因:
pu在处理我们的数据时,需要通过内存进行处理,而且cpu一次在内存中取到的内存大小是有限的,因此,如果没有内存对齐,某些变量的数据可能会被分开两次才能取完,因此就需要内存对齐,以空间换时间,来提高效率。
对齐规则:
第一个成员变量在结构体变量偏移量为0的地址处;
其他成员变量要对齐到某个对齐数(编译器默认对齐数与该成员变量大小中取较小值);
结构体的总大小为最大对齐数的整数倍;
嵌套结构体对齐得到自己的最大对齐数的整数倍。
这是我们模拟实现的string类:

在我们自己实现的string类中,通过计算我们得出其结构体大小为12 。
但在STL中string的实现更为复杂,为了解决,频繁开辟空间消耗过多的问题,并且,大多数字符串长度也不会超过16,因此,在其成员变量中还有一个联合体,联合体中有一个16个字符数组的空间,用来存放长度小于16的字符串。有了这个数组后,当字符串长度小于16时就不需要在堆上开辟空间,效率就提高了。
联合体又叫共用体,其内部的变量共用一块空间,其大小为最大变量的大小。因此string的大小为16+4+4+4=28。
四,string类的实现
4.1 深拷贝
在类与对象篇中我们提到了浅拷贝,只是将对象的值拷贝过来,但是如果对象中设计到了对象管理,那么若仍用浅拷贝,就会发生,两个指针指向同一块空间的情况,当调用析构时就会发生同一块空间被释放两次的情况,因此就有了深拷贝。
深拷贝:给每个对小尼姑独立分配资源,来保证其不会被多次释放。
代码如下:
拷贝构造
传统写法
string(const string& s)
{
_size = s._size;
_capacity = s._capacity;
_str = new char[s._size + 1];
strcpy(_str, s._str);
}
//s1=s2
string& operator =(const string& s)
{
if (this != &s)
{
delete[] _str;
_size = s._size;
_capacity = s._capacity;
_str = new char[s._size + 1];
strcpy(_str, s._str);
}
return* this;
}
//现代写法
void swap(string& tmp)
{
std::swap(_str, tmp._str);
std::swap(_size, tmp._size);
std::swap(_capacity, tmp._capacity);
}
string(const string& s)
: _str(nullptr)
,_size(0)
,_capacity(0)
{
string tmp(s._str);
swap(tmp);
}
string& operator=(string s)
{
swap(s);
return* this;//返回值是为了连续赋值
}
4.2 写时拷贝
写时拷贝就是类似与一种拖延症,采用引用计数,用来记录共同使用这块空间的对象的个数,只有堆某个对象进行修改时,才会进行拷贝构造,为这个对象开辟一块空间,并且在销毁时也会进行计数的判断,直到剩下最后一个使用者时才进行释放。
4.3 string类实现代码
namespace hyp
{
class string
{
public:
string(const char* str="")
{
_size = strlen(str);
_capacity = _size;
_str = new char[_size + 1];
strcpy(_str, str);
}
const char* c_str()const
{
return this->_str;
}
//拷贝构造
//传统写法
//string(const string& s)
//{
// _size = s._size;
// _capacity = s._capacity;
// _str = new char[s._size + 1];
// strcpy(_str, s._str);
//}
//s1=s2
/* string& operator =(const string& s)
{
if (this != &s)
{
delete[] _str;
_size = s._size;
_capacity = s._capacity;
_str = new char[s._size + 1];
strcpy(_str, s._str);
}
return* this;
}*/
//现代写法
void swap(string& tmp)
{
std::swap(_str, tmp._str);
std::swap(_size, tmp._size);
std::swap(_capacity, tmp._capacity);
}
string(const string& s)
: _str(nullptr)
,_size(0)
,_capacity(0)
{
string tmp(s._str);
swap(tmp);
}
string& operator=(string s)
{
swap(s);
return* this;//返回值是为了连续赋值
}
void reserve(size_t n)
{
if (n > _capacity)
{
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}
}
char& operator [](size_t pos)
{
assert(pos < _size);
return _str[pos];
}
const char& operator [](size_t pos)const
{
assert(pos < _size);
return _str[pos];
}
size_t size()const
{
return _size;
}
size_t capacity()const
{
return _capacity;
}
void resize(size_t n, char c = '\0')
{
if (n < _size)
{
_str[n] = '\0';
_size = n;
}
else
{
reserve(n);
for (size_t i = _size; i < n; i++)
{
_str[i] = c;
}
_str[n] = '\0';
_size = n;
}
}
void clear()
{
_str[0] = '\0';
_size = 0;
}
~string()
{
delete[] _str;
_str = nullptr;
}
string& insert(size_t pos, char c)
{
assert(pos <= _size);
//扩容
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
int begin = pos;
int end = _size;
while (end >= begin)
{
_str[end + 1] = _str[end];
end--;
}
_str[end+1] = c;
_size++;
return *this;
}
string& insert(size_t pos, const char* s)
{
assert(pos <= _size);
size_t len = strlen(s);
//扩容
if (_size+len > _capacity)
{
reserve(_size+len);
}
int begin = pos;
int end = _size + len;
int i = _size ;
while (end >= begin + len)
{
_str[end--] = _str[i--];
}
size_t j = 0;
while (j<len)
{
_str[++i] = s[j++];
}
_size += len;
return *this;
}
string& erase(size_t pos, size_t len=npos)
{
assert(pos < _size);
if (pos+len>=_size || len == npos)
{
_str[pos] = '\0';
_size = pos;
}
else
{
int end = _size;
strcpy(_str + pos, _str + pos + len);
_size -= len;
}
return *this;
}
size_t find(char c, size_t pos=0)
{
assert(pos <= _size);
while (pos < _size)
{
if (_str[pos] == c)
return pos;
pos++;
}
return npos;
}
size_t find( const char* sub, size_t pos=0)const
{
assert(sub);
assert(pos < _size);
char* _pos = std::strstr(_str, sub);
if (_pos == nullptr)
return npos;
else
return _pos - _str;
}
string& push_back(char c)
{
insert(_size, c);
return *this;
}
string& append(const char* s)
{
insert(_size, s);
return *this;
}
string& operator+=(char c)
{
push_back(c);
return *this;
}
string& operator+=(const char* s)
{
append(s);
return *this;
}
string substr(size_t pos, size_t len = npos)const
{
assert(pos < _size);
string tmp;
size_t reallen = len;
if (len == npos || pos + len > _size)
{
reallen = _size - pos;
}
for (size_t i = pos; i < pos + reallen; i++)
{
tmp += _str[i];
}
return tmp;
}
bool operator>(const string& s)const
{
int ret = strcmp(_str,s._str);
if (ret > 0)
{
return true;
}
return false;
}
bool operator==(const string& s)const
{
int ret = strcmp(_str, s._str);
if (ret == 0)
return true;
else
return false;
}
bool operator>=(const string& s)const
{
if (*this > s || *this == s)
return true;
else
return false;
}
bool operator<(const string& s)const
{
if (*this >= s)
return false;
else
return true;
}
bool operator<=(const string& s)const
{
if (*this < s || *this == s)
return true;
else
return false;
}
bool operator!=(const string& s)const
{
if (*this == s)
return false;
else
return true;
}
string operator+(const char* s)
{
string tmp(*this);
tmp += s;
return tmp;
}
private:
char* _str;
size_t _size;
size_t _capacity;
public:
const static size_t npos = -1;
};
ostream& operator <<(ostream& out, string& s)
{
for (int i = 0; i < (int)s.size(); i++)
{
out << s[i] ;
}
return out;
}
istream& operator>>(istream& in, string& s)
{
s.clear();
const size_t N = 32;
char buff[N];
char ch;
ch = in.get();
size_t i = 0;
while (ch != ' ' && ch != '\n')
{
buff[i++] = ch;
if (i == N - 1)
{
buff[i] = '\0';
s += buff;
i = 0;
}
ch = in.get();
}
buff[i] = '\0';
s += buff;
return in;
}
}