Datawhale干货
作者:鱼佬、骆秀韬,Datawhale成员
本实践是数据挖掘类型的比赛,聚焦于工业场景。实践任务本质上为回归任务,其中会涉及到时序预测相关的知识。
本实践可帮助大家:
快速掌握数据挖掘任务基本流程,为后续更多比赛的实践打下基础;
在实践中还可以学习到如果构建时间序列预测相关问题的特征提取技巧,以及模型使用方法。
实践任务
通过电炉生产数据推测产品内部温度:
任务输入:电炉对应17个温区的实际生产数据;
任务输出:电炉对应17个温区上部空间和下部空间17个测温点的测量温度值。
赛事地址:https://challenge.xfyun.cn/topic/info?type=lithium-ion-battery&ch=LpBfiI8
实践思路
面对回归预测问题,通常有以下几种思路:
常规思路:使用机器学习,如LightGBM、XGBoost,该方法模型使用简单,数据不需要过多预处理;
深度学习:使用深度学习进行实践。该在模型的搭建上就比较复杂,需要自己构建模型结构,对于数值数据需要进行标准化处理;
本实践使用机器学习lightgbm解决问题,主要步骤为数据预处理、切分训练集与验证集、训练模型、预测结果。
具体流程如下: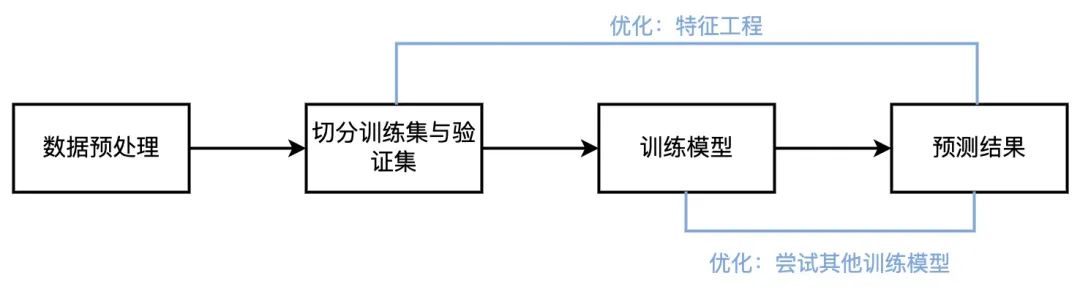
实践代码
完整代码如下,一键复制即可运行:
# 导入所需的库
import pandas as pd # 用于处理数据的工具
import lightgbm as lgb # 机器学习模型 LightGBM
from sklearn.metrics import mean_absolute_error # 评分 MAE 的计算函数
from sklearn.model_selection import train_test_split # 拆分训练集与验证集工具
from tqdm import tqdm # 显示循环的进度条工具
# 数据准备
train_dataset = pd.read_csv("./data/train.csv") # 原始训练数据。
test_dataset = pd.read_csv("./data/test.csv") # 原始测试数据(用于提交)。
submit = pd.DataFrame() # 定义提交的最终数据。
submit["序号"] = test_dataset["序号"] # 对齐测试数据的序号。
MAE_scores = dict() # 定义评分项。
# 模型训练
pred_labels = list(train_dataset.columns[-34:]) # 需要预测的标签。
train_set, valid_set = train_test_split(train_dataset, test_size=0.2) # 拆分数据集。
# 设定 LightGBM 训练参,查阅参数意义:https://lightgbm.readthedocs.io/en/latest/Parameters.html
lgb_params = {
'boosting_type': 'gbdt',
'objective': 'regression',
'metric': 'mae',
'min_child_weight': 5,
'num_leaves': 2 ** 5,
'lambda_l2': 10,
'feature_fraction': 0.8,
'bagging_fraction': 0.8,
'bagging_freq': 4,
'learning_rate': 0.05,
'seed': 2023,
'nthread' : 16,
'verbose' : -1,
}
no_info = lgb.callback.log_evaluation(period=-1) # 禁用训练日志输出。
def time_feature(data: pd.DataFrame, pred_labels: list=None) -> pd.DataFrame:
"""提取数据中的时间特征。
输入:
data: Pandas.DataFrame
需要提取时间特征的数据。
pred_labels: list, 默认值: None
需要预测的标签的列表。如果是测试集,不需要填入。
输出: data: Pandas.DataFrame
提取时间特征后的数据。
"""
data = data.copy() # 复制数据,避免后续影响原始数据。
data = data.drop(columns=["序号"]) # 去掉”序号“特征。
data["时间"] = pd.to_datetime(data["时间"]) # 将”时间“特征的文本内容转换为 Pandas 可处理的格式。
data["month"] = data["时间"].dt.month # 添加新特征“month”,代表”当前月份“。
data["day"] = data["时间"].dt.day # 添加新特征“day”,代表”当前日期“。
data["hour"] = data["时间"].dt.hour # 添加新特征“hour”,代表”当前小时“。
data["minute"] = data["时间"].dt.minute # 添加新特征“minute”,代表”当前分钟“。
data["weekofyear"] = data["时间"].dt.isocalendar().week.astype(int) # 添加新特征“weekofyear”,代表”当年第几周“,并转换成 int,否则 LightGBM 无法处理。
data["dayofyear"] = data["时间"].dt.dayofyear # 添加新特征“dayofyear”,代表”当年第几日“。
data["dayofweek"] = data["时间"].dt.dayofweek # 添加新特征“dayofweek”,代表”当周第几日“。
data["is_weekend"] = data["时间"].dt.dayofweek // 6 # 添加新特征“is_weekend”,代表”是否是周末“,1 代表是周末,0 代表不是周末。
data = data.drop(columns=["时间"]) # LightGBM 无法处理这个特征,它已体现在其他特征中,故丢弃。
if pred_labels: # 如果提供了 pred_labels 参数,则执行该代码块。
data = data.drop(columns=[*pred_labels]) # 去掉所有待预测的标签。
return data # 返回最后处理的数据。
test_features = time_feature(test_dataset) # 处理测试集的时间特征,无需 pred_labels。
# 从所有待预测特征中依次取出标签进行训练与预测。
for pred_label in tqdm(pred_labels):
train_features = time_feature(train_set, pred_labels=pred_labels) # 处理训练集的时间特征。
train_labels = train_set[pred_label] # 训练集的标签数据。
train_data = lgb.Dataset(train_features, label=train_labels) # 将训练集转换为 LightGBM 可处理的类型。
valid_features = time_feature(valid_set, pred_labels=pred_labels) # 处理验证集的时间特征。
valid_labels = valid_set[pred_label] # 验证集的标签数据。
valid_data = lgb.Dataset(valid_features, label=valid_labels) # 将验证集转换为 LightGBM 可处理的类型。
# 训练模型,参数依次为:导入模型设定参数、导入训练集、设定模型迭代次数(5000)、导入验证集、禁止输出日志
model = lgb.train(lgb_params, train_data, 5000, valid_sets=valid_data, callbacks=[no_info])
valid_pred = model.predict(valid_features, num_iteration=model.best_iteration) # 选择效果最好的模型进行验证集预测。
test_pred = model.predict(test_features, num_iteration=model.best_iteration) # 选择效果最好的模型进行测试集预测。
MAE_score = mean_absolute_error(valid_pred, valid_labels) # 计算验证集预测数据与真实数据的 MAE。
MAE_scores[pred_label] = MAE_score # 将对应标签的 MAE 值 存入评分项中。
submit[pred_label] = test_pred # 将测试集预测数据存入最终提交数据中。
submit.to_csv('submit_result.csv', index=False) # 保存最后的预测结果到 submit_result.csv。
print(MAE_scores) # 查看各项的 MAE 值。实践进阶
这里尝试提取更多特征改善最终结果,这也是数据挖掘比赛中的主要优化方向,很多情况下决定着最终的成绩。
以下主要构建了交叉特征、历史平移特征、差分特征、和窗口统计特征;每种特征都是有理可据的,具体说明如下:
交叉特征:主要提取流量、上部温度设定、下部温度设定之间的关系;
历史平移特征:通过历史平移获取上个阶段的信息;
差分特征:可以帮助获取相邻阶段的增长差异,描述数据的涨减变化情况。在此基础上还可以构建相邻数据比值变化、二阶差分等;
窗口统计特征:窗口统计可以构建不同的窗口大小,然后基于窗口范围进统计均值、最大值、最小值、中位数、方差的信息,可以反映最近阶段数据的变化情况。
完整代码如下:
# 交叉特征
for i in range(1,18):
train[f'流量{i}/上部温度设定{i}'] = train[f'流量{i}'] / train[f'上部温度设定{i}']
test[f'流量{i}/上部温度设定{i}'] = test[f'流量{i}'] / test[f'上部温度设定{i}']
train[f'流量{i}/下部温度设定{i}'] = train[f'流量{i}'] / train[f'下部温度设定{i}']
test[f'流量{i}/下部温度设定{i}'] = test[f'流量{i}'] / test[f'下部温度设定{i}']
train[f'上部温度设定{i}/下部温度设定{i}'] = train[f'上部温度设定{i}'] / train[f'下部温度设定{i}']
test[f'上部温度设定{i}/下部温度设定{i}'] = test[f'上部温度设定{i}'] / test[f'下部温度设定{i}']
# 历史平移
for i in range(1,18):
train[f'last1_流量{i}'] = train[f'流量{i}'].shift(1)
train[f'last1_上部温度设定{i}'] = train[f'上部温度设定{i}'].shift(1)
train[f'last1_下部温度设定{i}'] = train[f'下部温度设定{i}'].shift(1)
test[f'last1_流量{i}'] = test[f'流量{i}'].shift(1)
test[f'last1_上部温度设定{i}'] = test[f'上部温度设定{i}'].shift(1)
test[f'last1_下部温度设定{i}'] = test[f'下部温度设定{i}'].shift(1)
# 差分特征
for i in range(1,18):
train[f'last1_diff_流量{i}'] = train[f'流量{i}'].diff(1)
train[f'last1_diff_上部温度设定{i}'] = train[f'上部温度设定{i}'].diff(1)
train[f'last1_diff_下部温度设定{i}'] = train[f'下部温度设定{i}'].diff(1)
test[f'last1_diff_流量{i}'] = test[f'流量{i}'].diff(1)
test[f'last1_diff_上部温度设定{i}'] = test[f'上部温度设定{i}'].diff(1)
test[f'last1_diff_下部温度设定{i}'] = test[f'下部温度设定{i}'].diff(1)
# 窗口统计
for i in range(1,18):
train[f'win3_mean_流量{i}'] = (train[f'流量{i}'].shift(1) + train[f'流量{i}'].shift(2) + train[f'流量{i}'].shift(3)) / 3
train[f'win3_mean_上部温度设定{i}'] = (train[f'上部温度设定{i}'].shift(1) + train[f'上部温度设定{i}'].shift(2) + train[f'上部温度设定{i}'].shift(3)) / 3
train[f'win3_mean_下部温度设定{i}'] = (train[f'下部温度设定{i}'].shift(1) + train[f'下部温度设定{i}'].shift(2) + train[f'下部温度设定{i}'].shift(3)) / 3
test[f'win3_mean_流量{i}'] = (test[f'流量{i}'].shift(1) + test[f'流量{i}'].shift(2) + test[f'流量{i}'].shift(3)) / 3
test[f'win3_mean_上部温度设定{i}'] = (test[f'上部温度设定{i}'].shift(1) + test[f'上部温度设定{i}'].shift(2) + test[f'上部温度设定{i}'].shift(3)) / 3
test[f'win3_mean_下部温度设定{i}'] = (test[f'下部温度设定{i}'].shift(1) + test[f'下部温度设定{i}'].shift(2) + test[f'下部温度设定{i}'].shift(3)) / 3线上跑代码
将本教程Baseline部署在线上平台,对配置环境不熟悉的同学,可一键fork运行代码。
一键运行:https://aistudio.baidu.com/aistudio/projectdetail/6508229?contributionType=1
运行时,选择A100 16G或A100 32G的配置
总运行时间大约需要30分钟-1小时,请耐心等待。
↓↓↓点击直达赛事