MongoDB对于嵌套(Embedded)数组的过滤
首先定义下结构
{
"play_id": "639045efae627e2aacf35dce",
"region_id": 1106,
"point_list": [
{
"id": "1faf5aa9-e262-45fe-96dd-64395c96cf5c",
"name": "获取k8s node证书",
"status": 0,
},
{
"id": "bc1b11cf-c05a-4964-8ac6-cce1cc23e913“,
"name": "获取redis服务器的证书",
"status": 1,
},
]
}
{
"play_id": "639045efae627e2aacf35dce",
"region_id": 1107,
"point_list": [
{
"id": "7ac89b59-9657-48bf-8445-171c3de68d53",
"name": "获取k8s node证书",
"status": 0,
},
{
"id": "4db7c39d-d2b4-48c2-912d-fca3864ed556",
"name": "获取redis服务器的证书",
"status": 3,
},
{
"id": "cd825402-93de-4fb3-876a-e4d2e5d0973b",
"name": "检查系统最近 15 分钟平均负载小于CPU核数",
"status": 1,
},
]
}
这里将业务中的数据结构抽象一部分出来,供作数据使用;
- play_id: 任务的id
- region_id:地域id
- point_list: 执行内容的列表
–id:执行内容的唯一标识id
–name:执行内容的名称
–status:执行内容的状态
现在的小需求是查询某一任务中不同状态执行内容的数量以及列表,这里要注意某一任务会包含多地域的情况
这里主要用到的是Aggregation(官方传送门)
涉及到多步操作且需要有序执行,则使用bson.A来规范过滤条件
filter := bson.A{}
小tips:多步操作时将每一步的过滤条件应用为bson.D,最后使用bson.A进行有序表示
D:BSON 文档(切片)的有序表示A:BSON 数组的有序表示
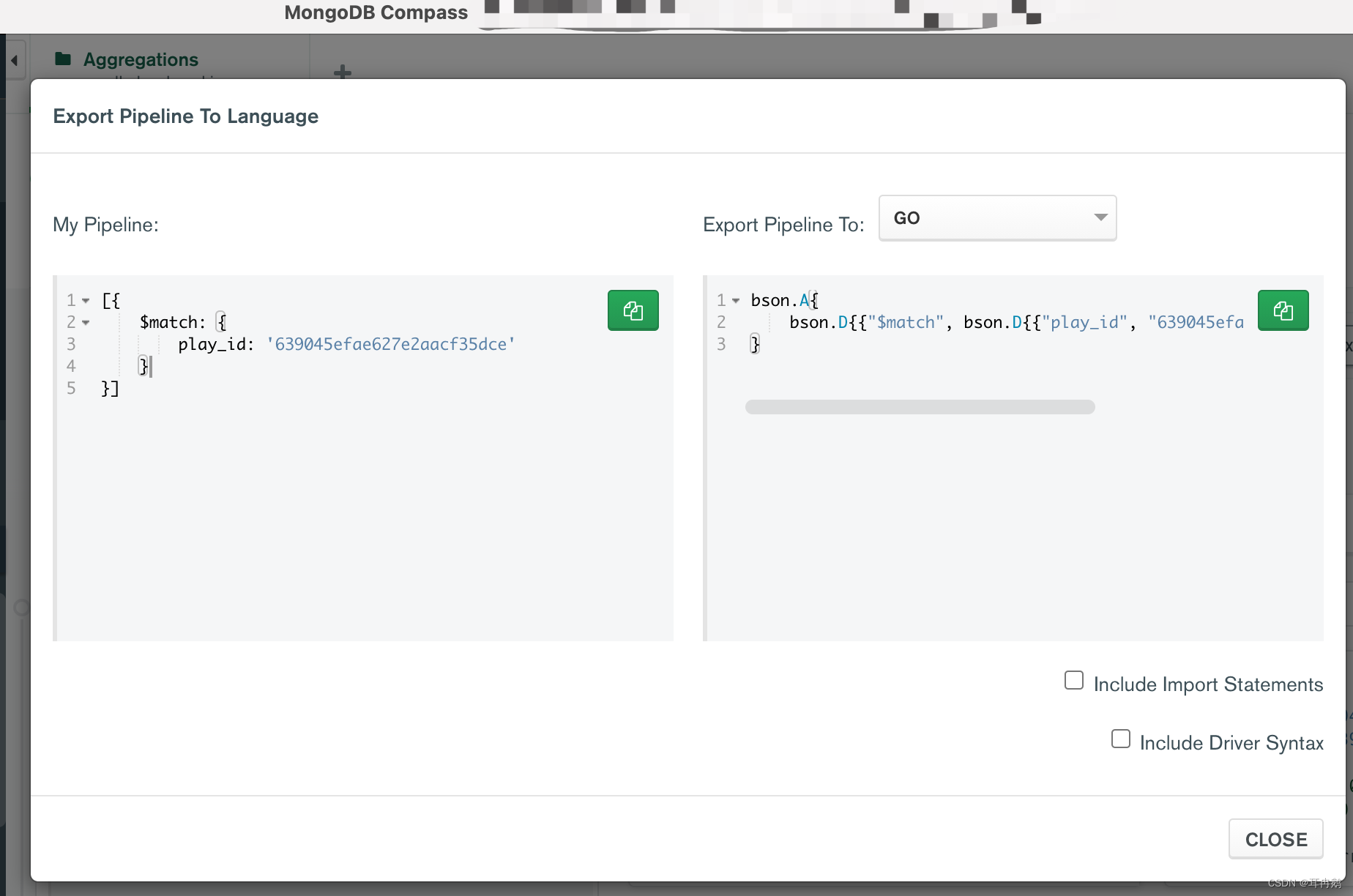
第一步 查询指定任务
因为本次需求要使用聚合操作,所以在编写filter的时候要记得添加相关语法
filter1 := bson.D{{"$match", bson.D{{"play_id", playId}}}}
这里可以使用MongoDB Compass来进行作弊:
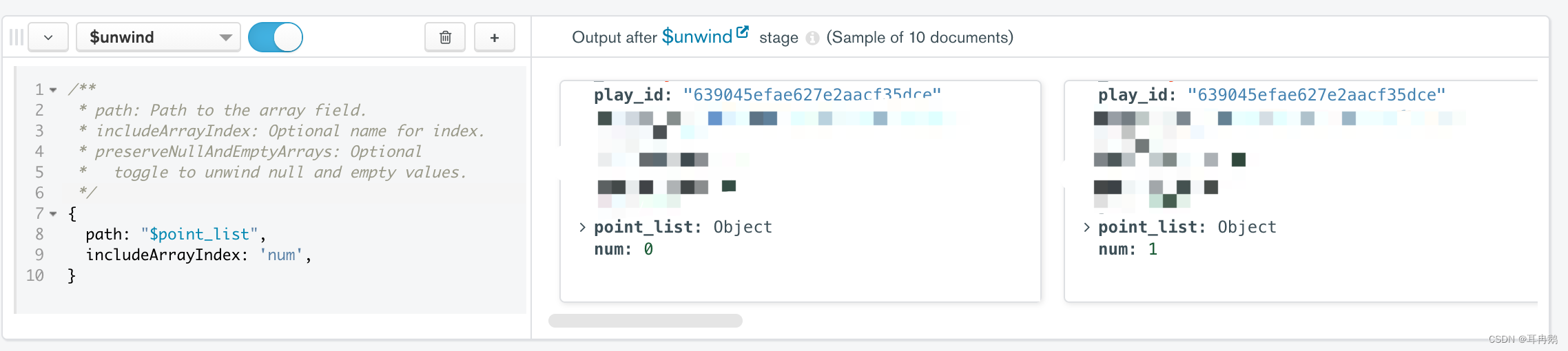
第二步 将嵌套数组拆分
使用 $unwind 操作符(传送门)
如果文档中包含 array 类型字段、并且其中包含多个元素,使用 $unwind 操作符会根据元素数量输出多个文档,每个文档的 array 字段中仅包含 array 中的单个元素。
$unwind 操作符返回了多条文档数据,并且改变了字段的类型。
filter2 := bson.D{
{"$unwind",
bson.D{
{"path", "$point_list"},
{"includeArrayIndex", "num"},
},
},
}
path 是决定将哪个嵌套数组进行打平。 以一开始举例的数据为例,则1106这个地域的数据会被分成两条数据,其中每一条数据的“point_list“会变成Object类型
includeArrayIndex则是新数据的名称(数字自增)
第三步 按照name进行聚合|统计数量
使用$group操作法(传送门)
filter3 := bson.D{
{"$group",
bson.D{
{"_id", "$point_list.name"},
{"point_list", bson.D{{"$push", "$point_list"}}},
},
},
})
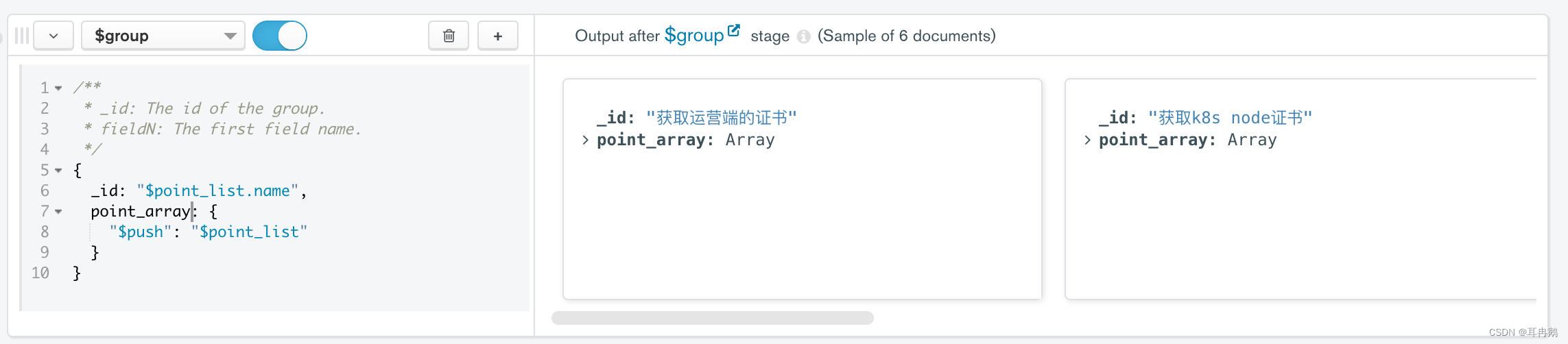
_id 是分组的id
point_array 是name=分组id的列表
—————————————————————————————————————————
filter3 := bson.D{
{"$group",
bson.D{
{"_id", "$point_list.status"},
count: {
"$sum": 1,
}
},
},
})
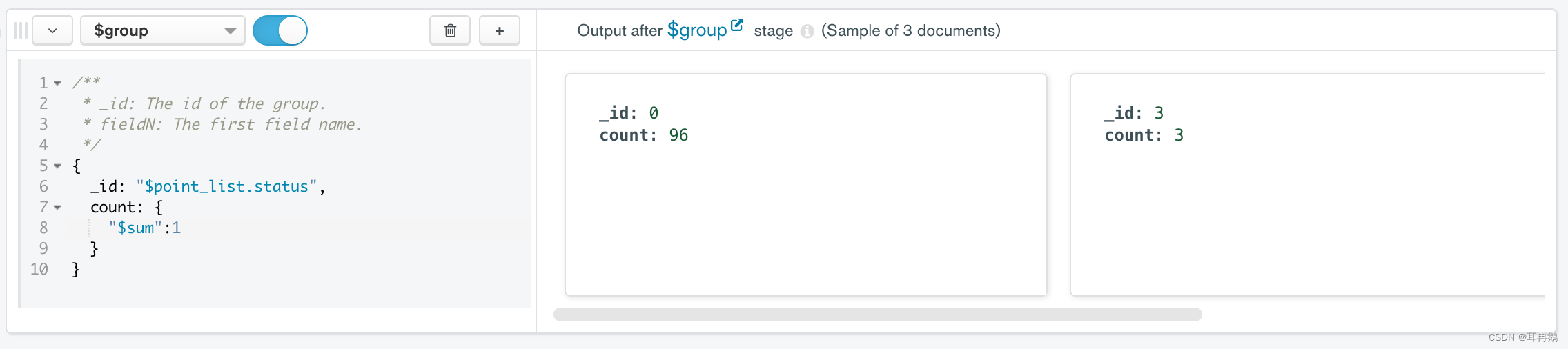
将上述分步的filter拼接起来便是最终的过滤条件,又或是写在一起:
filter := bson.A{
bson.D{{"$match", bson.D{{"play_id", playId}}}},
bson.D{
{"$unwind",
bson.D{
{"path", "$point_list"},
{"includeArrayIndex", "num"},
},
},
},
}
filter = append(filter, bson.D{
{"$group",
bson.D{
{"_id", "$point_list.name"},
{"point_array", bson.D{{"$push", "$point_list"}}},
},
},
})
如若需要添加其他匹配条件,append即可(要按照顺序添加)
使用pipeline的话代码如下:
[{
$match: {
play_id: '639045efae627e2aacf35dce'
}
}, {
$unwind: {
path: '$point_list',
includeArrayIndex: 'num'
}
}, {
$group: {
_id: '$point_list.status',
count: {
$sum: 1
}
}
}]


![[Linux]------线程池的模拟实现和读者写者锁问题](https://img-blog.csdnimg.cn/628fc476d19b45139497032e7415047a.png)