一,归并排序
1.定义:将两个或者两个以上的有序表合并成一个新的游戏表的过程。
2路归并排序:假设排序表中有n个记录,则可以将其视为n个有序子表,每个子表的长度为1,然后两两合并,得到n/2(向上取整)个长度为2或1的有序表;继续两两归并....重复如此,直到合并成一个长度为n的有序表为止。
2路归并:每选出一个小元素需要对比关键字1次
m路归并:每选出一个小元素需要对比关键字m-1次
在内部排序一般采用2路归并

该例子是2路归并,前面可以构成两两一对,就以前面先构成,没有两个的以以原来的位置为准
2.代码展示:
2.1合并排序:递归
void MergeSort(Str &L, int low, int high)
{
if(low < high)
{
int mid = (low+high)/2;//从中间划分两个子序列
MergeSort(L,low ,mid);//对左侧序列进行递归排序
MergeSort(L,mid+1,high);//对右侧序列进行递归排序
Merge(L,low,high,mid);//归并
}
}2.2归并:两段有序表假设为A[low...mid], A[mid+1 ... high],存放在同一个顺序表中相邻的位置,先将它们赋值到辅助数组B中。每次从对应的两个段取出一个关键字进行比较,将较小者放入A中,当数组B有一段的下标超出对应的表长(即该段的所有元素已经全部复制到A中)时,将另一段中剩余部分全部复制到A中。数组A和数组B的下标应该对应
//归并
void Merge(Str &L, int low, int high, int mid)
{//将表L.data的两段L.data[low...mid],L.data[mid+1...high]各自有序,将其合成一个有序表
int *B = (int *)malloc(sizeof(int)*(high+1));//动态分配内存辅助表B,我这里数组下标为0存储了数据,所以B分配的个数应该是high+1
int i,j,k;
for(k = low; k <= high; ++k)//将L.data中的元素全部赋值到B中
B[k] = L.data[k];
for(i = low, j = mid+1, k = i; i <= mid && j <= high; k++)//比较B中的两段元素
{
if(B[i] <= B[j])//如果前面一段小,则赋值到L.data中
L.data[k] = B[i++];
else
L.data[k] = B[j++];//否则就将后面一段赋值到L.data中,两个元素相等的时候优先将靠前的那个元素存储,这样可以保持算法的稳定性
}
while(i <= mid)//B中后面一段已经赋值完,则将前面一段元素全部赋值到L.data中
L.data[k++] = B[i++];
while(j <= high)
L.data[k++] = B[j++];//B中前面一段已经赋值完,则将后面一段元素全部赋值到L.data中
}3.结果:

4. 分析:
2路归并的算法性能分析:
空间复杂度:辅助空间的数组大小和存储待排序列数组的大小应当一致,所以空间复杂度为O(n)
时间复杂度:没塘归并的时间复杂度为O(n)(譬如第一趟归并,两两比较,可以比较n/2次,时间复杂度度为O(n)), 共进行(以2为底n的对数,向上取整)趟为 树高-1;所以时间复杂度为O(n
)
稳定性:稳定
二,基数排序
1.基本知识点:
1.1定义:基数排序:是基于比较和移动进行排序,是根据关键字个位的大小进行排序。
基数排序是一种借助多关键字排序的思想对单逻辑关键字进行排序的方法。
1.2 最主位关键字(关键字权重最大),最次位关键字(关键字权重最小);比如123,因为1对该数字影响最大,所以1是最主位关键字(权重最大);3对该数字影响最小,所以3是最次位关键字(权重最小)。
1.3实现关键字排序的方法有两种
最高位优先(MSD):按照关键字权重递减依次逐层划分成若干更小的子序列,最后将子序列依次连接成一个有序序列。
最低位优先(LSD):按照关键字权重递增依次逐层划分成若干更小的子序列,最后将子序列依次连接成一个有序序列。
1.4基数r,具体问题具体设置,譬如123,每一个关键字的取值范围都是0~9,所以基数r = 10;
d表示趟数,一次“分配”和“收集”称为一趟,譬如123有3位数,所以d = 3;
分配:就是将待排的序列(是通过链表L(假设链表名为L)存储)按照MSD或者LSD的方法按照其最主位关键字或者最低位关键字对应基数r的队列,然后将待排序列的元素入队。在队列下面挂着的就是分配的元素

分配:首先将原本的链表L的元素全部置空,要不从队列对应序号的最大依次进行收集或者最小开始依次进行收集;
当所有的趟数都进行完成后,如果是从队列对应序号大的依次进行收集的话得到的是一个递减序列;如果是从队列对应序号小的依次进行收集得到的是一个递增的序列
2.代码展示:
2.1通过链表存储待排序列,这里以三位数为标准
2.1.1结构体代码
//定义链表
//定义每个元素的结构体,这里以三位数标准
typedef struct
{
int g;//个位
int s;//十位
int b;//百位
}gsb;
typedef struct LinkNode
{
int elem;//用于队列中的元素
gsb data;//待排序列的数据域
struct LinkNode *next;//指针域
}LinkNode, *LinkList;
2.1.2创建链表
//无头结点尾插法创建链表
void CreatList(LinkList &L)
{
LinkNode *p = L;
LinkNode *q;
int g,s,b;
for(int i = 0; i < size; ++i)
{
q = (LinkNode *)malloc(sizeof(LinkNode));
printf("请输入第%d个元素的百位,十位,个位:\n",i+1);
scanf_s("%d %d %d",&b,&s,&g);
//q->data = (gsb *)malloc(sizeof(gsb)*10);如果是链表的数据是以指针的形式出现就会必须有这一步,不然就没有那么多的空间,没有这个只能输出以后,后面就直接跳过,不知为何
q->data.b = b;
q->data.s = s;
q->data.g = g;
q->next = NULL;
if(L == NULL)
{
L = q;
p = q;
}
else
{
p->next = q;
p = q;
}
}
}2.1.3遍历输出
//遍历输出
void PrintList(LinkList L)
{
LinkNode *p = L;
for(int i = 0; i < size && p != NULL; ++i)
{
int elem = 100*p->data.b + 10*p->data.s + 1*p->data.g;//通过个位,十位,百位按照左边乘就可以得到原本的数
printf("%d ",elem);
p = p->next;
}
printf("\n");
}2.2创造十个队列
2.2.1队列的结构体
typedef struct LinkNode
{
int elem;//用于队列中的元素
gsb data;//待排序列的数据域
struct LinkNode *next;//指针域
}LinkNode, *LinkList;
typedef struct
{
LinkNode *front,*rear;
}LinkQueue;
typedef struct
{
LinkQueue *data;
}Arr;2.2.2创建十个队列
//创造10个队列,通过数组存储10个队列
void CreatArr(Arr &A)
{
A.data = (LinkQueue *)malloc(sizeof(LinkQueue));
for(int i = 0; i < 10; ++i)//对10个队列依次进行初始化
{
A.data[i].front = A.data[i].rear = (LinkNode*)malloc(sizeof(LinkNode));//队列设置头结点
A.data[i].front->elem = i;//将队列对应的序号存储到头结点中
A.data[i].front->next = NULL;//最开始为空
}
}2.2.3元素对应入队
//个位数入队
void EnQueueg(Arr &A, LinkNode *x)
{
for(int i = 0; i < 10; ++i)//循环
{
if(A.data[i].front->elem == x->data.g)//找到元素的个位数与队列序号相同的队列
{
LinkNode *p = (LinkNode *)malloc(sizeof(LinkNode));//分配内存,用于入队
p->data.b = x->data.b;//元素的个位,十位,百位都要入队
p->data.g = x->data.g;
p->data.s = x->data.s;
p->next = NULL;
A.data[i].rear->next = p;
A.data[i].rear = p;
break;//找到之后就可以结束循环
}
}
}
//十位数入队
void EnQueues(Arr &A, LinkNode *x)
{
for(int i = 0; i < 10; ++i)
{
if(A.data[i].front->elem == x->data.s)
{
LinkNode *p = (LinkNode *)malloc(sizeof(LinkNode));
p->data.b = x->data.b;
p->data.g = x->data.g;
p->data.s = x->data.s;
A.data[i].rear->next = p;
A.data[i].rear = p;
A.data[i].rear->next = NULL;
break;
}
}
}
//百位数入队
void EnQueueb(Arr &A, LinkNode *x)
{
for(int i = 0; i < 10; ++i)
{
if(A.data[i].front->elem == x->data.b)
{
LinkNode *p = (LinkNode *)malloc(sizeof(LinkNode));
p->data.b = x->data.b;
p->data.g = x->data.g;
p->data.s = x->data.s;
A.data[i].rear->next = p;
A.data[i].rear = p;
A.data[i].rear->next = NULL;
break;
}
}
}2.2.4基数排序,LSD方法,从小到大
//基数排序
//个位数排序
void RadixSortg(LinkList &L, Arr &A)
{
LinkNode *p = L;//定义一个指针
while(p != NULL)//判断是否为空
{
for(int i = 0; i < 10; ++i)//不为空则进行循环,依次找到和链表中的个位数相等的队列
{
if(p->data.g == A.data[i].front->elem)//如果相等
{
EnQueueg(A,p);//入队
break;//结束循环
}
}
p = p->next;//然后比较链表的下一个结点的个位数
}
L = NULL;//找到之后要将L置空,因为要按照队列的序号从大到小依次存储这些元素
LinkNode *s = L;//定义一个变量
LinkNode *t = NULL;//定义一个变量指向链表的尾部
for(int i = 9; i >=0; --i)//从大到小依次查看,队列是否为空
{
if(A.data[i].front->next != NULL)//如果不为空
{
if(L == NULL)//无头结点进行尾插法创建链表的过程
{
L = A.data[i].front->next;//用L指向队列的头结点
s = A.data[i].front->next;//s指向队列的头结点
t = A.data[i].rear;//t指向队列的尾节点
t->next = NULL;//t的暂时没有下一个结点,所以为空
A.data[i].front->next = NULL;//这样队列就为空
A.data[i].rear = A.data[i].front;
}
else
{
s = t;//如果最开始不为空,则将s指向t
s->next = A.data[i].front->next;//s指向结点连接队列的头结点
t = A.data[i].rear;//t仍然是指向队列的尾节点
t->next = NULL;//尾节点后面为空
A.data[i].front->next = NULL;//将队列置空
A.data[i].rear = A.data[i].front;
}
}
}
}
//十位数排序
void RadixSorts(LinkList &L, Arr &A)
{
LinkNode *p = L;
while(p != NULL)
{
for(int i = 0; i < 10; ++i)
{
if(p->data.s == A.data[i].front->elem)
{
EnQueues(A,p);
break;
}
}
p = p->next;
}
L = NULL;
LinkNode *s = L;
LinkNode *t = NULL;
for(int i = 9; i >=0; --i)
{
if(A.data[i].front->next != NULL)
{
if(L == NULL)
{
L = A.data[i].front->next;
s = A.data[i].front->next;
t = A.data[i].rear;
t->next = NULL;
A.data[i].front->next = NULL;
A.data[i].rear = A.data[i].front;
}
else
{
s = t;
s->next = A.data[i].front->next;
t = A.data[i].rear;
t->next = NULL;
A.data[i].front->next = NULL;
A.data[i].rear = A.data[i].front;
}
}
}
}
//百位数
void RadixSortb(LinkList &L, Arr &A)
{
LinkNode *p = L;
while(p != NULL)
{
for(int i = 0; i < 10; ++i)
{
if(p->data.b == A.data[i].front->elem)
{
EnQueueb(A,p);
break;
}
}
p = p->next;
}
L = NULL;
LinkNode *s = L;
LinkNode *t = NULL;
for(int i = 9; i >=0; --i)
{
if(A.data[i].front->next != NULL)
{
if(L == NULL)
{
L = A.data[i].front->next;
s = A.data[i].front->next;
t = A.data[i].rear;
t->next = NULL;
A.data[i].front->next = NULL;
A.data[i].rear = A.data[i].front;
}
else
{
s = t;
s->next = A.data[i].front->next;
t = A.data[i].rear;
t->next = NULL;
A.data[i].front->next = NULL;
A.data[i].rear = A.data[i].front;
}
}
}
}
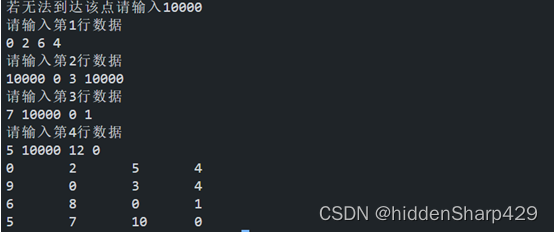
3.结果:

4.分析:
空间复杂度:一趟排序需要借助辅助存储空间为r,(r个队列:r个队头指针和队尾指针),但是后面的排序会重复使用这些队列,所以空间复杂度为:O(r).
时间复杂度: 基数排序需要进行d趟分配和收集,一趟分配需要O(n),一趟收集需要O(r)(因为每次收集的时候是看队列是否为空,如果不为空,只需要改变以下指针就行了,上面有过程,所以每次访问一个队列的时间复杂度为O(1)).所以基数排序的时间复杂度为O(d(n+r)),它与序列的初始状态无关。
稳定性:按位排序必须稳定,所以基数排序是稳定的
三,总结:
| 空间复杂度 | 时间复杂度 | 稳定性 | |
| 归并排序 | O(n) | O(n | 稳定 |
| 基数排序 | O(r) | O(d(r+n)) | 稳定 |
四,完整程序
1.归并排序
#include<stdio.h>
#include<malloc.h>
#include<stdlib.h>
//定义数组结构体
typedef struct
{
int *data;
int length;
}Str;
//函数说明
void CreatString(Str &L);
void PrintStr(Str L);
void Merge(Str &L, int low, int high, int mid);
void MergeSort(Str &L, int low, int high);
int main(void)
{
Str L;
CreatString(L);
printf("数组中的元素为:\n");
PrintStr(L);
MergeSort(L,0,L.length-1);
printf("归并排序之后数组的元素为:\n");
PrintStr(L);
return 0;
}
void CreatString(Str &L)
{
L.data = (int *)malloc(sizeof(int)*8);
L.length = 8;
int val;
for(int i = 0; i < L.length; ++i)
{
printf("请输入第%d个元素的值:",i+1);
scanf_s("%d",&val);
L.data[i] = val;
}
}
//遍历输出
void PrintStr(Str L)
{
for(int i = 0; i < L.length; ++i)
{
printf("%d ",L.data[i]);
}
printf("\n");
}
//归并
void Merge(Str &L, int low, int high, int mid)
{//将表L.data的两段L.data[low...mid],L.data[mid+1...high]各自有序,将其合成一个有序表
int *B = (int *)malloc(sizeof(int)*(high+1));//动态分配内存辅助表B
int i,j,k;
for(k = low; k <= high; ++k)//将L.data中的元素全部赋值到B中
B[k] = L.data[k];
for(i = low, j = mid+1, k = i; i <= mid && j <= high; k++)//比较B中的两段元素
{
if(B[i] <= B[j])//如果前面一段小,则赋值到L.data中
L.data[k] = B[i++];
else
L.data[k] = B[j++];//否则就将后面一段赋值到L.data中
}
while(i <= mid)//B中后面一段已经赋值完,则将前面一段元素全部赋值到L.data中
L.data[k++] = B[i++];
while(j <= high)
L.data[k++] = B[j++];//B中前面一段已经赋值完,则将后面一段元素全部赋值到L.data中
}
//合并排序
void MergeSort(Str &L, int low, int high)
{
if(low < high)
{
int mid = (low+high)/2;//从中间划分两个子序列
MergeSort(L,low ,mid);//对左侧序列进行递归排序
MergeSort(L,mid+1,high);//对右侧序列进行递归排序
Merge(L,low,high,mid);//归并
}
}2.基数排序
#include<stdio.h>
#include<malloc.h>
#include<stdlib.h>
#define size 11
//定义链表
//定义每个元素的结构体,这里以三位数标准
typedef struct
{
int g;//个位
int s;//十位
int b;//百位
}gsb;
typedef struct LinkNode
{
int elem;//用于队列中的元素
gsb data;//待排序列的数据域
struct LinkNode *next;//指针域
}LinkNode, *LinkList;
//定义队列
/*typedef struct LinkNode
{
int data;
struct LinkNode *next;
}LinkNode;*/
typedef struct
{
LinkNode *front,*rear;
}LinkQueue;
typedef struct
{
LinkQueue *data;
}Arr;
//函数说明
void CreatList(LinkList &L);
void PrintList(LinkList L);
void CreatArr(Arr &A);
void EnQueueg(Arr &A, LinkNode *x);
void EnQueues(Arr &A, LinkNode *x);
void EnQueueb(Arr &A, LinkNode *x);
void RadixSortg(LinkList &L, Arr &A);
void RadixSorts(LinkList &L, Arr &A);
void RadixSortb(LinkList &L, Arr &A);
int main(void)
{
LinkList L = NULL;
CreatList(L);
LinkNode *p = L->next;
//printf("%d%d%d",p->data.b,p->data.s,p->data.g);
printf("链表元素依次为:\n");
PrintList(L);
Arr A;
CreatArr(A);
RadixSortg(L,A);
printf("个位数基数排序之后元素顺序:\n");
PrintList(L);
RadixSorts(L,A);
printf("十位数基数排序之后元素顺序:\n");
PrintList(L);
RadixSortb(L,A);
printf("百位数基数排序之后元素顺序:\n");
PrintList(L);
return 0;
}
//无头结点尾插法创建链表
void CreatList(LinkList &L)
{
LinkNode *p = L;
LinkNode *q;
int g,s,b;
for(int i = 0; i < size; ++i)
{
q = (LinkNode *)malloc(sizeof(LinkNode));
printf("请输入第%d个元素的百位,十位,个位:\n",i+1);
scanf_s("%d %d %d",&b,&s,&g);
//q->data = (gsb *)malloc(sizeof(gsb)*10);如果是链表的数据是以指针的形式出现就会必须有这一步,不然就没有那么多的空间,没有这个只能输出以后,后面就直接跳过,不知为何
q->data.b = b;
q->data.s = s;
q->data.g = g;
q->next = NULL;
if(L == NULL)
{
L = q;
p = q;
}
else
{
p->next = q;
p = q;
}
}
}
//遍历输出
void PrintList(LinkList L)
{
LinkNode *p = L;
for(int i = 0; i < size && p != NULL; ++i)
{
int elem = 100*p->data.b + 10*p->data.s + 1*p->data.g;//通过个位,十位,百位按照左边乘就可以得到原本的数
printf("%d ",elem);
p = p->next;
}
printf("\n");
}
//队列函数
//创造10个队列,通过数组存储10个队列
void CreatArr(Arr &A)
{
A.data = (LinkQueue *)malloc(sizeof(LinkQueue));
for(int i = 0; i < 10; ++i)//对10个队列依次进行初始化
{
A.data[i].front = A.data[i].rear = (LinkNode*)malloc(sizeof(LinkNode));//队列设置头结点
A.data[i].front->elem = i;//将队列对应的序号存储到头结点中
A.data[i].front->next = NULL;//最开始为空
}
}
//判断队列为空
bool IsEmpty(Arr A)
{
for(int i = 0; i < 10; ++i)
{
if(A.data[i].front == A.data[i].rear)
return true;
else
return false;
}
return false;
}
//个位数入队
void EnQueueg(Arr &A, LinkNode *x)
{
for(int i = 0; i < 10; ++i)//循环
{
if(A.data[i].front->elem == x->data.g)//找到元素的个位数与队列序号相同的队列
{
LinkNode *p = (LinkNode *)malloc(sizeof(LinkNode));//分配内存,用于入队
p->data.b = x->data.b;//元素的个位,十位,百位都要入队
p->data.g = x->data.g;
p->data.s = x->data.s;
p->next = NULL;
A.data[i].rear->next = p;
A.data[i].rear = p;
break;//找到之后就可以结束循环
}
}
}
//十位数入队
void EnQueues(Arr &A, LinkNode *x)
{
for(int i = 0; i < 10; ++i)
{
if(A.data[i].front->elem == x->data.s)
{
LinkNode *p = (LinkNode *)malloc(sizeof(LinkNode));
p->data.b = x->data.b;
p->data.g = x->data.g;
p->data.s = x->data.s;
A.data[i].rear->next = p;
A.data[i].rear = p;
A.data[i].rear->next = NULL;
break;
}
}
}
//百位数入队
void EnQueueb(Arr &A, LinkNode *x)
{
for(int i = 0; i < 10; ++i)
{
if(A.data[i].front->elem == x->data.b)
{
LinkNode *p = (LinkNode *)malloc(sizeof(LinkNode));
p->data.b = x->data.b;
p->data.g = x->data.g;
p->data.s = x->data.s;
A.data[i].rear->next = p;
A.data[i].rear = p;
A.data[i].rear->next = NULL;
break;
}
}
}
//基数排序
//个位数排序
void RadixSortg(LinkList &L, Arr &A)
{
LinkNode *p = L;//定义一个指针
while(p != NULL)//判断是否为空
{
for(int i = 0; i < 10; ++i)//不为空则进行循环,依次找到和链表中的个位数相等的队列
{
if(p->data.g == A.data[i].front->elem)//如果相等
{
EnQueueg(A,p);//入队
break;//结束循环
}
}
p = p->next;//然后比较链表的下一个结点的个位数
}
L = NULL;//找到之后要将L置空,因为要按照队列的序号从大到小依次存储这些元素
LinkNode *s = L;//定义一个变量
LinkNode *t = NULL;//定义一个变量指向链表的尾部
for(int i = 9; i >=0; --i)//从大到小依次查看,队列是否为空
{
if(A.data[i].front->next != NULL)//如果不为空
{
if(L == NULL)//无头结点进行尾插法创建链表的过程
{
L = A.data[i].front->next;//用L指向队列的头结点
s = A.data[i].front->next;//s指向队列的头结点
t = A.data[i].rear;//t指向队列的尾节点
t->next = NULL;//t的暂时没有下一个结点,所以为空
A.data[i].front->next = NULL;//这样队列就为空
A.data[i].rear = A.data[i].front;
}
else
{
s = t;//如果最开始不为空,则将s指向t
s->next = A.data[i].front->next;//s指向结点连接队列的头结点
t = A.data[i].rear;//t仍然是指向队列的尾节点
t->next = NULL;//尾节点后面为空
A.data[i].front->next = NULL;//将队列置空
A.data[i].rear = A.data[i].front;
}
}
}
}
//十位数排序
void RadixSorts(LinkList &L, Arr &A)
{
LinkNode *p = L;
while(p != NULL)
{
for(int i = 0; i < 10; ++i)
{
if(p->data.s == A.data[i].front->elem)
{
EnQueues(A,p);
break;
}
}
p = p->next;
}
L = NULL;
LinkNode *s = L;
LinkNode *t = NULL;
for(int i = 9; i >=0; --i)
{
if(A.data[i].front->next != NULL)
{
if(L == NULL)
{
L = A.data[i].front->next;
s = A.data[i].front->next;
t = A.data[i].rear;
t->next = NULL;
A.data[i].front->next = NULL;
A.data[i].rear = A.data[i].front;
}
else
{
s = t;
s->next = A.data[i].front->next;
t = A.data[i].rear;
t->next = NULL;
A.data[i].front->next = NULL;
A.data[i].rear = A.data[i].front;
}
}
}
}
//百位数
void RadixSortb(LinkList &L, Arr &A)
{
LinkNode *p = L;
while(p != NULL)
{
for(int i = 0; i < 10; ++i)
{
if(p->data.b == A.data[i].front->elem)
{
EnQueueb(A,p);
break;
}
}
p = p->next;
}
L = NULL;
LinkNode *s = L;
LinkNode *t = NULL;
for(int i = 9; i >=0; --i)
{
if(A.data[i].front->next != NULL)
{
if(L == NULL)
{
L = A.data[i].front->next;
s = A.data[i].front->next;
t = A.data[i].rear;
t->next = NULL;
A.data[i].front->next = NULL;
A.data[i].rear = A.data[i].front;
}
else
{
s = t;
s->next = A.data[i].front->next;
t = A.data[i].rear;
t->next = NULL;
A.data[i].front->next = NULL;
A.data[i].rear = A.data[i].front;
}
}
}
}