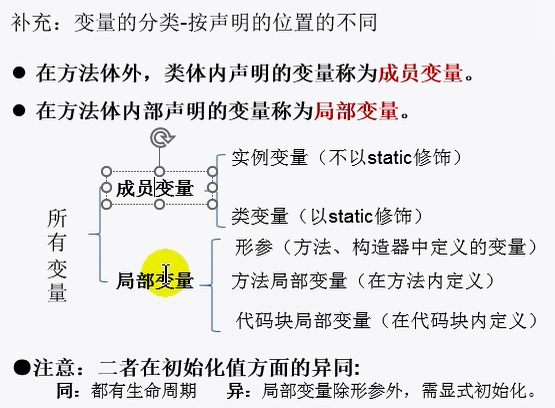
深度学习笔记之Transformer——PositionEmbedding铺垫:Skipgram与CBOW模型
引言
上一节介绍了 Word2vec \text{Word2vec} Word2vec模型架构与对应策略。本节将继续介绍 Skipgram \text{Skipgram} Skipgram与 CBOW \text{CBOW} CBOW模型架构。
回顾: Word2vec \text{Word2vec} Word2vec模型
关于 Word2vec \text{Word2vec} Word2vec模型,它的任务目标是基于语料库 ( Corpus ) (\text{Corpus}) (Corpus),对该语料库对应词汇表 ( Vocabulary ) (\text{Vocabulary}) (Vocabulary)中的每一个词表示成一个分布式向量 ( Distributed Vector ) (\text{Distributed Vector}) (Distributed Vector)。
而这个分布式向量需要满足:
- 作为特征表示的向量维数有限;
- 如果词与词之间存在相似性关系,我们希望对应的特征向量能够表达出来。
而我们已知的训练信息仅包含语料库,可以将语料库中的文本(句子)整合在一起,视作由若干个词语组成的超长序列
D
\mathcal D
D:
其中
w
t
(
t
=
1
,
2
,
⋯
,
T
)
w_t(t=1,2,\cdots,\mathcal T)
wt(t=1,2,⋯,T)表示一个随机变量,它可能是词汇表中的任意一个词,只不过存在各词均存在相应的概率而已。
D
=
{
w
1
,
w
2
,
⋯
,
w
T
}
\mathcal D = \{w_1,w_2,\cdots,w_{\mathcal T}\}
D={w1,w2,⋯,wT}
而优化分布式向量的策略可以使用极大似然估计进行描述:
- 关于语料库
D
\mathcal D
D内各随机变量的联合概率分布可表示为如下形式:
P ( w 1 : T ) = P ( w 1 , w 2 , ⋯ , w T ) = P ( w t ) ⋅ P ( w 1 : t − 1 , w t + 1 : T ∣ w t ) \begin{aligned} \mathcal P(w_{1:\mathcal T}) & = \mathcal P(w_1,w_2,\cdots,w_{\mathcal T}) \\ & = \mathcal P(w_t) \cdot \mathcal P(w_{1:t - 1},w_{t+1:\mathcal T} \mid w_t) \end{aligned} P(w1:T)=P(w1,w2,⋯,wT)=P(wt)⋅P(w1:t−1,wt+1:T∣wt)
其中 w t w_t wt表示位于语料库内的第 t ( t ∈ { 1 , 2 , ⋯ , T } ) t(t \in \{1,2,\cdots,\mathcal T\}) t(t∈{1,2,⋯,T})个位置的词;而 w 1 : t − 1 , w t + 1 : T w_{1:t - 1},w_{t+1:\mathcal T} w1:t−1,wt+1:T则表示词 w t w_t wt在该语料库中的上下文 ( Context ) (\text{Context}) (Context)信息。 P ( w 1 : t − 1 , w t + 1 : T ∣ w t ) \mathcal P(w_{1:t - 1},w_{t+1:\mathcal T} \mid w_t) P(w1:t−1,wt+1:T∣wt)则表示词 w t w_t wt对应的似然结果。 - 其中
P
(
w
t
)
\mathcal P(w_t)
P(wt)表示
D
\mathcal D
D中
w
t
w_t
wt这个位置关于词汇表
V
\mathcal V
V中所有词的概率分布,在上下文未知的条件下,其相当于在均匀分布中进行采样。各分量对应的概率结果均为
1
∣
V
∣
\begin{aligned}\frac{1}{|\mathcal V|}\end{aligned}
∣V∣1。
这里的∣ V ∣ |\mathcal V| ∣V∣则表示词汇表V \mathcal V V中词的数量。
基于 P ( w t ) \mathcal P(w_t) P(wt)这个定值,并不是我们关系的对象。我们更关心随机变量 w t w_t wt上下文的似然结果 P ( w 1 : t − 1 , w t + 1 : T ∣ w t ) P(w_{1:t - 1},w_{t+1:\mathcal T} \mid w_t) P(w1:t−1,wt+1:T∣wt)。对应地,其他随机变量的似然结果也可表示成该形式:
P ( w 1 : t − 1 , w t + 1 : T ∣ w t ) t = 1 , 2 , ⋯ , T \mathcal P(w_{1:t - 1},w_{t+1:\mathcal T} \mid w_t) \quad t=1,2,\cdots,\mathcal T P(w1:t−1,wt+1:T∣wt)t=1,2,⋯,T
其中每一项的后验部分均包含 T − 1 \mathcal T - 1 T−1个项。并且各项之间可能存在关联关系。因而我们想将 P ( w 1 : t − 1 , w t + 1 : T ∣ w t ) \mathcal P(w_{1:t - 1},w_{t+1:\mathcal T} \mid w_t) P(w1:t−1,wt+1:T∣wt)完整地表达出来几乎是不现实的(计算量与相关性的表达方面都有阻碍)。因而需要构造一系列的假设简化对似然的计算。- 假设
1
1
1:
w
t
w_t
wt仅能影响以
w
t
w_t
wt为中心,前后长度为
C
\mathcal C
C范围内的随机变量(上下文)。基于该假设,似然
P
(
w
1
:
t
−
1
,
w
t
+
1
:
T
∣
w
t
)
\mathcal P(w_{1:t - 1},w_{t+1:\mathcal T} \mid w_t)
P(w1:t−1,wt+1:T∣wt)可简化成如下形式:
对应的窗口大小为2 C 2\mathcal C 2C。
P ( w 1 : t − 1 , w t + 1 : T ∣ w t ) = (1) P ( w t − C : t − 1 , w t + 1 : t + C ∣ w t ) \mathcal P(w_{1:t - 1},w_{t+1:\mathcal T} \mid w_t) \overset{\text{(1)}}{=} \mathcal P(w_{t - \mathcal C \text{ : } t-1},w_{t+1 \text{ : } t+ \mathcal C} \mid w_t) P(w1:t−1,wt+1:T∣wt)=(1)P(wt−C : t−1,wt+1 : t+C∣wt) - 假设
2
2
2:在给定
w
t
w_t
wt的条件下,各似然结果之间相互独立。从而对应的完整似然函数可表示为:
引入log \log log函数,并引入均值操作。这样做的目的是希望窗口内的上下文信息尽量共同影响似然函数的变化,而不是集中在有限的几个随机变量。
∏ t = 1 T P ( w t − C : t − 1 , w t + 1 : t + C ∣ w t ) ⇒ 1 T ∑ t = 1 T log P ( w t − C : t − 1 , w t + 1 : t + C ∣ w t ) \prod_{t=1}^{\mathcal T} \mathcal P(w_{t - \mathcal C \text{ : } t-1},w_{t+1 \text{ : } t+ \mathcal C} \mid w_t) \Rightarrow \frac{1}{\mathcal T} \sum_{t=1}^{\mathcal T} \log \mathcal P(w_{t - \mathcal C \text{ : } t-1},w_{t+1 \text{ : } t+ \mathcal C} \mid w_t) t=1∏TP(wt−C : t−1,wt+1 : t+C∣wt)⇒T1t=1∑TlogP(wt−C : t−1,wt+1 : t+C∣wt) - 假设
3
3
3:在给定
w
t
w_t
wt的条件下,
w
t
−
C
,
⋯
,
w
t
−
1
,
w
t
+
1
,
w
t
+
C
w_{t-\mathcal C},\cdots,w_{t-1},w_{t+1},w_{t+\mathcal C}
wt−C,⋯,wt−1,wt+1,wt+C之间独立同分布。即:
w
t
−
C
∣
w
t
,
⋯
,
w
t
−
1
∣
w
t
,
w
t
+
1
∣
w
t
,
⋯
,
w
t
+
C
∣
w
t
w_{t-\mathcal C} \mid w_t,\cdots,w_{t-1} \mid w_t,w_{t+1} \mid w_t,\cdots,w_{t+\mathcal C} \mid w_t
wt−C∣wt,⋯,wt−1∣wt,wt+1∣wt,⋯,wt+C∣wt独立同分布。因而上式可以继续简化成如下形式:
由于假设3 3 3,使得随机变量之间失去了‘序列信息’。因而Word2vec \text{Word2vec} Word2vec系列模型并没有考虑序列信息,因为该模型的核心任务是生成“存在相似性关系”的分布式向量。
1 T ∑ t = 1 T ∑ i = − C ( ≠ 0 ) C log P ( w t + i ∣ w t ) \frac{1}{\mathcal T} \sum_{t=1}^{\mathcal T} \sum_{i=-\mathcal C(\neq 0)}^{\mathcal C} \log \mathcal P(w_{t+i} \mid w_t) T1t=1∑Ti=−C(=0)∑ClogP(wt+i∣wt)
- 假设
1
1
1:
w
t
w_t
wt仅能影响以
w
t
w_t
wt为中心,前后长度为
C
\mathcal C
C范围内的随机变量(上下文)。基于该假设,似然
P
(
w
1
:
t
−
1
,
w
t
+
1
:
T
∣
w
t
)
\mathcal P(w_{1:t - 1},w_{t+1:\mathcal T} \mid w_t)
P(w1:t−1,wt+1:T∣wt)可简化成如下形式:
最终,基于极大似然估计的优化函数
J
(
θ
)
\mathcal J(\theta)
J(θ)表示为如下形式:
{
θ
^
=
arg
min
θ
J
(
θ
)
J
(
θ
)
=
−
1
T
∑
t
=
1
T
∑
i
=
−
C
(
≠
0
)
C
log
P
(
w
t
+
i
∣
w
t
)
\begin{cases} \hat {\theta} = \mathop{\arg\min}\limits_{\theta} \mathcal J(\theta) \\ \mathcal J(\theta) = \begin{aligned} -\frac{1}{\mathcal T} \sum_{t=1}^{\mathcal T} \sum_{i=-\mathcal C(\neq 0)}^{\mathcal C} \log \mathcal P(w_{t+i} \mid w_t) \end{aligned} \end{cases}
⎩
⎨
⎧θ^=θargminJ(θ)J(θ)=−T1t=1∑Ti=−C(=0)∑ClogP(wt+i∣wt)
而
Word2vec
\text{Word2vec}
Word2vec模型的任务就是用来计算
P
(
w
t
+
1
∣
w
t
)
\mathcal P(w_{t+1} \mid w_t)
P(wt+1∣wt)。它的神经网络架构表示如下:

其中隐藏层神经元中的
∑
\sum
∑表示该神经元仅执行线性运算。也就是说,除了输出层的
Softmax
\text{Softmax}
Softmax函数,整个网络中不存在其他关于激活函数的非线性映射。原因在于:模型输入层、输出层的神经元数量均为
∣
V
∣
|\mathcal V|
∣V∣,这意味着隐藏层神经元数量也不会过小,因为数量过小会丢失更多信息。从而导致如果是非线性操作,后续的计算代价可能是无法估量的。
补充:关于 Word2vec \text{Word2vec} Word2vec的一些说明
上述模型的输出结果
w
o
w_o
wo是一个大小为
∣
V
∣
|\mathcal V|
∣V∣的随机变量:
w
o
∈
R
∣
V
∣
×
1
w_o \in \mathbb R^{|\mathcal V| \times 1}
wo∈R∣V∣×1
它描述的是
P
(
w
t
+
i
∣
w
t
)
(
i
∈
{
−
C
,
C
}
)
\mathcal P(w_{t+i} \mid w_t)(i \in \{-\mathcal C,\mathcal C\})
P(wt+i∣wt)(i∈{−C,C})。物理意义是:给定语料库
D
\mathcal D
D内的某个中心词,其上下文词的后验概率结果。但根据假设
(
1
)
(1)
(1),某中心词内包含
2
C
2\mathcal C
2C个上下文结果,并且这些上下文结果独立同分布。因而我们的神经网络应扩展为如下形式:

这个计算图它示如何描述上面三个假设的:
- 假设 1 1 1:基于某一个中心词 w i = ω t w_i = \omega_t wi=ωt作为输入,我们能够得到 2 C 2\mathcal C 2C个输出层结果,并且每个结果均是大小为 ∣ V ∣ |\mathcal V| ∣V∣的概率分布;
- 假设
2
2
2:输入层
w
i
w_i
wi无论输入哪一个元素
ω
1
,
ω
2
,
⋯
,
ω
T
\omega_1,\omega_2,\cdots,\omega_{\mathcal T}
ω1,ω2,⋯,ωT,均共用同一个计算图。这样能够保证各
ω
t
(
t
=
1
,
2
,
⋯
,
T
)
\omega_t(t=1,2,\cdots,\mathcal T)
ωt(t=1,2,⋯,T)的输出结果不仅相互独立,并且还同分布。
相互独立体现在:输入层的不同输入,对应的输出仅和该输入相关;同分布体现在:它们共用同一个计算图,共用相同的权重信息W , U \mathcal W,\mathcal U W,U。 - 假设 3 3 3:在输入层 w i = ω t w_i = \omega_t wi=ωt作为输入的条件下,其上下文各随机变量的输出分布均共用同一权重信息 U \mathcal U U。
而最终想要得到分布式向量到底是谁呢 ? ? ?自然是基于权重 W \mathcal W W作用下的隐藏层特征。而这个特征是否能够迁移到其他的语料库中 ? ? ?只要语料库使用相同语言(共用同一套语法),这个特征自然能够迁移到其他语料库中。
为什么会有这种效果
?
?
?这就要回到策略构建的过程中为什么要使用极大似然估计。回顾完整的似然函数,我们要让它最大:
max
{
1
T
∑
t
=
1
T
∑
i
=
−
C
(
≠
0
)
C
log
P
(
w
t
+
i
∣
w
t
)
}
\max \left\{\frac{1}{\mathcal T} \sum_{t=1}^{\mathcal T} \sum_{i=-\mathcal C(\neq 0)}^{\mathcal C} \log \mathcal P(w_{t+i} \mid w_t)\right\}
max⎩
⎨
⎧T1t=1∑Ti=−C(=0)∑ClogP(wt+i∣wt)⎭
⎬
⎫
由于
1
T
\begin{aligned}\frac{1}{\mathcal T}\end{aligned}
T1的作用,意味着每一个
P
(
w
t
+
i
∣
w
t
)
(
t
∈
{
1
,
2
,
⋯
,
T
}
;
i
∈
{
−
C
,
⋯
,
C
}
)
\mathcal P(w_{t+i} \mid w_t)(t \in\{1,2,\cdots,\mathcal T\};i \in \{-\mathcal C,\cdots,\mathcal C\})
P(wt+i∣wt)(t∈{1,2,⋯,T};i∈{−C,⋯,C})都要尽可能地达到最大。这会导致:中心词
w
t
w_t
wt与其对应的上下文结果
w
t
−
C
,
⋯
,
w
t
−
1
,
w
t
+
1
,
⋯
,
w
t
+
C
w_{t-\mathcal C},\cdots,w_{t-1},w_{t+1},\cdots,w_{t+\mathcal C}
wt−C,⋯,wt−1,wt+1,⋯,wt+C绑定在一起:
-
存在一组上下文 w t − C , ⋯ , w t − 1 , w t + 1 , ⋯ , w t + C w_{t-\mathcal C},\cdots,w_{t-1},w_{t+1},\cdots,w_{t+\mathcal C} wt−C,⋯,wt−1,wt+1,⋯,wt+C使下面式子达到最大;:
P ( w t − C , ⋯ , w t − 1 , w t + 1 , ⋯ , w t + C ∣ w t ) = ∏ i = − C ( ≠ 0 ) C P ( w t + i ∣ w t ) \mathcal P(w_{t-\mathcal C},\cdots,w_{t-1},w_{t+1},\cdots,w_{t+\mathcal C} \mid w_t) = \prod_{i=-\mathcal C(\neq 0)}^{\mathcal C} \mathcal P(w_{t+i} \mid w_t) P(wt−C,⋯,wt−1,wt+1,⋯,wt+C∣wt)=i=−C(=0)∏CP(wt+i∣wt) -
相反,如果换了一组上下文 w k − C , ⋯ , w k − 1 , w k + 1 , ⋯ , w k + C ( k ≠ t ) w_{k-\mathcal C},\cdots,w_{k-1},w_{k+1},\cdots,w_{k+\mathcal C}(k \neq t) wk−C,⋯,wk−1,wk+1,⋯,wk+C(k=t)(
这明显是另一个词w k w_k wk的上下文),它同样会得到一个结果:
P ( w k − C , ⋯ , w k − 1 , w k + 1 , ⋯ , w k + C ∣ w t ) \mathcal P(w_{k-\mathcal C},\cdots,w_{k-1},w_{k+1},\cdots,w_{k+\mathcal C} \mid w_t) P(wk−C,⋯,wk−1,wk+1,⋯,wk+C∣wt)
但这个结果会差于 P ( w t − C , ⋯ , w t − 1 , w t + 1 , ⋯ , w t + C ∣ w t ) \mathcal P(w_{t-\mathcal C},\cdots,w_{t-1},w_{t+1},\cdots,w_{t+\mathcal C} \mid w_t) P(wt−C,⋯,wt−1,wt+1,⋯,wt+C∣wt)。
基于上述逻辑,会有:如果两个词之间存在相似的情况,那么这两个词对应的上下文分布也应该是相似的。而这个相似的上下文结构反而成为了隐变量(隐藏层的输出)的一种判别依据。实际上,它并没有直接去描述相似性,而是从中心词与对应上下文的对应关系来学习隐变量,从而间接说明这个隐变量信息能够描述相似性。
实际上这个模型结构就是
Skip gram
\text{Skip gram}
Skip gram模型结构。而
CBOW
\text{CBOW}
CBOW模型与
Skip gram
\text{Skip gram}
Skip gram模型思想正好相反——上下文信息作为输入,共用同一个
W
\mathcal W
W,最终输出的是中心词的分布。
它的假设
3
3
3与
Skip gram
\text{Skip gram}
Skip gram相反,但同样也是基于条件的独立同分布。
相关参考:
词向量(Word Vector)【白板推导系列】