第一章 Clickhouse简介
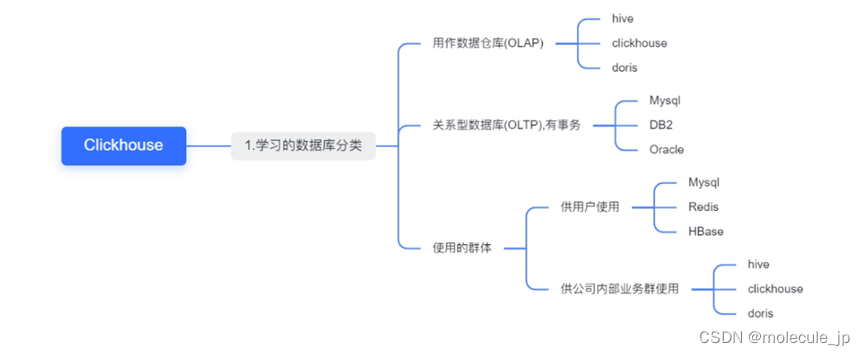
ClickHouse (C++编写)是俄罗斯的Yandex(相当于百度)于2016年开源的列式存储数据库(DBMS),使用C++语言编写,主要用于在线分析处理查询(OLAP),能够使用SQL查询实时生成分析数据报告。 一般做实时数仓
https://clickhouse.com/docs/zh/

第二章 Clickhouse的特点
2.1 列式存储
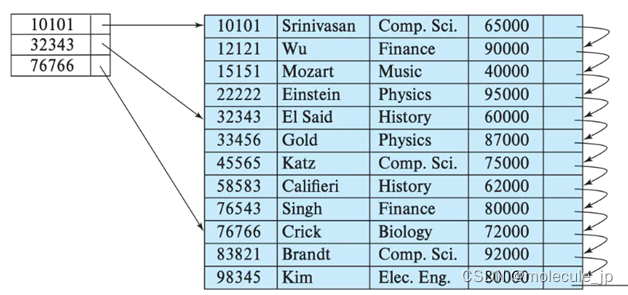
以下面的表为例:

采用行式存储时,数据在磁盘上的组织结构为:

好处是想查某个人所有的属性时,可以通过一次磁盘查找加顺序读取就可以。但是当想查所有人的年龄时,需要不停的查找,或者全表扫描才行,遍历的很多数据都是不需要的。
而采用列式存储时,数据在磁盘上的组织结构为:

这时想查所有人的年龄只需把年龄那一列拿出来就可以了
官方介绍: https://clickhouse.com/docs/zh/
列式储存的好处:
对于列的聚合,计数,求和等统计操作原因优于行式存储。列式数据库更适合于OLAP场景(对于大多数查询而言,处理速度至少提高了100倍),看视频和官网!
由于某一列的数据类型都是相同的,针对于数据存储更容易进行数据压缩,每一列选择更优的数据压缩算法,大大提高了数据的压缩比重。
由于数据压缩比更好,一方面节省了磁盘空间,另一方面对于cache也有了更大的发挥空间。
2.2 DBMS的功能
几乎覆盖了标准SQL的大部分语法,包括 DDL和 DML ,以及配套的各种函数。用户管理及权限管理和数据的备份与恢复。
2.3 多样化引擎
clickhouse和mysql(介绍了mysql的不同引擎)类似,把表级的存储引擎插件化,根据表的不同需求可以设定不同的存储引擎(比如可以使用Hive的引擎!)。目前包括合并树、日志、接口和其他四大类20多种引擎。
2.4 写(MergeTree)
ClickHouse采用类LSM Tree的结构,数据写入后定期在后台合并。通过类LSM tree的结构,但是没有内存表,没有预写日志,ClickHouse在数据导入时全部是顺序append写入磁盘,在后台周期性合并数据到主数据段。顺序写的特性,充分利用了磁盘的吞吐能力,即便在HDD上也有着优异的写入性能。
官方公开benchmark测试显示能够达到50MB-200MB/s的写入吞吐能力,按照每行100Byte估算,大约相当于50W-200W条/s的写入速度。
- 不支持常规意义的修改行和删除行数据。
- 不支持事务。OLAP都不支持
2.5 读(MergeTree)
2.5.1 语句级多线程
ClickHouse将数据划分为多个partition,每个partition再进一步划分为多个index granularity(颗粒),然后通过多个CPU核心分别处理其中的一部分来实现并行数据处理。
在这种设计下,单条Query就能利用整机所有CPU。极致的并行处理能力,极大的降低了查询延时。
弊端:
clickhouse即使对于大量数据的查询也能够化整为零平行处理。但是有一个弊端就是对于单条查询使用多cpu,就不利于同时并发多条查询。所以对于高qps的查询业务,clickhouse并不是强项。Redis就是高qps,如果有对于高qps的查询业务,可以将clickhouse的结果缓存到redis.
Mysql是语句级单线程(mysql服务器只会用一个线程进行处理Query)
2.5.2 稀疏索引
clickhouse使用稀疏索引,索引之间的颗粒度(默认8192行建一个索引)。因为clickhouse是用于海量数据的查询!
好处:范围查询过滤比较快。
弊端:不适合做点对点查询。不方便查询具体某行数据
2.6 生命周期管理
支持对数据的生存周期进行管理,可以像Redis那样失效掉过期的数据,维持数据的新陈代谢。可以对数仓的数据写脚本定时进行删除等操作!ttl
2.7 性能对比
clickhouse官方介绍: https://benchmark.clickhouse.com/
某网站精华帖,中对几款数据库做了性能对比。
单表查询:
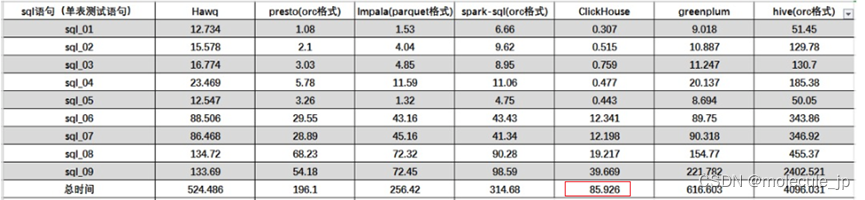
关联查询:

结论: clickhouse像很多OLAP数据库一样,单表查询速度优于关联查询,而且clickhouse的两者差距更为明显。
第三章 Clickhouse的安装
3.1 准备工作
3.1.1 CentOS取消打开文件数限制
三个机器都要改
在/etc/security/limits.conf 这 个文件的末尾加入一下内容:
[aa ~]$ sudo vim /etc/security/limits.conf
在文件末尾添加:
* soft nofile 65536
* hard nofile 65536
* soft nproc 131072
* hard nproc 131072
Soft的数量一定要超过hard
3.1.2 CentOS取消SELINUX
修改/etc/selinux/config中的SELINUX=disabled后重启虚拟机
[aa ~]# sudo vim /etc/selinux/config
SELINUX=disabled
查看当前状态:
[aa ~]$ getenforce
3.1.3 安装依赖
[aa ~]# sudo yum install -y libtool
[aa ~]# sudo yum install -y *unixODBC*
3.2 卸载
3.2.1 查看是否安装
rpm -qa | grep clickhouse
3.2.2 卸载
rpm -qa | grep clickhouse | sudo xargs rpm -e
3.2.3 删除数据和配置文件
sudo rm -rf /var/lib/clickhouse/
sudo rm -rf /etc/clickhouse-* s
sudo rm -rf /var/log/clickhouse-server/
如果是集群:
rm -rf /etc/metrika.xml
删除zk上的元数据:
rmr /clickhouse
3.3 单机安装
官网:https://clickhouse.yandex/
下载地址:http://repo.red-soft.biz/repos/clickhouse/stable/el6/
3.3.1 上传4个文件
[aa software]# ls
clickhouse/clickhouse-client-21.4.6.55-2.noarch.rpm
clickhouse/clickhouse-common-static-21.4.6.55-2.x86_64.rpm
clickhouse/clickhouse-common-static-dbg-21.4.6.55-2.x86_64.rpm
clickhouse/clickhouse-server-21.4.6.55-2.noarch.rpm
3.3.2分别在三台机子上安装这4个rpm文件
[aa@hadoop102 software]# sudo rpm -ivh *.rpm
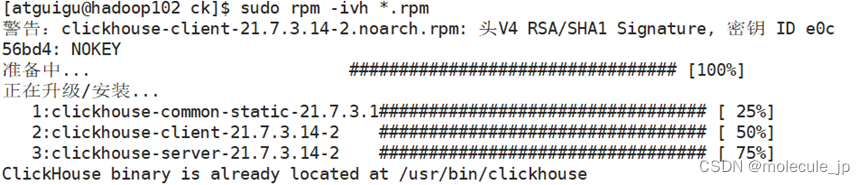
会向一些目录添加东西,所以需要sudo
为默认用户设置密码,可以设置也可以直接回车跳过。

3.3.3 修改配置文件
[aa]# sudo chmod 751 /etc/clickhouse-server/config.xml
[aa]# sudo vim /etc/clickhouse-server/config.xml

把 <listen_host>0.0.0.0</listen_host> 的注解打开,这样的话才能让clickhouse被除本机以外的服务器访问。
3.4 启动
3.4.1 启动Server
[aa]# sudo clickhouse start
server安装后,默认是开机自启动的,之后无需手动启动:
[aa ck]$ sudo systemctl list-unit-files | grep enable | grep clickhouse
clickhouse-server.service enabled
3.4.2 启动client
[aa]# clickhouse-client -h hadoop102 -m
-m mutiline
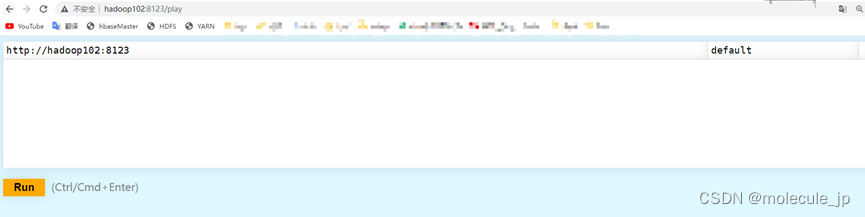
或者可以通过网页进行访问:







![[C语言][小游戏][猜数游戏]](https://img-blog.csdnimg.cn/e5924e40d8c34f159c6c8a7242c0b58e.png)