如有错误,恳请指出。
文章目录
- 1. 背景
- 2. 网络结构
- 2.1 Feature Encoder and Proposal Generation
- 2.2 voxel-to-keypoint scene encoding
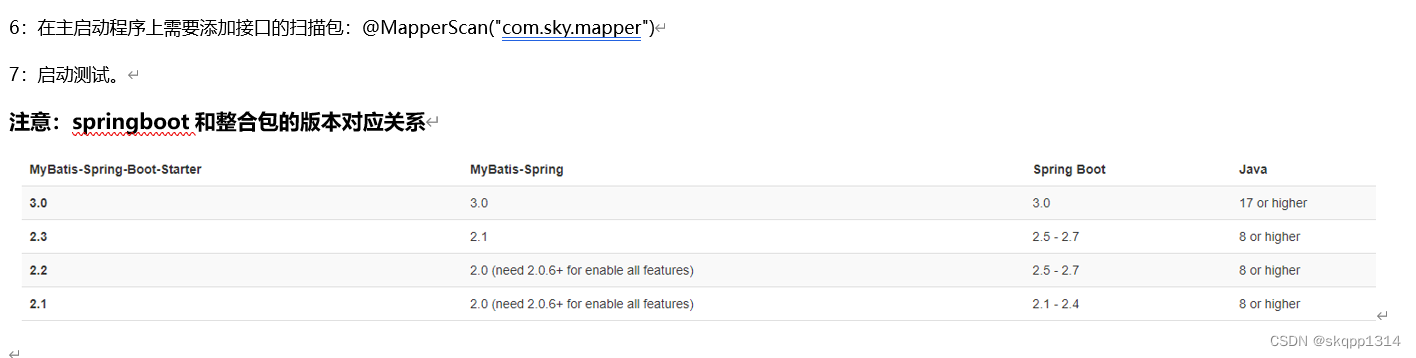
- 2.3 Keypoint-to-grid RoI Feature Abstraction
- 3. 实验部分
paper:《PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection》(2020CVPR)
1. 背景
基于voxel(paper中提到的是grid-based)的方法计算效率更高,但不可避免的信息损失降低了细粒度定位精度;而基于point的方法计算成本更高,但是通过PointNet++中的SA层(set abstraction layer)可以实现更大的感受野(这种说法是首次提出的)。
PV-RCNN的想法也是同时结合这两种方法的优势,取其所长,利用voxel-based操作进行有效的多尺度信息编码,生成高质量的3d候选框;同时利用改进的set abstraction模块操作保留精确的位置信息和灵活的感受野。同时利用两种方法的优势,实现学习到更多可区分性的特征。
2. 网络结构
PV-RCNN是一个Two-stage,anchor-based的3d检测算法,网络结构如下所示。主要思路是在proposal上进行roi改进,提出两个策略:体素到关键点场景编码(voxel-to-keypoint scene encoding)与点到网格RoI特征提取(point-togrid RoI feature abstraction),下面介绍各个部分的具体操作。

2.1 Feature Encoder and Proposal Generation
常规操作,对整个点云场景进行体素化,对非空体素用point-wise特征的平均值来计算,随后使用一些列的3x3x3的卷积核进行稀疏卷积处理下采样。不想Fast Point RCNN中先用3d卷积将z轴维度信息压缩为1再使用2d卷积对bev投影特征进行处理,PV-RCNN这里是将z轴特征进行叠加,得到bev特征图(尺寸大小为原尺寸的下采样8倍)。随后在特征图上类似SECOND与PointPillars进行anchor-based的方法,生成候选框(anchor的设置也一样,0°与90°两种anchor方向)。
对于two-stage的算法来说,获得候选框之后,一般需要对3d体积特征图或者2d特征图中进行特定的ROI信息汇集,来进一步对候选框进行修正。但是使用3d稀疏卷积后的特征具有一些限制:
1)空间分辨率较低(进行了8x下采样),妨碍了输入场景中对目标的准确定位;
2)既使可以通过上采样恢复,但特征仍然稀疏。因为常用的三线性插值或者是双线性插值都只能从比较小的邻域中获取特征,但由于稀疏性这种方法一般获得大部分特征是0,浪费了计算;
这里采用的方法就是利用SA层对点特征进行编码,但是对整个多尺度的roi区域会耗费性能,所以提出将整个场景的不同stage编码为少量的关键点,然后将这些关键点特征利用SA进行聚合。
2.2 voxel-to-keypoint scene encoding
对原始点云进行距离最远点采样获得k个关键点keypoints。
- Voxel Set Abstraction Module
在原始的PointNet++中,对每个关键点p以半径为r搜寻邻域的特征为point-wise特征,而在这里的是voxel-wise特征。具体来说,对于每一个关键点pi,在某一个特征层上其邻域半径r内,获取k个voxel-wise特征,每个voxel特征包含其自身的voxel特征以及当前voxel到关键点pi的相对位置信息。将其用类似set abstraction方法(MLP+Max pooling)进行区域特征聚合处理(得到的是一个编码的feature vector)。
通常在每层特征图上还会设置多个半径r来聚合不同感受野的局部voxel-wise特征(类似与PointNet++中的MSG操作),从而捕获更丰富的多尺度上下文信息。对3d voxel CNN中的不同阶段均执行上诉操作,可以获得多个网络stage的的feature vector。将这些不同层次包含不同尺寸范围的特征concat在一起组成关键点pi的语义特征(可以说是相当丰富了)。
此外,这里还额外扩展使用上了关键点pi的原始点云信息以及bev特征图上的信息,其中原始点云部分地弥补了点云体素化的量化损失,而2d的bev特征图沿着Z轴具有更大的感受野。原始点云信息使用上述voxel(下面的公式2)的类似方法聚合,而2d的bev特征图信息使用双线性插值来获取。所以关键点pi的完整特征组成如下:

- Predicted Keypoint Weighting
现在将整个3d点云场景通过少量的k个关键点进行编码,后续阶段将进一步利用这些关键点信息来进行候选框细化修正。但由于这些关键点是通过距离最远点采样(Further Point Sampling strategy)所获得,所以难免具有的背景点。这些背景点的贡献应该比前景点的贡献要小,所以PV-RCNN这里额外提出了一个关键点加权模块(Predicted Keypoint Weighting module),如下图所示。

具体实现上,利用3d标注框获取对应的掩码信息(关键点在GT的内部还是外部)进行有监督的语义分割训练,通过3层MLP处理再获得每个关键点的权重(sigmoid值)来重新作用与原始的特征上。
2.3 Keypoint-to-grid RoI Feature Abstraction
对于一阶段生成的候选框,现在需要聚合其中的关键点信息来对其进行修正处理。
与PartA2、PointRCNN类似,将候选框进行6x6x6大小进行网格化。如下图所示,对于每个grid points中,在其邻域具有关键点以及原始点,这里只对关键点信息进行处理。

具体来说,对每一个grid point设置r为半径的邻域,只获取其中的关键点信息,对原始点不作任何处理。对于每个关键点的信息组成是其上述操作获得的特征表示以及与grid point的相对位置信息。随后用类似set abstraction的方法将邻域中的所有关键点特征聚集,获得feature vector。当然,这里也会使用多个半径r来提取多个尺度的关键点信息。每个grid point的特征就是这些多个尺度的feature vector进行concat而成。

对候选框中的每个grid point获取到从不同邻域关键点的聚合信息后,接下里就可以进行MLP处理,来编码整个候选框信息(这里可能是将grid point的特征先进行reshape操作,再进行MLP处理)
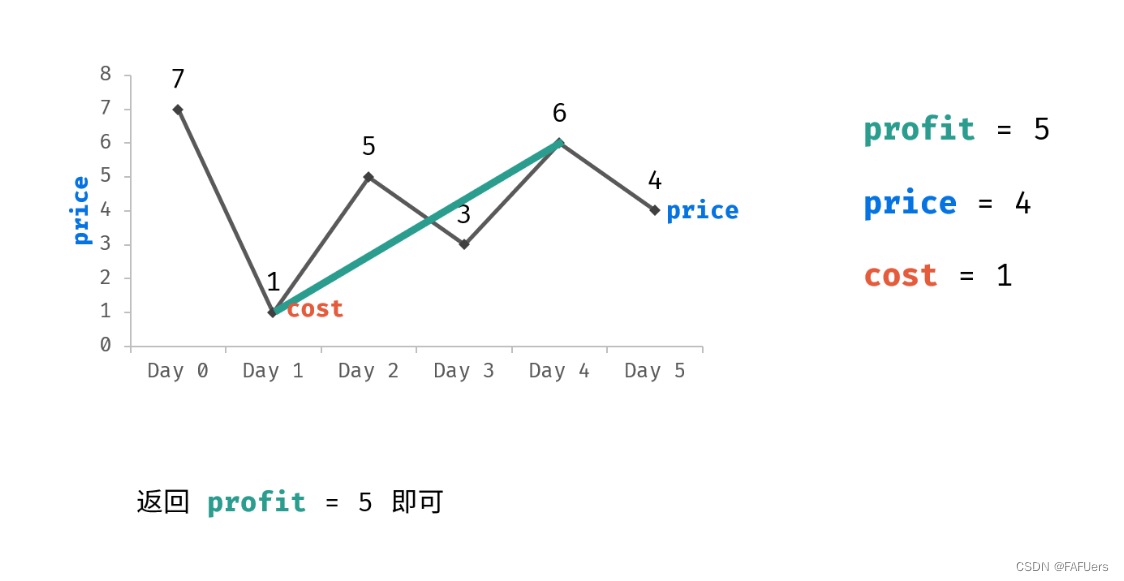
在后续操作中,对Confidence分支回归的是候选框与GT之前的3d IoU值, y k = m i n ( 1 , m a x ( 0 , 2 I o U k − 0.5 ) ) y_k = min (1, max (0, 2IoU_k − 0.5)) yk=min(1,max(0,2IoUk−0.5))。利用iou作为置信度预测基本是目标检测任务的标配了。对于Box Refinement,与SECOND、PartA2类似。其实,损失组成在多个经典网络均是类似的,无论是anchor-based或者是anchor-free的方法损失组成,直接参考PartA2即可。
3. 实验部分
效果如下就不多说了,效果杠杠的。不过好像比Voxel RCNN略低。

总结:
将整个检测任务转化成如何利用关键点聚合特征进行有效检测(比较新颖,别具一格),既利用了3d稀疏卷积提取特征,也使用了point-based的SA操作增加点的感受野。PV-RCNN涉及很多细节,在多个部分都使用到了多尺度这个概念:利用了3d稀疏卷积得到的多尺度特征图、获得关键点特征阶段利用每个不同stage的特征图上聚合多个半径范围的voxel-wise特征、获得roi特征阶段利用每个grid point也聚合多个半径范围的关键点特征。
同时这里还提到了一个如何使用权重预测前景点与背景点,利用额外的有监督训练弱化背景点的特征且提高前景点的特征贡献。这个是与3D-SSD中提到的F-FPS(特征最远点采样)对前景点与背景点不一样的思路。
既PointRCNN、PartA2之后,再一次仔细看大佬的文章,篇篇细节,篇篇经典。模型实现太复杂,大佬太强了…




![分布式文件存储系统FastDFS[3]-通过Docker安装并且从客户端进行上传下载测试](https://img-blog.csdnimg.cn/c53df8d8240948b0a3894966c0ced8fa.png)