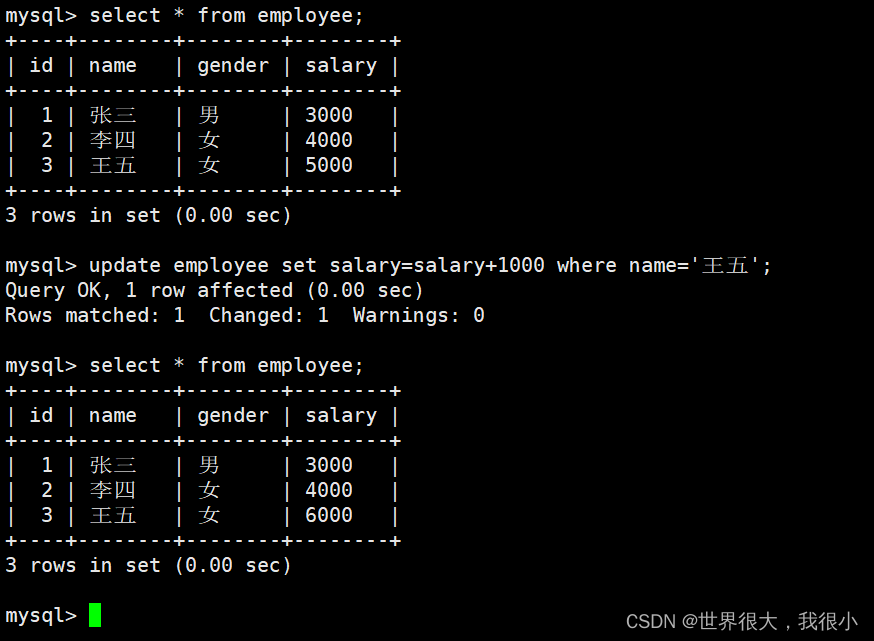
1 多模态概述
多模态指的是多种模态的信息数据,包括:文本、图像、视频、音频等。多模态任务是指需要同时处理两种或多种不同类型的数据的任务。近年来,随着深度学习技术的发展,多模态任务取得了显著的进步。特别是VIT(Vision Transformer)和CLIP(Contrastive Language–Image Pre-training)这两种基于Transformer模型的方法,极大地推动了多模态研究的发展。相比于传统的基于CNN(Convolutional Neural Network)的方法,Transformer能够对不同模态的数据进行统一建模,包括参数共享和特征融合。这极大地降低了多模态任务的复杂性和计算成本。
本文主要关注文本、图像两种模态数据的处理。
常见任务
- 图像描述(image captioning) :对给定图像生成描述性说明或生成字幕。
- 视觉定位(visual grounding):在给定的图像中定位具有指定描述的对象。
- 视觉问答(VQA):借助相关图像为文本问题生成文本答案。
- 跨模态检索(Cross-Modal Retrieval):包括利用文本搜索图像和利用图像搜索文本两种任务。
- 视觉推理(visual reasoning):对给定的图像图像推断常识信息和认知理解。可分为两个任务,包括问题回答(从问题的预期答案库中选择最佳答案)和回答理由(提供给定答案背后的理由)。
2 近期论文关系梳理
多模态近期出现较多论文,各论文的关系图如下,相同颜色代表作者是同一团队。
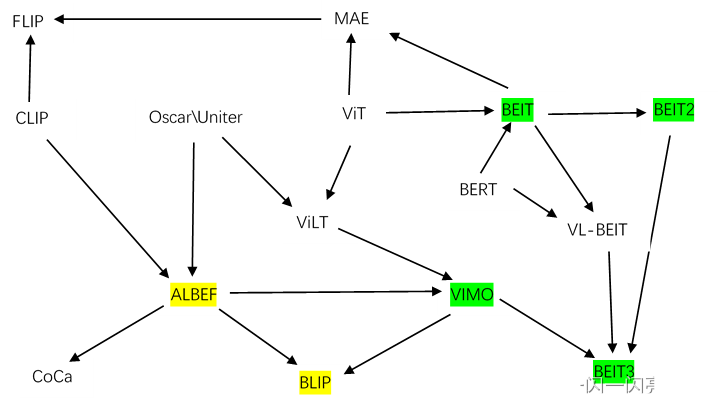
- ViLT:多模态学习之前都是Oscar或者Uniter的这些工作,但他们的缺陷是因为用了Object Detection的模型做视觉特征抽取,所以速度太慢,在Vision Transformer之后,Vilt的作者用一个Vision Transformer去代替vision特征提取,只用一个Embedding层大大简化了模型结构,所以结合VIT和Oscar推出了ViLT。
- ALBEF:ALBEF的作者发现Clip比较高效,适合做Image Text Retrieval,原始的方法因为Modality Fusion做得很好,所以多模态任务非常强,ViLT结构比较简单,所以最后综合各算法长处推出了ALBEF这样一个Fusion Encoder的模式.
- CoCa:SimVLM用Encoder Decoder去做多模态,它的作者在ALBEF的基础上推出了CoCa,用一个Contrast和Captioning两个Loss训练出非常强大的模型。
- VLMO:微软根据ALBEF和Vilt,提出VLMO,用共享参数的方式做一个统一的多模态的框架
- BLIP:ALBEF的作者基于参数共享的思想,基于可以用很多Text Branch,提出Blip的模型,能做非常好的Captioning功能,而且它的Caption Filter模型非常好用,能够像一个普适工具一样用到各种各样的情形中。
详细解析参考:多模态系列论文–BLIP 详细解析 - BEIT:ViT也用Mask Data Modeling的方式做Self-Supplied Learning,但是效果不是很好,而微软团队认为Mask Data Modeling是非常有前景的方向,所以顺着Bert的思想提出BEIT,号称计算机视觉界的Bert Moment,很快又推出BEITv2,但这个主要做视觉任务,不是多模态。
- Vision Language BEIT:BEIT可以在视觉上做Mask Modeling,Bert可以在文本上做Mask Modeling,因此作者将视觉和文本合在一起,推出VL-BEIT
- BEITv3:该团队将VLMO, VLBEIT和BEITv2三个工作合起来,推出多模态的BEITv3,大幅超过了CoCa, Blip在单模态和多模态上的各种表现。
详细解析参考:多模态系列论文–BEiT-3 详细解析 - MAE:Mask Auto Encoder,主要是Mask and Predict Pixel(BEIT是Mask and Predict Patch),其实Vision Transformer都已经做,但是效果都不是很好,BEIT和MAE都把效果推到一个非常高的高度
- Flip:Fast Language Image Prediction,MAE有一个非常好的一个特性,就是在视觉端把大量的Patch全都Mask掉之后,只把没有Mask过的Patch送入Vision Transformer学习,大大减少了计算量,Flip把MAE的这个有用的特性用到Clip的结构里,模型就是Clip没有任何的改变,只不过在视觉端跟MAE一样,只用没有Mask的Token,这样就把Sequence Length降低了很多,训练就快了。
详细解析参考:多模态系列论文–CLIP 详细解析
4 最新进展
目前很多工作认为之前模型不够统一,不是真正意义上的Unified Framework,只是更灵活的把很多模型拼到一起,对于大一统的框架,目前主要是两种思路。
- 微软的MetaLM,Google的Poli,提出模型就是一个Encoder Decoder,有图像的输入,文本的输入,模型不论是在预训练的时候还是在下游任务的时候做什么,完全是由文本的Prompt决定。不论什么任务,它的输出永远都是文字。所以是Text Generation任务,它通过调整各种各样的Prompt,也就是文章的Language Interface,只需要调整它的Language,这个模型就知道在做什么任务。这个模型真的是很少被改动。所以算得上是一个Unified Framework。
- Generalist Model通用模型:不论在预训练的时候,还是在做下游任务的时候,都只用一个模型直接训练好就可以了,不再根据下游任务调整模型结构,或者再给它加一个Task Specific的Head,最近也有一些工作比如Unified IO、UniPerceiver、UniPerceiver MOE、UniPerceiver V2等,虽然暂时效果还没有优势,但是应该很快就会有进一步的提升。
5 常用损失函数
- ITC(Image-Text Contrastive loss): 使用对比损失来约束image与text的特征,positive靠近,negative远离。
- ITM(Image-Text Matching loss): 选取对比计算中的hard negative,要求网络计算其是否匹配,赋予网络具有挑战的任务。
- MLM(Masked Language Modeling): BERT的预训练函数,ALBEF和VLMO也用这个目标函数,类似完形填空,将一个句子某个中间词mask掉,再预测这个中间词,属于双向模型
- LM(Language Modeling):给定一个句子,mask掉一个句子后半部分,然后用前半部分去预测句子后面内容,BLIP、GPT的预训练函数。有的论文称为Captioning Loss
致谢:
感谢李沐老师和朱老师的详细讲解,本文是对朱老师课程的总结,并增加个人理解,详细内容请参考两位老师的课程,谢谢。