目录标题
- 一. 通过 pdfplumber.open() 解析复杂PDF:
- 1-2. 报错:
- V2 :
- 1-3. v3 使用tk 库,弹框选择文件
- 运行环境准备
- 完整代码保存
- 运行测试步骤
- 方式二:命令行方式(适用于自动化)
- 测试用例示例
- 常见问题排查
- 1. 无文件选择对话框弹出:
- 2. No such file or directory错误:
- 3. 提取内容为空:
- 4. 内存不足错误:
- 扩展测试建议
- 1-10 总结:
- 二. PDF中包含表格,table = first_page.extract_table() 只能提取到 PDF文件中的表头如下:
- 1. 表格结构识别问题
- 解决办法
- 2. 文本布局问题
- 解决办法
- 3. 字体和颜色问题
- 解决办法
一. 通过 pdfplumber.open() 解析复杂PDF:
这段 Python 代码使用了 pdfplumber 库来读取 PDF 文件中的文本内容,下面是逐行解释:
import pdfplumber
- 引入
pdfplumber模块,这是一个用于从 PDF 文件中提取文本、表格等内容的第三方库。
# 打开 PDF 文件, 这里写死了,看下面的V2版本,用弹框选择文件
with pdfplumber.open("example.pdf") as pdf:
- 使用
pdfplumber.open()方法打开名为"example.pdf"的 PDF 文件。 - 使用
with语句可以确保文件使用完后会自动关闭,避免资源泄露。
# 获取第一页
page = pdf.pages[0]
- 获取 PDF 文件的第一页内容,
pdf.pages是一个页面对象的列表,索引从 0 开始。
# 提取文本
text = page.extract_text()
- 调用
extract_text()方法从第一页中提取文本内容。 - 这个方法返回一个字符串,包含该页的所有可提取文本(按照排版顺序)。
print(text)
- 将提取到的文本打印出来。
1-2. 报错:
ImportError: DLL load failed while importing _rust: 找不到指定的程序。
Traceback:
File "D:\Users\wang\PycharmProjects\github\ltkj-aiseek\seek_backend_py\ltjt_ai_seek_app\com\szkj\test_pdf\pdf_parser.py", line 2, in <module>
import pdfplumber
File "D:\Users\wang\PycharmProjects\github\ltkj-aiseek\seek_backend_py\.venv\lib\site-packages\pdfplumber\__init__.py", line 15, in <module>
from .pdf import PDF
File "D:\Users\wang\PycharmProjects\github\ltkj-aiseek\seek_backend_py\.venv\lib\site-packages\pdfplumber\pdf.py", line 8, in <module>
from pdfminer.layout import LAParams
File "D:\Users\wang\PycharmProjects\github\ltkj-aiseek\seek_backend_py\.venv\lib\site-packages\pdfminer\layout.py", line 21, in <module>
from pdfminer.pdfinterp import Color, PDFGraphicState
File "D:\Users\wang\PycharmProjects\github\ltkj-aiseek\seek_backend_py\.venv\lib\site-packages\pdfminer\pdfinterp.py", line 10, in <module>
from pdfminer.pdfdevice import PDFDevice, PDFTextSeq
File "D:\Users\wang\PycharmProjects\github\ltkj-aiseek\seek_backend_py\.venv\lib\site-packages\pdfminer\pdfdevice.py", line 16, in <module>
from pdfminer.pdfpage import PDFPage
File "D:\Users\wang\PycharmProjects\github\ltkj-aiseek\seek_backend_py\.venv\lib\site-packages\pdfminer\pdfpage.py", line 6, in <module>
from pdfminer.pdfdocument import (
File "D:\Users\wang\PycharmProjects\github\ltkj-aiseek\seek_backend_py\.venv\lib\site-packages\pdfminer\pdfdocument.py", line 23, in <module>
from cryptography.hazmat.primitives.ciphers import Cipher, algorithms, modes
File "D:\Users\wang\PycharmProjects\github\ltkj-aiseek\seek_backend_py\.venv\lib\site-packages\cryptography\hazmat\primitives\ciphers\__init__.py", line 11, in <module>
from cryptography.hazmat.primitives.ciphers.base import (
File "D:\Users\wang\PycharmProjects\github\ltkj-aiseek\seek_backend_py\.venv\lib\site-packages\cryptography\hazmat\primitives\ciphers\base.py", line 10, in <module>
from cryptography.hazmat.bindings._rust import openssl as rust_openssl
你遇到的 ImportError: DLL load failed while importing _rust: 找不到指定的程序 错误通常是由于缺少某些依赖项或环境配置问题导致的。以下是一些可能的解决方案:
- 确保安装了所有必要的依赖项
确保你已经安装了所有必要的依赖项,特别是 cryptography 和 pdfplumber。你可以使用以下命令来安装这些库:
pip install pdfplumber cryptography
- 安装 Visual C++ Redistributable
有时,这个错误是由于缺少 Microsoft Visual C++ Redistributable 包引起的。你可以从微软官方网站下载并安装最新版本的 Visual C++ Redistributable for Visual Studio 2015, 2017, 2019 或 2022。
Visual C++ Redistributable for Visual Studio 2015, 2017, and 2019
Visual C++ Redistributable for Visual Studio 2022
- 检查 Python 和 pip 的版本
确保你使用的是兼容的 Python 和 pip 版本。你可以使用以下命令来检查和升级它们:
python --version
pip --version
pip install --upgrade pip
- 重新安装 cryptography 库
有时,重新安装 cryptography 库可以解决问题。你可以使用以下命令来卸载并重新安装它:
pip uninstall cryptography
pip install cryptography
如果都安装了,还是报错,那就是python版本的问题:
从3.9 -> 3.12 ,换完之后 ,成功


验证 安装成功
pip show pdfplumber
linux下 一样,pdfplumber 好像需要python3.12 版本:
V2 :
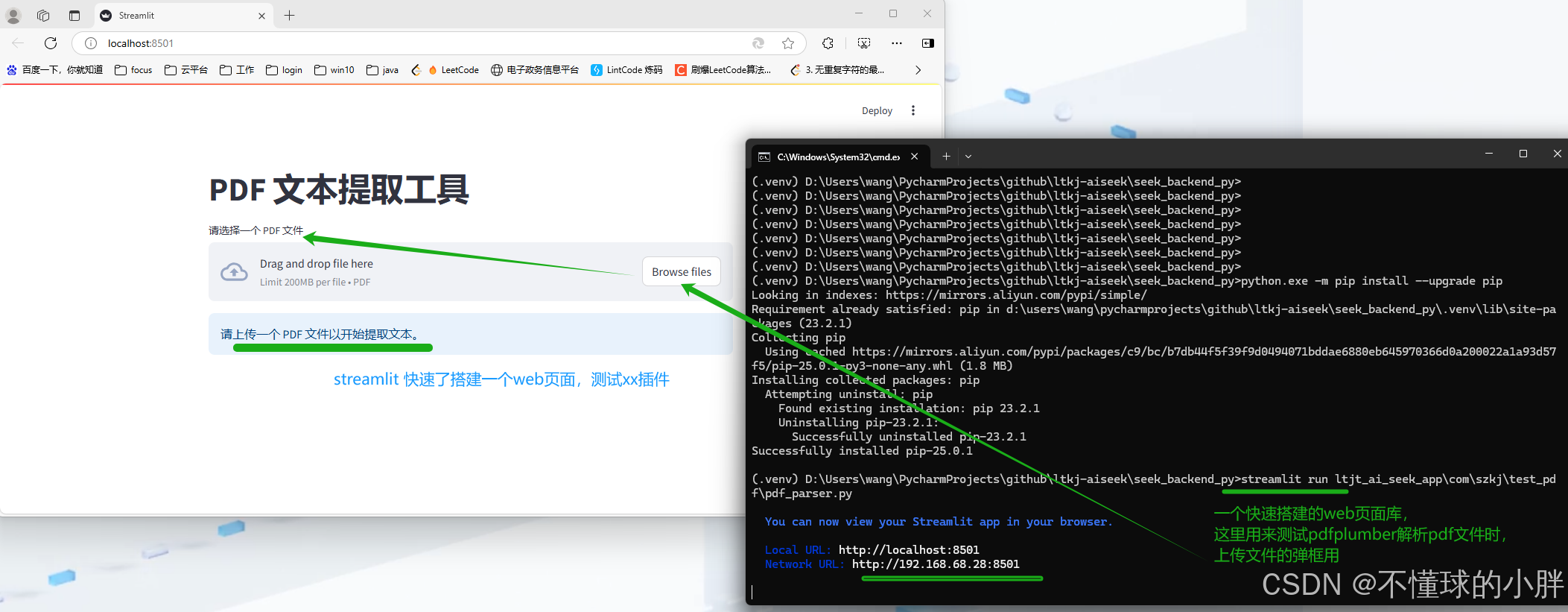
代码如下:
import streamlit as st
import pdfplumber
import io
# 设置页面标题
st.title("PDF 文本提取工具")
# 创建文件上传组件
uploaded_file = st.file_uploader("请选择一个 PDF 文件", type=["pdf"])
if uploaded_file is not None:
# 读取上传的文件
file_bytes = uploaded_file.read()
# 转换为类文件对象
file_stream = io.BytesIO(file_bytes)
# 使用 pdfplumber 打开 PDF 文件
with pdfplumber.open(file_stream) as pdf:
# 获取第一页
page = pdf.pages[0]
# 提取文本
text = page.extract_text()
# 显示提取的文本
if text:
st.subheader("提取的文本内容:")
st.write(text)
else:
st.warning("未能从该页提取到任何文本。")
else:
st.info("请上传一个 PDF 文件以开始提取文本。")
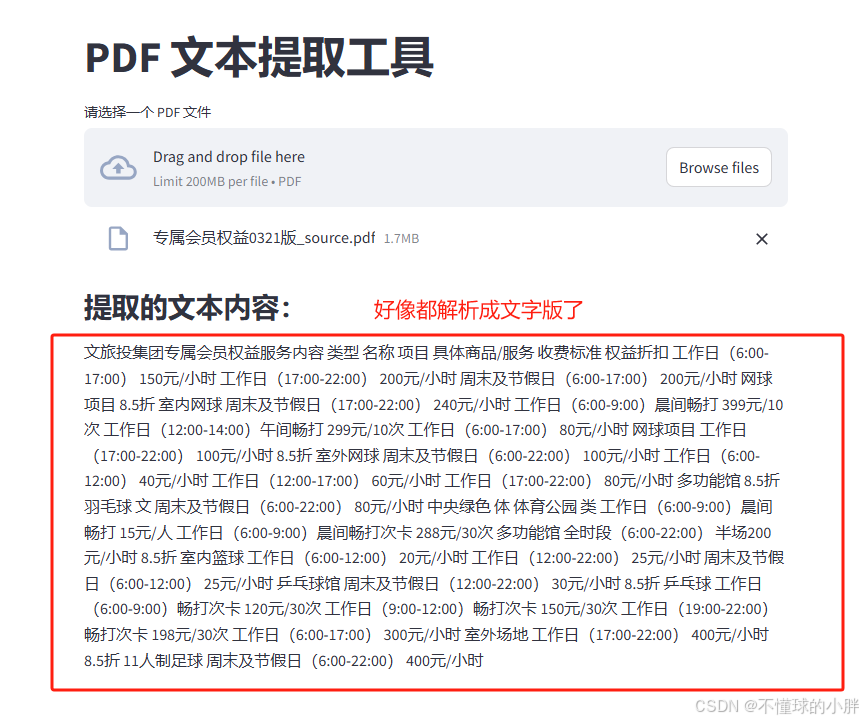
提取的文本内容:
文旅投集团专属会员权益服务内容 类型 名称 项目 具体商品/服务 收费标准 权益折扣 工作日(6:00-17:00) 150元/小时 工作日(17:00-22:00) 200元/小时 周末及节假日(6:00-17:00) 200元/小时 网球项目 8.5折 室内网球 周末及节假日(17:00-22:00) 240元/小时 工作日(6:00-9:00)晨间畅打 399元/10次 工作日(12:00-14:00)午间畅打 299元/10次 工作日(6:00-17:00) 80元/小时 网球项目 工作日(17:00-22:00) 100元/小时 8.5折 室外网球 周末及节假日(6:00-22:00) 100元/小时 工作日(6:00-12:00) 40元/小时 工作日(12:00-17:00) 60元/小时 工作日(17:00-22:00) 80元/小时 多功能馆 8.5折 羽毛球 文 周末及节假日(6:00-22:00) 80元/小时 中央绿色 体 体育公园 类 工作日(6:00-9:00)晨间畅打 15元/人 工作日(6:00-9:00)晨间畅打次卡 288元/30次 多功能馆 全时段(6:00-22:00) 半场200元/小时 8.5折 室内篮球 工作日(6:00-12:00) 20元/小时 工作日(12:00-22:00) 25元/小时 周末及节假日(6:00-12:00) 25元/小时 乒乓球馆 周末及节假日(12:00-22:00) 30元/小时 8.5折 乒乓球 工作日(6:00-9:00)畅打次卡 120元/30次 工作日(9:00-12:00)畅打次卡 150元/30次 工作日(19:00-22:00)畅打次卡 198元/30次 工作日(6:00-17:00) 300元/小时 室外场地 工作日(17:00-22:00) 400元/小时 8.5折 11人制足球 周末及节假日(6:00-22:00) 400元/小时

1-3. v3 使用tk 库,弹框选择文件
以下是运行完整示例程序并进行测试的详细步骤说明:
运行环境准备
- 安装依赖库:
pip install pdfplumber tk
-
pdfplumber:用于PDF解析
-
tk:用于图形界面(Python自带,但部分Linux系统可能需要单独安装)
-
准备测试文件:
-
准备一个测试用的PDF文件(建议同时准备正常PDF和错误文件用于测试异常处理)
完整代码保存
新建一个.py文件(如pdf_extractor.py),粘贴以下代码:
import pdfplumber
import io
import tkinter as tk
from tkinter import filedialog
# 创建隐藏的根窗口
root = tk.Tk()
root.withdraw()
# 打开文件选择对话框
file_path = filedialog.askopenfilename(
title="选择PDF文件",
filetypes=[("PDF文件", "*.pdf")]
)
if not file_path:
print("未选择文件")
exit()
try:
# 先读取为字节数据
with open(file_path, "rb") as f:
file_bytes = f.read()
# 转换为类文件对象
file_stream = io.BytesIO(file_bytes)
# 解析PDF
with pdfplumber.open(file_stream) as pdf:
first_page = pdf.pages[0]
print("="*30 + "\n提取的文本内容:\n" + "="*30)
print(first_page.extract_text() or "未检测到文本内容")
except Exception as e:
print(f"处理文件时出错:{str(e)}")
运行测试步骤
####. 方式一:图形界面方式(推荐)
启动程序:
python pdf_extractor.py
- 选择文件:
- 将自动弹出文件选择对话框
- 选择准备好的测试PDF文件(建议选择包含可识别文本的简单PDF)
- 查看输出:
==============================
提取的文本内容:
==============================
这里是PDF第一页的文本内容...
方式二:命令行方式(适用于自动化)
python pdf_extractor.py "/path/to/your/file.pdf"
测试用例示例
| 测试场景 | 预期结果 | 验证点 |
|---|---|---|
| -------- | -------- | ----- |
| 选择正常PDF文件 | 正确输出第一页文本 | 文本提取功能正常 |
| 取消文件选择 | 输出"未选择文件"并退出 | 异常处理逻辑正常 |
| 选择非PDF文件(如.jpg) | 弹出错误提示 | 文件类型过滤有效 |
| 选择加密的PDF文件 | 抛出解密错误 | 异常处理机制有效 |
| 选择损坏的PDF文件 | 显示解析错误信息 | 健壮性验证 |
常见问题排查
1. 无文件选择对话框弹出:
- 检查是否安装了图形界面支持
- 在Linux服务器环境可使用以下命令安装基础GUI支持:
sudo apt-get install python3-tk
2. No such file or directory错误:
- 确认文件路径是否正确
- 检查文件权限设置
3. 提取内容为空:
- 测试文件是否是扫描版图片PDF(需要OCR处理)
- 尝试使用官方测试文件:
# 测试代码
import pdfplumber
with pdfplumber.open("https://www.w3.org/WAI/ER/tests/xhtml/testfiles/resources/pdf/dummy.pdf") as pdf:
print(pdf.pages[0].extract_text())
4. 内存不足错误:
对于超大PDF文件(>100MB),改用文件路径方式打开:
# 替代BytesIO的方式
with pdfplumber.open(file_path) as pdf:
# 处理逻辑
扩展测试建议
- 多页测试:
# 修改代码遍历所有页面
for i, page in enumerate(pdf.pages):
print(f"第 {i+1} 页内容:")
print(page.extract_text())
- 表格提取测试: TODO 看看能不能 弥补上面 V2 解析结果错乱的问题
# 在with语句中添加
table = first_page.extract_table()
if table:
print("\n检测到表格:")
for row in table:
print(row)
- 性能测试:
import time
start = time.time()
# 处理代码
print(f"处理耗时:{time.time()-start:.2f}秒")
通过以上步骤可以完整验证PDF文本提取功能的可用性和健壮性。
1-10 总结:
这段代码实现了从一个名为 example.pdf 的 PDF 文件中提取第一页的文本,并将其输出到控制台。它适合用于快速查看或处理 PDF 中的文本信息。
如果你有 PDF 文件想解析或提取特定内容,也可以告诉我,我可以帮你构建更复杂的提取逻辑。
二. PDF中包含表格,table = first_page.extract_table() 只能提取到 PDF文件中的表头如下:
提取的文本内容:
==============================
['类型', '名称', '项目', '具体商品/服务', '收费标准', '权益折扣']
表格里的单元格数据 提取不到
1. 表格结构识别问题
pdfplumber 是基于规则来识别表格的,若表格的结构较为复杂或者不规则,它可能无法正确识别表格的边界,进而导致只能提取到表头。
解决办法
调整表格检测参数:可以通过修改 table_settings 参数来调整表格检测的规则。例如,修改 vertical_strategy 和 horizontal_strategy 参数,让其能更精准地识别表格的边界。
import pdfplumber
pdf_path = 'your_pdf_file.pdf'
with pdfplumber.open(pdf_path) as pdf:
first_page = pdf.pages[0]
# 调整表格检测参数
table_settings = {
"vertical_strategy": "text",
"horizontal_strategy": "text"
}
table = first_page.extract_table(table_settings)
for row in table:
print(row)
效果:

有单元格内容,也能成行成行打印了,但是对于前2列 是合并行的单元格,还不友好。
2. 文本布局问题
若表格中的文本布局比较特殊,例如存在合并单元格、跨页表格等情况,pdfplumber 可能难以正确识别表格的结构。
解决办法
- 手动指定表格区域:可以通过指定表格的坐标区域来精确提取表格数据。你可以使用 pdfplumber 的 crop() 方法来裁剪页面,只保留表格所在的区域。
生成 pdf_table_extraction_manual.py。 未测试验证
import pdfplumber
pdf_path = 'your_pdf_file.pdf'
with pdfplumber.open(pdf_path) as pdf:
first_page = pdf.pages[0]
# 手动指定表格区域的坐标(x0, top, x1, bottom)
table_bbox = (100, 200, 500, 400)
cropped_page = first_page.crop(table_bbox)
table = cropped_page.extract_table()
for row in table:
print(row)
3. 字体和颜色问题
如果表格中的文本使用了特殊的字体或者颜色,pdfplumber 在识别文本时可能会出现问题。
解决办法
- 检查 PDF 文件:尝试使用 PDF 阅读器打开文件,查看表格中的文本是否能够正常显示。若文本显示存在问题,可以尝试重新生成 PDF 文件。





![[数据结构]图krusakl算法实现](https://i-blog.csdnimg.cn/blog_migrate/a9d7c46158ab904efc0766b48abc738f.png)