上回说到在我们搭好的YAF3环境上使用yaf处理pcap文件得到silk flow,再使用super mediator工具转为ipfix,继而在spark中导入mothra,就可以开始数据分析了。然而在我们粗粗一用之下,却发现DPI信息在ipfix文件中找不到,到底是提取的时候就没提取出来(ipfix不支持dpi信息存储)?还是说我们的分析方式不对?——换句话说yaf、super-mediator、methora这三个环节,问题到底出在哪里了?我们卖了个关子,为本篇开启留了个伏笔。实则是我也不知道……。
所以,本篇从记录排查过程的角度,更深入地探索以下这3个组件——主要是methora的使用。
一、YAF肯定没有问题
因为我们在执行 super_mediator -o result.txt -m text test.yaf的时候已经从yaf的结果文件中导出过txt版本的dpi记录,其中是存在dns和tls的,可以证明相关的信息在test.yaf中确实存在。
使用json格式导出一次,也可以证明结果还比较“完备”:
[root@12c4bd60ff5f testdata]# rm tmp.ipfix -f
[root@12c4bd60ff5f testdata]# super_mediator -o test2.json -m json test2.yaf
Initialization Successful, starting...
[2023-06-30 05:59:34] Running as root in --live mode, but not dropping privilege
cat输出的json文件,可以看到tls和dns的相关记录也都在里面:

二、super-mediator也没问题
既然super-mediator的txt模式和json模式都没有问题,那是不是ipfix模式不支持dpi信息呢(之前我们是这么猜的)。这个猜测,我们通过观察super-mediator的执行log记录否定了:
[root@12c4bd60ff5f testdata]# super_mediator -o tmp.ipfix --verbose test2.yaf
[2023-06-30 06:16:23] super_mediator starting
[2023-06-30 06:16:23] E1: Opening File tmp.ipfix
[2023-06-30 06:16:23] E1: Exporter Active.
Initialization Successful, starting...
[2023-06-30 06:16:23] Running as root in --live mode, but not dropping privilege
[2023-06-30 06:16:23] C1: Opening file: test2.yaf
[2023-06-30 06:16:23] COL C1(1) TID 0xd006: received. Labeled as IE_SPEC - TMD OR IE - EXACT_DEF
[2023-06-30 06:16:23] COL C1(1) TID 0xd007: received. Labeled as TMD - TMD OR IE - EXACT_DEF
[2023-06-30 06:16:23] COL C1(1) TID 0xd008: received. Labeled as TMD - TMD OR IE - EXACT_DEF
[2023-06-30 06:16:23] COL C1(1) TID yaf_dns_a (0xce01): received. Labeled as NESTED DATA - DPI - DPI UNKNOWN - EXACT_DEF
[2023-06-30 06:16:23] EXP E1(1) TID yaf_dns_a (0xce01): Adding new template
[2023-06-30 06:16:23] COL C1(1) TID yaf_dns_aaaa (0xce02): received. Labeled as NESTED DATA - DPI - DPI UNKNOWN - EXACT_DEF
…… …… ……
[2023-06-30 06:16:23] EXP E1(1) TID yaf_ssl_cert (0xca0b): Adding new template
[2023-06-30 06:16:23] COL C1(1) TID yaf_ssh (0xcc00): received. Labeled as NESTED DATA - DPI - DPI UNKNOWN - EXACT_DEF
[2023-06-30 06:16:23] EXP E1(1) TID yaf_ssh (0xcc00): Adding new template
…… …… ……
[2023-06-30 06:16:23] COL C1(1) TID yaf_flow_rle_tcp_ip4_total_biflow (0xb022): Added observationDomainId
[2023-06-30 06:16:23] COL C1(1) TID yaf_flow_rle_tcp_ip4_total_biflow (0xb022): Added yafFlowKeyHash
…… …… ……
[2023-06-30 06:16:23] Collector Stats: C1-INACTIVE-SINGLE FILE: Total Records Read: 3418, Files Read: 1, Restarts: 0, UNKNOWN Records: 0, FLOW Records: 3416, YAF STATS Records: 1, TOMBSTONE Records: 1, DNS DEDUP Records: 0, SSL DEDUP Records: 0, GENERAL DEDUP Records: 0, DNS RR Records: 0, TMD OR IE Records: 0, DPI Records: 0, UNKNOWN DATA Records: 0, UNKNOWN OPTIONS Records: 0, No filters used
[2023-06-30 06:16:23] Core Stats: Records Processed: 3418, UNKNOWN Records: 0, FLOW Records: 3416, YAF STATS Records: 1, TOMBSTONE Records: 1, DNS DEDUP Records: 0, SSL DEDUP Records: 0, GENERAL DEDUP Records: 0, DNS RR Records: 0, TMD OR IE Records: 0, DPI Records: 0, UNKNOWN DATA Records: 0, UNKNOWN OPTIONS Records: 0, AppLabel 0 Records: 1401, AppLabel 53 Records: 601, AppLabel 80 Records: 790, AppLabel 123 Records: 1, AppLabel 137 Records: 42, AppLabel 138 Records: 28, AppLabel 161 Records: 4, AppLabel 443 Records: 537, AppLabel 51443 Records: 12, Tombstone Records Generated: 0
[2023-06-30 06:16:23] Exporter Stats: E1-ACTIVE-SINGLE FILE: Total Records Written: 3418, Files Written: 1, Bytes Written: 614700, Restarts: 0, No filters used, UNKNOWN Ignored: 0, FLOW Ignored: 0, YAF STATS Ignored: 0, TOMBSTONE Ignored: 0, DNS DEDUP Ignored: 0, SSL DEDUP Ignored: 0, GENERAL DEDUP Ignored: 0, DNS RR Ignored: 0, TMD OR IE Ignored: 0, DPI Ignored: 0, UNKNOWN DATA Ignored: 0, UNKNOWN OPTIONS Ignored: 0, UNKNOWN Generated: 0, FLOW Generated: 0, YAF STATS Generated: 0, TOMBSTONE Generated: 0, DNS DEDUP Generated: 0, SSL DEDUP Generated: 0, GENERAL DEDUP Generated: 0, DNS RR Generated: 0, TMD OR IE Generated: 0, DPI Generated: 0, UNKNOWN DATA Generated: 0, UNKNOWN OPTIONS Generated: 0, UNKNOWN Forwarded: 0, FLOW Forwarded: 3416, YAF STATS Forwarded: 1, TOMBSTONE Forwarded: 1, DNS DEDUP Forwarded: 0, SSL DEDUP Forwarded: 0, GENERAL DEDUP Forwarded: 0, DNS RR Forwarded: 0, TMD OR IE Forwarded: 0, DPI Forwarded: 0, UNKNOWN DATA Forwarded: 0, UNKNOWN OPTIONS Forwarded: 0, AppLabel 0 Records: 1401, AppLabel 53 Records: 601, AppLabel 80 Records: 790, AppLabel 123 Records: 1, AppLabel 137 Records: 42, AppLabel 138 Records: 28, AppLabel 161 Records: 4, AppLabel 443 Records: 537, AppLabel 51443 Records: 12,
[2023-06-30 06:16:23] Exporter Stats: E1-ACTIVE-SINGLE FILE: Total Records Written: 3418, Files Written: 1, Bytes Written: 614700, Restarts: 0, No filters used, UNKNOWN Ignored: 0, FLOW Ignored: 0, YAF STATS Ignored: 0, TOMBSTONE Ignored: 0, DNS DEDUP Ignored: 0, SSL DEDUP Ignored: 0, GENERAL DEDUP Ignored: 0, DNS RR Ignored: 0, TMD OR IE Ignored: 0, DPI Ignored: 0, UNKNOWN DATA Ignored: 0, UNKNOWN OPTIONS Ignored: 0, UNKNOWN Generated: 0, FLOW Generated: 0, YAF STATS Generated: 0, TOMBSTONE Generated: 0, DNS DEDUP Generated: 0, SSL DEDUP Generated: 0, GENERAL DEDUP Generated: 0, DNS RR Generated: 0, TMD OR IE Generated: 0, DPI Generated: 0, UNKNOWN DATA Generated: 0, UNKNOWN OPTIONS Generated: 0, UNKNOWN Forwarded: 0, FLOW Forwarded: 3416, YAF STATS Forwarded: 1, TOMBSTONE Forwarded: 1, DNS DEDUP Forwarded: 0, SSL DEDUP Forwarded: 0, GENERAL DEDUP Forwarded: 0, DNS RR Forwarded: 0, TMD OR IE Forwarded: 0, DPI Forwarded: 0, UNKNOWN DATA Forwarded: 0, UNKNOWN OPTIONS Forwarded: 0, AppLabel 0 Records: 1401, AppLabel 53 Records: 601, AppLabel 80 Records: 790, AppLabel 123 Records: 1, AppLabel 137 Records: 42, AppLabel 138 Records: 28, AppLabel 161 Records: 4, AppLabel 443 Records: 537, AppLabel 51443 Records: 12,
[2023-06-30 06:16:23] E1: Closing File tmp.ipfix
[2023-06-30 06:16:23] super_mediator Terminating
[root@12c4bd60ff5f testdata]#
通过--verbose参数打印处理过程,可以看到即使是在ipfix模式下,super-mediator也处理了 dns、ssl之类的dpi信息,并且在最后统计信息的处理中,也看到了多种类型的AppLabel。所以,super-mediator大概率应该是没有问题的——也是就说数据是没有问题的。那么,问题只能是出在我们对mothra的使用方式上。
三、Mothra的使用
1. 载入字段选择
通过学习mothra的API文档Mothra 1.6.0 - org.cert.netsa.mothra.datasources.ipfix,发现丢失DPI数据的原因可能是由于我们使用了默认的数据载入方式: 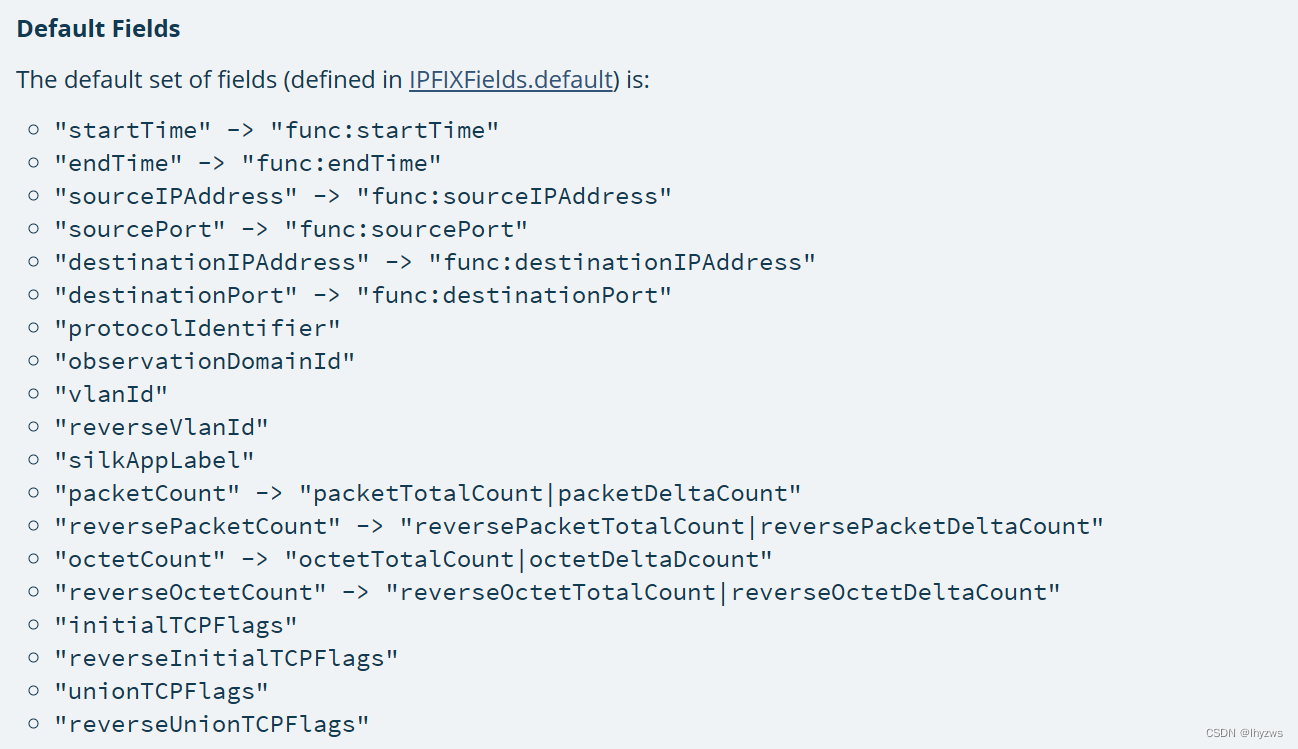
也就是说,采用spark.read.ipfix(your_file_path)载入的数据,由于没有使用fields方法指定载入数据的范围,可能只是Default Fields。实际上,spark.read是sparksession类的read方法,其调用了mothra提供的数据源CERTDataFrameReader提供的ipfix方法。该数据源还提供了fields方法用于指定读取数据的范围。
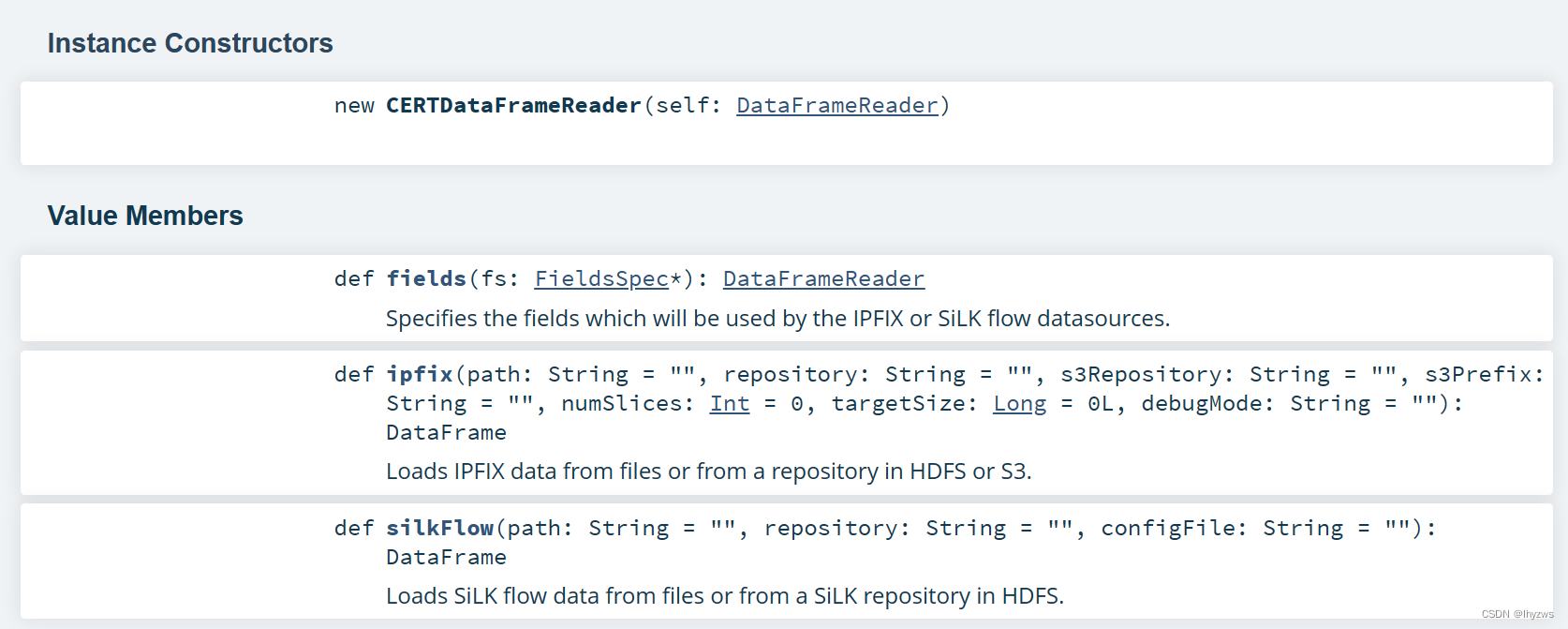
fields方法使用FieldsSpec类型来指定读取数据范围,而IPFIXFields.default正是这样一个类型:
同理,IPFIXFields也定义了诸如IPFIXFields:everything这样的fieldsSpec:

所以,只要以IPFIXFields.everything指定fields,应该可以将所有信息导入到spark中:
scala> import org.cert.netsa.mothra.datasources._
import org.cert.netsa.mothra.datasources._
scala> import org.cert.netsa.mothra.datasources.ipfix.IPFIXFields
import org.cert.netsa.mothra.datasources.ipfix.IPFIXFields
scala> val all = spark.read.fields(IPFIXFields.everything).ipfix("f:/tmp/test2.ipfix")
all: org.apache.spark.sql.DataFrame = [startTime: timestamp, endTime: timestamp ... 184 more fields]
scala> all.count
res45: Long = 3418
scala> all.show(1,0,true)
-RECORD 0-----------------------------------------------------------
startTime | 2022-11-15 10:34:36.433
endTime | 2022-11-15 10:34:36.485
sourceIPAddress | 47.110.20.149
sourcePort | 443
destinationIPAddress | 192.168.182.76
destinationPort | 62116
protocolIdentifier | 6
observationDomainId | 0
vlanId | 0
reverseVlanId | 0
silkAppLabel | 0
packetCount | 3
reversePacketCount | 4
octetCount | 674
reverseOctetCount | 253
initialTCPFlags | 24
reverseInitialTCPFlags | 24
unionTCPFlags | 25
reverseUnionTCPFlags | 21
dnp3RecordList | []
dnsRecordList | []
………………
reverseFlowAttributes | 0
flowEndReason | 3
reverseFlowDeltaMilliseconds | 1
ipClassOfService | 20
………………
reverseMaxPacketSize | null
reverseStandardDeviationPayloadLength | null
tcpSequenceNumber | 3558855353
reverseTcpSequenceNumber | 341543645
ndpiL7Protocol | null
ndpiL7SubProtocol | null
mplsTopLabelStackSection | null
mplsLabelStackSection2 | null
mplsLabelStackSection3 | null
yafFlowKeyHash | 4001181757
only showing top 1 row可以看到,明显比使用default时的数据是要多了好多的。
2. 提取特定的DPI数据
下一步的问题,是证明mothra是否真的将数据读入了进来,还是说虽然字段多了但其实是张空表。
(1)统计AppLabel
scala> all.groupBy('silkAppLabel).count.show
+------------+-----+
|silkAppLabel|count|
+------------+-----+
| 137| 42|
| 53| 601|
| null| 2|
| 51443| 12|
| 161| 4|
| 443| 537|
| 80| 790|
| 123| 1|
| 0| 1401|
| 138| 28|
+------------+-----+通过统计AppLabel,我们能够直到,至少在ipfix中存在601条dns信息、537条tls信息和790条http信息,这个是我们在执行yaf时设置过需要提取DPI信息的,接下来需要搞清楚的是这些信息有没有存下来。
(2)提取DNS记录
根据everthing的schema,我们知道存储dns信息的列名是dnsRecordList,因此可以使用filter appLabel的方式进行过滤后提取。
scala> all.printSchema
root
|-- startTime: timestamp (nullable = true)
|-- endTime: timestamp (nullable = true)
|-- sourceIPAddress: string (nullable = true)
|-- sourcePort: integer (nullable = true)
…………………………
|-- dnsRecordList: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- dnsName: string (nullable = true)
| | |-- dnsTTL: long (nullable = true)
| | |-- dnsRRType: integer (nullable = true)
| | |-- dnsQueryResponse: integer (nullable = true)
| | |-- dnsAuthoritative: integer (nullable = true)
| | |-- dnsResponseCode: integer (nullable = true)
| | |-- dnsSection: integer (nullable = true)
| | |-- dnsId: integer (nullable = true)
| | |-- dnsA: array (nullable = true)
| | | |-- element: string (containsNull = true)
| | |-- dnsAAAA: array (nullable = true)
| | | |-- element: string (containsNull = true)
| | |-- dnsCNAME: array (nullable = true)
| | | |-- element: string (containsNull = true)
| | |-- dnsMX: array (nullable = true)
| | | |-- element: struct (containsNull = true)
| | | | |-- exchange: string (nullable = true)
| | | | |-- preference: integer (nullable = true)
| | |-- dnsNS: array (nullable = true)
| | | |-- element: string (containsNull = true)
| | |-- dnsPTR: array (nullable = true)
| | | |-- element: string (containsNull = true)
| | |-- dnsTXT: array (nullable = true)
| | | |-- element: string (containsNull = true)
| | |-- dnsSOA: array (nullable = true)
| | | |-- element: struct (containsNull = true)
| | | | |-- mname: string (nullable = true)
| | | | |-- rname: string (nullable = true)
| | | | |-- serial: long (nullable = true)
| | | | |-- refresh: long (nullable = true)
| | | | |-- retry: long (nullable = true)
| | | | |-- expire: long (nullable = true)
| | | | |-- minimum: long (nullable = true)
| | |-- dnsSRV: array (nullable = true)
| | | |-- element: struct (containsNull = true)
| | | | |-- target: string (nullable = true)
| | | | |-- priority: integer (nullable = true)
| | | | |-- weight: integer (nullable = true)
| | | | |-- port: integer (nullable = true)
|-- enipDataList: array (nullable = true)
…………………………
scala> val dns = all.filter("silkAppLabel='53'").select('dnsRecordList)
dns: org.apache.spark.sql.DataFrame = [dnsRecordList: array<struct<dnsName:string,dnsTTL:bigint,dnsRRType:int,dnsQueryResponse:int,dnsAuthoritative:int,dnsResponseCode:int,dnsSection:int,dnsId:int,dnsA:array<string>,dnsAAAA:array<string>,dnsCNAME:array<string>,dnsMX:array<struct<exchange:string,preference:int>>,dnsNS:array<string>,dnsPTR:array<string>,dnsTXT:array<string>,dnsSOA:array<struct<mname:string,rname:string,serial:bigint,refresh:bigint,retry:bigint,expire:bigint,minimum:bigint>>,dnsSRV:array<struct<target:string,priority:int,weight:int,port:int>>>>]
scala> dns.count
res49: Long = 601打印一下试试
scala> dns.show
+--------------------+
| dnsRecordList|
+--------------------+
|[{pagead2.googles...|
|[{SMS_SLP., 0, 1,...|
|[{SMS_SLP., 0, 1,...|
…… …… ……
+--------------------+
only showing top 20 rows
scala> dns.show(1,0,true)
-RECORD 0------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
dnsRecordList | [{pagead2.googlesyndication.com., 0, 1, 0, 0, 0, 0, 37404, [], [], [], [], [], [], [], [], []}, {pagead2.googlesyndication.com., 254, 1, 1, 0, 0, 1, 37404, [180.163.150.166], [], [], [], [], [], [], [], []}]
only showing top 1 row可见Dns数据确实是读进来了,下一步就是怎么把它展开以方便分析了。
四、操作复杂的spark类型
上文中可以看到,经由ipfix读进来的数据其结构是比较复杂的,包括了Array和Struct等scala类型的嵌套,这些类型难以被简单地转成rdd进行处理,需要掌握一些展平数据的方法才能快乐的使用。
例如,上文我们已经打印了dnsRecordList的schema结构,这里还可以看看http的主要IE的schema结构:
scala> val http = all.filter("silkAppLabel='80'").select('httpHostList,
| 'httpGetList,
| 'httpResponseList,
| 'httpViaList,
| 'httpContentTypeList,
| 'httpContentLengthList)
http: org.apache.spark.sql.DataFrame = [httpHostList: array<string>, httpGetList: array<string> ... 4 more fields]
scala> http.count
res2: Long = 790
scala> http.show(1)
+--------------------+-----------+----------------+-----------+--------------------+---------------------+
| httpHostList|httpGetList|httpResponseList|httpViaList| httpContentTypeList|httpContentLengthList|
+--------------------+-----------+----------------+-----------+--------------------+---------------------+
|[pr.x.hub.sandai....| [POST /]| [200 OK]| []|[application/octe...| [192, 36]|
+--------------------+-----------+----------------+-----------+--------------------+---------------------+
only showing top 1 row
scala> http.printSchema
root
|-- httpHostList: array (nullable = true)
| |-- element: string (containsNull = true)
|-- httpGetList: array (nullable = true)
| |-- element: string (containsNull = true)
|-- httpResponseList: array (nullable = true)
| |-- element: string (containsNull = true)
|-- httpViaList: array (nullable = true)
| |-- element: string (containsNull = true)
|-- httpContentTypeList: array (nullable = true)
| |-- element: string (containsNull = true)
|-- httpContentLengthList: array (nullable = true)
| |-- element: string (containsNull = true)1.纵向打开
纵向打开是比较常见的打开方式,就是当一行数据中存在嵌套时,将数据展开成多行。这在dns记录中比较常见,比如在一条dns应答中得到了多个options结果,为了分析方便起见,需要将options结果展开为多行,一行一个,而且每行都需要保持dns应答中的相关信息。所以纵向打开也会显著增加数据的冗余量。
(1)explode方法
explode函数是在Spark 3.4.1 ScalaDoc - org.apache.spark.sql.functions中定义的,官方的说法,是从给定的array/map列创建新的数据行。

使用explode,如果被炸对象是空值,会导致整行数据被删掉。所以,如果还希望保留被炸对象为空值的数据行,可以使用explode_outer方法。
(2)单个array打开
以dnsRecordList为例。 打印出第一行,大概能够猜出来,dnsRecordList是一个包含struct类型对象的array数组,这个array实际就是以这个struct为条目包装的dns查询应答,一条一个struct。
scala> dns.show(1,0,true)
-RECORD 0------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
dnsRecordList | [{pagead2.googlesyndication.com., 0, 1, 0, 0, 0, 0, 37404, [], [], [], [], [], [], [], [], []}, {pagead2.googlesyndication.com., 254, 1, 1, 0, 0, 1, 37404, [180.163.150.166], [], [], [], [], [], [], [], []}]
only showing top 1 row由上面给出的官方说明,explode输入一个列,输出也是列,所以可以用select来选择explode炸出的列。 炸成多行后是这个样子:
scala> dns.select(explode('dnsRecordList).as("dnsRecord")).show
+--------------------+
| dnsRecord|
+--------------------+
|{pagead2.googlesy...|
|{pagead2.googlesy...|
|{SMS_SLP., 0, 1, ...|
|{SMS_SLP., 0, 1, ...|
…… …… …… ……
+--------------------+
only showing top 20 rows可以看到,那个代表array的中括号没了,中括号中如果有多个struct的话,就会被炸成多行的形式。
(3)多个array打开
多个array打开和单个是一样的,但要注意空值的处理,所以比较合适的是使用explode_outer;另外一个麻烦的问题,是在一个select语句中不能使用多次explode,所以需要使用withColumn来配合,代码上感觉冗余,不太舒服。
scala> http.withColumn("Host",explode_outer('httpHostList)).
| | withColumn("Get",explode_outer('httpGetList)).
| | withColumn("Response",explode_outer('httpResponseList)).
| | withColumn("ContentType",explode_outer('httpContentTypeList)).
| | withColumn("ContentLen",explode_outer('httpContentLengthList)).
| | select('Host,'Get,'Response,'ContentType,'ContentLen).show
+--------------------+--------------------+----------------+--------------------+----------+
| Host| Get| Response| ContentType|ContentLen|
+--------------------+--------------------+----------------+--------------------+----------+
|pr.x.hub.sandai.n...| POST /| 200 OK|application/octet...| 192|
|pr.x.hub.sandai.n...| POST /| 200 OK|application/octet...| 36|
|pr.x.hub.sandai.n...| POST /| 200 OK|application/octet...| 192|
|pr.x.hub.sandai.n...| POST /| 200 OK|application/octet...| 36|
|pr.x.hub.sandai.n...| POST /| 200 OK|application/octet...| 192|
|pr.x.hub.sandai.n...| POST /| 200 OK|application/octet...| 36|
|pr.x.hub.sandai.n...| POST /| 200 OK|application/octet...| 192|
|pr.x.hub.sandai.n...| POST /| 200 OK|application/octet...| 36|
…………………………
+--------------------+--------------------+----------------+--------------------+----------+
only showing top 20 rows炸开的结果,可以明显感觉到数据的冗余量上来了。对比一下原始的数据:
scala> http.select('httpHostList,'httpGetList,'httpResponseList,'httpContentTypeList,'httpContentLengthList).show
+--------------------+--------------------+--------------------+--------------------+---------------------+
| httpHostList| httpGetList| httpResponseList| httpContentTypeList|httpContentLengthList|
+--------------------+--------------------+--------------------+--------------------+---------------------+
|[pr.x.hub.sandai....| [POST /]| [200 OK]|[application/octe...| [192, 36]|
|[pr.x.hub.sandai....| [POST /]| [200 OK]|[application/octe...| [192, 36]|对比一下原始的数据,可以看到这主要是因为Contentlength被炸开造成的;所以,观察数据的时候,谨慎选择炸开的列还是很有必要的。
2. 横向打开
横向打开,就是将复杂数据类型打开成多列。需要注意到对于表格来说,行数是可以随意增长的,这也是纵向打开相对容易的原因,只要接受数据冗余就好了;但是列数,就不是能够随意打开的了,毕竟表头不能随着数据动态增长——那就太自由了。所以,根据数据类型的不同,横向展开的方式也会不同。
(1)Struct类型横向打开
如果数据类型是Struct,也就暗示着实际复杂类型包含的子要素的个数是恒定的,相对来说,展成多列也就容易接受。
比如dnsRecordList里面的这个struct,通过printSchema我们已经知道其数据结构,包含dnsName、dnsTTL等下级元素。只需要使用select(“structname.*”)就可以解决问题。
scala> dns.select(explode('dnsRecordList).as("RecordList")).select("RecordList.*").show
+--------------------+------+---------+----------------+----------------+---------------+----------+-----+-----------------+--------------------+--------+-----+-----+------+------+--------------------+------+
| dnsName|dnsTTL|dnsRRType|dnsQueryResponse|dnsAuthoritative|dnsResponseCode|dnsSection|dnsId| dnsA| dnsAAAA|dnsCNAME|dnsMX|dnsNS|dnsPTR|dnsTXT| dnsSOA|dnsSRV|
+--------------------+------+---------+----------------+----------------+---------------+----------+-----+-----------------+--------------------+--------+-----+-----+------+------+--------------------+------+
|pagead2.googlesyn...| 0| 1| 0| 0| 0| 0|37404| []| []| []| []| []| []| []| []| []|
|pagead2.googlesyn...| 254| 1| 1| 0| 0| 1|37404|[180.163.150.166]| []| []| []| []| []| []| []| []|
| SMS_SLP.| 0| 1| 0| 0| 0| 0|14041| []| []| []| []| []| []| []| []| []|
| SMS_SLP.| 0| 1| 0| 0| 0| 0|14041| []| []| []| []| []| []| []| []| []|如果只需要查看有限几个下级元素,也可以直接指定元素进行选择:
scala> dns.select(explode('dnsRecordList).as("RecordList")).select("RecordList.dnsName","RecordList.dnsA").show
+--------------------+-----------------+
| dnsName| dnsA|
+--------------------+-----------------+
|pagead2.googlesyn...| []|
|pagead2.googlesyn...|[180.163.150.166]|
| SMS_SLP.| []|(2)Array类型横向展开
如果数据类型是Array,就不携带任何下级元素的表头信息了,而且还可能因为数据带来不同array大小,这种展开就比较麻烦了:
scala> import org.apache.spark.sql.functions.size
import org.apache.spark.sql.functions.size
scala> http.select('httpHostList).withColumn("listSize",size('httpHostList)).groupBy('listSize).count.sort('listSize.desc).show
+--------+-----+
|listSize|count|
+--------+-----+
| 3| 2|
| 2| 1|
| 1| 106|
| 0| 681|
+--------+-----+过滤一下看看,确实有host为3的情况:
scala> val tmp = http.select('httpHostList).withColumn("size",size('httpHostList)).filter("size='3'")
tmp: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [httpHostList: array<string>, size: int]
scala> tmp.show
+--------------------+----+
| httpHostList|size|
+--------------------+----+
|[ctldl.windowsupd...| 3|
|[1d.tlu.dl.delive...| 3|
+--------------------+----+对于array类型,需要在dataframe中选择的话,直接使用“(索引)”操作符就行。所以,比较笨的方法,就是手动展开:
scala> http.select('httpHostList(0).as("host0"),'httpHostList(1).as("host1"),'httpHostList(2).as("host2")).show
+--------------------+--------------------+--------------------+
| host0| host1| host2|
+--------------------+--------------------+--------------------+
|pr.x.hub.sandai.n...| null| null|
|pr.x.hub.sandai.n...| null| null|
|extshort.weixin.q...| null| null|
| 42.187.182.123| null| null|
|ctldl.windowsupda...|ctldl.windowsupda...|ctldl.windowsupda...|
| x1.c.lencr.org| null| null|
……………………
自动一点,可以考虑采取如下的写法,其中“:_*”表示将对应的参数序列化后使用:
scala> http.select( $"httpGetList" +: (0 until 3).map(i => 'httpHostList(i).alias(s"host$i")):_* ).show
+--------------------+--------------------+--------------------+--------------------+
| httpGetList| host0| host1| host2|
+--------------------+--------------------+--------------------+--------------------+
| [POST /]|pr.x.hub.sandai.n...| null| null|
| [POST /]|pr.x.hub.sandai.n...| null| null|
|[POST /mmtls/0000...|extshort.weixin.q...| null| null|
|[POST /mmtls/0000...| 42.187.182.123| null| null|
|[GET /msdownload/...|ctldl.windowsupda...|ctldl.windowsupda...|ctldl.windowsupda...|
………………
+--------------------+--------------------+--------------------+--------------------+
only showing top 20 rowsPS
最后,推荐几篇不错的文章,帮助我解决了scala小白过程中遭遇的问题:
1. 数组列转多列:
Spark DataFrame数组列转多列 - 知乎 (zhihu.com)
2. 操作复杂的spark类型:
Spark之处理复杂数据类型(Struct、Array、Map、JSON字符串等)_spark string 转成json array_大数据翻身的博客-CSDN博客
3. explode的本质是什么:
Spark Sql中的Map和flatMap_spark flatmap_数仓白菜白的博客-CSDN博客
4. 带表达式的select:
Spark---DataFrame学习(二)——select、selectExpr函数_stan1111的博客-CSDN博客
5. 奇怪的Scala操作符
scala中:_*的使用和scala中的:: , +:, :+, :::, +++ 等操作_scala中*_爱学习的孙同学的博客-CSDN博客