介绍
在现实世界中,基于学习的异常检测任务极具挑战性,这主要是因为此类事件很少发生。由于这些事件的无约束性质,这一挑战进一步加剧。因此,获取足够的异常示例是相当麻烦的,而人们可以安全地假设,将永远不会收集到一个详尽的集合,特别是训练完全监督的模型所需的集合。为了使学习变得容易理解,通常将异常归因于与正常数据的显著偏差。因此,异常检测的一种流行方法是训练一类分类器,该分类器仅使用正常训练示例来学习主要数据表示。
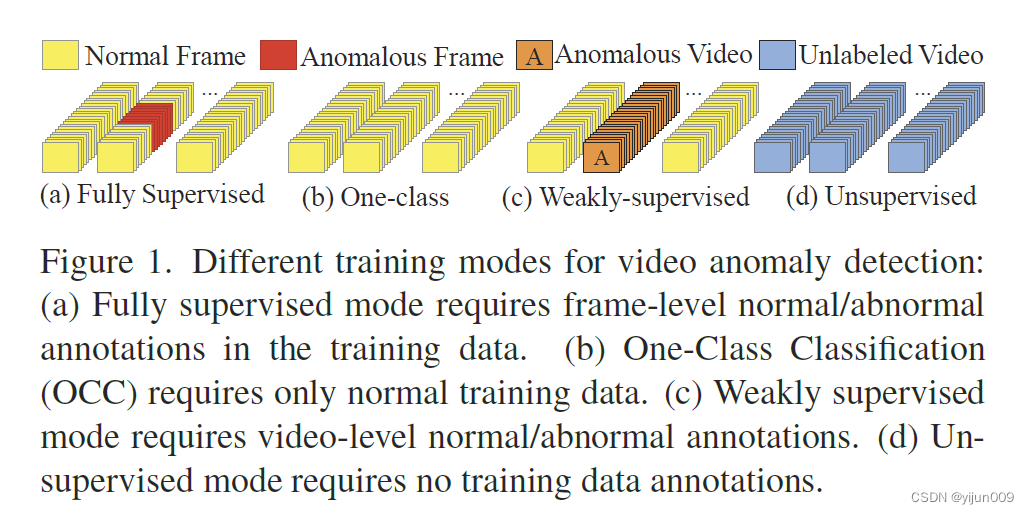
单类分类(OCC)方法的一个明显缺点是正常训练数据的可用性有限,无法捕获所有正常变化[9]。
此外,OCC方法通常不适用于视频监控中经常出现的具有多种类别和广泛动态情况的复杂问题。
在这种情况下,看不见的正常活动可能会显著偏离学习到的正常表示,从而被预测为异常,从而导致误报[14,67]。
最近,弱监督异常检测方法获得了显著的普及[24,26,34,46,56,63],通过使用视频级别标签[50,65,67,69,74]降低了获得手动细粒度注释的成本。
具体而言,如果视频的某些内容异常,则将其标记为异常;如果视频的所有内容正常,则将视频标记为正常,需要手动检查完整视频。尽管这样的注释相对经济高效,但在许多实际应用中仍然不切实际。有大量的视频数据,特别是原始镜头,如果不产生注释成本,可以用于异常检测训练。不幸的是,据我们所知,在利用未标记的训练数据进行视频异常检测方面几乎没有任何值得注意的尝试。
在这项工作中,我们探索了视频异常检测的无监督模式,这肯定比完全、弱或一类监督更具挑战性(图1)。然而,由于最小的假设,它也更有价值,因此将鼓励开发新的更实用的算法。注意,文献中的术语“无监督”通常指假设所有正常训练数据的OCC方法[11,37,64,66]。
然而,它重新定义了部分监督的整体学习问题[19]。在接近视频中的无监督异常检测时,我们利用了一个简单的事实,即视频与静止图像相比信息丰富,并且异常比正常发生的频率低[8,29,51,67],并试图以结构化的方式利用此类领域知识。
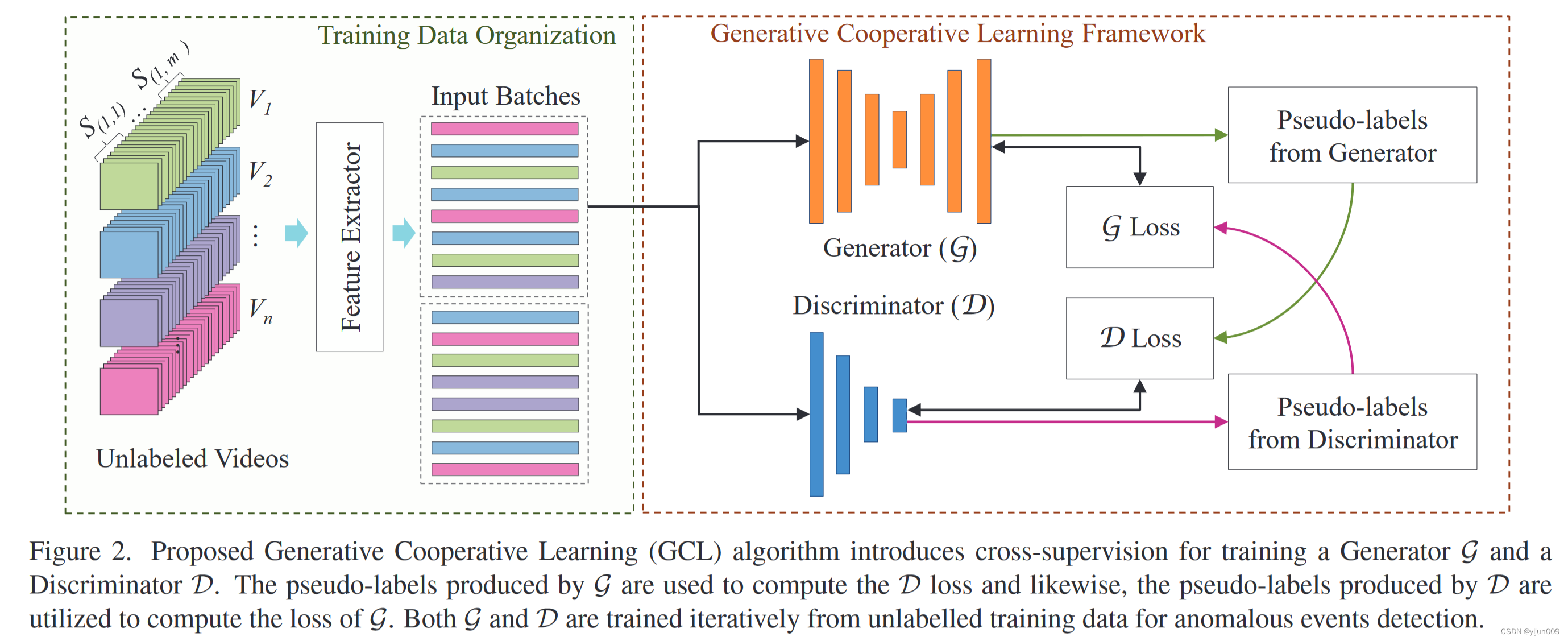
为此,我们提出了一种生成合作学习(GCL)方法,该方法将未标记视频作为输入,并学习预测帧级异常分数预测作为输出。
生成器不仅重建了大量可用的正常表示,还通过使用新的负学习(NL)方法扭曲了可能的高置信度异常表示。相反,鉴别器估计实例异常的概率。对于无监督异常检测,我们从生成器中创建伪标签,并使用这些伪标签来训练鉴别器。在接下来的步骤中,我们从经过训练的鉴别器版本创建伪标签,然后使用这些标签来改进生成器。整个系统以交替的方式进行训练,在每一次迭代中,生成器和鉴别器都通过相互合作得到改进。
贡献。我们提出了一种异常检测方法,能够在复杂的监视场景中定位异常事件,而不需要标记的训练数据。据我们所知,我们的方法是首次在完全无监督模式下处理监控视频异常检测的严格尝试。提出了一种新的生成式合作学习(GCL)框架,该框架包括生成器、鉴别器和交叉监督。通过使用新的负学习方法,生成器网络被迫不重构异常。在两个大型复杂异常事件检测数据集(UCF犯罪和上海科技)上的大量实验表明,我们的方法比基线和几种现有的无监督和OCC方法提供了明显的增益。
相关工作
异常检测是图像[7,16,39]和视频[49,50,64,67,69]领域中广泛研究的问题。我们回顾了视频异常检测的不同监督模式和相互学习策略。
异常检测作为一类分类(OCC)。 OCC方法在广泛的异常检测问题中找到了自己的方法,包括医疗诊断[58]、网络安全[11]、监控安全系统[20、29、32、64]和工业检查[5]。其中一些方法使用手工制作的特征[3,31,38,55,71],而其他方法使用使用预训练模型提取的深度特征[42,47]。随着生成模型的出现,许多方法方法提出了此类网络的变体,以学习正常数据表示[12,35,36,43–45,61,62,64]。OCC方法发现,避免异常测试输入的well-reconstruction具有挑战性。该问题归因于这样一个事实,即由于OCC方法在训练时仅使用正常类数据,因此可能会实现无效的分类器边界,该边界在封闭正常数据的同时排除异常[64]。为了解决这一限制,一些研究人员最近提出了伪监督方法,其中使用正常训练数据生成伪异常实例[1,64]。
无监督异常检测。 使用未标记训练数据的异常检测方法在文献中相当稀少。根据图1所示的命名法,文献中大多数无监督方法实际上属于OCC类别。例如,MVTecAD[5]基准确保训练数据仅正常,因此其评估协议为OCC,继承该假设的方法本质上也是一类分类器[6,12]。与这些算法相比,我们提出的GCL方法能够从未标记的训练数据中学习,而不假设任何正常性。视频形式的训练数据符合关于异常检测的几个重要属性,例如,异常比正常事件更不频繁,并且事件通常在时间上是一致的。我们从这些线索中获得动机,以完全无监督的方式进行训练。
师生网络。 我们提出的GCL与师生(TS)知识提炼框架有一些相似之处[18]。GCL不同于TS框架,主要是因为它的目的不是知识提炼。此外,我们的生成器生成有噪声的标签,而我们的鉴别器对噪声相对鲁棒,它会清除这些标签,这在TS框架中不是这样的。
相互学习(ML)。GCL框架也与ML算法有相似之处[73]。然而,GCL的两个组成部分学习不同类型的信息,并且与ML算法所使用的监督学习相比,通过交叉监督进行训练。此外,在GCL中,每个网络的输出都经过阈值处理以产生伪标签。在ML中,队列学习匹配每个成员的分布,而在GCL中,每个成员尝试从其他成员生成的伪标签中学习。在无监督模式下,使用未标记的训练数据对队列进行相互学习尚未探索。
对偶学习。 这也是一种相关的方法,其中两种语言翻译模型相互交互教学[15]。然而,外部监督是使用预先培训的无条件语言专家模型提供的,该模型检查翻译质量。这样,不同的模型具有不同的学习任务,而在我们提出的GCL方法中,学习任务是相同的。合作学习的另一个变体[4]先前已被提出为跨不同领域的同一任务联合学习多个模型。例如,通过在RGB图像上训练一个模型和在深度图像上训练另一个模型来制定对象识别,然后这些模型传达域不变的对象属性。然而,在我们的GCL方法中,两个模型在同一领域中处理相同的任务。
方法
我们提出的用于异常检测的生成合作学习方法(GCL)包括特征提取器、生成器网络、鉴别器网络和两个伪标签生成器。图2显示了总体架构。接下来将讨论每个组件。
3.1 Training Data Organization
为了最小化计算复杂性并减少GCL的训练时间,类似于现有的SOTA[50,52,65,67,69,74],我们利用深度特征提取器将视频数据转换为紧凑的特征。所有输入视频被安排为片段,然后提取其特征。此外,这些特征按批次随机排列。在每次迭代中,使用随机选择的批次来训练GCL模型(图2)。



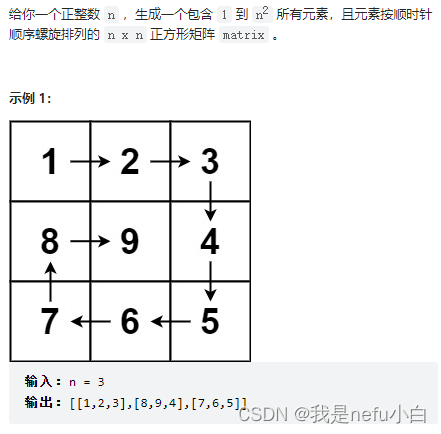




![Docker[6]-.DockerCompose](https://img-blog.csdnimg.cn/df129d08bd32403dbd77f9dfba3f872c.png)