如果你会任意一门语言的stream流,没道理不会大数据开发。
俗话说男追女隔座山,女追男隔层纱。 如果说零基础学大数据,感觉前面是一座山,那么只要你会java或者任意一门语言的stream流,那大数据就只隔了一层纱。
本文以java stream流计算为例,讲解一些基础的spark操作。另一个流行的大数据框架flink同理。
原来 Lamda 表达式是这样写的
巧用Stream优化老代码
准备工作
测试数据,以下列分别表示姓名,年龄,部门,职位。
张三,20,研发部,普通员工
李四,31,研发部,普通员工
李丽,36,财务部,普通员工
张伟,38,研发部,经理
杜航,25,人事部,普通员工
周歌,28,研发部,普通员工
创建一个Employee类。
@Getter
@Setter
@AllArgsConstructor
@NoArgsConstructor
@ToString
static
class Employee implements Serializable {
private String name;
private Integer age;
private String department;
private String level;
}
版本: jdk:1.8 spark:3.2.0 scala:2.12.15。
上面的 scala 版本只是spark框架本身需要依赖到 scala。
因为 scala 确实是比较小众的语言,本文还是使用 java 演示 spark 代码。
map类
java stream map
map 表示一对一操作。将上游数据的一行数据进行任意操作,最终得到操作后的一条数据。 这种思想,在 java 和 spark,flink 都是一致的。
我们先用 java stream 演示读取文件,再使用map操作将每行数据映射为Employee对象。
List<String> list = FileUtils.readLines(new File("f:/test.txt"), "utf-8");
List<Employee> employeeList = list.stream().map(word -> {
List<String> words = Arrays.stream(word.split(",")).collect(Collectors.toList());
Employee employee = new Employee(words.get(0), Integer.parseInt(words.get(1)), words.get(2), words.get(3));
return employee;
}).collect(Collectors.toList());
employeeList.forEach(System.out::println);
转换后的数据:
JavaStreamDemo.Employee(name=张三, age=20, department=研发部, level=普通员工)
JavaStreamDemo.Employee(name=李四, age=31, department=研发部, level=普通员工)
JavaStreamDemo.Employee(name=李丽, age=36, department=财务部, level=普通员工)
JavaStreamDemo.Employee(name=张伟, age=38, department=研发部, level=经理)
JavaStreamDemo.Employee(name=杜航, age=25, department=人事部, level=普通员工)
JavaStreamDemo.Employee(name=周歌, age=28, department=研发部, level=普通员工)
spark map
首先得到一个 SparkSession 对象,读取文件,得到一个 DataSet 弹性数据集对象。
SparkSession session = SparkSession.builder().master("local[*]").getOrCreate();
Dataset<Row> reader = session.read().text("F:/test.txt");
reader.show();
这里的 show() 就是打印输出当前数据集,它是一个 action 类的算子。 得到结果:
+-----------------------+
| value|
+-----------------------+
|张三,20,研发部,普通员工|
|李四,31,研发部,普通员工|
|李丽,36,财务部,普通员工|
| 张伟,38,研发部,经理|
|杜航,25,人事部,普通员工|
|周歌,28,研发部,普通员工|
+-----------------------+
现在我们拿到了基础数据,我们使用map一对一操作,将一行行数据转换为Employee对象。 我们这里不使用lamda表达式,让大家看得更加清晰。
这里实现了MapFunction接口里的call方法,每次拿到一行数据,我们这里进行切分,再转换为对象。
-
需要特别指出的一点是,与后端WEB应用有一个统一异常处理不同的是,大数据应用,特别是流式计算,要保证7*24在线,需要对每个算子进行异常捕获。 因为你不知道上游数据清洗到底怎么样,很可能拿到一条脏数据,处理的时候抛出异常,如果没有捕获处理,那么整个应用就会挂掉。
-
spark的算子分为Transformation和Action两种类型。Transformation会开成一个DAG图,具有lazy延迟性,它只会从一个dataset(rdd/df)转换成另一个dataset(rdd/df),只有当遇到action类的算子才会真正执行。 我们今天会演示的算子都是Transformation类的算子。
典型的Action算子包括show,collect,save之类的。比如在本地进行show查看结果,或者完成运行后save到数据库,或者HDFS。
-
spark执行时分为driver和executor。但不是本文的重点,不会展开讲。 只需要注意driver端会将代码分发到各个分布式系统的节点executor上,它本身不会参与计算。一般来说,算子外部,如以下示例代码的a处会在driver端执行,b处算子内部会不同服务器上的executor端执行。 所以在算子外部定义的变量,在算子内部使用的时候要特别注意!! 不要想当然地以为都是一个main方法里写的代码,就一定会在同一个JVM里。
这里涉及到序列化的问题,同时它们分处不同的JVM,使用"=="比较的时候也可能会出问题!!
这是一个后端WEB开发转向大数据开发时,这个思想一定要转变过来。
简言之,后端WEB服务的分布式是我们自己实现的,大数据的分布式是框架天生帮我们实现的。
MapFunction
// a 算子外部,driver端
Dataset<Employee> employeeDataset = reader.map(new MapFunction<Row, Employee>() {
@Override
public Employee call(Row row) throws Exception {
// b 算子内部,executor端
Employee employee = null;
try {
// gson.fromJson(); 这里使用gson涉及到序列化问题
List<String> list = Arrays.stream(row.mkString().split(",")).collect(Collectors.toList());
employee = new Employee(list.get(0), Integer.parseInt(list.get(1)), list.get(2), list.get(3));
} catch (Exception exception) {
// 日志记录
// 流式计算中要做到7*24小时不间断,任意一条上流脏数据都可能导致失败,从而导致任务退出,所以这里要做好异常的抓取
exception.printStackTrace();
}
return employee;
}
}, Encoders.bean(Employee.class));
employeeDataset.show();
输出
+---+----------+--------+----+
|age|department| level|name|
+---+----------+--------+----+
| 20| 研发部|普通员工|张三|
| 31| 研发部|普通员工|李四|
| 36| 财务部|普通员工|李丽|
| 38| 研发部| 经理|张伟|
| 25| 人事部|普通员工|杜航|
| 28| 研发部|普通员工|周歌|
MapPartitionsFunction
spark中 map和mapPartitions有啥区别?
map 是 1 条 1 条处理数据。 mapPartitions 是一个分区一个分区处理数据。
后者一定比前者效率高吗?
不一定,看具体情况。
这里使用前面 map 一样的逻辑处理。可以看到在 call 方法里得到的是一个 Iterator 迭代器,是一批数据。
得到一批数据,然后再一对一映射为对象,再以 Iterator 的形式返回这批数据。
Dataset<Employee> employeeDataset2 = reader.mapPartitions(new MapPartitionsFunction<Row, Employee>() {
@Override
public Iterator<Employee> call(Iterator<Row> iterator) throws Exception {
List<Employee> employeeList = new ArrayList<>();
while (iterator.hasNext()){
Row row = iterator.next();
try {
List<String> list = Arrays.stream(row.mkString().split(",")).collect(Collectors.toList());
Employee employee = new Employee(list.get(0), Integer.parseInt(list.get(1)), list.get(2), list.get(3));
employeeList.add(employee);
} catch (Exception exception) {
// 日志记录
// 流式计算中要做到7*24小时不间断,任意一条上流脏数据都可能导致失败,从而导致任务退出,所以这里要做好异常的抓取
exception.printStackTrace();
}
}
return employeeList.iterator();
}
}, Encoders.bean(Employee.class));
employeeDataset2.show();
输出结果跟 map 一样,这里就不贴出来了。
flatMap类
map和flatMap有什么区别?
map是一对一,flatMap是一对多。 当然在java stream中,flatMap 叫法叫做扁平化。
这种思想,在java和spark,flink都是一致的。
java stream flatMap
以下代码将1条原始数据映射到2个对象上并返回。
List<Employee> employeeList2 = list.stream().flatMap(word -> {
List<String> words = Arrays.stream(word.split(",")).collect(Collectors.toList());
List<Employee> lists = new ArrayList<>();
Employee employee = new Employee(words.get(0), Integer.parseInt(words.get(1)), words.get(2), words.get(3));
lists.add(employee);
Employee employee2 = new Employee(words.get(0)+"_2", Integer.parseInt(words.get(1)), words.get(2), words.get(3));
lists.add(employee2);
return lists.stream();
}).collect(Collectors.toList());
employeeList2.forEach(System.out::println);
输出
JavaStreamDemo.Employee(name=张三, age=20, department=研发部, level=普通员工)
JavaStreamDemo.Employee(name=张三_2, age=20, department=研发部, level=普通员工)
JavaStreamDemo.Employee(name=李四, age=31, department=研发部, level=普通员工)
JavaStreamDemo.Employee(name=李四_2, age=31, department=研发部, level=普通员工)
JavaStreamDemo.Employee(name=李丽, age=36, department=财务部, level=普通员工)
JavaStreamDemo.Employee(name=李丽_2, age=36, department=财务部, level=普通员工)
JavaStreamDemo.Employee(name=张伟, age=38, department=研发部, level=经理)
JavaStreamDemo.Employee(name=张伟_2, age=38, department=研发部, level=经理)
JavaStreamDemo.Employee(name=杜航, age=25, department=人事部, level=普通员工)
JavaStreamDemo.Employee(name=杜航_2, age=25, department=人事部, level=普通员工)
JavaStreamDemo.Employee(name=周歌, age=28, department=研发部, level=普通员工)
JavaStreamDemo.Employee(name=周歌_2, age=28, department=研发部, level=普通员工)
spark flatMap
这里实现FlatMapFunction的call方法,一次拿到1条数据,然后返回值是Iterator,所以可以返回多条。
Dataset<Employee> employeeDatasetFlatmap = reader.flatMap(new FlatMapFunction<Row, Employee>() {
@Override
public Iterator<Employee> call(Row row) throws Exception {
List<Employee> employeeList = new ArrayList<>();
try {
List<String> list = Arrays.stream(row.mkString().split(",")).collect(Collectors.toList());
Employee employee = new Employee(list.get(0), Integer.parseInt(list.get(1)), list.get(2), list.get(3));
employeeList.add(employee);
Employee employee2 = new Employee(list.get(0)+"_2", Integer.parseInt(list.get(1)), list.get(2), list.get(3));
employeeList.add(employee2);
} catch (Exception exception) {
exception.printStackTrace();
}
return employeeList.iterator();
}
}, Encoders.bean(Employee.class));
employeeDatasetFlatmap.show();
输出
+---+----------+--------+------+
|age|department| level| name|
+---+----------+--------+------+
| 20| 研发部|普通员工| 张三|
| 20| 研发部|普通员工|张三_2|
| 31| 研发部|普通员工| 李四|
| 31| 研发部|普通员工|李四_2|
| 36| 财务部|普通员工| 李丽|
| 36| 财务部|普通员工|李丽_2|
| 38| 研发部| 经理| 张伟|
| 38| 研发部| 经理|张伟_2|
| 25| 人事部|普通员工| 杜航|
| 25| 人事部|普通员工|杜航_2|
| 28| 研发部|普通员工| 周歌|
| 28| 研发部|普通员工|周歌_2|
+---+----------+--------+------+
groupby类
与SQL类似,java stream流和spark一样,groupby对数据集进行分组并在此基础上可以进行聚合函数操作。也可以分组直接得到一组子数据集。
java stream groupBy
按部门分组统计部门人数:
Map<String, Long> map = employeeList.stream().collect(Collectors.groupingBy(Employee::getDepartment, Collectors.counting()));
System.out.println(map);
输出
{财务部=1, 人事部=1, 研发部=4}
spark groupBy
将映射为对象的数据集按部门分组,在此基础上统计部门员工数和平均年龄。
RelationalGroupedDataset datasetGroupBy = employeeDataset.groupBy("department");
// 统计每个部门有多少员工
datasetGroupBy.count().show();
/**
* 每个部门的平均年龄
*/
datasetGroupBy.avg("age").withColumnRenamed("avg(age)","avgAge").show();
输出分别为
+----------+-----+
|department|count|
+----------+-----+
| 财务部| 1|
| 人事部| 1|
| 研发部| 4|
+----------+-----+
+----------+------+
|department|avgAge|
+----------+------+
| 财务部| 36.0|
| 人事部| 25.0|
| 研发部| 29.25|
+----------+------+
spark groupByKey
spark 的groupBy和groupByKey的区别,前者在此基础上使用聚合函数得到一个聚合值,后者只是进行分组,不进行任何计算。
类似于java stream的:
Map<String, List<Employee>> map2 = employeeList.stream().collect(Collectors.groupingBy(Employee::getDepartment));
System.out.println(map2);
输出
{财务部=[JavaStreamDemo.Employee(name=李丽, age=36, department=财务部, level=普通员工)],
人事部=[JavaStreamDemo.Employee(name=杜航, age=25, department=人事部, level=普通员工)],
研发部=[JavaStreamDemo.Employee(name=张三, age=20, department=研发部, level=普通员工), JavaStreamDemo.Employee(name=李四, age=31, department=研发部, level=普通员工), JavaStreamDemo.Employee(name=张伟, age=38, department=研发部, level=经理), JavaStreamDemo.Employee(name=周歌, age=28, department=研发部, level=普通员工)]}
使用spark groupByKey。
先得到一个key-value的一对多的一个集合数据集。 这里的call()方法返回的是key,即分组的key。
KeyValueGroupedDataset keyValueGroupedDataset = employeeDataset.groupByKey(new MapFunction<Employee, String>() {
@Override
public String call(Employee employee) throws Exception {
// 返回分组的key,这里表示根据部门进行分组
return employee.getDepartment();
}
}, Encoders.STRING());
再在keyValueGroupedDataset 的基础上进行mapGroups,在call()方法里就可以拿到每个key的所有原始数据。
keyValueGroupedDataset.mapGroups(new MapGroupsFunction() {
@Override
public Object call(Object key, Iterator iterator) throws Exception {
System.out.println("key = " + key);
while (iterator.hasNext()){
System.out.println(iterator.next());
}
return iterator;
}
}, Encoders.bean(Iterator.class))
.show(); // 这里的show()没有意义,只是触发计算而已
输出
key = 人事部
SparkDemo.Employee(name=杜航, age=25, department=人事部, level=普通员工)
key = 研发部
SparkDemo.Employee(name=张三, age=20, department=研发部, level=普通员工)
SparkDemo.Employee(name=李四, age=31, department=研发部, level=普通员工)
SparkDemo.Employee(name=张伟, age=38, department=研发部, level=经理)
SparkDemo.Employee(name=周歌, age=28, department=研发部, level=普通员工)
key = 财务部
SparkDemo.Employee(name=李丽, age=36, department=财务部, level=普通员工)
reduce类
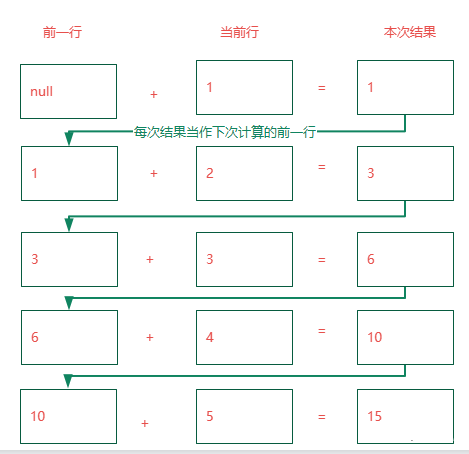
reduce的字面意思是:减少;减小;降低;缩小。 又叫归约。
它将数据集进行循环,让当前对象和前一对象两两进行计算,每次计算得到的结果作为下一次计算的前一对象,并最终得到一个对象。
假设有5个数据【1,2,3,4,5】,使用reduce进行求和计算,分别是
比如上面的测试数据集,我要计算各部门年龄总数。使用聚合函数得到的是一个int类型的数字。
java stream reduce
int age = employeeList.stream().mapToInt(e -> e.age).sum();
System.out.println(age);//178
使用 reduce 也可进行上面的计算
int age1 = employeeList.stream().mapToInt(e -> e.getAge()).reduce(0,(a,b) -> a+b);
System.out.println(age1);// 178
但是我将年龄求和,同时得到一个完整的对象呢?
JavaStreamDemo.Employee(name=周歌, age=178, department=研发部, level=普通员工)
可以使用 reduce 将数据集两两循环,将年龄相加,同时返回最后一个遍历的对象。
下面代码的 pre 代表前一个对象,current 代表当前对象。
/**
* pre 代表前一个对象
* current 代表当前对象
*/
Employee reduceEmployee = employeeList.stream().reduce(new Employee(), (pre,current) -> {
// 当第一次循环时前一个对象为null
if (pre.getAge() == null) {
current.setAge(current.getAge());
} else {
current.setAge(pre.getAge() + current.getAge());
}
return current;
});
System.out.println(reduceEmployee);
spark reduce
spark reduce的基本思想跟java stream是一样的。
直接看代码:
Employee datasetReduce = employeeDataset.reduce(new ReduceFunction<Employee>() {
@Override
public Employee call(Employee t1, Employee t2) throws Exception {
// 不同的版本看是否需要判断t1 == null
t2.setAge(t1.getAge() + t2.getAge());
return t2;
}
});
System.out.println(datasetReduce);
输出
SparkDemo.Employee(name=周歌, age=178, department=研发部, level=普通员工)
其它常见操作类
Employee employee = employeeDataset.filter("age > 30").limit(3).sort("age").first();
System.out.println(employee);
// SparkDemo.Employee(name=李四, age=31, department=研发部, level=普通员工)
同时可以将dataset注册成table,使用更为强大的SQL来进行各种强大的运算。 现在SQL是flink的一等公民,spark也不遑多让。 这里举一个非常简单的例子。
employeeDataset.registerTempTable("table");
session.sql("select * from table where age > 30 order by age desc limit 3").show();
输出
+---+----------+--------+----+
|age|department| level|name|
+---+----------+--------+----+
| 38| 研发部| 经理|张伟|
| 36| 财务部|普通员工|李丽|
| 31| 研发部|普通员工|李四|
+---+----------+--------+----+
employeeDataset.registerTempTable("table");
session.sql("select
concat_ws(',',collect_set(name)) as names, // group_concat
avg(age) as age,
department from table
where age > 30
group by department
order by age desc
limit 3").show();
输出
+---------+----+----------+
| names| age|department|
+---------+----+----------+
| 李丽|36.0| 财务部|
|张伟,李四|34.5| 研发部|
+---------+----+----------+
小结
本文依据java stream的相似性,介绍了spark里面一些常见的算子操作。
本文只是做一个非常简单的入门介绍。
如果感兴趣的话, 后端的同学可以尝试着操作一下,非常简单,本地不需要搭建环境,只要引入spark 的 maven依赖即可。
我把本文的所有代码全部贴在最后面。
java stream 源码:
点击查看代码
import lombok.*;
import org.apache.commons.io.FileUtils;
import java.io.File;
import java.io.IOException;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
public class JavaStreamDemo {
public static void main(String[] args) throws IOException {
/**
* 张三,20,研发部,普通员工
* 李四,31,研发部,普通员工
* 李丽,36,财务部,普通员工
* 张伟,38,研发部,经理
* 杜航,25,人事部,普通员工
* 周歌,28,研发部,普通员工
*/
List<String> list = FileUtils.readLines(new File("f:/test.txt"), "utf-8");
List<Employee> employeeList = list.stream().map(word -> {
List<String> words = Arrays.stream(word.split(",")).collect(Collectors.toList());
Employee employee = new Employee(words.get(0), Integer.parseInt(words.get(1)), words.get(2), words.get(3));
return employee;
}).collect(Collectors.toList());
// employeeList.forEach(System.out::println);
List<Employee> employeeList2 = list.stream().flatMap(word -> {
List<String> words = Arrays.stream(word.split(",")).collect(Collectors.toList());
List<Employee> lists = new ArrayList<>();
Employee employee = new Employee(words.get(0), Integer.parseInt(words.get(1)), words.get(2), words.get(3));
lists.add(employee);
Employee employee2 = new Employee(words.get(0)+"_2", Integer.parseInt(words.get(1)), words.get(2), words.get(3));
lists.add(employee2);
return lists.stream();
}).collect(Collectors.toList());
// employeeList2.forEach(System.out::println);
Map<String, Long> map = employeeList.stream().collect(Collectors.groupingBy(Employee::getDepartment, Collectors.counting()));
System.out.println(map);
Map<String, List<Employee>> map2 = employeeList.stream().collect(Collectors.groupingBy(Employee::getDepartment));
System.out.println(map2);
int age = employeeList.stream().mapToInt(e -> e.age).sum();
System.out.println(age);// 178
int age1 = employeeList.stream().mapToInt(e -> e.getAge()).reduce(0,(a,b) -> a+b);
System.out.println(age1);// 178
/**
* pre 代表前一个对象
* current 代表当前对象
*/
Employee reduceEmployee = employeeList.stream().reduce(new Employee(), (pre,current) -> {
if (pre.getAge() == null) {
current.setAge(current.getAge());
} else {
current.setAge(pre.getAge() + current.getAge());
}
return current;
});
System.out.println(reduceEmployee);
}
@Getter
@Setter
@AllArgsConstructor
@NoArgsConstructor
@ToString
static
class Employee implements Serializable {
private String name;
private Integer age;
private String department;
private String level;
}
}
spark 的源码:
点击查看代码
import com.google.gson.Gson;
import lombok.*;
import org.apache.spark.api.java.function.*;
import org.apache.spark.sql.*;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
import java.util.stream.Collectors;
public class SparkDemo {
public static void main(String[] args) {
SparkSession session = SparkSession.builder().master("local[*]").getOrCreate();
Dataset<Row> reader = session.read().text("F:/test.txt");
// reader.show();
/**
* +-----------------------+
* | value|
* +-----------------------+
* |张三,20,研发部,普通员工|
* |李四,31,研发部,普通员工|
* |李丽,36,财务部,普通员工|
* |张伟,38,研发部,经理|
* |杜航,25,人事部,普通员工|
* |周歌,28,研发部,普通员工|
* +-----------------------+
*/
// 本地演示而已,实际分布式环境,这里的gson涉及到序列化问题
// 算子以外的代码都在driver端运行
// 任何算子以内的代码都在executor端运行,即会在不同的服务器节点上执行
Gson gson = new Gson();
// a 算子外部,driver端
Dataset<Employee> employeeDataset = reader.map(new MapFunction<Row, Employee>() {
@Override
public Employee call(Row row) throws Exception {
// b 算子内部,executor端
Employee employee = null;
try {
// gson.fromJson(); 这里使用gson涉及到序列化问题
List<String> list = Arrays.stream(row.mkString().split(",")).collect(Collectors.toList());
employee = new Employee(list.get(0), Integer.parseInt(list.get(1)), list.get(2), list.get(3));
} catch (Exception exception) {
// 日志记录
// 流式计算中要做到7*24小时不间断,任意一条上流脏数据都可能导致失败,从而导致任务退出,所以这里要做好异常的抓取
exception.printStackTrace();
}
return employee;
}
}, Encoders.bean(Employee.class));
// employeeDataset.show();
/**
* +---+----------+--------+----+
* |age|department| level|name|
* +---+----------+--------+----+
* | 20| 研发部|普通员工|张三|
* | 31| 研发部|普通员工|李四|
* | 36| 财务部|普通员工|李丽|
* | 38| 研发部| 经理|张伟|
* | 25| 人事部|普通员工|杜航|
* | 28| 研发部|普通员工|周歌|
*/
Dataset<Employee> employeeDataset2 = reader.mapPartitions(new MapPartitionsFunction<Row, Employee>() {
@Override
public Iterator<Employee> call(Iterator<Row> iterator) throws Exception {
List<Employee> employeeList = new ArrayList<>();
while (iterator.hasNext()){
Row row = iterator.next();
try {
List<String> list = Arrays.stream(row.mkString().split(",")).collect(Collectors.toList());
Employee employee = new Employee(list.get(0), Integer.parseInt(list.get(1)), list.get(2), list.get(3));
employeeList.add(employee);
} catch (Exception exception) {
// 日志记录
// 流式计算中要做到7*24小时不间断,任意一条上流脏数据都可能导致失败,从而导致任务退出,所以这里要做好异常的抓取
exception.printStackTrace();
}
}
return employeeList.iterator();
}
}, Encoders.bean(Employee.class));
// employeeDataset2.show();
/**
* +---+----------+--------+----+
* |age|department| level|name|
* +---+----------+--------+----+
* | 20| 研发部|普通员工|张三|
* | 31| 研发部|普通员工|李四|
* | 36| 财务部|普通员工|李丽|
* | 38| 研发部| 经理|张伟|
* | 25| 人事部|普通员工|杜航|
* | 28| 研发部|普通员工|周歌|
* +---+----------+--------+----+
*/
Dataset<Employee> employeeDatasetFlatmap = reader.flatMap(new FlatMapFunction<Row, Employee>() {
@Override
public Iterator<Employee> call(Row row) throws Exception {
List<Employee> employeeList = new ArrayList<>();
try {
List<String> list = Arrays.stream(row.mkString().split(",")).collect(Collectors.toList());
Employee employee = new Employee(list.get(0), Integer.parseInt(list.get(1)), list.get(2), list.get(3));
employeeList.add(employee);
Employee employee2 = new Employee(list.get(0)+"_2", Integer.parseInt(list.get(1)), list.get(2), list.get(3));
employeeList.add(employee2);
} catch (Exception exception) {
exception.printStackTrace();
}
return employeeList.iterator();
}
}, Encoders.bean(Employee.class));
// employeeDatasetFlatmap.show();
/**
* +---+----------+--------+------+
* |age|department| level| name|
* +---+----------+--------+------+
* | 20| 研发部|普通员工| 张三|
* | 20| 研发部|普通员工|张三_2|
* | 31| 研发部|普通员工| 李四|
* | 31| 研发部|普通员工|李四_2|
* | 36| 财务部|普通员工| 李丽|
* | 36| 财务部|普通员工|李丽_2|
* | 38| 研发部| 经理| 张伟|
* | 38| 研发部| 经理|张伟_2|
* | 25| 人事部|普通员工| 杜航|
* | 25| 人事部|普通员工|杜航_2|
* | 28| 研发部|普通员工| 周歌|
* | 28| 研发部|普通员工|周歌_2|
* +---+----------+--------+------+
*/
RelationalGroupedDataset datasetGroupBy = employeeDataset.groupBy("department");
// 统计每个部门有多少员工
// datasetGroupBy.count().show();
/**
* +----------+-----+
* |department|count|
* +----------+-----+
* | 财务部| 1|
* | 人事部| 1|
* | 研发部| 4|
* +----------+-----+
*/
/**
* 每个部门的平均年龄
*/
// datasetGroupBy.avg("age").withColumnRenamed("avg(age)","avgAge").show();
/**
* +----------+--------+
* |department|avg(age)|
* +----------+--------+
* | 财务部| 36.0|
* | 人事部| 25.0|
* | 研发部| 29.25|
* +----------+--------+
*/
KeyValueGroupedDataset keyValueGroupedDataset = employeeDataset.groupByKey(new MapFunction<Employee, String>() {
@Override
public String call(Employee employee) throws Exception {
// 返回分组的key,这里表示根据部门进行分组
return employee.getDepartment();
}
}, Encoders.STRING());
keyValueGroupedDataset.mapGroups(new MapGroupsFunction() {
@Override
public Object call(Object key, Iterator iterator) throws Exception {
System.out.println("key = " + key);
while (iterator.hasNext()){
System.out.println(iterator.next());
}
return iterator;
/**
* key = 人事部
* SparkDemo.Employee(name=杜航, age=25, department=人事部, level=普通员工)
* key = 研发部
* SparkDemo.Employee(name=张三, age=20, department=研发部, level=普通员工)
* SparkDemo.Employee(name=李四, age=31, department=研发部, level=普通员工)
* SparkDemo.Employee(name=张伟, age=38, department=研发部, level=经理)
* SparkDemo.Employee(name=周歌, age=28, department=研发部, level=普通员工)
* key = 财务部
* SparkDemo.Employee(name=李丽, age=36, department=财务部, level=普通员工)
*/
}
}, Encoders.bean(Iterator.class))
.show(); // 这里的show()没有意义,只是触发计算而已
Employee datasetReduce = employeeDataset.reduce(new ReduceFunction<Employee>() {
@Override
public Employee call(Employee t1, Employee t2) throws Exception {
// 不同的版本看是否需要判断t1 == null
t2.setAge(t1.getAge() + t2.getAge());
return t2;
}
});
System.out.println(datasetReduce);
Employee employee = employeeDataset.filter("age > 30").limit(3).sort("age").first();
System.out.println(employee);
// SparkDemo.Employee(name=李四, age=31, department=研发部, level=普通员工)
employeeDataset.registerTempTable("table");
session.sql("select * from table where age > 30 order by age desc limit 3").show();
/**
* +---+----------+--------+----+
* |age|department| level|name|
* +---+----------+--------+----+
* | 38| 研发部| 经理|张伟|
* | 36| 财务部|普通员工|李丽|
* | 31| 研发部|普通员工|李四|
* +---+----------+--------+----+
*/
}
@Getter
@Setter
@AllArgsConstructor
@NoArgsConstructor
@ToString
public static class Employee implements Serializable {
private String name;
private Integer age;
private String department;
private String level;
}
}
spark maven依赖,自行不需要的spark-streaming,kafka依赖去掉。
点击查看代码
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<scala.version>2.12.15</scala.version>
<spark.version>3.2.0</spark.version>
<encoding>UTF-8</encoding>
</properties>
<dependencies>
<!-- scala依赖-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- spark依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.2</version>
<scope>provided</scope>
</dependency>
<!--<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>${spark.version}</version>
</dependency>-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.7</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.34</version>
</dependency>
</dependencies>