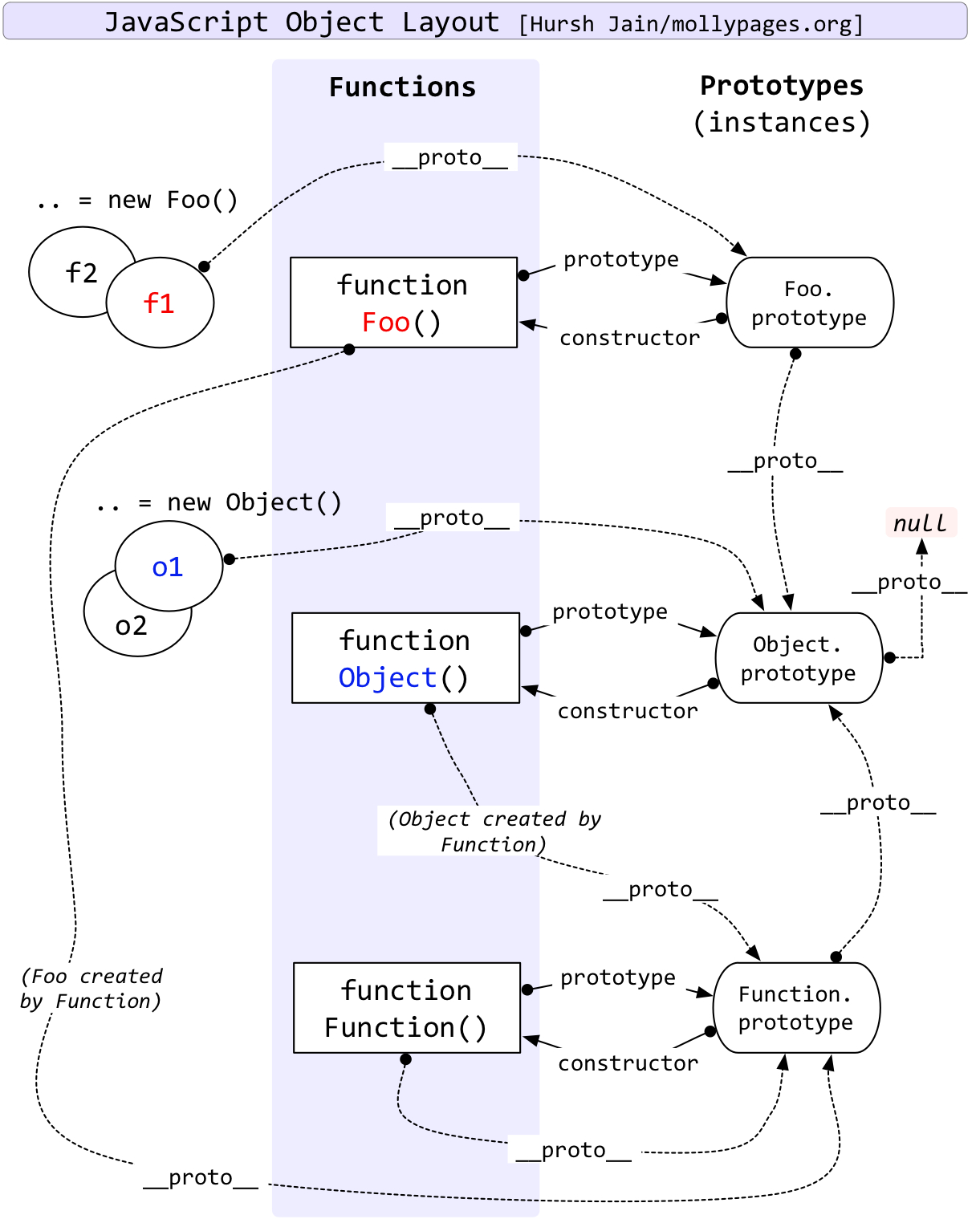
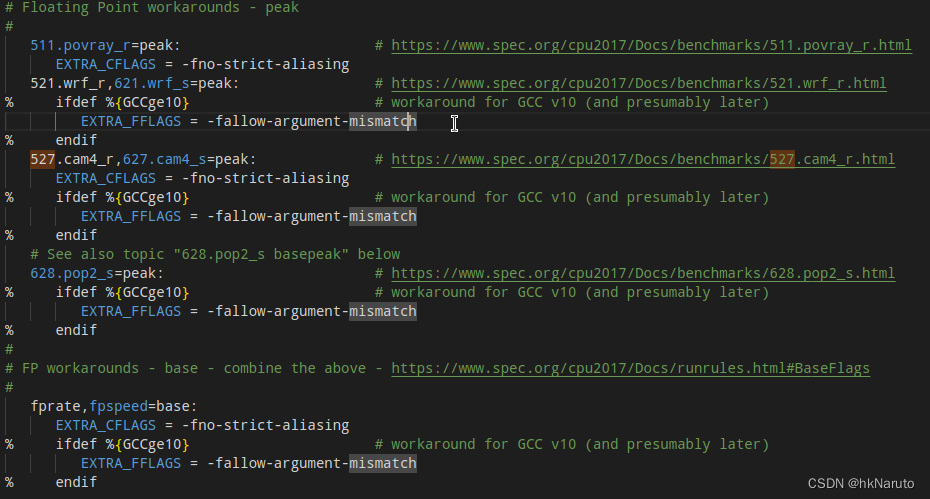
MySQL体系结构
- Client Connectors: 接入方支持的协议。
- Management Serveices & Utilities: 系统管理和控制工具,mysqldump、 mysql复制集群、分区管理等。
- Connection Pool: 连接池,管理缓冲用户连接、用户名、密码、权限校验、线程处理等需要缓存的需求。
- SQL Interface: SQL接口,接受用户的SQL命令,并且返回用户需要查询的结果。
- Parser: 解析器,SQL命令传递到解析器的时候会被解析器验证和解析。解析器是由Lex和YACC实现的。
- Optimizer: 查询优化器,SQL语句在查询之前会使用查询优化器对查询进行优化。
- Cache和Buffer(高速缓存区): 查询缓存,如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据。
- Pluggable Storage Engines: 插件式存储引擎。存储引擎是MySql中具体的与文件打交道的子系统。
- File System: 文件系统,数据、日志(redo,undo)、索引、错误日志、查询记录、慢查询等。
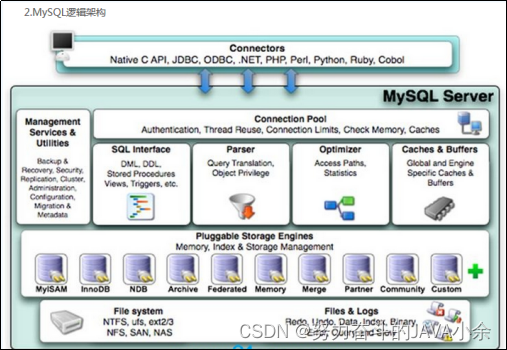
mysql主要索引的对比:
- InnoDB的主键索引与行记录是存储在一起的,使用的索引叫做聚集索引;
- 所有的数据查找都是基于聚集索引。
- 存在主键,则以主键作为聚集索引,否则以一个非空的unique作为聚集索引,否则创建一个隐藏的row-id作为聚集索引;
- 当通过辅助索引查找数据时,通过索引查找树,查找到叶子节点中存储聚集索引,最后才通过聚集索引查找到对应的数据。
索引的作用:
- 提高数据检索的效率,降低数据库的IO成本
- 通过创建唯一索引保证每一行数据的唯一性
- 提高查询效率
索引的缺点:
- 创建索引和维护需要耗费时间
- 占用磁盘空间
- 当对表中数据进行增删改时需要修改索引,降低更新表的速度
索引优化技巧:
- 全值匹配我最爱,最左前缀要遵守;
- 带头大哥不能死,中间兄弟不能断;
- 索引列上少计算;范围之后全失效;
- like百分写最右;覆盖索引不写量;
- 不等空值还有OR;索引失效要少用;
- VAR引号不可丢;SQL高级也不难;
其他优化:
a.保证被驱动表的JOIN字段已经创建了索引
b.需要JOIN 的字段,数据类型保持绝对一致。
c.LEFT JOIN时选择小表作为驱动表,大表作为被驱动表。减少外层循环的次数。
d.INNER JOIN 时,MySQL会自动将小结果集的表选为驱动表,选择相信MySQL优化策略。
e.能够直接多表关联的尽量直接关联,不用子查询。(减少查询的趟数)
f.不建议使用子查询,建议将子查询SQL拆开结合程序多次查询,或使用JOIN来代替子查询。
g.衍生表建不了索引
注意: 什么是小表
在决定哪个表做驱动表的时候,应该是两个表按照各自的条件过滤,过滤完成之后,计算参与join的各个字段的总数据量,数据量小的那个表,就是“小表”,应该作为驱动表
Order By 与Group By:
对于order by,尽量使用Index方式排序,避免使用FileSort方式排序。
group by 实质是先排序后进行分组,优化技巧同order by一样。
MySQL支持Index和FileSort排序,Index比FileSort排序效率高,Index是基于索引实现排序,而FileSort是基于外部文件排序的。若想要实现Index排序,需要遵照索引建的最佳左前缀原则,下面通过案例(伪代码)说明:
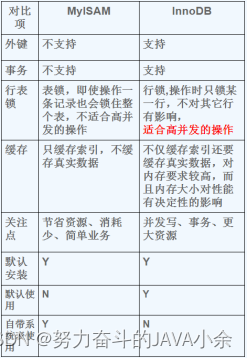
假设一个表建立索引:index_abc(a,b,c)
--无过滤不索引
explain select SQL_NO_CACHE * from emp order by age,deptid limit 10;
create index idx_age_deptid on emp (age,deptid)
-- order by 使用到索引排序,遵守最佳左前缀排序
order by a
order by a,b
order by a,b,c
order by a DESC,b DESC,c DESC
-- 如果WHERE使用索引的左前缀为常量,则order by 能使用索引
where a = const order by b,c
where a = const and b = const order by c
where a = const and b>const order by b,c
-- 不能使用索引排序
-- 排序不一致
order by a ASC,b DESC,c DESC
-- 丢掉a索引
where g=const order by b,c
-- 丢掉b索引
where a=const order by c
-- d不是索引的一部分
where a=const order by a,d
-- 对于排序来说,多个相等的条件也是范围查询
where a in(…………) order by b,c
案例分析:
假设表Y建立索引index(a,b,c)
a是字符类型,b、c 是整型;
1/2的含义是: 若是多列索引,要遵守最左前缀法则;指的是查询从索引的最左前列开始并且不跳过索引中的列,同时如果能够所有索引列都能匹配是最完美的。
-- 使用到索引列a,其他b、c并未使用到
select *from Y where a='1';
-- 使用到索引a、b,未使用到c
select *from Y where a='1' and b=2;
-- 所有的索引列都使用到,最好的最完美的方式
select *from Y where a='1' and b=2 and c=3;
-- 跳过了索引a,所有的索引都未使用到(所以带头大哥不能死哟)
select *from Y where b=2 and c=3;
select *from Y where b=2;
select *from Y where c=3;
-- 使用到索引a,并未使用到索引c,因为跳过了中间索引b
select *from Y where a='1' and c=3;
3 的含义是: 不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),否则会导致索引失效而转向全表扫描;若使用索引列中,使用到范围查找,则范围查找右边使用到的索引列会失效。
-- 通过索引列计算,则索引列a未使用到
select *from Y where right(a,2)='1';
-- b列通过范围查找,则范围右边的列c未使用到
select *from Y where a='1' and b>2 and c=3;
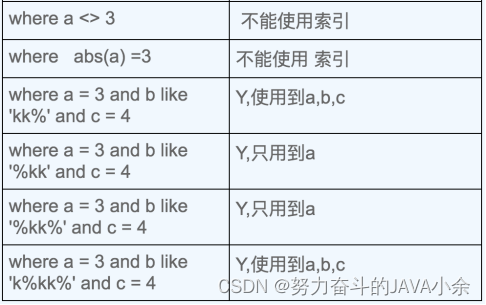
4 的含义是: like模糊查找以通配符开头(’%abc’、’%abc%’)mysql索引失效会变成全表扫描操作;查询中尽量使用覆盖索引(只访问索引的查询(索引列和查询列一致)),减少使用select*。
-- abc索引列都使用到了
select *from Y where a like 'xx%' and b=2 and c=3;
-- 同上
select *from Y where a like 'k%xx%' and b=2 and c=3;
-- 左匹配模糊查询,导致索引失效,所有索引都未使用到
select *from Y where a like '%xx' and b=2 and c=3;
-- 同上
select *from Y where a like '%xx%' and b=2 and c=3;
-- 使用覆盖索引,不使用select*,覆盖索引前提是保证查询条件和查询内容列一样
select a,b,c from Y where a='1' and b=2 and c=3;
5 的含义是: MySQL在使用(!=或<>或is null或is not null 或or)的时候无法使用索引会导致全表扫描。
-- a、b、c索引失效
select *from Y where a='1' or b='2' and c='3';
-- 索引a未使用
select *from Y where a is null;
-- 索引a未使用
select *from Y where a != '1';
6 的含义是: 字符类型的字段作为条件查询时,不加单引号会导致索引失效,因为它存在隐式类型转换。
-- 存在隐式类型转换
select *from Y where a = 1;
-- 不带引号,索引列a是用不到
select *from Y where a = '1';
查询优化处理:
查询优化处理主要由解析器、预处理器、查询优化器。
通过explain,能够很清晰的知道SQL查询读取表的顺序、哪些索引被使用到、表直接的引用关系、每张表有多少条数据被扫描等等。

-
id: 表示select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序。
id相同,执行顺序由上至下;
id不同,如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行;
id相同,可以认为是一组,从上往下顺序执行;在所有组中,id值越大,优先级越高,越先执行。 -
select_type: 主要是用于区分普通查询、联合查询、子查询等。
SIMPLE: 简单的select查询,查询中不包含子查询或者UNION;
PRIMARY: 查询中若包含任何复杂的子部分,最外层查询则被标记为primary;
SUBQUERY: 在SELECT或者WHERE列表中包含了子查询;
DERIVED: 在FROM列表中包含的子查询被标记为DERIVED(衍生) MySQL会递归执行这些子查询,把结果放在临时表里;
UNION: 若第二个SELECT出现在UNION之后,则被标记为UNION; 若UNION包含在FROM子句的子查询中,外层SELECT将被标记为DERIVED;
UNION RESULT: 从UNION表获取结果的SELECT。 -
table: 查询涉及到的表,直接显示表名或者表的别名。
<unionM,N> 由ID为M,N 查询union产生的结果;
由ID为N查询生产的结果。 -
type: 访问类型,sql 查询优化中一个很重要的指标,结果值从好到坏依次是:system > const > eq_ref > ref > range > index > ALL。
system: 表只有一行记录(等于系统表),const类型的特例,基本不会出现,可以忽略不计;
const: 表示通过索引一次就找到了,const用于比较primary key 或者 unique索引;
eq_ref: 唯一索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或唯一索引扫描;
ref: 非唯一性索引扫描,返回匹配某个单独值的所有行,本质是也是一种索引访问;
range: 只检索给定范围的行,使用一个索引来选择行。key列显示使用了哪个索引一般就是在你的where语句中出现了between、<、>、in等的查询 这种范围扫描索引扫描比全表扫描要好,因为他只需要开始索引的某一点,而结束语另一点,不用扫描全部索引。
index: Full Index Scan,索引全表扫描,把索引从头到尾扫一遍;
ALL: Full Table Scan,遍历全表以找到匹配的行。 -
possible_keys: 查询涉及的字段上若存在索引,则该索引将被列出,但不一定被查询实际使用,也就是可能使用到的索引。
-
key: 实际使用的索引。如果为null则没有使用索引,查询中若使用了覆盖索引,则索引和查询的select字段重叠。
-
key_len: 表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。在不损失精确性的情况下,长度越短越好key_len显示的值为索引最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的。
-
ref: 显示索引那一列被使用了,如果可能的话,是一个常数。那些列或常量被用于查找索引列上的值。
-
rows: 据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数。
-
Extra: 包含不适合在其他列中显示但十分重要的额外信息。
Using filesort: 说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取。 MySQL中无法利用索引完成排序操作成为“文件排序”;
Using temporary: 使用了临时表保存中间结果,MySQL在对查询结果排序时使用临时表。常见于排序order by 和分组查询 group by;
Using index: 表示相应的select操作中使用了覆盖索引(Coveing Index),避免访问了表的数据行,效率不错! 如果同时出现using where,表明索引被用来执行索引键值的查找; 如果没有同时出现using where,表面索引用来读取数据而非执行查找动作,覆盖索引(Covering Index) ;
Using where: 表明用到where条件过滤;
Using join buffer: 使用了连接缓存;
Impossible where: 子句的值总是false,不能用来获取任何元组;
Select tables optimized away: 在没有GROUPBY子句的情况下,基于索引优化MIN/MAX操作或者对于MyISAM存储引擎优化COUNT(*)操作,不必等到执行阶段再进行计算, 查询执行计划生成的阶段即完成优化;
distinct: 优化distinct,在找到第一匹配的元组后即停止找同样值的工作。
partitions: 查询记录来自哪个分区。若没有匹配分区,该值为NULL。
filtered: 查询过滤行所占百分比,若为100则数据未过滤,过滤掉的行数为:总行数×filtered百分比值(单位%)。
show profiles:
show profiles是MySQL提供可以用来分析当前会话中语句执行的资源消耗情况,可以用于SQL的调优测量
B-tree和B+tree的区别
系统从磁盘读取数据到内存时是以磁盘块(block)为基本单位的,InnoDB存储引擎中默认每个页的大小为16KB
B-tree:
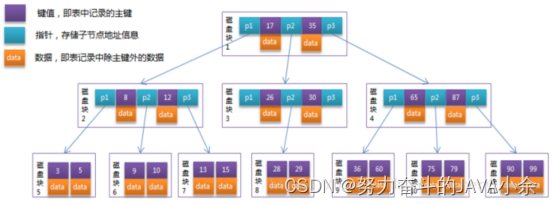
元素为键值对的形式,key是数据的主键,data是具体的数据。沿着根节点往下找key就可以直接获取到对应的data效率比较高。缺点:data占用磁盘块的空间,存储的key有限。
B+tree:
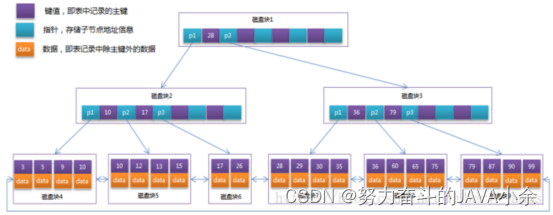
当存储的数据量很大时同样会导致B-Tree的深度较大,增大查询时的磁盘I/O次数,而非叶子节点上只存储key值信息,这样可以大大加大每个节点存储的key值数量,降低B+Tree的高度。
一般表的主键类型为INT(占用4个字节)或BIGINT(占用8个字节),指针类型也一般为4或8个字节,也就是说一个页(B+Tree中的一个节点)中大概存储16KB/(8B+8B)=1K个键值(因为是估值,为方便计算,这里的K取值为〖10〗^3)。 也就是说一个深度为3的B+Tree索引可以维护10^3 * 10^3 * 10^3 = 10亿 条记录
也就是说查找某一键值的行记录时最多只需要1~3次磁盘I/O操作。
MySQL主要使用B+Tree作为索引算法,InnoDB引擎就是使用这种算法,它的特点有如下几点:
- 节点关键字搜索采用闭合区间;
- 非叶节点不保存数据相关信息,只保存关键字和子节点的引用;
- 关键字对应的数据保存在叶子节点中;
- 叶子节点是顺序排列的,并且相邻节点具有顺序引用的关系;
练习(包含SQL优化处理):
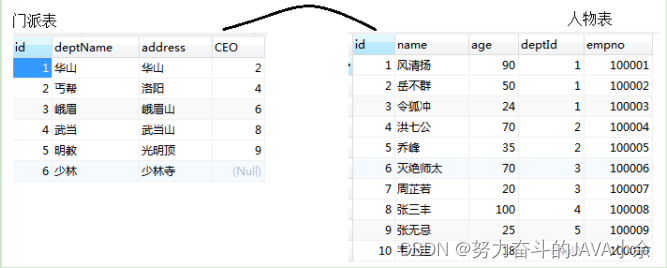
1、列出自己的掌门比自己年龄小的人员
select a.name,a.age,c.name,c.age from t_emp a inner join t_dept b
on a.deptid=b.id
left join t_emp c on b.ceo=c.id
where a.age>c.age
优化---建立索引
create index index_deptid_age on emp (deptid,age);
create index index_ceo on dept (ceo);
2、列出所有年龄低于自己门派平均年龄的人员
select * from t_emp b inner join
(select a.deptId,AVG(a.age) avgAge from t_emp a GROUP BY a.deptId) c
on b.deptId=c.deptId and b.age<c.avgAge
优化---效果不太好
create index index_deptid_age on emp (deptid,age);
没有办法继续更好优化的时候 可能就需要考虑重新设计表结构
3、列出至少有2个年龄大于40岁的成员的门派
select b.deptName,count(0) num from t_emp a inner join t_dept b on a.deptId=b.id where a.age>40
group by b.deptName HAVING num>=2
优化---建立索引
create index index_deptid_age on emp (deptid,age);
create index index_deptName on dept (deptName);
4、至少有2位非掌门人成员的门派
select * from t_dept c inner join
(select a.deptId,count(0) num from t_emp a left join t_dept b on a.id=b.ceo
where b.id is null GROUP BY a.deptId HAVING num>=2) ab
on c.id=ab.deptId
优化---修改SQL语句写法
select a.deptId,c.deptName,count(0) num from t_emp a
left join t_dept c on c.id=a.deptId
left join t_dept b on a.id=b.ceo
where b.id is null GROUP BY a.deptId,c.deptName HAVING num>=2
修改SQL语句写法
explain select a.deptId,c.deptName,count(0) num from dept c
left join emp a on c.id=a.deptId
left join dept b on a.id=b.ceo
where b.id is null GROUP BY a.deptId,c.deptName HAVING num>=2
5、列出全部人员,并增加一列备注“是否为掌门” 如果是掌门人显示是 不是掌门人显示否
select a.name,case when b.id is null then '否' else '是' end '是否为掌门'
from t_emp a left join t_dept b on a.id=b.ceo
6、列出全部门派,并增加一列备注“老鸟or菜鸟”,若门派的平均值年龄>50显示“老鸟”,否则显示“菜鸟”
select a.deptName,AVG(b.age) avgAge,if(AVG(b.age)>50,'老鸟','菜鸟') '老鸟or菜鸟'
from t_dept a left join t_emp b on a.id =b.deptId
GROUP BY a.deptName
7、显示每个门派年龄最大的人
select * from t_emp c inner join
(select a.deptId,max(a.age) maxAge from t_emp a GROUP BY a.deptId) b
on c.deptId=b.deptId and c.age=b.maxAge
优化---建立索引
create index index_deptid_age on emp (deptId,age);
8、显示每个门派年龄第二大的人
SET @rank=0;
SET @last_deptid=0;
SELECT t.*,
IF(@last_deptid=deptid,@rank:=@rank+1,@rank:=1) AS rk,
@last_deptid:=deptid AS last_deptid
FROM t_emp t
ORDER BY deptid,age DESC
已经在组内实现分组按照年龄降序排序
SET @rank=0;
SET @last_deptid=0;
SELECT a.deptid,a.name,a.age
FROM(
SELECT t.*,
IF(@last_deptid=deptid,@rank:=@rank+1,@rank:=1) AS rk,
@last_deptid:=deptid AS last_deptid
FROM t_emp t
ORDER BY deptid,age DESC
)a WHERE a.rk=2;
解决bug
update t_emp set age=90 where id =2
SET @rank=0;
SET @last_deptid=0;
SET @last_age=0;
SELECT t.*,
IF(@last_deptid=deptid,
IF(@last_age = age,@rank,@rank:=@rank+1)
,@rank:=1) AS rk,
@last_deptid:=deptid AS last_deptid,
@last_age :=age AS last_age
FROM t_emp t
ORDER BY deptid,age DESC