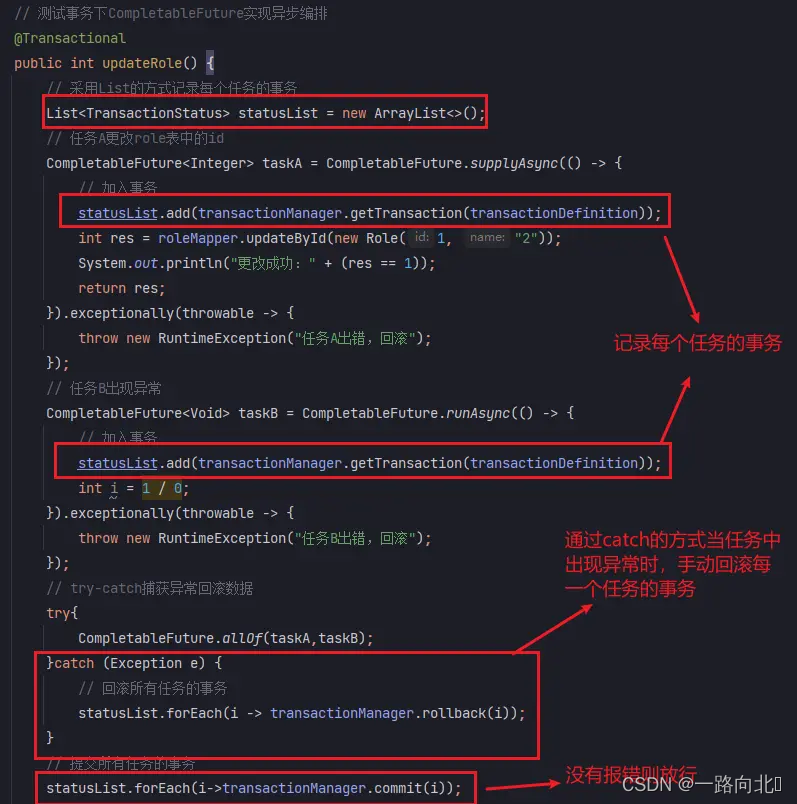
目录
方法一:按行读取
方法二:按表头与表数据一一对应的关系
方法三:按列的方式读取
之前有说到如何在Django中读取数据库数据写入到excel中 今天来说说如何读取excel中的数据,(读取后就可以写入到数据库中了)
开始前需要安装xlrd模块
pip install -i https://pypi.douban.com/simple xlrd
默认安装最新版,支持xls格式的excel文件,如果是xlsx文件格式可能需要安装旧版本的xlrd
方法一:按行读取
import xlrd
class ReadExcel(View):
def post(self, request):
excel_file = request.FILES['excel_file'] # 获取上传的Excel文件
workbook = xlrd.open_workbook(file_contents=excel_file.read()) # 打开Excel文件
sheet_names = workbook.sheet_names() # 获取所有工作表的名称
# 方式一:按行
data = [] # 存储所有工作表的数据
for sheet_name in sheet_names:
sheet = workbook.sheet_by_name(sheet_name) # 获取具体的工作表
rows = []
for row_num in range(sheet.nrows): # 迭代每一行数据
row_values = sheet.row_values(row_num) # 获取当前行的值
rows.append(row_values)
data.append({
'sheet_name': sheet_name,
'rows': rows,
})
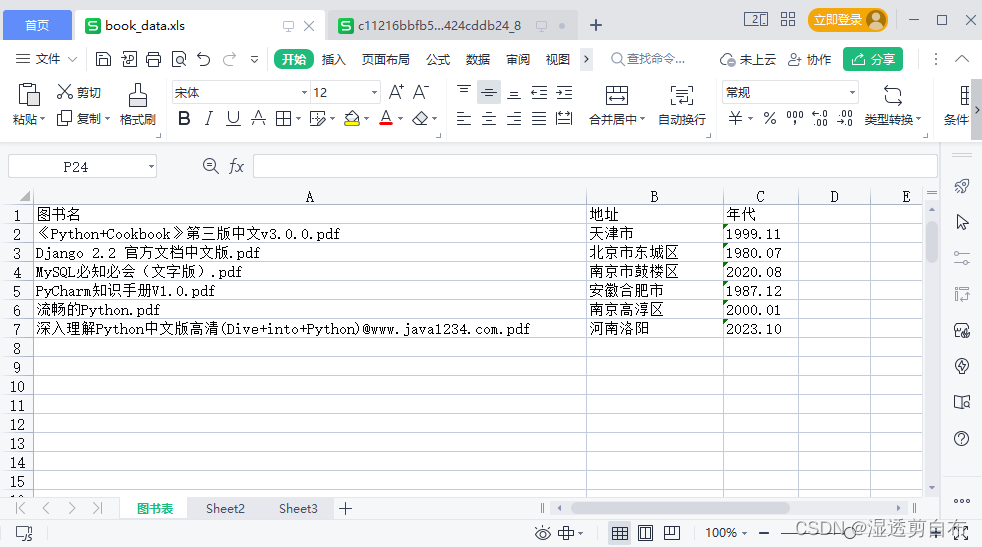
return JsonResponse({"res": data})使用book_data.xls表格文件,内容如下
输出结果:
{
"res": [
{
"sheet_name": "图书表",
"rows": [
[
"图书名",
"地址",
"年代"
],
[
"《Python+Cookbook》第三版中文v3.0.0.pdf",
"天津市",
"1999.11"
],
[
"Django 2.2 官方文档中文版.pdf",
"北京市东城区",
"1980.07"
],
[
"MySQL必知必会(文字版).pdf",
"南京市鼓楼区",
"2020.08"
],
[
"PyCharm知识手册V1.0.pdf",
"安徽合肥市",
"1987.12"
],
[
"流畅的Python.pdf",
"南京高淳区",
"2000.01"
],
[
"深入理解Python中文版高清(Dive+into+Python)@www.java1234.com.pdf",
"河南洛阳",
"2023.10 "
]
]
},
{
"sheet_name": "Sheet2",
"rows": [
[
"图片名",
"路径"
],
[
"测试",
"测试路径"
]
]
},
{
"sheet_name": "Sheet3",
"rows": []
}
]
}方法二:按表头与表数据一一对应的关系
import xlrd
class ReadExcel(View):
def post(self, request):
excel_file = request.FILES['excel_file'] # 获取上传的Excel文件
workbook = xlrd.open_workbook(file_contents=excel_file.read()) # 打开Excel文件
sheet_names = workbook.sheet_names() # 获取所有工作表的名称
# 方式二:按表头与表数据一一对应关系
data = [] # 存储所有工作表的数据
for sheet_name in sheet_names:
sheet = workbook.sheet_by_name(sheet_name) # 获取具体的工作表
if sheet.nrows != 0:
rows = []
first_row = sheet.row_values(0) # 原表头数据
# first_row = ['name', 'address', 'year'] # 使用对应的英文字段替换上面first_row从表中获取的中文表头名
for row_num in range(1, sheet.nrows): # 迭代每一行数据
row_values = sheet.row_values(row_num) # 获取当前行的值
zip_data = dict(zip(first_row, row_values))
rows.append(zip_data)
data.append({
'sheet_name': sheet_name,
'rows': rows,
})
return JsonResponse({"res": data})结果如下:
{
"res": [
{
"sheet_name": "图书表",
"rows": [
{
"图书名": "《Python+Cookbook》第三版中文v3.0.0.pdf",
"地址": "天津市",
"年代": "1999.11"
},
{
"图书名": "Django 2.2 官方文档中文版.pdf",
"地址": "北京市东城区",
"年代": "1980.07"
},
{
"图书名": "MySQL必知必会(文字版).pdf",
"地址": "南京市鼓楼区",
"年代": "2020.08"
},
{
"图书名": "PyCharm知识手册V1.0.pdf",
"地址": "安徽合肥市",
"年代": "1987.12"
},
{
"图书名": "流畅的Python.pdf",
"地址": "南京高淳区",
"年代": "2000.01"
},
{
"图书名": "深入理解Python中文版高清(Dive+into+Python)@www.java1234.com.pdf",
"地址": "河南洛阳",
"年代": "2023.10 "
}
]
},
{
"sheet_name": "Sheet2",
"rows": [
{
"图片名": "测试",
"路径": "测试路径"
}
]
}
]
}方法三:按列的方式读取
import xlrd
class ReadExcel(View):
def post(self, request):
excel_file = request.FILES['excel_file'] # 获取上传的Excel文件
workbook = xlrd.open_workbook(file_contents=excel_file.read()) # 打开Excel文件
sheet_names = workbook.sheet_names() # 获取所有工作表的名称
# 方式三:按列的方式
data = [] # 存储所有工作表的数据
for sheet_name in sheet_names:
sheet = workbook.sheet_by_name(sheet_name) # 获取具体的工作表
if sheet.nrows != 0:
cols = []
cols_data = {}
for col_num in range(sheet.ncols): # 迭代每一列数据
first_row = sheet.col_values(col_num, 0, 1)[0] # 获取每一列第一行的数据(也就是表头)
col_values = sheet.col_values(col_num, 1) # 从列的第二行开始获取数据
cols_data.update({first_row: col_values})
cols.append(cols_data)
data.append({
'sheet_name': sheet_name,
'cols': cols,
})
return JsonResponse({"res": data})结果如下:
{
"res": [
{
"sheet_name": "图书表",
"cols": [
{
"图书名": [
"《Python+Cookbook》第三版中文v3.0.0.pdf",
"Django 2.2 官方文档中文版.pdf",
"MySQL必知必会(文字版).pdf",
"PyCharm知识手册V1.0.pdf",
"流畅的Python.pdf",
"深入理解Python中文版高清(Dive+into+Python)@www.java1234.com.pdf"
],
"地址": [
"天津市",
"北京市东城区",
"南京市鼓楼区",
"安徽合肥市",
"南京高淳区",
"河南洛阳"
],
"年代": [
"1999.11",
"1980.07",
"2020.08",
"1987.12",
"2000.01",
"2023.10 "
]
}
]
},
{
"sheet_name": "Sheet2",
"cols": [
{
"图片名": [
"测试"
],
"路径": [
"测试路径"
]
}
]
}
]
}共列出三种方式读取