利用人工智能解决音频、视觉和语言问题。音频分类、图像分类、物体检测、问答、总结、文本分类、翻译等均有大量模型进行参考。
Eg1: 图像识别
图像分类是为整个图像分配标签或类别的任务。每张图像预计只有一个类别。图像分类模型将图像作为输入并返回有关图像所属类别的预测
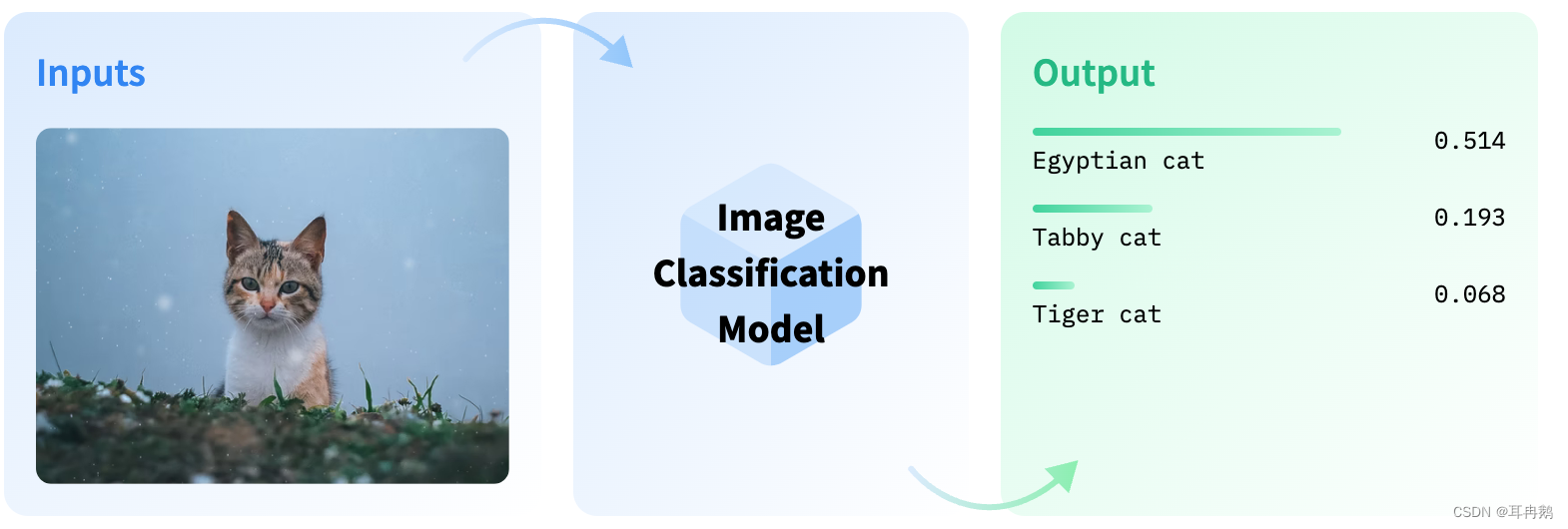
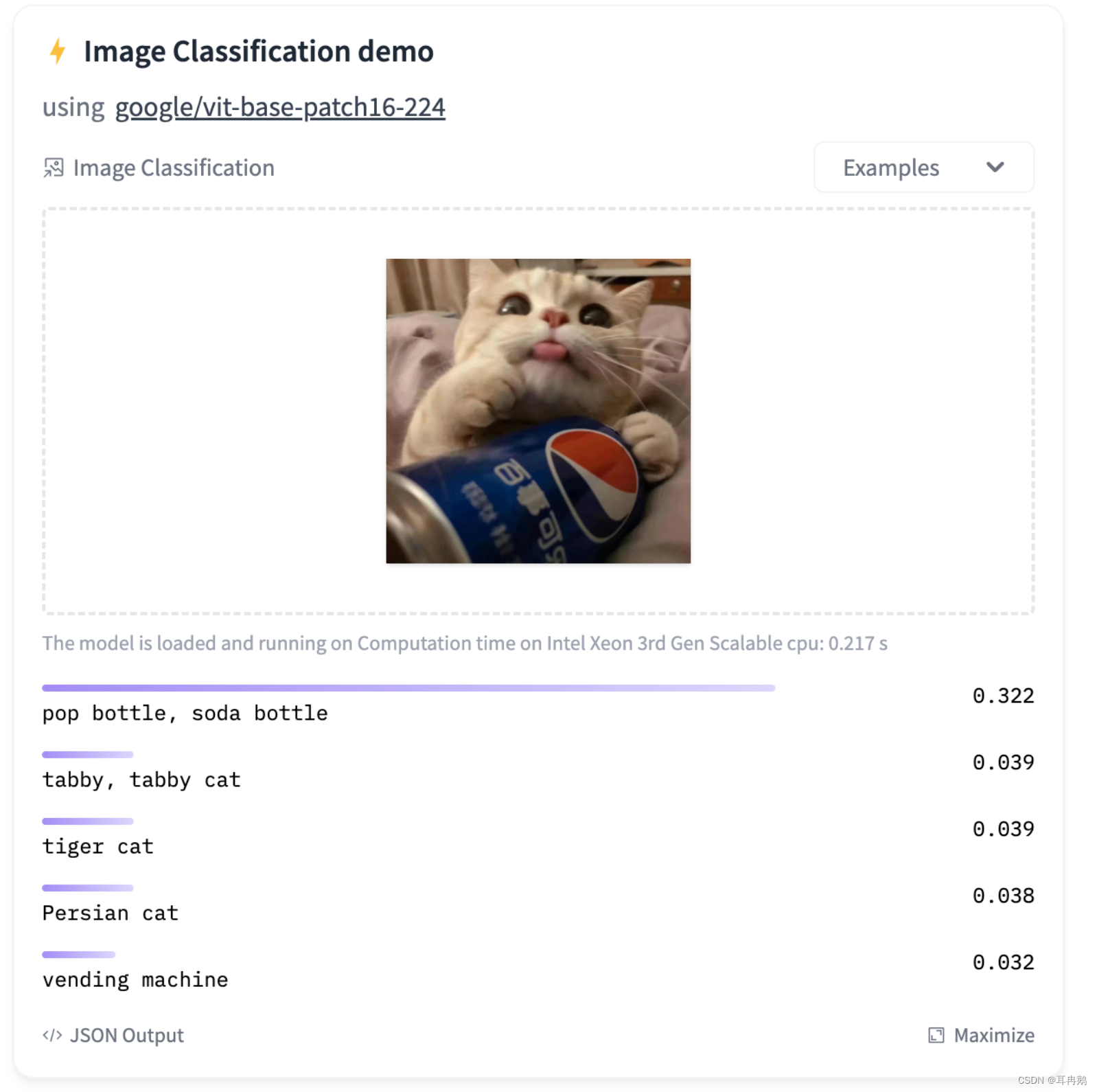
借助该transformers库,可以使用image-classification管道来推断图像分类模型。在不提供模型ID时,默认使用google/vit-base-patch16-224进行初始化pipeline。 调用pipeline管道时,只需要指定路径、http链接或PIL(Python Imaging Library)中加载的图标;还可以提供一个top_k参数来确定应返回多少结果
使用Transformer微调ViT
如何像对句子标记一样对图像进行标记,以便将其传递到Transformer模型进行训练。
- 将图像分割成子图像块的网格
- 使用线性投影嵌入每个补丁
- 每个嵌入的补丁都会成为一个令牌,嵌入补丁的结果序列就是传递给模型的序列
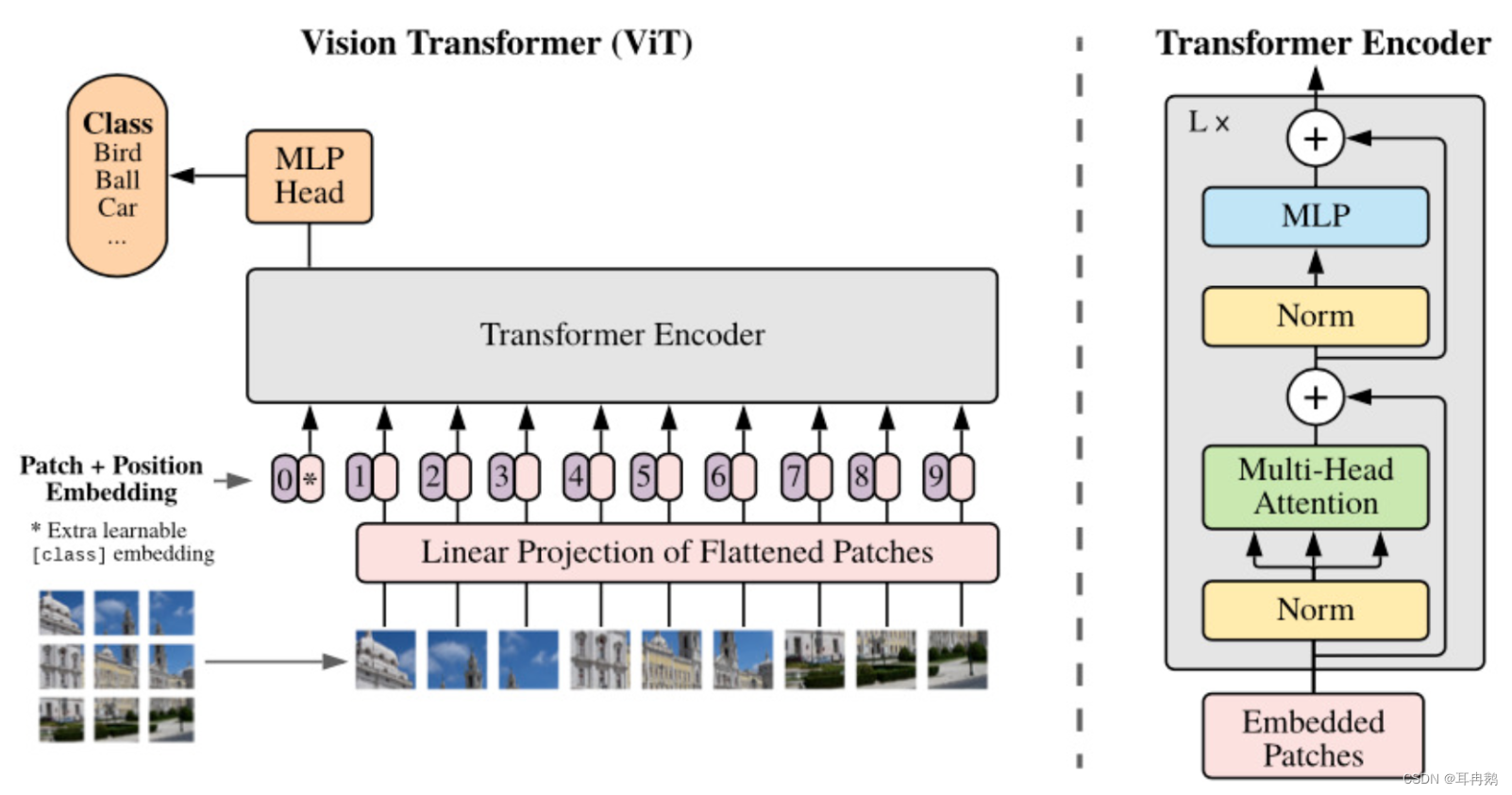
- MLP:Multilayer Perceptron 前向结构的人工神经网络——多层感知器
- Embedded Patches 嵌入补丁
如何使用datasets下载和处理的图像分类数据集通过微调预训练的ViT transformer
-
首先安装软件包
pip install datasets transformers Pillow -
加载数据集
使用beans数据集,是健康和非健康豆叶的图片集合
from datasets import load_dataset ds = load_dataset('beans') //DatasetDict({ // train: Dataset({ // features: ['image_file_path', 'image', 'labels'], // num_rows: 1034 // }) // validation: Dataset({ // features: ['image_file_path', 'image', 'labels'], // num_rows: 133 // }) // test: Dataset({ // features: ['image_file_path', 'image', 'labels'], // num_rows: 128 // }) //})每个数据集中每个示例都有3个特征:
- image: PIL图像
- image_file_path: str加载的图像文件的路径image
- labels:一个datasets.CLassLabel特征,是标签的整数表示
{ 'image': <PIL.JpegImagePlugin ...>, 'image_file_path': '/root/.cache/.../bean_rust_train.4.jpg', 'labels': 1 }ex = ds['train'][400] image = ex['image']
由于'labels'该数据集的特征是datasets.features.ClassLabel,我们可以使用它来查找本示例的标签 ID 的相应名称
labels = ds['train'].features['labels']
// ClassLabel(num_classes=3, names=['angular_leaf_spot', 'bean_rust', 'healthy'], names_file=None, id=None)
使用int2str 函数来打印示例的类标签
labels.int2str(ex['labels'])
// 'bean_rust'
上面图片叶子感染了“豆锈病”,是一种豆科植物的严重疾病
编写一个函数显示每个类的示例网格:
import random
from PIL import ImageDraw, ImageFont, Image
def show_examples(ds, seed: int = 1234, examples_per_class: int = 3, size=(350, 350)):
w, h = size
labels = ds['train'].features['labels'].names
grid = Image.new('RGB', size=(examples_per_class * w, len(labels) * h))
draw = ImageDraw.Draw(grid)
font = ImageFont.truetype("/usr/share/fonts/truetype/liberation/LiberationMono-Bold.ttf", 24)
for label_id, label in enumerate(labels):
# Filter the dataset by a single label, shuffle it, and grab a few samples
ds_slice = ds['train'].filter(lambda ex: ex['labels'] == label_id).shuffle(seed).select(range(examples_per_class))
# Plot this label's examples along a row
for i, example in enumerate(ds_slice):
image = example['image']
idx = examples_per_class * label_id + i
box = (idx % examples_per_class * w, idx // examples_per_class * h)
grid.paste(image.resize(size), box=box)
draw.text(box, label, (255, 255, 255), font=font)
return grid
show_examples(ds, seed=random.randint(0, 1337), examples_per_class=3)

- 角叶斑:有不规则的棕色斑块
- 豆锈病:有圆形棕色斑点,周围有白黄色环
- 健康:……看起来很健康
加载ViT特征提取器
现在知道图像是什么样子,并且更好地理解我们要解决的问题。让我们看看如何为我们的模型准备这些图像!
当训练 ViT 模型时,特定的转换将应用于输入到其中的图像。对图像使用错误的转换,模型将无法理解它所看到的内容!🖼➡️🔢
为了确保我们应用正确的转换,我们将使用ViTFeatureExtractor与我们计划使用的预训练模型一起保存的配置进行初始化。在我们的例子中,我们将使用google/vit-base-patch16-224-in21k模型,因此让我们从 Hugging Face Hub 加载其特征提取器。
from transformers import ViTFeatureExtractor
model_name_or_path = 'google/vit-base-patch16-224-in21k'
feature_extractor = ViTFeatureExtractor.from_pretrained(model_name_or_path)
//ViTFeatureExtractor {
// "do_normalize": true,
// "do_resize": true,
// "feature_extractor_type": "ViTFeatureExtractor",
// "image_mean": [
// 0.5,
// 0.5,
// 0.5
// ],
// "image_std": [
// 0.5,
// 0.5,
// 0.5
// ],
// "resample": 2,
// "size": 224
//}
要处理图像,只需将其传递给特征提取器的调用函数即可。这将返回一个包含 的字典pixel values,它是要传递给模型的数字表示形式
默认情况下,您会得到一个 NumPy 数组,但如果添加参数return_tensors='pt',您将得到torch张量…张量的形状是(1, 3, 224, 224)
feature_extractor(image, return_tensors='pt')
//{
// 'pixel_values': tensor([[[[ 0.2706, 0.3255, 0.3804, ...]]]])
//}
-
处理数据集
编写一个函数,读取图像并将其转换为输入——>处理数据集中的单个示例
def process_example(example): inputs = feature_extractor(example['image'], return_tensors='pt') inputs['labels'] = example['labels'] return inputs process_example(ds['train'][0]) //{ // 'pixel_values': tensor([[[[-0.6157, -0.6000, -0.6078, ..., ]]]]), // 'labels': 0 //}⚠️: 虽然可以ds.map立即调用方法并将其应用于每个示例,但在大数据集时会出现性能问题。故在每次转换发生于索引示例时应用于示例
ds = load_dataset('beans') def transform(example_batch): # Take a list of PIL images and turn them to pixel values inputs = feature_extractor([x for x in example_batch['image']], return_tensors='pt') # Don't forget to include the labels! inputs['labels'] = example_batch['labels'] return inputs也可以直接将其应用到数据集
prepared_ds = ds.with_transform(transform)每次从数据集中获取示例时,都会实时应用转换
prepared_ds['train'][0:2] //{ // 'pixel_values': tensor([[[[-0.6157, -0.6000, -0.6078, ..., ]]]]), // 'labels': [0, 0] //}训练
数据已处理完毕,就可以开始设置训练管道了。
这篇博文使用了 🤗 的 Trainer,但这需要我们首先做一些事情:
- 定义一个整理函数。
- 定义评估指标。在训练期间,应评估模型的预测准确性。应该使用
compute_metrics相应地定义一个函数。 - 加载预训练的检查点。需要加载预训练的检查点并正确配置它以进行训练。
- 定义训练配置。
对模型进行微调后,我们将在评估数据上正确评估它,并验证它确实学会了正确分类图像。
-
定义我们的数据整理器
批次以字典列表的形式出现,因此可以将它们解压+堆叠到批次张量中。
由于
collate_fn将返回一个批处理字典,因此可以**unpack稍后将输入输入到模型中import torch def collate_fn(batch): return { 'pixel_values': torch.stack([x['pixel_values'] for x in batch]), 'labels': torch.tensor([x['labels'] for x in batch]) } -
定义评估指标
数据集的准确性度量可以轻松用于将预测与标签进行比较。 下面可以看到如何在 Trainer 将使用的compute_metrics 函数中使用它
import numpy as np from datasets import load_metric metric = load_metric("accuracy") def compute_metrics(p): return metric.compute(predictions=np.argmax(p.predictions, axis=1), references=p.label_ids)加载预训练的模型。我们将添加
num_labelsinit,以便模型创建具有正确数量的单元的分类头。(我们还将包括
id2label和label2id映射,以便在 Hub 小部件中具有人类可读的标签。。如果您选择这样做push_to_hub)from transformers import ViTForImageClassification labels = ds['train'].features['labels'].names model = ViTForImageClassification.from_pretrained( model_name_or_path, num_labels=len(labels), id2label={str(i): c for i, c in enumerate(labels)}, label2id={c: str(i) for i, c in enumerate(labels)} )在此之前需要的最后一件事是通过定义 来设置训练配置
TrainingArguments其中大多数都是不言自明的,但这里非常重要的是
remove_unused_columns=False。这将删除模型调用函数未使用的所有功能。默认情况下,这是True因为通常最好删除未使用的特征列,从而更容易将输入解包到模型的调用函数中。但是,在我们的例子中,我们需要未使用的特征(特别是“图像”)来创建“像素值”。from transformers import TrainingArguments training_args = TrainingArguments( output_dir="./vit-base-beans", per_device_train_batch_size=16, evaluation_strategy="steps", num_train_epochs=4, fp16=True, save_steps=100, eval_steps=100, logging_steps=10, learning_rate=2e-4, save_total_limit=2, remove_unused_columns=False, push_to_hub=False, report_to='tensorboard', load_best_model_at_end=True, )接下来便可以开始训练
from transformers import Trainer trainer = Trainer( model=model, args=training_args, data_collator=collate_fn, compute_metrics=compute_metrics, train_dataset=prepared_ds["train"], eval_dataset=prepared_ds["validation"], tokenizer=feature_extractor, )Train 🚀
train_results = trainer.train() trainer.save_model() trainer.log_metrics("train", train_results.metrics) trainer.save_metrics("train", train_results.metrics) trainer.save_state()Evaluate 📊
metrics = trainer.evaluate(prepared_ds['validation']) trainer.log_metrics("eval", metrics) trainer.save_metrics("eval", metrics)结果如下:
***** eval metrics ***** epoch = 4.0 eval_accuracy = 0.985 eval_loss = 0.0637 eval_runtime = 0:00:02.13 eval_samples_per_second = 62.356 eval_steps_per_second = 7.97