StandAlone模式是spark自带的集群运行模式,不依赖其他的资源调度框架,部署起来简单。
StandAlone模式又分为client模式和cluster模式,本质区别是Driver运行在哪里,如果Driver运行在SparkSubmit进程中就是Client模式,如果Driver运行在集群中就是Cluster模式
standalone client模式
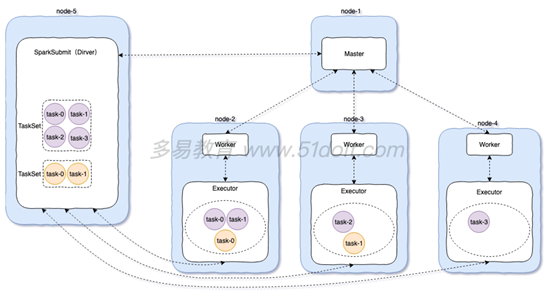
standalone cluster模式

Spark On YARN cluster模式

Spark执行流程简介

- Job:RDD每一个行动操作都会生成一个或者多个调度阶段 调度阶段(Stage):每个Job都会根据依赖关系,以Shuffle过程作为划分,分为Shuffle Map Stage和Result Stage。每个Stage对应一个TaskSet,一个Task中包含多Task,TaskSet的数量与该阶段最后一个RDD的分区数相同。
- Task:分发到Executor上的工作任务,是Spark的最小执行单元
- DAGScheduler:DAGScheduler是将DAG根据宽依赖将切分Stage,负责划分调度阶段并Stage转成TaskSet提交给TaskScheduler
- TaskScheduler:TaskScheduler是将Task调度到Worker下的Exexcutor进程,然后丢入到Executor的线程池的中进行执行
Spark中重要角色
- Master :是一个Java进程,接收Worker的注册信息和心跳、移除异常超时的Worker、接收客户端提交的任务、负责资源调度、命令Worker启动Executor。
- Worker :是一个Java进程,负责管理当前节点的资源管理,向Master注册并定期发送心跳,负责启动Executor、并监控Executor的状态。
- SparkSubmit :是一个Java进程,负责向Master提交任务。
- Driver :是很多类的统称,可以认为SparkContext就是Driver,client模式Driver运行在SparkSubmit进程中,cluster模式单独运行在一个进程中,负责将用户编写的代码转成Tasks,然后调度到Executor中执行,并监控Task的状态和执行进度。
- Executor :是一个Java进程,负责执行Driver端生成的Task,将Task放入线程中运行。
Spark和Yarn角色对比