作者:申国骏
性能分析工具
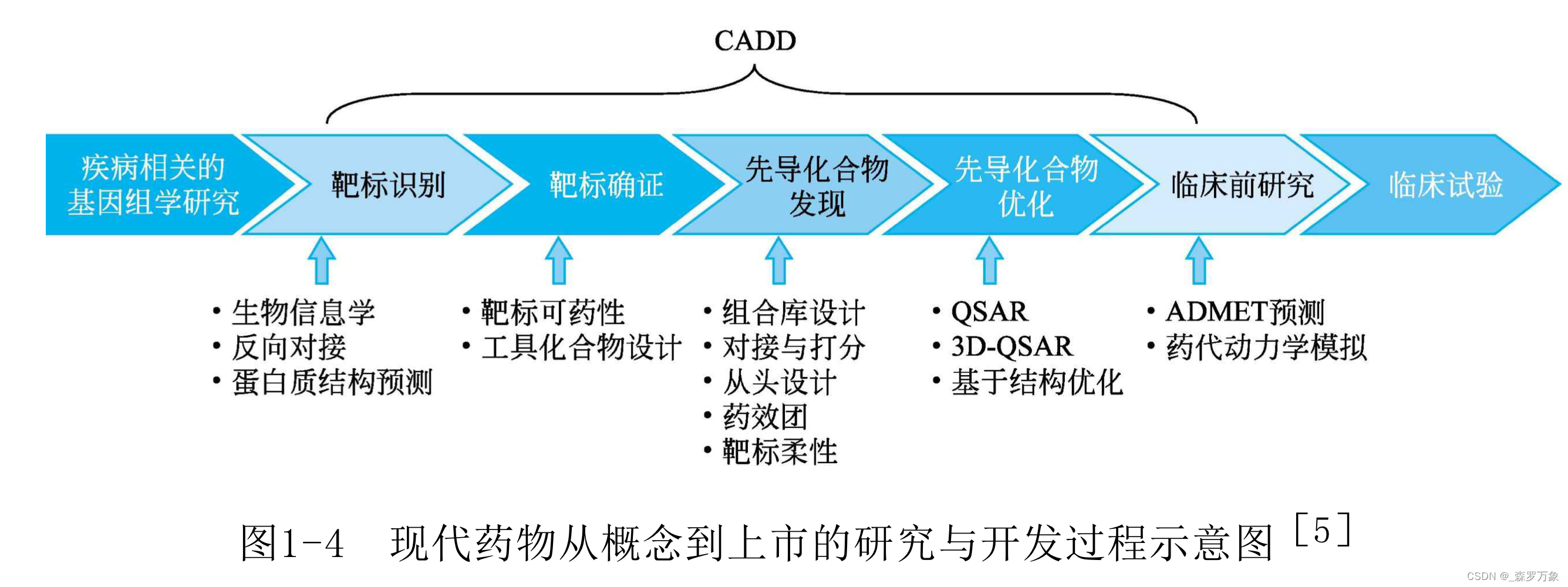
首先我们来学习一下如何使用性能分析的工具。我们从一个具体的例子出发,就是如何分析应用启动的性能。
Android Profiler
配置
我们来先看看Android Profiler。为了能在应用一启动就能马上捕捉到分析数据,我们需要按照下面的步骤配置一下:
- 选择 Run -> Edit Configurations

- 在设置里面选择Profiling的tab,然后选中Start recording CPU activity on startup。注意这里选择的Sample Java Methods,表示可以定位到Java代码。其他选项的含义查看 cpu-profiler#configurations 。 如果想有更详细的信息的话,可以选中Enable advanced profiling。

- 在配置完之后选择Run -> Profiler

在页面启动完成之后停止监测,可以得到启动过程的CPU、内存网络和电量消耗信息,如下图:

CPU监控
分析过程
点击进入CPU模块

可以选择线程,并看到线程的具体代码耗时。 如以下例子

绿色表示我们写的代码耗时,我们可以选择主线程进行观察。这里显示在Applicaiton onCreate过程中需要耗费620ms。其中比较耗时的方法是registerByCourseKey和initYouzanSDK。并且通过Call Chart视图不断的往下看可以看出导致这个方法耗时的具体原因


通过这样不断的往下分析,就能大致定位到启动CPU耗时的原因。下面我们举一个具体的优化例子。
优化例子
优化前:

如果上图所示,在启动过程中RxBroadcast的时候带来了较大的耗时

查看代码:
private fun initBroadcast() {
val filter = IntentFilter()
……
disposables.add(RxBroadcast.fromLocalBroadcast(context, filter)
.subscribe({ intent ->
……
},
{ throwable: Throwable ->
……
}
))
}
确实在initBroadcast使用了RxBroadcast.fromLocalBroadcast()方法,我们尝试使用LocalBroadcastManager.registerReceiver代替。修改为如下代码:
private fun initBroadcast() {
val filter = IntentFilter()
……
LocalBroadcastManager.getInstance(context).registerReceiver(broadcastReceiver, filter)
}
优化后重新进行启动CPU分析:

可以看出初始化的时间比优化前减少了90ms。由此我们也可以得到结论,使用RxBroadcast虽然比较炫酷,但是这是一个比较耗时的行为,因此应该尽量减少RxBroadcast的使用。
注意事项
- 需要注意的是这里的耗时有些是在CPU处于Sleep状态下的。 在Sleep状态表示CPU被其他线程占用,这个时候需要分析主线程Sleep状态下其他线程的情况。例如:

这里显示主线程在00:06左右的时间处于Sleeping状态,这个时候查看其他线程的CPU占用

发现在MemoryAg的线程在占用CPU资源,这种情况下不应该认为对应的主线程方法耗时,而是要考虑例如内存回收或者其他线程占用了CPU资源的情况。
- 还需要注意不是每次点击"Profiler"都会正常把信息记录下来,偶尔会出现应用闪退的情况,这可能是Android Studio的Bug或者是日志太大了的问题。这种情况不要灰心,多试几次就会好。
Perfetto UI
使用过程
在Android 10的手机上,开发者模式新增加了一个“系统跟踪”的功能,我们首先将开发者模式下的“系统跟踪”打开:


我们也可以从“类别”选项中选择我们关注的信息类别:

设置完之后我们会发现下拉快捷选项多了个棒棒糖形状的图标

这个时候杀掉我们需要调试的应用,然后点击开启棒棒糖,接着打开应用,等待应用完全打开之后,再点击一次棒棒糖,结束录制。


然后我们保存录制后的文件,后缀为“.perfetto-trace” 然后我们在 perfetto ui 网站上选择Open trace file上传刚刚得到的文件

渲染之后我们可以得到类似于之前systrace的分析,通过Perfetto UI我们可以更加容易操控

分析过程
首先我们需要知道,通过“系统跟踪”得到的结果是类似于在Android Studio里面Profiler选择“Trace System Calls”的结果,我们可以看到系统中所有CPU在时间轴的所有运行任务。并且我们也可以看到系统所有的进程以及进程中所有的线程任务。

我们展开Perfetto UI的调试应用里面的主线程:

可以看到线程中每个步骤的耗时。我们可以通过不断的放大来查看每个时间段的系统调用。
优化例子
优化前:


可以看出在首页inflate的过程中,有个一个“bg_simple_dict_blueriver.jpg”的图标耗时了29ms加载。分析其所在的代码:
<ImageView
android:id="@+id/iv_simple_dict_bg"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:src="@drawable/bg_simple_dict_blueriver"
android:scaleType="centerCrop"
android:visibility="gone"
/>
由于这个图片只会在网络不畅的时候作为placeholder存在,因此这里简单的做法可以将
android:src="@drawable/bg_simple_dict_blueriver"
更好的办法也可以将ImageView改为ViewStub引入,在有需要的时候再渲染出来,节省布局渲染时间。 优化后:

可以看出,在优化后inflate的时间由原来的118ms降低到了103ms,并且在inflate过程中也没有了bg_simple_dict_blueriver.jpg图片加载的过程。
启动优化
有了以上的Sample Java Methods以及Trace System Calls分析,我们可以得到从宏观代码层面以及微观CPU执行层面的启动任务耗时。
Proguard & R8

除了业务的懒加载处理之外,我们可以看到dex文件的加载时间占据了大部分的启动时间。dex的加载时间跟代码量级有关。由于长期的历史引入了大量了第三方库以及本身业务增长带来的代码量增加,我们dex加载的速度也越来越慢。为了解决dex加载慢的问题,我们可以通过两个方面:首先是处理对dex加载有较大影响的加固过程,这个可以跟杭研进行沟通处理。第二就是在代码中加入代码压缩和混淆。
代码压缩和混淆可以使得dex文件变小,从而减少dex文件加载的时间。但是从零开始加入代码压缩和混淆是一个非常艰巨的过程,因为代码压缩和混淆后会导致很容易发生ClassNotFoundException以及NoSuchMethodError,并且会对诸如push、序列化等依赖类名以及属性名的代码失效。加入代码压缩和混淆需要额外的细心和较大的工作量。
在加入代码压缩和混淆的过程中,我们总结了以下的方法步骤:
本地代码
- 检查所有使用注解的代码,加入proguard 规则
- 检查所有JNI相关代码,加入proguard 规则
- 检查所有使用反射的代码,加入proguard 规则
- 检查所有序列化以及会使用Json转换为Modle的代码,加入proguard 规则
- 检查所有根据类名来使用的代码,例如Push等,加入proguard 规则
- 要求以后代码重构需要对Proguard进行相应改变
- 要求新增的代码需要添加Proguard规则
三方代码
- 判断External Libraries中的三方库引用是否是release依赖或者debug依赖,如果是的话继续
- 判断lib库是否为目前代码所需要的,如果引用了没有使用或者引用了目前代码上所有使用的地方都已经不再使用,则清理这个lib并清理相关没有用到的代码
- 若果lib库为目前代码所需要的,到该lib库的官网查找相应的proguard规则,并粘贴到proguard-rules.pro文件中
- 如果该lib官网库没有相应proguard规则,则观察lib库是否有用到native代码、annotation或者反射这种需要proguard处理的地方,有的话添加相应规则
- 添加完proguard规则之后,找到目前项目中使用到这个库的地方,尝试一下是否会有崩溃出现
- 如果有崩溃出现,根据崩溃提示增加相应proguard规则
为了帮助到大家更好的全面清晰的掌握好性能优化,准备了相关的学习路线以及核心笔记(还该底层逻辑):https://qr18.cn/FVlo89 大家可以进行参考学习:
Android性能分析与优化实战进阶手册