起因
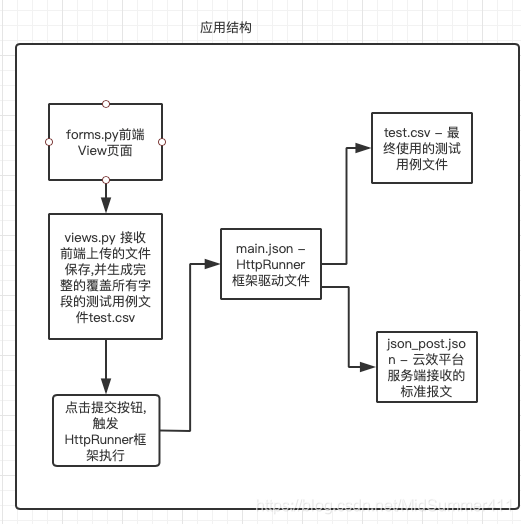
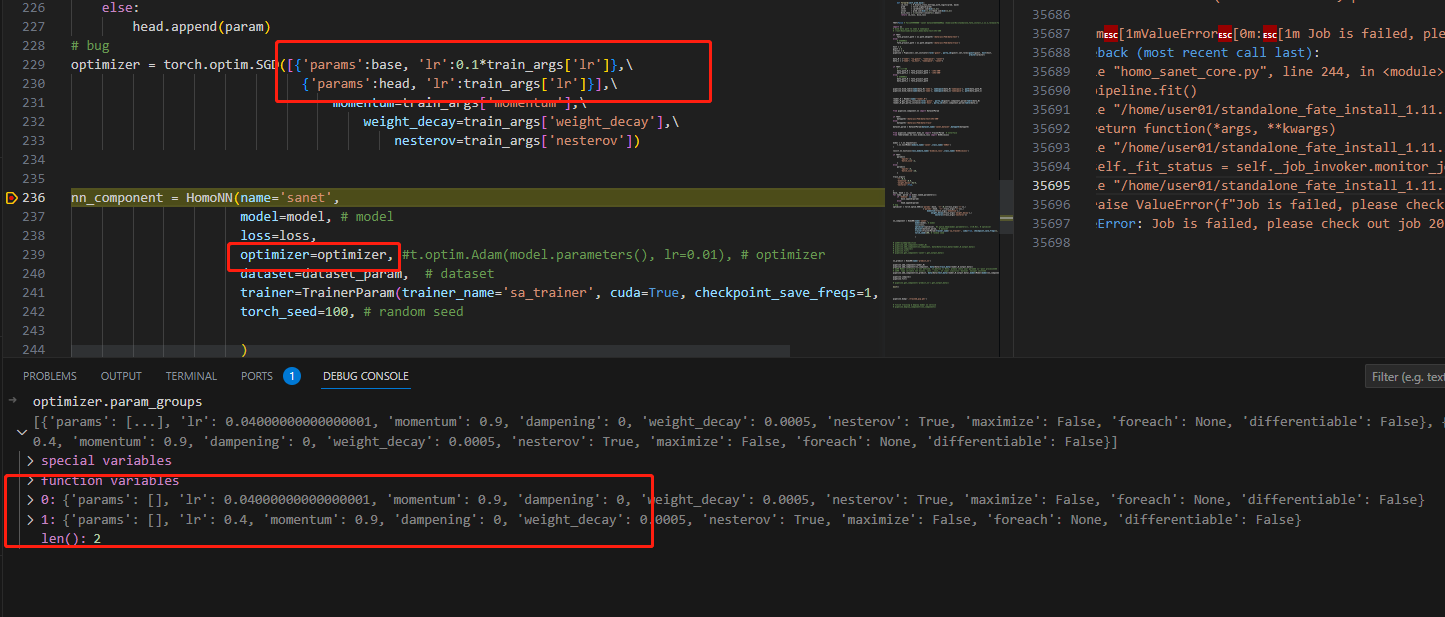
使用torch的optimizer添加了2组parameter,传参进入FATE的trainer后,optimizer被改变,且FATE框架无提示。
代码差不多是下面这样:
# optimizer中加入2组优化参数(param)
optimizer = torch.optim.SGD([{'params':base, 'lr':0.1*train_args['lr']},\
{'params':head, 'lr':train_args['lr']}])
nn_component = HomoNN(name='sanet',
model=model, # model
loss=loss,
optimizer=optimizer, # 传入trainer后
dataset=dataset_param, # dataset
trainer=TrainerParam(trainer_name='sa_trainer', cuda=True, checkpoint_save_freqs=1, **params),
torch_seed=100, # random seed
)
# optimizer的param_group在trainer中就只变成1组了,其他的不见了。
github上反馈给社区了:我提的issue
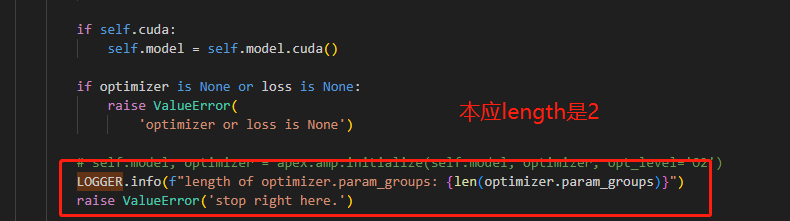 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I9vA6ec9-1688611983896)(https://user-images.githubusercontent.com/31330044/251026326-46379778-8b50-4ebc-a486-d9b4f27fdbf4.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I9vA6ec9-1688611983896)(https://user-images.githubusercontent.com/31330044/251026326-46379778-8b50-4ebc-a486-d9b4f27fdbf4.png)]
解决
解决方法是不使用FATE给的接口,而自己直接在trainer里面提供optimizer。
class Trainer():
def init(opt_name='sgd'):
xxxx
def train():
self.optimizer = make_optimizer(self.model, self.opt_name)
可以在trainer中自己实现,提交任务时不提供optimizer参数即可.


![NSS [NSSCTF 2022 Spring Recruit]ezgame](https://img-blog.csdnimg.cn/img_convert/06a6d4cde1d831a1cdccd0d9793403b9.png)