Okhttp是Android开发常用的一个网络请求框架,下面将按照自己的理解将okhttp分为三条主线进行分析。
文章目录
- 使用方式
- OkHttp第一条主线:请求发送到哪里去了?
- OkHttp第二条主线:请求是如何被消费的?
- OkHttp第三条主线:请求是如何被维护的?
- 常见问题
使用方式
OkHttpClient okHttpClient= new OkHttpClient.Builder().build();
Request request=new Request.Builder().url("").build();
Call call=okHttpClient.newCall(request);
call.enqueue(new Callback() {
@Override
public void onFailure(@NotNull Call call, @NotNull IOException e) {
}
@Override
public void onResponse(@NotNull Call call, @NotNull Response response) throws IOException {
}
});
OkHttp第一条主线:请求发送到哪里去了?
首先先看call.enqueue方法,在call接口中
/**
* Schedules the request to be executed at some point in the future.
*
* <p>The {@link OkHttpClient#dispatcher dispatcher} defines when the request will run: usually
* immediately unless there are several other requests currently being executed.
*
* <p>This client will later call back {@code responseCallback} with either an HTTP response or a
* failure exception.
*
* @throws IllegalStateException when the call has already been executed.
*/
void enqueue(Callback responseCallback);
再看一下call接口的实现类
@Override public void enqueue(Callback responseCallback) {
synchronized (this) {
if (executed) throw new IllegalStateException("Already Executed");
executed = true;
}
captureCallStackTrace();
eventListener.callStart(this);
client.dispatcher().enqueue(new AsyncCall(responseCallback));
}
在进去看一下client.dispatcher().enqueue(new AsyncCall(responseCallback))方法
private int maxRequests = 64;
private int maxRequestsPerHost = 5;
synchronized void enqueue(AsyncCall call) {
if (runningAsyncCalls.size() < maxRequests && runningCallsForHost(call) < maxRequestsPerHost) {
runningAsyncCalls.add(call);
executorService().execute(call);
} else {
readyAsyncCalls.add(call);
}
}
可以发现在dispatcher类中有两个队列,一个是runningSyncCalls,一个是readyAyncCalls,也就是运行中的队列和等待中的队列。
并且有判断条件,当运行中队列请求数小于64并且访问同一目标机器的数量小于5,将请求放入运行中的队列,不然放入等待队列。
但是你会发现一个问题,假设我们有84个请求,那么我们会将64条请求放入运行中队列,剩下的86-64条放到等待中的队列,那么等待中的队列要等到什么时候进行处理呢?如果两个队列中都有数据再来20条数据又要怎么办?这个时候我们再看第二条主线。
OkHttp第二条主线:请求是如何被消费的?
点进行看executorService().execute(call)
public interface Executor {
/**
* Executes the given command at some time in the future. The command
* may execute in a new thread, in a pooled thread, or in the calling
* thread, at the discretion of the {@code Executor} implementation.
*
* @param command the runnable task
* @throws RejectedExecutionException if this task cannot be
* accepted for execution
* @throws NullPointerException if command is null
*/
void execute(Runnable command);
}
可以发现重点在与我们传入的call,回到
synchronized void enqueue(AsyncCall call) {
if (runningAsyncCalls.size() < maxRequests && runningCallsForHost(call) < maxRequestsPerHost) {
runningAsyncCalls.add(call);
executorService().execute(call);
} else {
readyAsyncCalls.add(call);
}
}
再观察AsyncCall
final class AsyncCall extends NamedRunnable{
private final Callback responseCallback;
AsyncCall(Callback responseCallback) {
super("OkHttp %s", redactedUrl());
this.responseCallback = responseCallback;
}
String host() {
return originalRequest.url().host();
}
Request request() {
return originalRequest;
}
RealCall get() {
return RealCall.this;
}
@Override protected void execute() {
boolean signalledCallback = false;
try {
Response response = getResponseWithInterceptorChain();
if (retryAndFollowUpInterceptor.isCanceled()) {
signalledCallback = true;
responseCallback.onFailure(RealCall.this, new IOException("Canceled"));
} else {
signalledCallback = true;
responseCallback.onResponse(RealCall.this, response);
}
} catch (IOException e) {
if (signalledCallback) {
// Do not signal the callback twice!
Platform.get().log(INFO, "Callback failure for " + toLoggableString(), e);
} else {
eventListener.callFailed(RealCall.this, e);
responseCallback.onFailure(RealCall.this, e);
}
} finally {
client.dispatcher().finished(this);
}
}
}
再点进去看一下继承类NamedRunnable
public abstract class NamedRunnable implements Runnable {
protected final String name;
public NamedRunnable(String format, Object... args) {
this.name = Util.format(format, args);
}
@Override public final void run() {
String oldName = Thread.currentThread().getName();
Thread.currentThread().setName(name);
try {
execute();
} finally {
Thread.currentThread().setName(oldName);
}
}
protected abstract void execute();
}
发现run()方法中会执行execute()方法,且这里的execute方法是抽象的
那么也就表示我们在执行 executorService().execute(call);的时候其实会调用AsyncCall的execute()方法。说明我们把请求放在运行中队列的时候会立马放入线程池执行。
@Override protected void execute() {
boolean signalledCallback = false;
try {
Response response = getResponseWithInterceptorChain();
if (retryAndFollowUpInterceptor.isCanceled()) {
signalledCallback = true;
responseCallback.onFailure(RealCall.this, new IOException("Canceled"));
} else {
signalledCallback = true;
responseCallback.onResponse(RealCall.this, response);
}
} catch (IOException e) {
if (signalledCallback) {
// Do not signal the callback twice!
Platform.get().log(INFO, "Callback failure for " + toLoggableString(), e);
} else {
eventListener.callFailed(RealCall.this, e);
responseCallback.onFailure(RealCall.this, e);
}
} finally {
client.dispatcher().finished(this);
}
}
这里的代码也就是代表是请求怎么访问服务器的。点进行看一下getResponseWithInterceptorChain,getResponseWithInterceptorChain是处理请求的方法。
Response getResponseWithInterceptorChain() throws IOException {
// Build a full stack of interceptors.
List<Interceptor> interceptors = new ArrayList<>();
interceptors.addAll(client.interceptors());
interceptors.add(retryAndFollowUpInterceptor);
interceptors.add(new BridgeInterceptor(client.cookieJar()));
interceptors.add(new CacheInterceptor(client.internalCache()));
interceptors.add(new ConnectInterceptor(client));
if (!forWebSocket) {
interceptors.addAll(client.networkInterceptors());
}
interceptors.add(new CallServerInterceptor(forWebSocket));
Interceptor.Chain chain = new RealInterceptorChain(interceptors, null, null, null, 0,
originalRequest, this, eventListener, client.connectTimeoutMillis(),
client.readTimeoutMillis(), client.writeTimeoutMillis());
return chain.proceed(originalRequest);
}
这一块运用到了责任链模式,假设客户端的请求到达服务端,中间有3个节点要求,需要满足个节点的要求才能到达服务器,如果你第1个节点需要验证的东西你通不过,那么就到达不了第2个节点,在第1个节点就被拦截了。使用这种设计模式的话,可以节省很多无用功,做到优化。
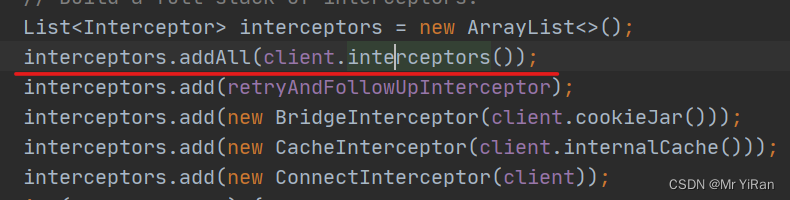

还有可以添加自己定义的拦截器,增加框架的拓展性。
OkHttp第三条主线:请求是如何被维护的?
@Override protected void execute() {
boolean signalledCallback = false;
try {
Response response = getResponseWithInterceptorChain();
if (retryAndFollowUpInterceptor.isCanceled()) {
signalledCallback = true;
responseCallback.onFailure(RealCall.this, new IOException("Canceled"));
} else {
signalledCallback = true;
responseCallback.onResponse(RealCall.this, response);
}
} catch (IOException e) {
if (signalledCallback) {
// Do not signal the callback twice!
Platform.get().log(INFO, "Callback failure for " + toLoggableString(), e);
} else {
eventListener.callFailed(RealCall.this, e);
responseCallback.onFailure(RealCall.this, e);
}
} finally {
client.dispatcher().finished(this);
}
}
在execute()方法中点进去 client.dispatcher().finished(this);
/** Used by {@code AsyncCall#run} to signal completion. */
void finished(AsyncCall call) {
finished(runningAsyncCalls, call, true);
}
再进来
private <T> void finished(Deque<T> calls, T call, boolean promoteCalls) {
int runningCallsCount;
Runnable idleCallback;
synchronized (this) {
if (!calls.remove(call)) throw new AssertionError("Call wasn't in-flight!");
if (promoteCalls) promoteCalls();
runningCallsCount = runningCallsCount();
idleCallback = this.idleCallback;
}
if (runningCallsCount == 0 && idleCallback != null) {
idleCallback.run();
}
}
有个promoteCalls()方法
private void promoteCalls() {
if (runningAsyncCalls.size() >= maxRequests) return; // Already running max capacity.
if (readyAsyncCalls.isEmpty()) return; // No ready calls to promote.
for (Iterator<AsyncCall> i = readyAsyncCalls.iterator(); i.hasNext(); ) {
AsyncCall call = i.next();
if (runningCallsForHost(call) < maxRequestsPerHost) {
i.remove();
runningAsyncCalls.add(call);
executorService().execute(call);
}
if (runningAsyncCalls.size() >= maxRequests) return; // Reached max capacity.
}
}
如果运行中的队列个数已经大于等于maxRequests64,则直接返回,如果等待中的队列为空,那么也直接返回。不然的话就去循环等待中的队列,把等待中的队列移除并将其放入运行中的队列,再和上次请求消费完一样,放入线程池进行处理。
说明了当某个请求被消费掉之后,会回来检查等待队列中是否有数据,如果有数据,则将数据从等待中移除,然后放入运行中,再直接交给线程池进行处理。
常见问题
下面是几个常见的问题,如果有错误欢迎指正!
- 为什么运行中的队列最大是64?
因为okhttp在写源码的时候,大量参考了浏览器的源码 默认都是64,避免手机和服务器建立过多的线程造成内存溢出 ;而且这个数是可以改的 - 访问统一目标机器数量为什么是5?
这可能是出于对服务器压力的考虑。如果同一个手机对同一个服务器的请求个数太多,可能会影响服务器的性能和稳定性。这个数字也是OkHttp的开发者根据经验和实践设定的,没有一个确定的理由或标准。 - 为什么设计两个队列,能不能用一个队列?
等待队列(readyAsyncCalls):用于存放还未执行的异步请求,等待调度器分配线程执行 。
运行队列(runningAsyncCalls):用于存放正在执行的异步请求,当运行中队列请求数小于64并且访问同一目标机器的数量小于5才能将请求放入运行中队列,限制最大并发数 。
Dispatcher类负责调度和分发这两个队列中的请求,以及复用和管理线程池
okhttp设计两个队列的原因是为了完成调度和复用,以及控制执行和分发,这样可以保证请求的顺序和效率,以及避免资源的浪费和冲突。一个队列可能无法满足这些需求。 - 队列为什么用Deque?能不能用arraylist?hashmap?普通数组行不行?
Deque:双端队列,可以在头部和尾部进行数据的访问和增删。
ArrayList:基于数组实现的列表,元素有序且可以重复,支持随机访问。
HashMap:基于数组和键值对实现的映射,元素无序且键不能重复,支持根据键快速查找值。
数组:一种基本的数据结构,元素有序且可以重复,支持根据下标快速访问。
队列为什么用Deque?因为Deque可以实现先进先出或后进先出的操作,适合用于存储请求等待执行。
如果需要存储有序的元素,并且不需要根据键查找值,可以用ArrayList或数组。如果需要存储无序的键值对,并且需要根据键查找值,可以用HashMap。但是这些数据结构可能不如Deque方便和高效地进行头尾的操作。 - 为什么线程池中,默认的队列使用SynchronousQueue?
SynchronousQueue是一个没有容量的阻塞队列,它可以保证每个提交的任务都会被执行,而不会被缓存或丢弃。 可以支持公平性策略,让等待时间最长的生产者或消费者优先执行。可以避免线程池中的线程过多或过少,提高资源利用率和响应速度 - 使用了什么设计模式?
OkHttp中最直接的责任链模式的使用就是Interceptor的使用。书写简单漂亮,使用也非常方便,只需要OkHttpClient.Builder调用addInterceptor()方法,将实现了Interceptor接口的类添加进去即可,扩展性和可定制化都非常方便。
OkHttpClient httpClient = new OkHttpClient.Builder()
.addInterceptor(new HeaderInterceptor())
.addInterceptor(new LogInterceptor())
.addInterceptor(new HttpLoggingInterceptor(logger)
......
.readTimeout(30, TimeUnit.SECONDS)
.cache(cache)
.build();
OkHttp中最直接的建造者模式的使用就是XXBuilder的使用。在OkHttp中的OkHttpClient、Request、Response、HttpUrl、Headers、MultipartBody等大量使用了类似的建造者模式。
public class OkHttpClient implements Cloneable, Call.Factory, WebSocket.Factory {
......
public static final class Builder {
Dispatcher dispatcher;
@Nullable Proxy proxy;
int callTimeout;
int connectTimeout;
......
public OkHttpClient build() {
return new OkHttpClient(this);
}
}
}
public class Headers {
......
public static final class Builder {
final List<String> namesAndValues = new ArrayList<>(20);
......
public Headers build() {
return new Headers(this);
}
}
}
public class Request {
......
public static class Builder {
@Nullable HttpUrl url;
String method;
Headers.Builder headers;
@Nullable RequestBody body;
......
public Request build() {
return new Request(this);
}
}
}
将对象的创建与表示相分离,Builder负责组装各项配置参数,并且生成对象,目标对象则对外提供接口,符合类的单一原则。
工厂模式相对于建创者模式的生成对象的过程更复杂,侧重于对象的生成过程,比如
public interface Call extends Cloneable {
Request request();
Response execute() throws IOException;
void enqueue(Callback responseCallback);
void cancel();
boolean isExecuted();
boolean isCanceled();
Call clone();
//创建Call实现对象的工厂
interface Factory {
//创建新的Call,里面包含了Request对象。
Call newCall(Request request);
}
}
public class OkHttpClient implements Cloneable, Call.Factory, WebSocket.Factory {
@Override public Call newCall(Request request) {
return RealCall.newRealCall(this, request, false /* for web socket */);
}
}
final class RealCall implements Call {
......
}
在Call接口中,有一个内部工厂Factory接口。这样只要像下面这样就可以了:
实现Call接口,现实相应的功能,RealCall;
使用某个类(OkHttpClient)实现Call.Factory接口,在newCall中返回RealCall对象,就可以了。
- 为什么这么设计?如果是你,还能想到其他更好的设计模式吗?
这些设计模式的目的是为了提高OkHttp的可扩展性、可维护性和可读性。如果是我,我可能会考虑使用观察者模式,让用户可以注册一些回调函数,来监听请求和响应的状态变化。这样可以让用户更方便地处理异步请求和异常情况。 - 每个拦截器设计的意义是什么?
RetryAndFollowUpInterceptor:负责请求失败的时候实现重试重定向功能。
BridgeInterceptor:负责将用户构造的请求转换为向服务器发送的请求,添加一些必要的头部信息。
CacheInterceptor:负责处理缓存逻辑,根据缓存策略和响应头判断是否使用缓存或更新缓存。
ConnectInterceptor:负责建立连接,选择路由,协商协议等。
CallServerInterceptor:负责向服务器发送请求和接收响应,处理GZIP压缩等。 - 为什么使用Socket连接池?好处是什么
okhttp使用Socket连接池的原因是提高性能和效率。连接池可以复用已有的连接,避免频繁地创建和关闭连接,减少请求延迟和网络开销。如果使用HTTP/2协议,连接池还可以多路复用同一主机的请求,进一步提升并发能力。 - 为什么每次请求运行完之后都需要对队列中的请求进行维护?这样设计有什么好处
如果是以前的volley框架的话,他会启动一个线程会有一句代码while(true),代表这个线程一直是死循环。假设客户端一直源源不断向服务器发送请求,那么没问题,但是要是不发送请求,线程一直跑的话,这样的话就会造成浪费。
但是okhttp不一样,假设发送一条请求,会将请求放到线程池,线程池执行去请求服务器,请求完成后会回去检查,如果没有任何请求发送过来,就不可能将请求加入到运行中的队列,也就不可能放到线程池,也不是发送到服务器,使得框架内部是停止状态。不会向while(true)那样源源不断发送请求,使得造成浪费,性能下降。