开头还是介绍一下群,如果感兴趣polardb ,mongodb ,mysql ,postgresql ,redis 等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请联系 liuaustin3 ,在新加的朋友会分到3群(共950人左右 1 + 2 + 3)
POSTGRESQL SQL 查询中经常用到的一些查询使用的查询符号,如 in , exists ,any ,这些查询符号在使用中有什么性能方面的差距,以及在什么场景下适合使用,这应该是一个有意思的话题。
IN EXISTS ANY ,三个条件操作符,分别带有不同的目的
虽然IN 和 EXISTS 本身都是从一个结果集合匹配另一个结果集合中包含相关的数据的问题,但是两个操作符号,对应的操作方法是不同的。
IN 是将外表当做一个结果集,将内表和外表进行一个笛卡尔积,所以如果内表比较小的话,则对于计算的速度是有利的。
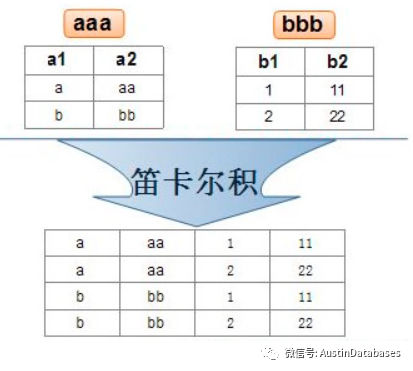
EXISTS 本身是循环外表,简则内表的行是否在外表中存在
我们下面先入为主的用三查询来说明
select sum(pay.amount),sta.staff_id
from payment as pay
left join staff as sta on pay.staff_id = sta.staff_id
left join (select rental_date,rental_id from rental where rental_date > '2000-09-08') as ren on pay.rental_id = ren.rental_id
group by sta.staff_id;
select sum(pay.amount),sta.staff_id
from staff as sta
left join (
select pay_z.amount,pay_z.staff_id
from payment as pay_z where exists (select * from rental as ren where pay_z.rental_id = ren.rental_id and rental_date > '2000-09-08')) as
pay on pay.staff_id = sta.staff_id
group by sta.staff_id;
select sum(pay.amount),pay.staff_id from
(select pay.amount,pay.staff_id,pay.rental_id
from payment as pay where pay.staff_id in (select staff_id from staff)) as pay
left join rental as ren on ren.rental_id = pay.rental_id
where ren.rental_date > '2000-09-08'
group by pay.staff_id;
相关查询已经有预热了查询,所以不存在第一次查询的时间的差异

三个查询的方式 一样的查询结果,这里第一个查询时间最快,但查看执行计划,发现一个问题,虽然查询里面的rental 表并用时间进行了控制,但是在查询计划中并未有相关的表出现。经过分析在rental 表中的最早有时间的rental_date 是在 2005年5月24日所以这个条件相对于整体的SQL 是一个完全包含的结果,通过统计信息的分析,在这条SQL 里面并未涉及 rental 表与整体数据的关联。
left join (select rental_date,rental_id from rental where rental_date > '2005-09-08') as ren on pay.rental_id = ren.rental_id
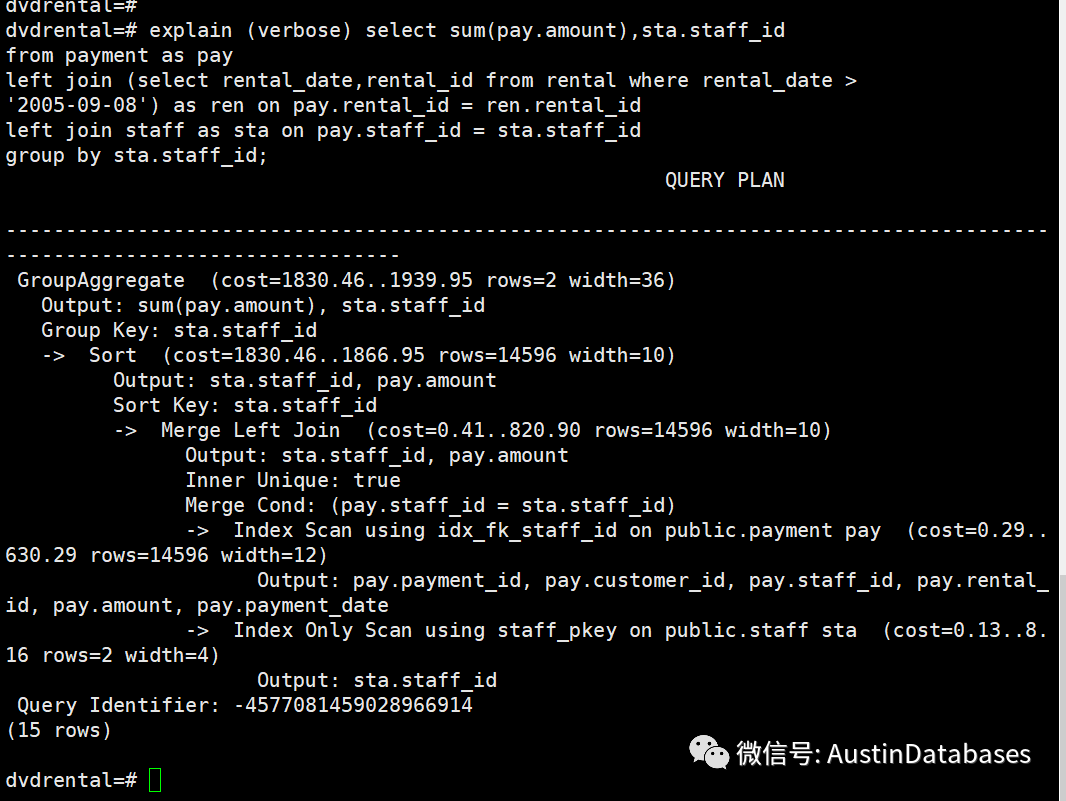
第二种方式,在查询中使用了exists 的方式,这里由于操作方式的变化,根据语句的逻辑整体还是先根据rental_date时间的条件进行过滤然后通过merge 的方式将 payment 表和 rental表进行条件的匹配,并且对于payment 的staff_id进行了排序,然后在和排序的 staff表进行了merge 最后产出的结果。
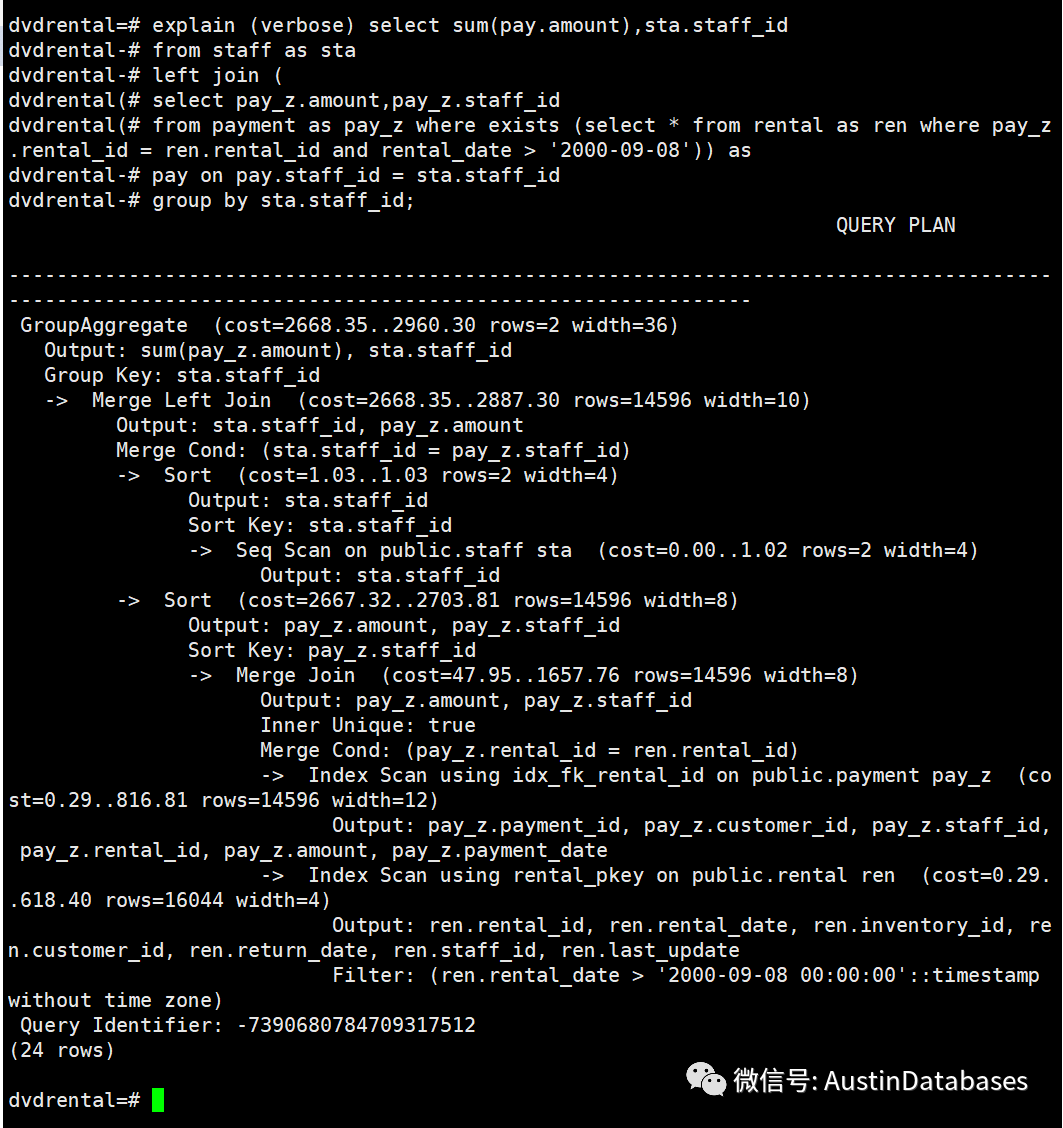
第三种 查询将 EXISTS 替换成 IN 操作,这里的操作明显复杂于 EXISTS ,在rental 和payments 两个表进行merge后,在进行排序然后在对STAFF 表进行排序在对 STAFF 和结果集进行MERGE
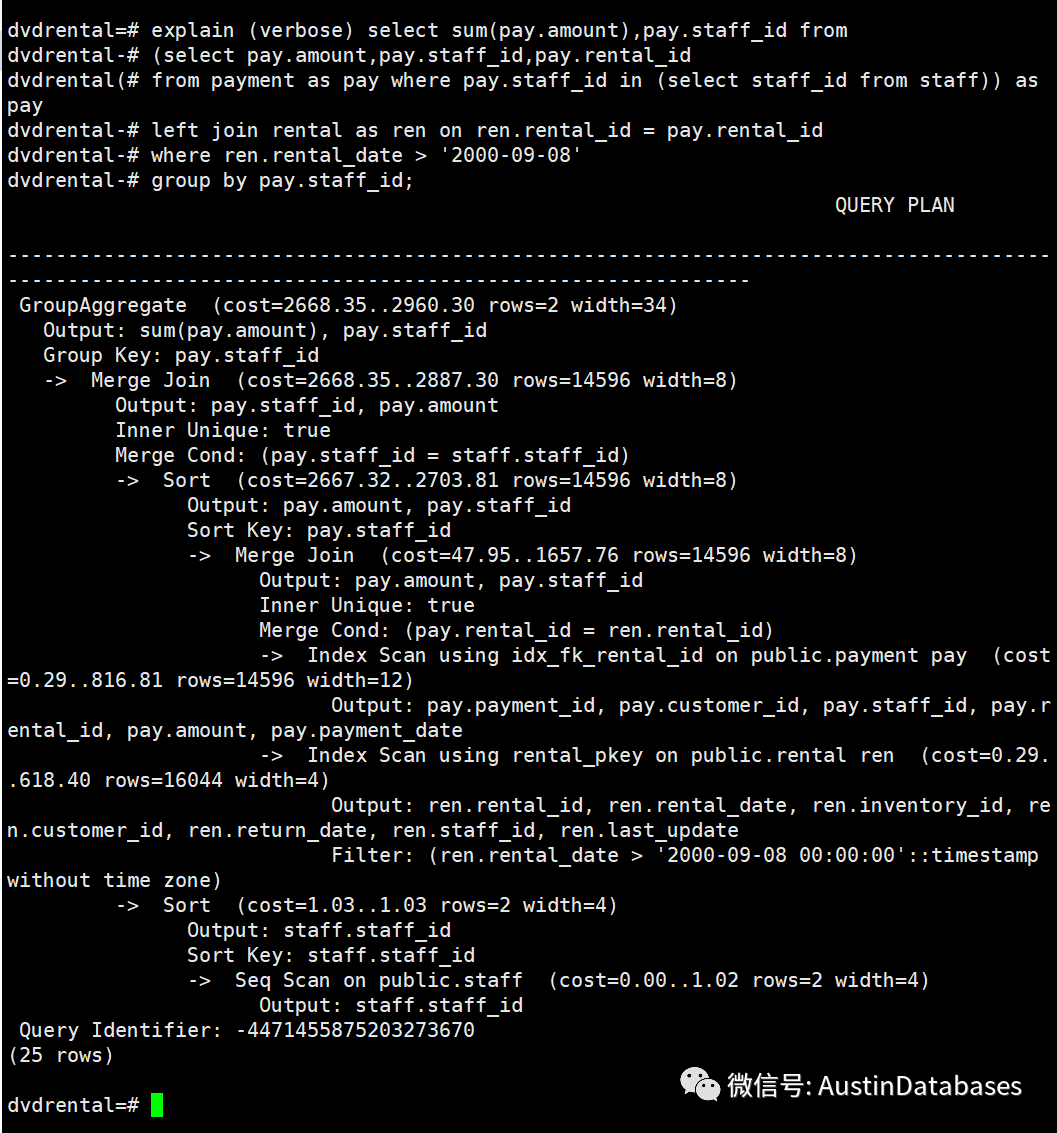
三个语句最终,还是不通过exists 和in 采用单纯的JOIN的方式的语句速度要快,因为他抛弃了rental 表的操作, 而无论采用EXISTS 或 IN 两个执行的过程是类似的,COST的值也是一样的,但是后者有极小的差异,EXISTS 占优。
在POSTGRESQL 还有一个运算操作 ANY ,通过ANY 也可以进行类似 EXISTS 或 IN 通过类似的方式进行,但不同的是 ANY 的操作余地比其他的方案要多,非等值的计算也可以通过ANY来进行。
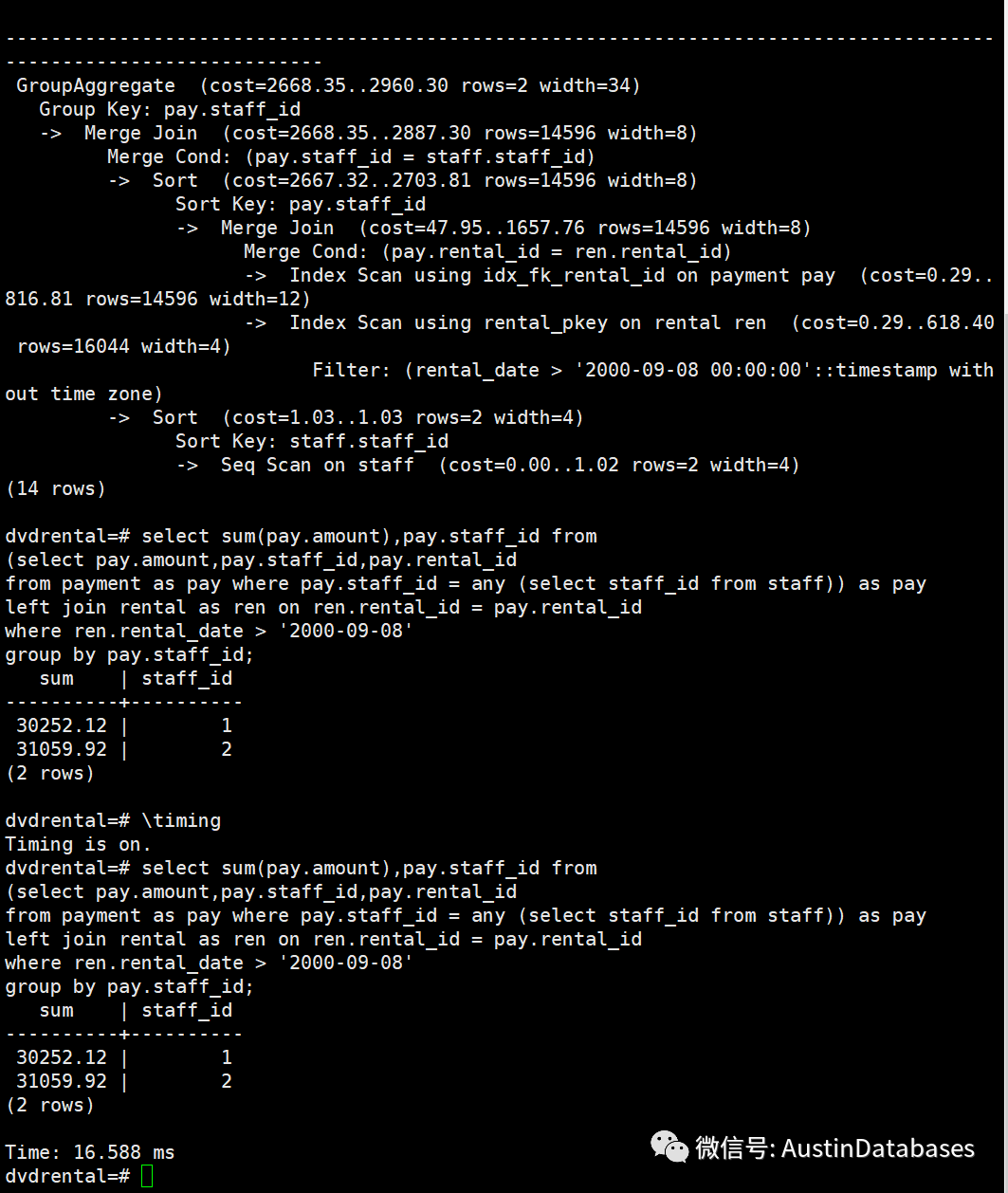
其中查询时间类似EXISTS 的查询时间。
那么下面我们变换一下查询的逻辑将等值的运算变为非等值的运算,看看这样三种方式还是否在查询时间上类似。
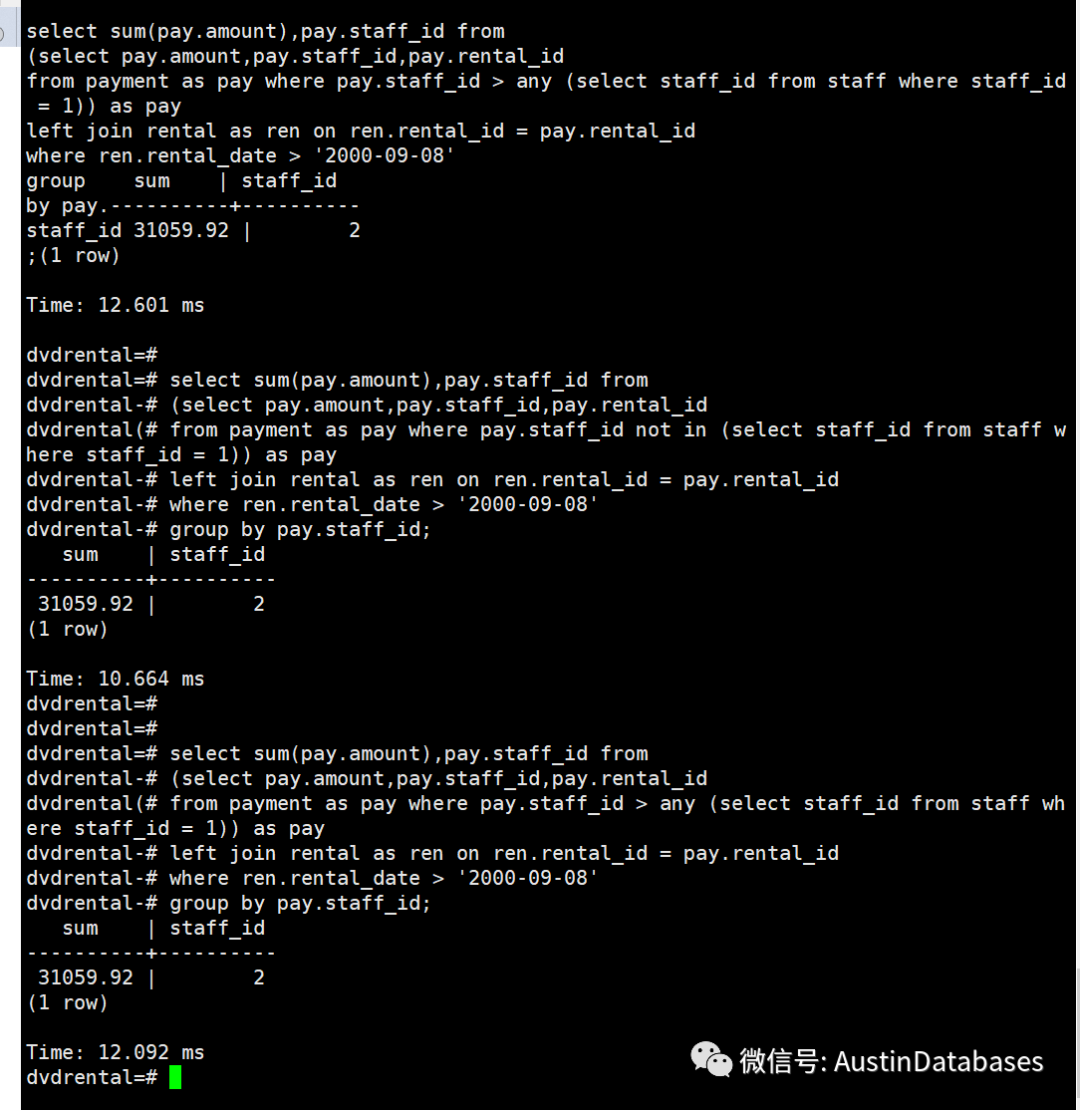
在我们变换了查询的逻辑,将staff_id 等于1的排除在外后,查询的效率里面排名 not in 为速度最快, not exists 排名第二 , any的速度与 not exists 类似。
select sum(pay.amount),sta.staff_id
from staff as sta
inner join (
select pay_z.amount,pay_z.staff_id
from payment as pay_z where not exists (select * from rental as ren where pay_z.rental_id = ren.rental_id and rental_date > '2000-09-08' and pay_z.staff_id = 1)) as
pay on pay.staff_id = sta.staff_id
group by sta.staff_id;
select sum(pay.amount),pay.staff_id from
(select pay.amount,pay.staff_id,pay.rental_id
from payment as pay where pay.staff_id not in (select staff_id from staff where staff_id = 1)) as pay
left join rental as ren on ren.rental_id = pay.rental_id
where ren.rental_date > '2000-09-08'
group by pay.staff_id;
select sum(pay.amount),pay.staff_id from
(select pay.amount,pay.staff_id,pay.rental_id
from payment as pay where pay.staff_id > any (select staff_id from staff where staff_id = 1)) as pay
left join rental as ren on ren.rental_id = pay.rental_id
where ren.rental_date > '2000-09-08'
group by pay.staff_id;
但是这里要说明,not exists 的语句变动最大,从原来的LEFT JOIN 变为了 INNER JOIN 而从人操作的逻辑来看 any 是从思维的角度最容易理解的语句的撰写的方式。
当然这里数据量不一样的情况下,可能NOT IN 就不会占据优势。
总结:
如果你想要排除一组值,NOT IN 通常是一个简单和直观的选择。
如果你想要比较一个值与子查询的结果集中的任何值,ANY 是一种常用的方法。
如果你只是想确定子查询是否返回结果,并且不关心具体的匹配记录,NOT EXISTS 是一个适当的选择。
三种数据的处理方式中,根据数据量和表前后的关系,可以在性能差的时候进行一些语句查询方式的变更,看看是否可以提高相关的语句查询的效率。但根据上面的案例,如果可以直接使用 JOIN ,那么还是直接使用JOIN 的方式在部分情况下,更快。




![Failed to start connector [Connector[HTTP/1.1-8080]]](https://img-blog.csdnimg.cn/7673761ee2c244c9bb129d8a75b399f2.png)