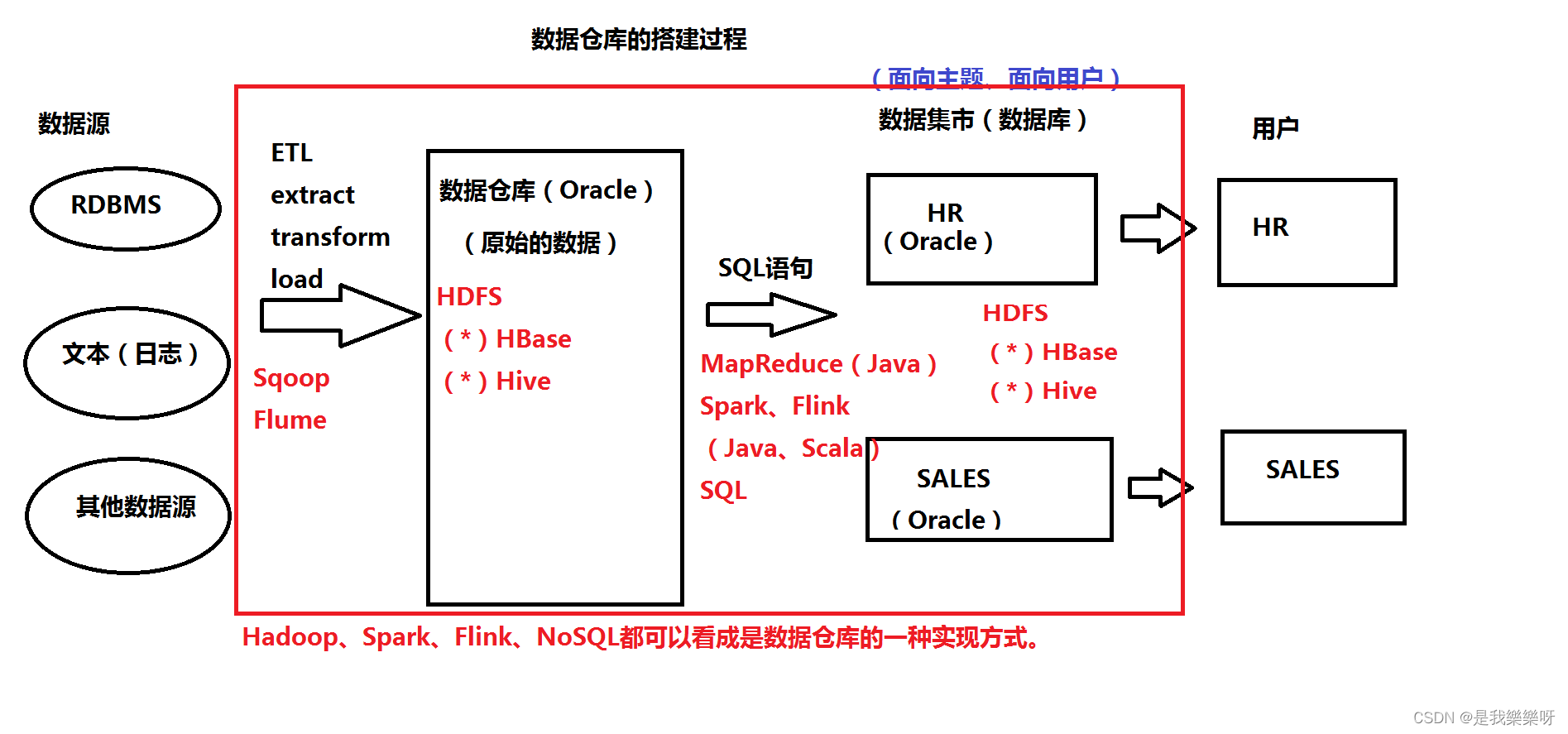
1. SLF4J简介
SLF4J(Simple Logging Facade for Java)是一种日志规范,类似于JDBC,我们常用的日志log4j、logback等都实现了这个规范,所以我们可以直接使用SLF4J的规范来使用日志。

2. logback和log4j
它们是同一个作者开发的,logback是重新编写的内核,在一些关键执行的路径上提升了10倍以上。它也支持了一些新的特性。
这两者虽然作者相同,但log4j早已被托管给Apache基金会维护,并且自从2012年5月之后就没有更新了。而logback从出生开始就是其作者奔着取代log4j的目的开发的,因此一方面logback继承了log4j大量的用法,使得学习和迁移的成本不高,另一方面logback在性能上要明显优于log4j,尤其是在大量并发的环境下,并且新增了一些log4j所没有的功能(如将日志文件压缩成zip包等)
思考一下
为什么要记录日志?
-
程序上线前:代码编写过程
-
测试环节更快的找bug
-
易于观察程序的执行顺序和执行流程
-
-
程序上线之后:
-
用来跟踪定位程序的运行状态
-
用来快速的定位bug
-
3. logback的使用
3.1 引入依赖
logback是遵循slf4j规范的,所以要先引入其依赖.其实logback内部已经关联了slf4j的jar包,其实只需要依赖logback的依赖!
导入坐标:
<!--加入slf4j+logback-->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
</dependency>
<dependency>
<groupId>org.logback-extensions</groupId>
<artifactId>logback-ext-spring</artifactId>
<version>0.1.5</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.26</version>
</dependency>
<!--SLF4J转化包 可以打印spring框架的日志-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>jcl-over-slf4j</artifactId>
<version>1.7.25</version>
</dependency>
如上所示是集成所需要的依赖,其中:
-
第一个logback-classic包含了logback本身所需的slf4j-api.jar、logback-core.jar及logback-classsic.jar。
-
第二个logback-ext-spring是由官方提供的对Spring的支持,它的作用就相当于log4j中Log4jConfigListener;这个listener,网上大多都是用的自己实现的,原因在于这个插件似乎并没有出现在官方文档的显要位置导致大多数人并不知道它的存在。
-
第三个jcl-over-slf4j是用来把Spring源代码中大量使用到的commons-logging替换成slf4j,只有在添加了这个依赖之后才能看到Spring框架本身打印的日志–即info文件中打印出的spring启动日志信息,否则只能看到开发者自己打印的日志。
3.2 引入logback.xml日志配置文件
这里特别注意引入位置(maven工程)在src/main/resource这个根目录下。
<?xml version="1.0" encoding="UTF-8"?>
<configuration debug="false">
<!--定义日志文件的存储地址 logs为当前项目的logs目录 还可以设置为../logs -->
<property name="LOG_HOME" value="logs" />
<!--控制台日志, 控制台输出 -->
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度,%msg:日志消息,%n是换行符-->
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern>
</encoder>
</appender>
<!--文件日志, 按照每天生成日志文件 -->
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!--日志文件输出的文件名-->
<FileNamePattern>${LOG_HOME}/TestWeb.log.%d{yyyy-MM-dd}.log</FileNamePattern>
<!--日志文件保留天数-->
<MaxHistory>30</MaxHistory>
</rollingPolicy>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度%msg:日志消息,%n是换行符-->
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern>
</encoder>
<!--日志文件最大的大小-->
<triggeringPolicy class="ch.qos.logback.core.rolling.SizeBasedTriggeringPolicy">
<MaxFileSize>10MB</MaxFileSize>
</triggeringPolicy>
</appender>
<!-- show parameters for hibernate sql 专为 Hibernate 定制 -->
<logger name="org.hibernate.type.descriptor.sql.BasicBinder" level="TRACE" />
<logger name="org.hibernate.type.descriptor.sql.BasicExtractor" level="DEBUG" />
<logger name="org.hibernate.SQL" level="DEBUG" />
<logger name="org.hibernate.engine.QueryParameters" level="DEBUG" />
<logger name="org.hibernate.engine.query.HQLQueryPlan" level="DEBUG" />
<!--myibatis log configure-->
<logger name="com.apache.ibatis" level="TRACE"/>
<logger name="java.sql.Connection" level="DEBUG"/>
<logger name="java.sql.Statement" level="DEBUG"/>
<logger name="java.sql.PreparedStatement" level="DEBUG"/>
<!-- 日志输出级别 -->
<root level="DEBUG">
<appender-ref ref="STDOUT" />
<appender-ref ref="FILE"/>
</root>
<!-- 指定项目中某个包,当有日志操作行为时的日志记录级别 -->
<!-- com.framework为根包,也就是只要是发生在这个根包下面的所有日志操作行为的权限都是DEBUG -->
<!-- 级别依次为【从高到低】:FATAL > ERROR > WARN > INFO > DEBUG > TRACE -->
<!--
<logger name="com.framework" level="info">
<appender-ref ref="demolog" />
</logger>
-->
</configuration>
4. logback.xml日志配置文件的配置逻辑:
1.先对日志的基本配置声明:包括日志的输出路径— (日志路径,这里是相对路径,web项目idea下会输出到idea 的安装目录下,如果部署到linux上的tomcat下,会输出到tomcat/bin目录 下 ) ,日志级别—(日志的输出级别 由低到高(越高问题越严重)trace->debug->info->warn->error ),日志生成的文件名,日志文件大小等。
2.声明不同appender来具体定义系统不同级别的信息匹配记录,和生成文件的设置,只是定义,并没有引入本应 用就不会用到。
3.为某些特定的包加上上面定义好的appender。用来区别对待系统一般的日志输出模式。
4.将定义好的appender添加到本应用的日志系统中。类是定时任务中先声明任务,在把任务加入到调度里才算这个任务开始被使用了。
5. 理解正确的日志输出级别
很多人都忽略了日志输出级别, 甚至不知道如何指定日志的输出级别. 相对于System.out来说, 日志框架有两个最大的优点就是可以指定输出类别(category)和级别(level). 对于日志输出级别来说, 下面是我们应该记住的一些原则:
ERROR:
系统发生了严重的错误, 必须马上进行处理, 否则系统将无法继续运行. 比如, NPE, 数据库不可用等.
WARN:
系统能继续运行, 但是必须引起关注. 对于存在的问题一般可以分为两类:
-
系统存在明显的问题(比如, 数据不可用),
-
就是系统存在潜在的问题,需要引起注意或者给出一些建议
- (比如, 系统运行在安全模式或者访问当前系统的账号存在安全隐患). 总之就是系统仍然可用,但是最好进行检查和调整.
INFO:
重要的业务逻辑处理完成. 在理想情况下, INFO的日志信息要能让高级用户和系统管理员理解, 并从日志信息中能知道系统当前的运行状态。
比如对于一个机票预订系统来说, 当一个用户完成一个机票预订操作之后, 提醒应该给出"谁预订了从A到B的机票". 另一个需要输出INFO信息的地方就是一个系统操作引起系统的状态发生了重大变化(比如数据库更新, 过多的系统请求).
DEBUG: 主要给开发人员看,
TRACE: 系统详细信息, 主要给开发人员用, 一般来说, 如果是线上系统的话, 可以认为是临时输出, 而且随时可以通过开关将其关闭. 有时候我们很难将DEBUG和TRACE区分开, 一般情况下, 如果是一个已经开发测试完成的系统, 再往系统中添加日志输出, 那么应该设为TRACE级别.
测试应用:
@Slf4j
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations={"classpath:applicationContext.xml"})
@WebAppConfiguration
public class UserControllerTest {
@Test
public void sys(){
log.trace("trace测试{}","trace显示");
log.debug("debug测试{}","debug显示");
log.info("info测试{}","info显示");
log.warn("warn测试{}","warn显示");
log.error("error测试{}","error显示");
}
}
6. 其他补充
如果需要查看mybatis的SQL信息,需要把级别改为debug。
有两种方式:
1、把全局的日志级别设为info,然后把打印SQL相关的日志级别改为debug
<logger name="druid.sql" level="debug"/> <!--指定数据库-->
<logger name="com.xcj.batchdemo" level="debug"/><!--指定某个包下-->
<!-- 日志输出级别 -->
<root level="info">
<appender-ref ref="console"/>
<appender-ref ref="fileInfoLog"/>
<appender-ref ref="fileErrorLog"/>
</root>
2、将全局的日志级别设置为debug,然后将需要屏蔽的框架日志级别设置为info
<logger name="org.springframework" level="INFO" />
<logger name="org.hibernate" level="INFO" />
<logger name="org.apache.ibatis" level="INFO" />
<!-- 控制台日志输出级别 -->
<root level="debug">
<appender-ref ref="console"/>
<appender-ref ref="fileInfoLog"/>
<appender-ref ref="fileErrorLog"/>
</root>
3、mybatis简易常用配置直接显示到控制台:
<?xml version="1.0"?>
<configuration>
<!--定义日志文件的存储地址 logs为当前项目的logs目录 还可以设置为../logs -->
<property name="LOG_HOME" value="logs" />
<!-- ch.qos.logback.core.ConsoleAppender 控制台输出 -->
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>[%-5level] %d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<!-- 日志级别 -->
<root>
<level value="off" />
<appender-ref ref="STDOUT" />
</root>
<logger name="cn" level="DEBUG"/>
</configuration>
如果文件地址放的正确还是提醒xml找不到? 可选择下面的进行填补
配置全局扫描xml
尽量的在pom的build标签中加入如下内容,以扫描到logback.xml文件。
<!--扫描全局xml-->
<resources>
<resource>
<directory>src/main/java</directory>
<includes>
<include>**/*.xml</include>
</includes>
<filtering>true</filtering>
</resource>
<resource>
<directory>src/main/resources</directory>
<includes>
<include>**/*.xml</include>
<include>**/*.properties</include>
</includes>
<filtering>true</filtering>
</resource>
</resources>