1 MMU基本知识
1.1 什么是MMU
MMU是 MemoryManagementUnit 的缩写即,内存管理单元. 针对各种CPU, MMU是个可选的配件. MMU负责的是虚拟地址与物理地址的转换. 提供硬件机制的内存访问授权.(现代 CPU 的应用中,基本上都选择了使用 MMU)
现代的多用户多进程操作系统, 需要MMU, 才能达到每个用户进程都拥有自己的独立的地址空间的目标. 使用MMU, OS划分出一段地址区域,在这块地址区域中, 每个进程看到的内容都不一定一样. 例如MICROSOFT WINDOWS操作系统, 地址4M-2G处划分为用户地址空间. 进程A在地址 0X400000映射了可执行文件. 进程B同样在地址 0X400000映射了可执行文件. 如果A进程读地址0X400000, 读到的是A的可执行文件映射到RAM的内容. 而进程B读取地址0X400000时则读到的是B的可执行文件映射到RAM的内容.
1.2 MMU的产生
许多年以前,当人们还在使用DOS或是更古老的操作系统的时候,计算机的内存还非常小,一般都是以K为单位进行计算,相应的,当时的程序规模也不大,所以内存容量虽然小,但还是可以容纳当时的程序。但随着图形界面的兴起还用用户需求的不断增大,应用程序的规模也随之膨胀起来,终于一个难题出现在程序员的面前,那就是应用程序太大以至于内存容纳不下该程序,通常解决的办法是把程序分割成许多称为覆盖块(overlay)的片段。覆盖块0首先运行,结束时他将调用另一个覆盖块。虽然覆盖块的交换是由OS完成的,但是必须先由程序员把程序先进行分割,这是一个费时费力的工作,而且相当枯燥。人们必须找到更好的办法从根本上解决这个问题。不久人们找到了一个办法,这就是虚拟存储器(virtual memory).虚拟存储器的基本思想是程序,数据,堆栈的总的大小可以超过物理存储器的大小,操作系统把当前使用的部分保留在内存中,而把其他未被使用的部分保存在磁盘上比如对一个16MB的程序和一个内存只有4MB的机器,OS通过选择,可以决定各个时刻将哪4M的内容保留在内存中,并在需要时在内存和磁盘间交换程序片段,这样就可以把这个16M的程序运行在一个只具有4M内存机器上了。而这个16M的程序在运行前不必由程序员进行分割。
1.3 MMU的作用
- 将虚拟地址翻译成为物理地址,然后访问实际的物理地址(地址翻译)
- 访问权限控制(内存保护)
1.3.1 地址翻译
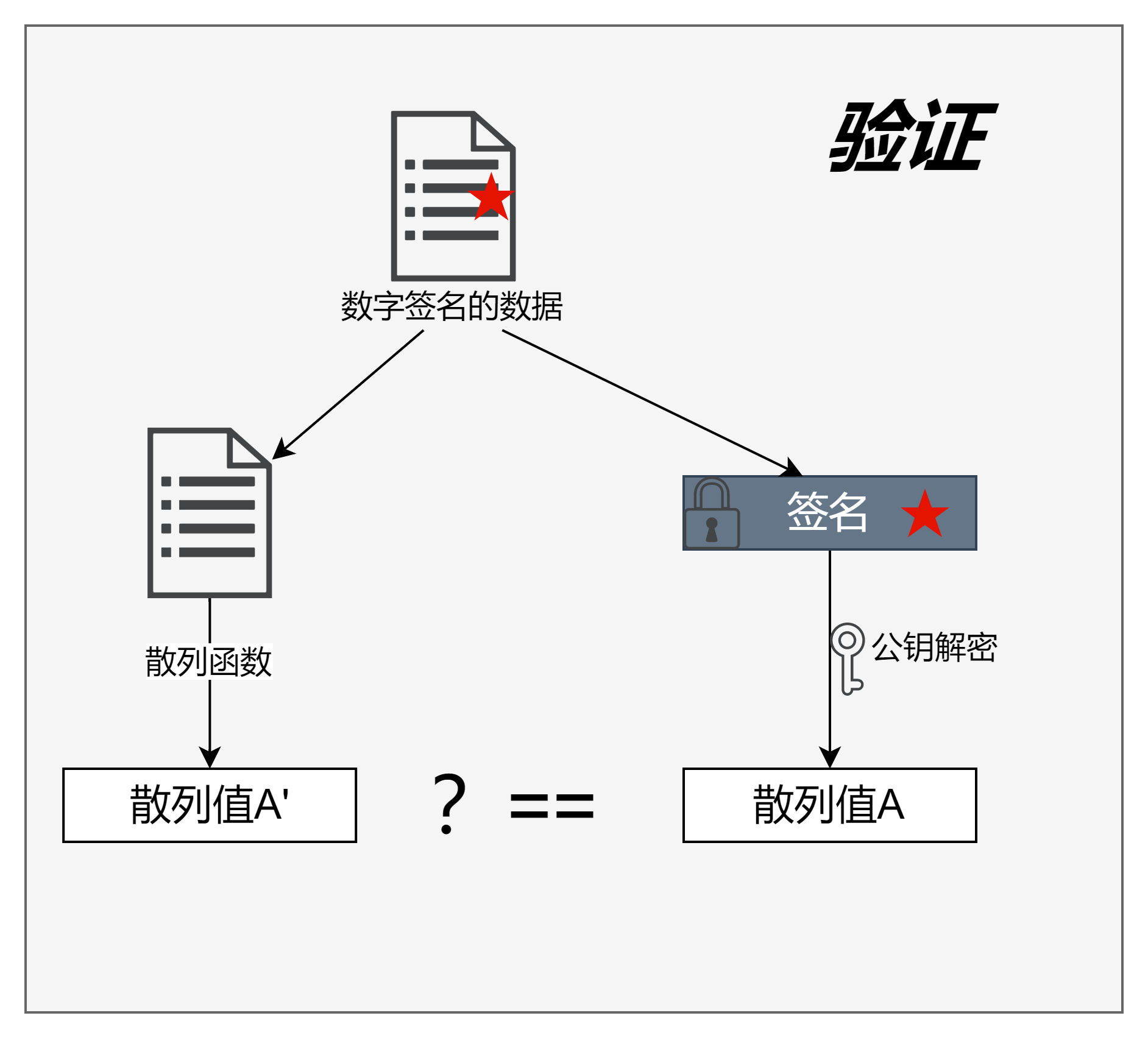
在处理器上一般会运行一个操作系统,如Linux,用户编写的源程序需要经过编译、链接得到可执行文件,然后被操作系统加载执行。编译、链接的过程在第2章实验环境搭建中有过描述,在链接的时候需要指定一个链接描述脚本,链接描述脚本有很多作用,其中一项是控制可执行文件中Section和符号的内存布局,也就是控制可执行程序在内存中是如何放置的,操作系统会按照可执行文件的要求将其加载到内存对应地址并执行。假如用户A编写了程序ProgramA,并且ProgramA占用的内存空间是0x100-0x200,用户B编写了程序ProgramB,并且ProgramB要求的内存空间也是0x100-0x200,这是完全有可能的,因为给操作系统提供程序的用户很多,不可能限定每个用户使用不同部分的内存。这样当ProgramA被加载执行时,ProgramB就不能被加载执行,一旦ProgramB也被加载了就会破坏ProgramA的执行,因为后者会覆盖ProgramA占用的内存。为了解决这个问题,将操作系统和处理器都做了修改,添加了MMU,在其中进行地址翻译,程序加载入内存的时候为其建立地址翻译表,处理器执行不同程序的时候使用不同的地址翻译表,如图1.1所示。

【文章福利】小编推荐自己的Linux内核技术交流群:【977878001】整理一些个人觉得比较好得学习书籍、视频资料共享在群文件里面,有需要的可以自行添加哦!!!前100进群领取,额外赠送一份价值699的内核资料包(含视频教程、电子书、实战项目及代码)
内核资料直通车:Linux内核源码技术学习路线+视频教程代码资料
学习直通车:Linux内核源码/内存调优/文件系统/进程管理/设备驱动/网络协议
图1.1 MMU地址翻译的作用
ProgramA被加载到地址0x500-0x600处,ProgramB被加载到地址0x700-0x800处,同时建立了各自的地址翻译表,当处理器要执行ProgramB时,会使用ProgramB对应的地址翻译表,比如读取ProgramB地址0x100处的指令,那么经过地址翻译表可知0x100对应实际内存的0x700处,所以实际读取的就是0x700处的指令。同样的,当处理器要执行ProgramA时,会使用ProgramA对应的地址翻译表,这样就避免了之前提到的内存冲突问题,有了MMU的支持,操作系统就可以轻松实现多任务了。
图1.1中CPU给出的地址称之为虚拟地址(OR1200中称之为有效地址EA),经过MMU翻译后的地址称之为物理地址。
MMU的地址翻译功能还可以为用户提供比实际大得多的内存空间。用户在编写程序的时候并不知道运行该程序的计算机内存大小,如果在链接的时候指定程序被加载到地址Addr处,而运行该程序的计算机内存小于Addr,那么程序就无法执行,有了MMU后,程序员就不用关心实际内存大小,可以认为内存大小就是“2^指令地址宽度”。MMU会将超过实际内存的虚拟地址翻译为物理地址进行访问。
地址翻译表存储在内存中,如果采用图1.1中的方式:地址翻译表的表项是一个虚拟地址对应一个物理地址,那么会占用太多的内存空间,为此,需要修改翻译方式,常用的有三种:页式、段式、段页式,这也是三种不同的内存管理方式。
页式内存管理将虚拟内存、物理内存空间划分为大小固定的块,每一块称之为一页,以页为单位来分配、管理、保护内存。此时MMU中的地址翻译表称为页表(Page Table),每个任务或进程对应一个页表,页表由若干个页表项(PTE:Page Table Entry)组成,每个页表项对应一个虚页,内含有关地址翻译的信息和一些控制信息。在页式内存管理方式中地址由页号和页内位移两部分组成,其地址翻译方式如图1.2所示。
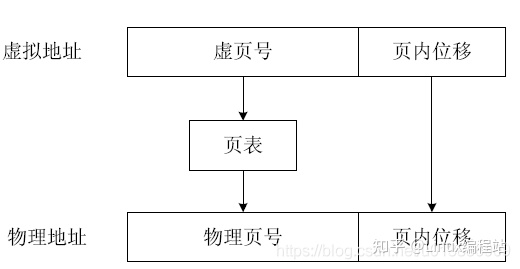
图1.2 页表实现虚拟地址到物理地址的映射
使用虚拟地址中的虚页号查询页表得到对应的物理页号,然后与虚拟地址中的页内位移组成物理地址。比如:页大小是256字节,虚拟地址是0x104,可知对应的虚页号是0x1,页内位移是0x4,假如通过页表翻译得到的对应物理页号是0x7,那么0x104对应的物理地址就是0x704。使用页表方式进行地址翻译可以有效减少地址翻译表占用的内存空间,还是以图1.1为例,页大小是256字节,此时每个程序对应的页表就只有两项,如图1.3所示。

图1.3 MMU页表地址翻译
段式内存管理将虚拟内存、物理内存空间划分为段进行管理,段的大小取决于程序的逻辑结构,可长可短,一般将一个具有共同属性的程序代码和数据定义在一个段中。每个任务和进程对应一个段表(Segment Table),段表由若干个段表项(STE:Segment Table Entry)组成,内含地址映像信息(段基址和段长度)等内容。在段式虚拟存储器中,地址分为段号、段内位移两部分,使用段表进行地址翻译的过程与使用页表进行地址翻译的过程是相似的。
段页式内存管理是在内存分段的基础上再分页,即每段分成若干个固定大小的页。每个任务或进程对应有一个段表,每段对应有自己的页表。在访问存储器时,由CPU经页表对段内存储单元进行寻址。
1.3.2 内存保护
MMU除了做地址转换之外,还提供内存保护机制。各种体系结构都有用户模式( UserMode) 和特权模式(Privileged Mode) 之分,操作系统可以设定每个内存页面的访问权限,有些页面不允许访问,有些页面只有在CPU处于特权模式时才允许访问,有些页面在用户模式和特权模式都可以访问,允许访问的权限又分为可读、可写和可执行三种。这样设定好之后,当CPU要访问一个VA时, MMU会检查CPU当前处于用户模式还是特权模式,访问内存的目的是读数据、写数据还是取指令,如果和操作系统设定的页面权限相符,就允许访问,把它转换成PA,否则不允许访问,产生一个异常( Exception) 。异常的处理过程和中断类似,只不过中断是由外部设备产生的,而异常是由CPU内部产生的,中断产生的原因和CPU当前执行的指令无关,而异常的产生就是由于CPU当前执行的指令出了问题,例如访问内存的指令被MMU检查出权限错误,除法指令的除数为0等。通常操作系统把虚拟地址空间划分为用户空间和内核空间,例如x86平台的虚拟地址空间是0x0000 0000~0xffff ffff,大致上前3GB( x0000 0000~0xbfff ffff)是用户空间,后1GB( 0xc000 0000~0xffff ffff)是内核空间。用户程序在用户模式下执行,不能访问内核中的数据,也不能跳转到内核代码中执行。这样可以保护内核,如果一个进程访问了非法地址,顶多这一个进程崩溃,而不会影响到内核和其它进程。 CPU在产生中断或异常时会自动切换模式,由用户模式切换到特权模式,因此跳转到内核代码中执行中断或异常服务程序就被允许了。事实上,所有内核代码的执行都是从中断或异常服务程序开始的,整个内核就是由各种中断处理和异常处理程序组成。
访问权限也是在页表中设置的,可以设定哪些页面属于用户空间,哪些页面属于内核空间,哪些页面可读,哪些页面可写,哪些页面的数据可以当作指令执行等等。 MMU在做地址转换时顺便检查访问权限。
1.4 MMU工作过程
MMU 进行虚拟地址转换成为物理地址的过程是 MMU 工作的核心。
大多数使用虚拟存储器的系统都使用一种称为分页(paging)。虚拟地址空间划分成称为页(page)的单位,而相应的物理地址空间也被进行划分,单位是页框(frame).页和页框的大小必须相同。接下来配合图片我以一个例子说明页与页框之间在MMU的调度下是如何进行映射的:
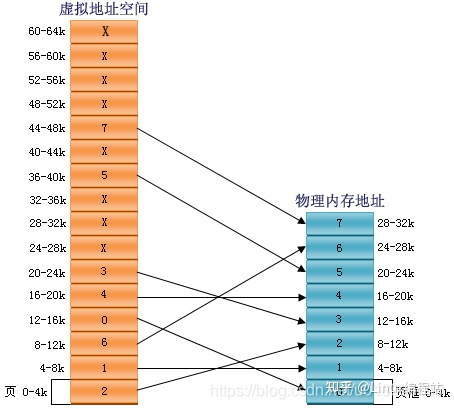
图1.4 页、页框映射关系图
在这个例子中我们有一台可以生成16位地址的机器,它的虚拟地址范围从0x0000~0xFFFF(64K),而这台机器只有32K的物理地址,因此他可以运行64K的程序,但该程序不能一次性调入内存运行。这台机器必须有一个达到可以存放64K程序的外部存储器(例如磁盘或是FLASH)以保证程序片段在需要时可以被调用。在这个例子中,页的大小为4K,页框大小与页相同(这点是必须保证的,内存和外围存储器之间的传输总是以页为单位的),对应64K的虚拟地址和32K的物理存储器,他们分别包含了16个页和8个页框。
我们先根据上图解释一下分页后要用到的几个术语,在上面我们已经接触了页和页框,上图中绿色部分是物理空间,其中每一格表示一个物理页框。橘黄色部分是虚拟空间,每一格表示一个页,它由两部分组成,分别是Frame Index(页框索引)和位p(present 存在位),Frame Index的意义很明显,它指出本页是往哪个物理页框进行映射的,位p的意义则是指出本页的映射是否有效,如上图,当某个页并没有被映射时(或称映射无效,Frame Index部分为X),该位为0,映射有效则该位为1。
我们执行下面这些指令(本例子的指令不针对任何特定机型,都是伪指令)
例1:
MOVE REG,0 //将0号地址的值传递进寄存器REG虚拟地址0将被送往MMU,MMU看到该虚地址落在页0范围内(页0范围是0到4095),从上图我们看到页0所对应(映射)的页框为2(页框2的地址范围是8192到12287),因此MMU将该虚拟地址转化为物理地址8192,并把地址8192送到地址总线上。内存对MMU的映射一无所知,它只看到一个对地址8192的读请求并执行它。MMU从而把0到4096的虚拟地址映射到8192到12287的物理地址。
例2:
MOVE REG,8192
被转换为
MOVE REG,24576因为虚拟地址8192在页2中,而页2被映射到页框6(物理地址从24576到28671)
例3:
MOVE REG,20500
被转换为
MOVE REG,12308虚拟地址20500在虚页5(虚拟地址范围是20480到24575)距开头20个字节处,虚页5映射到页框3(页框3的地址范围是 12288到16383),于是被映射到物理地址12288+20=12308。
通过适当的设置MMU,可以把16个虚页隐射到8个页框中的任何一个,但是这个方法并没有有效的解决虚拟地址空间比物理地址空间大的问题。从上图中我们可以看到,我们只有8个页框(物理地址),但我们有16个页(虚拟地址),所以我们只能把16个页中的8个进行有效的映射。我们看看例4会发生什么情况:
例4:
MOV REG,32780虚拟地址32780落在页8的范围内,从上图总我们看到页8没有被有效的进行映射(该页被打上X),这是又会发生什么?MMU注意到这个页没有被映射,于是通知CPU发生一个缺页故障(page fault).这种情况下操作系统必须处理这个页故障,它必须从8个物理页框中找到1个当前很少被使用的页框并把该页框的内容写入外围存储器(这个动作被称为page copy),随后把需要引用的页(例4中是页8)映射到刚才释放的页框中(这个动作称为修改映射关系),然后从新执行产生故障的指令(MOV REG,32780)。假设操作系统决定释放页框1,那么它将把虚页8装入物理地址的4-8K,并做两处修改:首先把标记虚页1未被映射(原来虚页1是被影射到页框1的),以使以后任何对虚拟地址4K到8K的访问都引起页故障而使操作系统做出适当的动作(这个动作正是我们现在在讨论的),其次他把虚页8对应的页框号由X变为1,因此重新执行MOV REG,32780时,MMU将把32780映射为4108。
我们大致了解了MMU在我们的机器中扮演了什么角色以及它基本的工作内容是什么,下面我们将举例子说明它究竟是如何工作的(注意,本例中的MMU并无针对某种特定的机型,它是所有MMU工作的一个抽象)。
首先明确一点,MMU的主要工作只有一个,就是把虚拟地址映射到物理地址。
我们已经知道,大多数使用虚拟存储器的系统都使用一种称为分页(paging)的技术,就象我们刚才所举的例子,虚拟地址空间被分成大小相同的一组页,每个页有一个用来标示它的页号(这个页号一般是它在该组中的索引,这点和C/C++中的数组相似)。在上面的例子中04K的页号为0,48K的页号为1,8~12K的页号为2,以此类推。而虚拟地址(注意:是一个确定的地址,不是一个空间)被MMU分为2个部分,第一部分是页号索引(page Index),第二部分则是相对该页首地址的偏移量(offset). 。我们还是以刚才那个16位机器结合下图进行一个实例说明,该实例中,虚拟地址8196被送进MMU,MMU把它映射成物理地址。16位的CPU总共能产生的地址范围是0~64K,按每页4K的大小计算,该空间必须被分成16个页。而我们的虚拟地址第一部分所能够表达的范围也必须等于16(这样才能索引到该页组中的每一个页),也就是说这个部分至少需要4个bit。一个页的大小是4K(4096),也就是说偏移部分必须使用12个bit来表示(2^12=4096,这样才能访问到一个页中的所有地址),8192的二进制码如下图所示:

图1.5 页索引号与偏移量关系图
该地址的页号索引为0010(二进制码),既索引的页为页2,第二部分为000000000100(二进制),偏移量为4。页2中的页框号为6(页2映射在页框6,见上图),我们看到页框6的物理地址是24~28K。于是MMU计算出虚拟地址8196应该被映射成物理地址24580(页框首地址+偏移量=24576+4=24580)。同样的,若我们对虚拟地址1026进行读取,1026的二进制码为0000010000000010,page index=“0000”=0,offset=010000000010=1026。页号为0,该页映射的页框号为2,页框2的物理地址范围是8192~12287,故MMU将虚拟地址1026映射为物理地址9218(页框首地址+偏移量=8192+1026=9218)。以上就是MMU的工作过程。
1.5 Cortex-A7 MMU
1.5.1 MMU特性
Cortex-A7 MPCore处理器实现了扩展的VMSAv7 MMU,支持ARMv7-A VMSA(Virtual Memory System Architecture)、安全扩展、LPAE(Large Physical Address Extensions)和虚拟扩展。主要功能是地址转换、内存权限管理等。MMU必须与L1、L2cache一起工作。
Cortex-A7多处理器设备的每个处理器的MMU特性包括:
• 10条全相联微指令TLB。
• 10条全相联微数据TLB。
• 2路组相联256条统一主TLB。
• 2路组相联64条步行缓存。
• 2路组相联64路IPA缓存。
• TLB条目包括全局和应用程序特定的标识符,以防止上下文切换TLB刷新。
• 虚拟机标识符(VMID),用于防止管理程序在虚拟机开关上刷新TLB。
1.5.2 Cortex-A7内存管理系统
Cortex-A7 MPCore处理器支持ARM v7 VMSA,包括安全扩展和LPAE。指令集体系结构使用的虚拟地址(VA)转换为内存系统中使用的物理地址(PA),并使用两级MMU管理相关联的属性和权限。
第一级MMU是用哈佛架构设计的MicroTLB结构,在DPU中用于数据读写请求(DuTLB),使用单独的Micro TLB结构。
未命中的Micro TLB会导致对在存储系统的数据和指令端之间共享的统一的Main TLB的请求。 TLB由基于256项2路集关联RAM的结构组成。TLB页面漫游机制支持L1数据缓存中保存的页面描述符。这些缓存的描述符在Cortex-A7 MPCore处理器的各个内核之间是一致的。页面描述符的缓存是为系统协处理器CP15中的每个转换表基址寄存器TTBRx全局配置的。
1.5.2.1 Cortex-a7内存类型和属性
尽管可以在页表中指定各种不同的内存类型,但是Cortex-A7 MPCore处理器并不能实现所有可能的组合:
• 直写式缓存。标记为“内部直写”的任何内存都不会在数据侧缓存。在SCTLR.I设置为1时,在标记为Inner Write-Through和Inner Write-Through的指令侧区域将被相同地对待,并且都缓存在L1指令高速缓存中。但是,不会标记为Inner Write-Through的指令侧区域在二级缓存中时(如果存在)。即使未缓存,所有标记为“内部可写”的内存也会被PAR报告为“内部可写”。
• 如果连续写入三个以上的完整缓存行,则可以将所有内部回写内存视为忽略所有缓存分配提示的回写写分配,尽管这可以动态切换为不进行写分配。请参阅第2-4页的数据缓存单元。所有内部回写在PAR中均报告为回写写分配。将ACTLR.SMP设置为1,启用MMU并将SCTLR.C设置为1时,可以缓存所有回写内存。
• 普通内存(内部不可缓存和外部不可缓存)始终被报告为外部共享,而与转换表设置无关。强顺序存储和设备内存类型的属性行为是在体系结构上定义的,有关更多信息,请参见《 ARM体系结构参考手册》。
1.5.3 Cortex-a7 TLB组织
1.5.3.1 Micro TLB
页表信息的第一级缓存是在指令和数据端均实现的10个条目的微型TLB。 这些块在单个周期中提供了虚拟地址的查找。
Micro TLB将物理地址返回到缓存以进行地址比较,还检查访问权限以发出预取中止或数据中止的信号。
所有与Main TLB相关的维护操作都会影响指令和数据MicroTLB,从而导致它们被刷新。
1.5.3.2 Main TLB
未命中的Micro TLB统一由Main TLB处理。这是一个256项2路组相联结构。 除了2MB和1GB的LPAE页面大小之外,主TLB还支持所有4KB,64KB,1MB和16MB的VMSAv7页面大小。 根据以下条件,对主TLB的访问需要可变的周期数:
•每个微型TLB的竞争请求。
•飞行中的TLB维护操作。
•使用中的不同页面大小映射。1.5.3.3 IPA Cache RAM
IPA高速缓存RAM保留中间物理地址和物理地址之间的映射。 仅在非安全非管理程序模式下执行的翻译才使用此功能。 第2阶段翻译完成后,将对其进行更新,并在需要第2阶段翻译时进行检查。
与MainTLB相似,它可以保存不同大小的条目,并维护存在大小的匹配图,因此不必查找已知不存在的大小。
1.5.3.4 Walk cache RAM
步行缓存RAM保留阶段1转换的部分结果,其中不包括最后一级。 如果阶段1转换导致一个部分或更大的映射,则不会在步行缓存中放置任何内容。
步行缓存保存从安全和非安全状态(包括虚拟机监控程序模式)获取的条目。
1.5.4 TLB match process
虚拟化扩展和安全性扩展提供了多个虚拟地址空间,它们的转换方式有所不同。Main TLB条目存储所有必需的上下文信息,以促进匹配并避免在上下文或虚拟机交换机上进行TLB刷新。每个TLB条目都包含一个虚拟地址,页面大小,物理地址以及一组包含内存类型和访问权限的内存属性。每个条目都被标记为与特定的应用程序空间ID(ASID)相关联,或者被标记为对所有应用程序空间都是全局的。 TLB条目还包含一个字段,用于存储引入该条目的虚拟机标识符(VMID),该字段适用于虚拟化扩展定义的从非安全状态进行的访问。还有一点记录是否在Hyp模式请求上分配了该TLB条目。满足以下条件时,将发生TLB条目匹配:
•由页面大小(例如虚拟地址位[31:N])控制的虚拟地址,其中N是存储在TLB条目中的转换的页面大小的log2,与请求的地址匹配。
•非安全TLB ID NSTID与请求的安全或非安全状态匹配。
•“ Hyp模式”位与是否从“ Hyp模式”发出请求相匹配。
•ASID与保存在CONTEXTIDR,TTBR0或TTBR1寄存器中的当前ASID匹配,或者该条目标记为全局。
•VMID与保存在VTTBR寄存器中的当前VMID相匹配。1.5.5 Memory access sequence
当处理器生成内存访问时,MMU:
1.在相关指令或数据Micro TLB中查找请求的虚拟地址,当前ASID,当前VMID和安全状态。
2.如果相关的微型TLB中未命中,则在统一的主TLB中对请求的虚拟地址,当前的ASID,当前的VMID和安全状态进行查找。
3.如果Main TLB中未命中,则执行硬件转换表遍历。
您可以使用传统的VMSAv7短描述符转换表格式或LPAE指定的长描述符转换表格式,将MMU配置为执行硬件转换表遍历。这是通过对适当的安全或非安全转换表基本控制寄存器(TTBR)中的扩展地址使能(EAE)位进行编程来控制的。有关转换表格式的信息,请参见《ARM体系结构参考手册》。
您可以使用以下命令配置MMU以在可缓存区域中执行转换表遍历:
• 通过将转换表基址寄存器0(TTBR0)和转换表基址寄存器1(TTBR1)中的IRGN位置1,可以实现短描述符转换表格式。
• 通过将相关转换表基本控制寄存器(TTBCR)中的IRGN位置1,来建立长描述符转换表格式。
• 如果IRGN位的编码为回写,则执行L1数据高速缓存查找,并从数据高速缓存中读取数据。如果IRGN位的编码为直写或不可缓存,则将执行对外部存储器的访问。
在Main TLB丢失的情况下,如果通过以下方式启用了翻译表遍历,则硬件将执行翻译表遍历:
• 通过将TTBCR中的PD0或PD1位设置为0,可以实现短描述符转换表格式。
• 通过将TTBCR中的EPD0或EPD1位设置为0,实现长描述符转换表格式。
如果禁用转换表漫游,例如,将TTBR0的PD0或EPD0设置为1,或者将TTBR1的PD1或EPD1设置为1,则处理器将返回转换错误。如果TLB找到匹配的条目,它将按以下方式使用条目中的信息:
• 使用短描述符转换表格式时的访问许可位和域,确定是否启用了访问。如果匹配的条目未通过权限检查,则MMU发出内存中止的信号。有关访问权限位,中止类型和优先级的说明,以及指令故障状态寄存器(IFSR)和数据故障状态寄存器(DFSR)的说明,请参见《 ARM体系结构参考手册》。
• 在TLB条目中指定的内存区域属性确定访问是否为:
—安全或不安全。
—内部,外部共享与否。
—正常内存,设备或强顺序。
• TLB将虚拟地址转换为用于内存访问的物理地址。
1.5.6 External aborts
外部存储器错误定义为发生在存储器系统中的错误,而不是MMU检测到的错误。 外部存储器错误预计将极为罕见。 当请求传到Cortex-A7 MPCore处理器外部时,外部中断是由ACE主接口标记的错误引起的。 您可以通过将SCR.EA位设置为1,将外部中断配置为捕获到监视模式。
1.5.6.1 External aborts on data write
数据写入期间外部产生的错误可以是异步的。 这意味着在此类异常终止中进入异常终止处理程序的r14_abt可能不保存导致异常的指令的地址。
可缓存写操作中的外部存储器错误不会导致异常终止,但会导致nAXIERRIRQ信号被置为有效。
异步中止发生时,DFAR是不可预知的。
1.5.6.2 External aborts on data read
外部在数据加载指令上产生的错误始终是同步的。 DFAR中捕获的地址与生成外部异常终止的地址匹配。
不会导致中止的读取通道访问上的外部存储器错误导致nAXIERRIRQ信号被置位。 这包括:
• 由L1指令触发的L2换行会在脏状态下从互连中接收数据。 由于自我修改代码或包含数据和指令混合的行,指令数据可被标记为脏数据。 如果在该行的任何部分接收到错误响应,则脏数据可能会丢失。
• DVM操作
1.5.6.3 Synchronous and asynchronous aborts
要确定故障类型,请读取DFSR以中止数据,或读取IFSR以中止预取。
在DBGDSCR.ADAdiscard设置为1的调试状态下,nAXIERRIRQ信号的行为不受影响。













![[附源码]Python计算机毕业设计Django预约挂号app](https://img-blog.csdnimg.cn/edec0154433e44e1ab04d30845442be9.png)