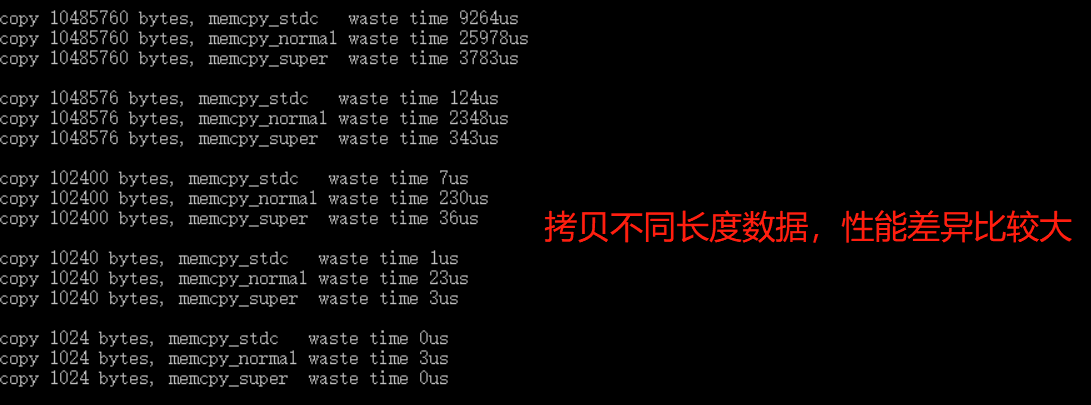
👉本篇速览
早在最开始学Redis的时候,我们就学到了这九种数据类型:String、Hash、List、Set、Zset、BitMap、HyperLogLog、GEO、Stream,但其实在学的时候并不了解它的底层是怎么存储这些数据,而不同的数据类型又有哪些应用的场景,本文将分别讲述这九种数据类型的底层实现和应用场景,但是不会去具体讲解这九种数据类型的使用或者说是指令
Tips:文章很长,建议大家静心攻读,相信会有不错的收获!也可以收藏起来,重复去看和理解(骗收藏hhh)
1️⃣ String
我们不难发现Redis的数据类型中没有char,int,double……这种数据类型,因为Redis的String不仅可以是字符串,还能是数字(整数或者浮点数),就让我们来一起看看是如何做到兼容的:
🍕 SDS-简单动态字符串
String 类型的底层的数据结构实现主要是靠 int 和 SDS,SDS:简单动态字符串
🍔 C语言字符数组
在讲解SDS之前我们先谈谈为什么不使用char型数组(Redis使用C语言写的,此处的char型数组是指char*):
-
char型数组判断字符串长度有局限性且获取字符串长度的时间复杂度高 C语言使用strlen判断字符串长度的函数是对字符数组进行遍历,找到\0,那么对于字符串中有\0的,就会遍历提前结束,得到的长度并不准确 刚刚也提到,是对字符数组进行遍历,那么得到长度的时间复杂度就是O(N)
-
char型数组容易缓冲区溢出:C语言的库提供的字符串操作函数并不安全,因为这些函数的底层并不会判断缓冲区大小是否够用,因此会出现缓冲区溢出进而程序崩溃
🍟 SDS数据结构
其实SDS的实现就是把字符数组封装成了一个能够成熟使用的对象,用C语言的话来说,就是一个结构体,我们来看看结构的中的成员变量
该结构体中的字段有:
-
len:记录字符串的长度,这样就不需要全表遍历去获得字符串的长度,获取字符串长度的时间复杂度就:O(N) -> O(1)
-
alloc:分配给字符数组的空间长度,通过alloc - len可以计算出剩余的空间大小,方便后续的扩容,也就是说在做操作的时候会判断剩余的空间是否够用,这样也就防止了缓冲区溢出的问题
-
flags:表示SDS的类型,可以理解为type
-
buf[]:字节数组,也就是真正存储数据的数组,除了可以保存字符串还能保存二进制数据
🌭 存储数据的流程
对于存入的key-value的键值对,会把value的信息封装成一个RedisObject,然后编码为SDS存入内存:

如果字符串是一个数值,数值可以使用long类型存储,例如666.66,那么它的RedisObject就为:
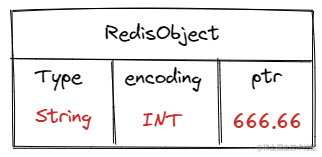
首先是字符串形式,因此Type:String,然后encoding有三种类型:
-
int:用于编码数值类型的数据
-
raw:用于编码数据量大于指定字节的字符串数据
-
embstr:用于编码数据量小于指定字节的字符串数据
-
这个指定的字节,与redis的版本有关系: redis 2.+ 是 32 字节 redis 3.0 - 4.0 是 39 字节 redis 5.0 是 44 字节
那我们再来讨论字符串长度小于指定字节,也就是说使用embstr编码的字符串时,它的RedisObject就为:
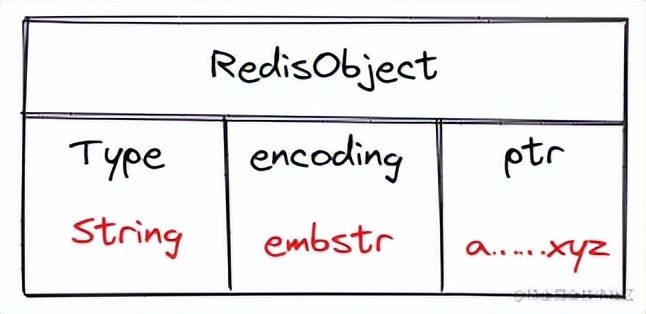
编码得到SDS,并把这个数据结构存到内存中:

那么,既然分出了不同字节不同编码,两种编码方式有什么区别呢?
我们先看看内存图,我们可以发现:embstr的RedisObject和SDS空间是连在一起的,而raw编码的二者是两块不连续的内存

两种编码方式各有千秋,经比较,他们的优缺点如下:
-
embstr编码只需要分配内存一次,对于SDS的空间直接分配在RedisObject后面即可
-
释放Embstr编码的对象也只需要一次释放即可
-
embstr编码的数据保存在连续的内存中,有利于利用CPU缓存提高性能
-
embstr只读!!,如果需要修改就需要先要把数据从embstr -> raw
🥓 应用场景
-
存储对象:通常我们去做缓存数据的时候,会把数据转化为JSON格式的字符串放入Redis缓存,虽然我们也可以放入Hash进行缓存
-
计数器:Redis是单线程的,因此执行命令的时候具备原子性,可以用于计数,如点赞数、访问次数……
-
分布式锁:尽管我们使用分布式锁的时候,一般直接去使用Reddision,但是人底层是用这个写的,使用SETNX来实现,这个我们后续在讲分布式事务的时候来讲
-
session共享:由于搭分布式后Session只会存在一个服务器中,但是不会做到共享,因为分布式系统每次会把请求随机达到不同的服务器,因此就要利用Redis做共享
2️⃣ List
在Redis 3.2之前,List的底层数据结构为双向链表或压缩列表:
-
如果列表个数小于512个,且每个元素的内存大小都小于64字节,Redis的List使用压缩列表作为底层数据结构
-
如果列表元素大于512个,或者元素的内存大小大于64字节,就会使用双向链表进行存储List
🥖 压缩列表
压缩列表是由连续内存块组成的顺序型数据结构,其实我觉得是有点像数组的,可以说是一个结构体数组,但是数组的头部和尾部有一些特点,我们可以看一下它的结构图:

编辑切换为居中
我们分别来解读一下各个字段:
-
zlbytes:压缩列表的占用内存字节数
-
zltail:压缩列表的尾部的偏移量,也就是尾部离起始的位置的字节数
-
zllen:记录结点的个数
-
entry:结点,它有三个字段: prevlen:记录前一个结点的长度,方便从后到前的遍历,这里有个知识点: 如果前面的结点的长度小于254字节,prevlen只占用1个字节 如果前面的结点的长度大于254字节,prevlen占用5个字节 encoding:它用于标识结点的类型,是数值还是字符串 data:存储真正的数据
-
zlend:标识压缩列表的结尾
那么为什么不使用压缩列表去实现LIst呢?也就是说压缩列表存在一定的缺陷和优点,我们下面来讨论一下:
优点:它占用了一块连续的内存空间,可以利用CPU缓存,并且针对不同长度的数据会进行不同的编码,可以有效的节省内存开销
缺点:
-
其实我们可以发现,我们只能快速的定位到第一个结点和尾部的结点,但是如果要进行数据的查找,那就是全表扫描了,也就是说查找复杂度高,因此在数据量较多的情况下不会使用压缩列表
-
再就是我们在新增某个元素或者修改某个元素的时候,可能出现空间不足,那么就需要重新分配内存空间
-
在插入数据的时候,如果数据较大,可能导致所有元素的prevlen发生变化,导致连锁更新: 假设压缩列表中的数据是连续的252字节的数据 那么插入一个大一点的数据,导致第二个数据的prevlen变为5,导致整个数据变为256 导致下一个也出问题,然后多米诺骨牌,连锁更新(连续多次空间扩展)
因为存在连锁更新,所以压缩列表只会用于节点数不多的情况,即使发生连锁更新,节点数不多的情况下也是能勉强接受的。
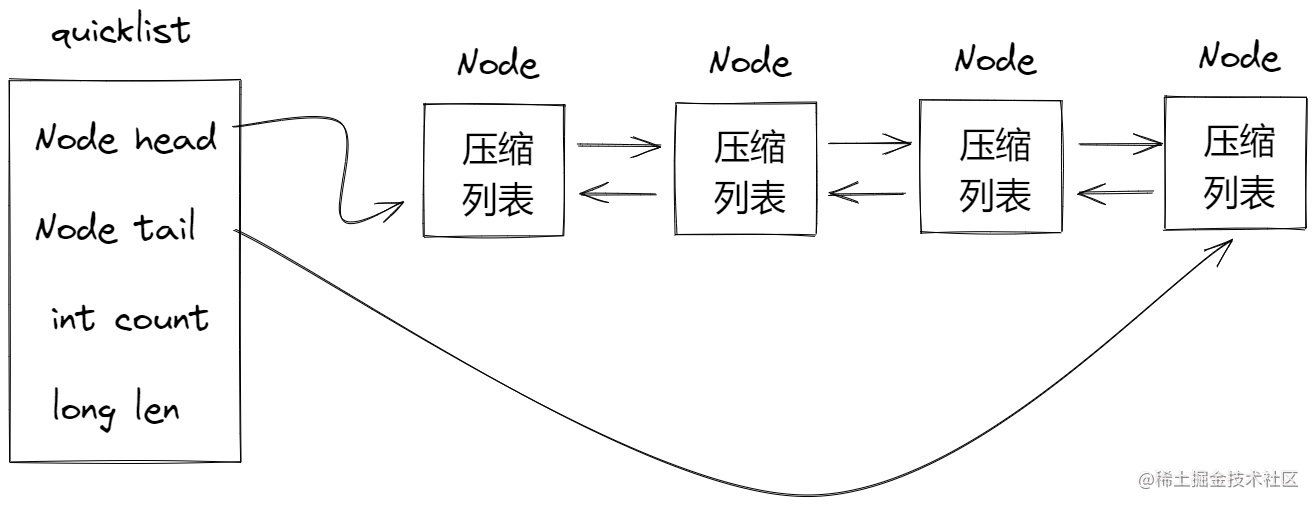
🧀 quicklist
在Redis 3.2的时候,List的底层数据结构就由压缩链表/双向链表 -> quicklist
其实quicklist = 压缩链表 + 双向链表,它其实就是一个链表,但是链表链的是压缩列表,压缩列表不被使用的原因主要是因为连锁更新,但是如果控制每个压缩列表的大小,然后把这些压缩列表通过链表连接,那么在压缩列表的元素比较少的情况下,出现连锁更新带来的影响就很小。
其实说到这里可能大家都明白了,这里还是画一张图帮助大家记忆:
🌯 应用场景
List主要的应用场景就是消息队列,Redis实现消息队列可以使用到List / Stream,这里我们简单谈一谈List实现消息队列:
其实就是利用List双向链表的LPUSH、RPOP进行消息队列的生成和消费,但是这只是最基础的命令,我们一步一步来看,究竟使用什么命令更好:
-
首先简单的RPOP,如果没有消息就返回空,有消息就返回,这样就无法做到即时消费,除非一直RPOP
-
因此就引入了BRPOP,阻塞读,也就是说如果没有消息就会一直阻塞,直到有消息,但是我们无法保证消息的可靠性,也就是说如果消息确实被拿走了,但是消费过程中宕机了,就会出现该消息没有被消费但是,消息没了
-
因此就又引入了BRPOPLPUSH,使用这个命令,如果消费者从List中读取到了消息后,Redis还会把这个消息放在另外的一个备份List中留存,防止上述情况
用List做消息队列的最大缺陷就是List不支持多个消费者消费一条记录
3️⃣ Hash
在Redis 7.0之前,Hash类型的底层数据结构是压缩列表或哈希表实现:
-
如果哈希类型元素个数小于512个,所有的元素的内存大小都小于64字节,Redis会使用压缩列表作为Hash类的底层数据结构
-
如果哈希类型元素个数大于512个,或者有元素的内存大小大于64字节,Redis就是用哈希表作为Hash类型的底层数据结构
🍖 listpack
在Redis 7.0中,压缩列表数据结构被废弃,转而使用 listpack 数据结构来实现
在讲listpack之前,我们先谈谈quicklist,尽管缩小了压缩列表的大小,减小连锁更新带来的影响,但是没有完全解决这个问题
因此在listpack中,直接废弃prevlen字段,从根源解决问题。
🍗 应用场景
Hash主要是用来缓存对象,在上面讲String的时候我们有提到,使用String + Json可以用于缓存对象,而Hash也可以缓存对象,并且缓存的对象的可观性更高,且修改属性更方便。
-
对于String + Json存储的对象,我们想要修改属性值,就需要JSON转为对象,对象修改属性值,然后再把修改后的对象转为Json字符串存入Redis。
-
对于Hash存储的对象,直接修改属性值即可
结论:一般对象使用String + Json,但是频繁更改属性值的可以用 Hash存储,如购物车
4️⃣ Set
Set也就是无序且唯一的键值集合,除了HashSet中那些基础的增删查改功能以外,其实Redis还提供了做集合的交集、并集、差集这样的操作,这些都有不错的应用,但是也不得不注意的是:这些运算的复杂度很高,因此在数据量比较大的情况下容易出现Redis阻塞
🥩 底层实现
Set类型的底层数据结构是由哈希表或者整数集合实现的:
-
如果集合中的元素小于512个,就会使用整数集合作为底层数据结构
-
如果集合中的元素大于521个,就会使用哈希表作为底层的数据机构
哈希表我们已经很熟悉了,那整数集合是什么呢?
整数集合实际上就是一块连续的内存空间,我们可以看一下它的字段:
-
contents:真正存储数据的数组
-
length:整数集合包含的元素个数
-
encoding:编码方式,它决定了存储数据的数组的类型: 如果encoding = INTSET_ENC_INT16,那么contents就是一个int16_t类型的数组 如果encoding = INTSET_ENC_INT32,那么contents就是一个int32_t类型的数组 如果encoding = INTSET_ENC_INT64,那么contents就是一个int64_t类型的数组 那么Redis会判断数据,使用最优的编码方式,以达到节省内存的目的,但是存在一个问题,对于一个int16_t的数组,插入一条int32_t的数据,会发生什么呢?
答案是整数集合的升级:其实就是原本的int16_t的数组变为int32_t的数组,其中的数据也要向上转型为32位,然后占用的空间自然也更多了
🍠 应用场景
-
点赞:我们可以以文章的ID作为唯一标识,用户的ID作为value,由于一篇文章一个用户只能赞一次,正好能利用到Set的唯一性
-
共同关注:在做关注的时候,就是用户Redis进行存储用户关注的数据,这样我们就能通过做两个人的关注的交集得到他们的共同关注,或者说做差集得到:你可能认识的人
-
抽奖活动:在抽奖活动中,为了保证活动的“公平”,我们不能让同一个用户抽中两次奖,因此我们可以使用Redis这个基于内存的数据库存储
5️⃣ Zset
在Redis 7.0以前,Zset底层的数据结构是由压缩列表或跳表实现的:
-
如果有序集合的元素个数小于128个,且每个元素的大小不大于64字节的时候,就使用压缩列表作为Zset的底层数据结构
-
如果不满足上述的条件,就使用跳表作为Zset的底层数据结构
同样的,在Redis7.0后,压缩列表就被替换为listpack了
🍘跳表
其实Zset的底层有两个数据结构:一个是跳表,帮助进行高效的范围查询,一个是哈希表,帮助高效的定点查询,在更新数据的时候会依次去这两张表更新数据,哈希表我们就不多说了,来看看跳表,为什么可以高效的范围查询:
🍙 跳表结构
我们先来看看跳表结点的成员变量:
typedef struct zskiplistNode {
sds element;
double score;
struct zskiplistNode *backward;
//节点的level数组,保存每层上的前向指针和跨度
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;-
elemen、score:对象的元素值、元素权重值,也就说我们存入Zset时的两个字段
-
backward:后向指针,也就是指向前一个结点,方便倒序遍历
-
level[]:代表这个结点在这一层时的跨度,我们以下面这张图举例: 例如结点3,它在第二层的跨度为3,第一层的跨度为1,第零层的跨度也为一,因此结点三的level数组就为:
| level层数 | forward | span |
| 2 | NULL | 3 |
| 1 | 结点5 | 1 |
| 0 | 结点4 | 1 |
然后,这里做一个辨析,此处的结点不是左边的L2、L1、L0,而是数据的结点,头结点是由跳表这个结构体定义的:
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;此处的头结点的后向指针、权重、元素值都没有,因此图中就忽略了这一部分
🍚 跳表查询过程
话不多说,我们直接上场景:

在查询的过程中,跳表会逐层遍历,然后在遍历的过程中,对元素和权重进行判断,进而决定下一步的走向,判断的条件为:
-
如果当前结点的权重小于要查找的权重,就访问这一层的下个结点
-
如果当前结点的权重等于要查找的权重,并且当前结点的SDS数据小于要查找的数据,就访问这一层的下一个结点
-
如果都不满足,或者下一个结为空,就去level数组的下一层指针继续查找
如果我们要查询元素abcd,且权重为4的结点,我们来模拟一遍:
-
首先头结点指向元素:abc,权重3的level[2],经比对,当前结点的权重小于目标权重,因此指向该层的下一个结点NULL
-
由于指向的结点为空,就需要去LEVEL数组的下一层指针,即level[1],它的下一个指针指向的元素为:元素:abcde,权重4的level[1],经比对,尽管权重相等,但是当前结点的SDS也就是abcde要不小于我们找的abcd,因此第一个和第二个条件都不满足
-
于是来到了元素:abc,权重3的level[0],此时指向的下一个结点符合条件,返回
这里我们没有详细去介绍跳表具体如何实现,如何插入,如何维护它的层数,如何让效率最高,因为我们本意只是要了解它的搜索,当然如果大家有兴趣,可以评论区留言,我会再出一篇单独的文章讲跳表。
🍛 应用场景
Zset相较于无序的Set,多了元素的权重,也就是说可以根据元素的权重进行排序,因此多了更多的应用场景:
-
排行榜:例如本次的年度总结的征文计划中的计分:数据表现分=阅读量/1000+点赞/100+评论/50,就可以作为我们每篇博客的权重,最后只需要对权重进行排序,就能得到排行榜的数据
-
电话排序:听起来可能有点怪,但是我们可以使用Zset做到一丢丢的模糊查询,例如我现在要找186开头的电话,就可以使用下面这个命令就能得到:
ZRANGEBYLEX phone [132 (134-
时间排序:其实跟排行榜有点像了,我们以时间戳作为权重,就能得到关于时间的排序
6️⃣ BitMap
BitMap:位图,可以通过偏移量来定位元素,其实可以理解为一个二进制数组,或者说是一个bit数组,只存储0|1,用0|1来表示状态,但是呢对于这个数组的统计和预算做了一些API,所以其实原理比较简单,我们来看看它的具体应用场景:
-
签到统计:刚刚也提到了,其实这个适用于统计状态,像这种非0即就可以使用位图来统计,1就是签到了,0就是没有签到,一年的签到下来也就365位。 我们除了能统计签到天数,还能通过BITPOS定位到某一条记录,例如某个月的第一次签到 还能统计连续签到的天数,可以每天做一个BitMap,然后userID作为offset,我们可以统计多天的offset做与运算,如果七天的BitMap与运算结果为1,代表他连续签了7天了
-
记录用户登陆状态:同样的用户无非登陆、离线两种状态,使用位图可以帮助我们在有限的空间统计更多的用户登陆信息
7️⃣ HyperLogLog
这个数据结构的底层实现我们就不讲了,因为很难(牵扯到数学问题)!面试应该不考~大家有兴趣自行了解,这个评论区留言也没用,哥们没那能力 O.o
我们来聊聊它的应用:百万级网页UV计数,首先谈谈为什么是百万级呢,因为如果量级小一点你就自己用Set去计数,因为HyperLogLog统计的数据并不精确,有0.81% 的错误率,但是它的优势就是:耗用的内存极低它平时使用就两命令,如果要插入访问页面的用户,就:
PFADD page1:uv userId如果要统计UV值,就使用这个命令:
PFCOUNT page1:uv8️⃣ GEO
GEO主要用于存储地理位置信息,并能对位置信息做一定的筛选搜索,它主要用于我们位置信息的储存和运算
🍜 底层原理
先说说它的底层原理,其实它并没有使用到新的数据结构,而是使用了Zset,通过编码方式,把经纬度编码为权重分数,然后分数在同一个区间的地理位置,就离的比较近,当然这要看你的区间的大小,因此可以通过区间的大小进而得到二者的距离。
假设我家的经纬度编码得到的值为15,我想要我家方圆100m以内的店铺信息,那么可能算法就会找权重值为(15,15.1)的值,然后返回给我店铺信息 (ps:此处只是做假设,讲解实现思路)
🍤 应用场景
-
附近的商铺:就上面那个场景,我们可以获取到离我们当前地理位置xxxm以内的店铺信息
-
同理,我们也可以使用这个获取 xxxm内的打车信息,xxxm以内的人
9️⃣ Stream
先谈谈在Stream诞生之前消息队列的弊端:
-
List实现消息队列不能创建消费者组,一个消息只能被消费一次
-
消息去重需要生产者去创建全局唯一ID
-
发布订阅模式做不到持久化,对于离线的客户端读取不到历史消息 说了这么多,自然Stream在Redis 5.0应运而生,它解决了上述的三个问题,我们来看看怎么解决:
全局唯一ID
生产者通过XADD插入消息的时候,就会返回一个全局唯一ID,也就是说不需要生产者自己去维护一个全局ID生成器了
这个全局ID生成的策略为:以毫秒为单位的时间戳 + 计数器,计数器用于标识这一毫秒内的多个消息
消费者组
Stream可以使用XGROUP创建消费者组,创建消费组后,可以让消费者组内的成员消费一条信息,也就是说,一旦消费者组中的一个消费者消费了该条信息,组内其他消费者就不能再消费了,此时不同组的消费者可以消费这条信息
保证信息被消费
Streams会使用一个内部的队列去维护消费者消费的所有信息,如果消费者出现了宕机或其他故障,导致信息被拿走,但是没有处理完,那么消费者就不会发送最后的XACK命令来确认消费完成,此时消息就一直会备份在内部的队列中,可以在重启后重新消费
那么Redis相较于专业的消息队列,如RocketMQ、Kafka有什么缺陷呢?
-
Redis 本身可能在宕机或者主从复制这个异步场景中丢失数据
-
Redis 是基于磁盘的,因此如果堆积消息过多,且指定了最大的长度,消息有丢失的可能性
💬 总结
本文讲了Redis的九种数据类型,除了HyperLogLog和Stream其他都讲了底层的实现原理,希望大家在使用的时候不仅会用,还要知道它的底层,同时讲到了九种数据结构的应用场景,那么在面试的时候,无论面试官问你某种数据结构的应用场景,还是给你应用场景,让你来选数据结构都不至于说不上来。





![[附源码]Python计算机毕业设计Django预约挂号app](https://img-blog.csdnimg.cn/edec0154433e44e1ab04d30845442be9.png)