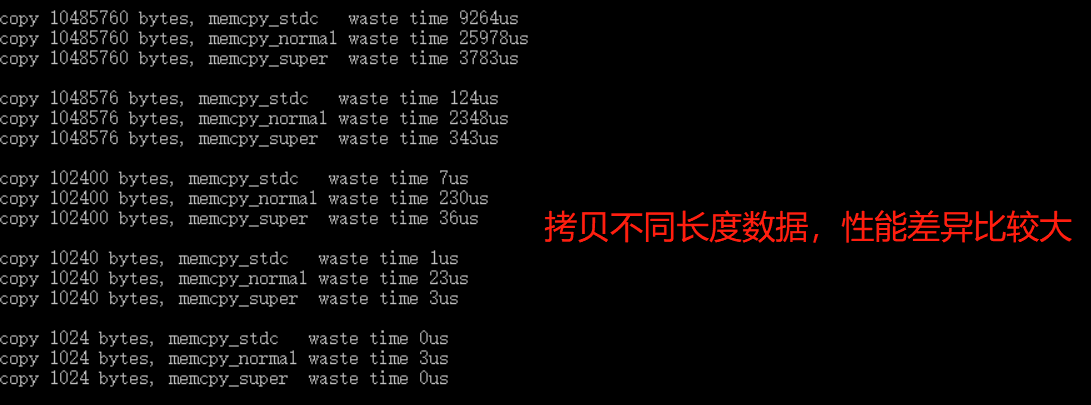
前言 语义分割通常得益于全局上下文、精细定位信息、多尺度特征等。为了在这些方面改进基于Transformer的分割器,本文提出了一种简单而强大的语义分割架构——IncepFormer。
IncepFormer介绍了一种新颖的金字塔结构Transformer编码器,它同时获取全局上下文和精细定位特征。IncepFormer还集成了具有深度卷积的类Inception架构,以及每个自注意力层中的轻量级前馈模块,有效地获得了丰富的局部多尺度对象特征。
Transformer、目标检测、语义分割交流群
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【百篇论文阅读计划】新升级!

论文:https://arxiv.org/pdf/2212.03035.pdf
代码:http://github.com/shendu0321/IncepFormer
论文创新思路
ViT的局限性:
1)标准的自我注意力机制带来了大量的计算复杂性,与输入token的数量成二次方。
2) ViT的输出特征图是单尺度的,这可能导致提取的特征缺乏丰富的上下文信息。
为了解决这些问题, Transformer模型采用降采样策略来减少特征大小,从而设计出一种分层编码器架构。金字塔视觉transformer(PVT)是第一个将金字塔结构用于密集预测的工作。之后,Xie等人提出了Mix Transformer(MiT),这也是一种金字塔结构,显示出在语义分割方面比SETR对应物有相当大的改进。Swin Transformer是另一种流行的分层视觉transformer,它计算局部窗口中的自我注意力度,并根据图像大小产生线性复杂度。
然而,这些方法只考虑了跨阶段/层的多尺度性质,而忽略了一个注意力层内对象的多尺度特性,即自我注意力多尺度,导致无法捕获不同大小对象中的丰富特征。
为了解决上述局限性,本文引入了一种新颖且通用的Transformer框架,即语义分割的高效Inception Transformer和Pyramid Pooling(IncepFormer)。
本文的主要贡献
•金字塔transformer编码器,它不仅考虑了不同阶段的特征图中的多尺度,还通过类似于初始的架构将多尺度性质纳入了自我注意力机制中。
•一个简单但功能强大的上采样 Concat解码器,它以极低的计算成本合并了精细定位和全局上下文信息。
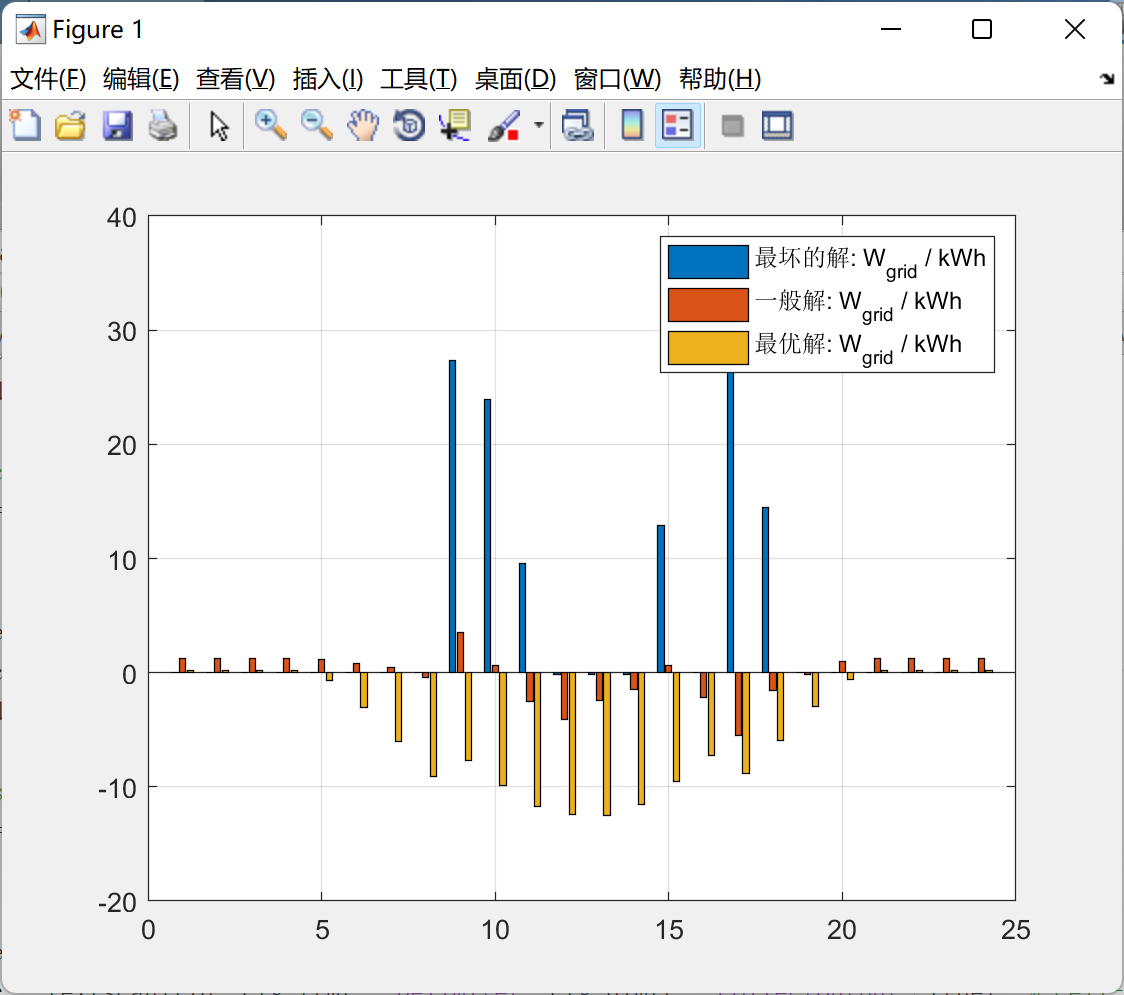
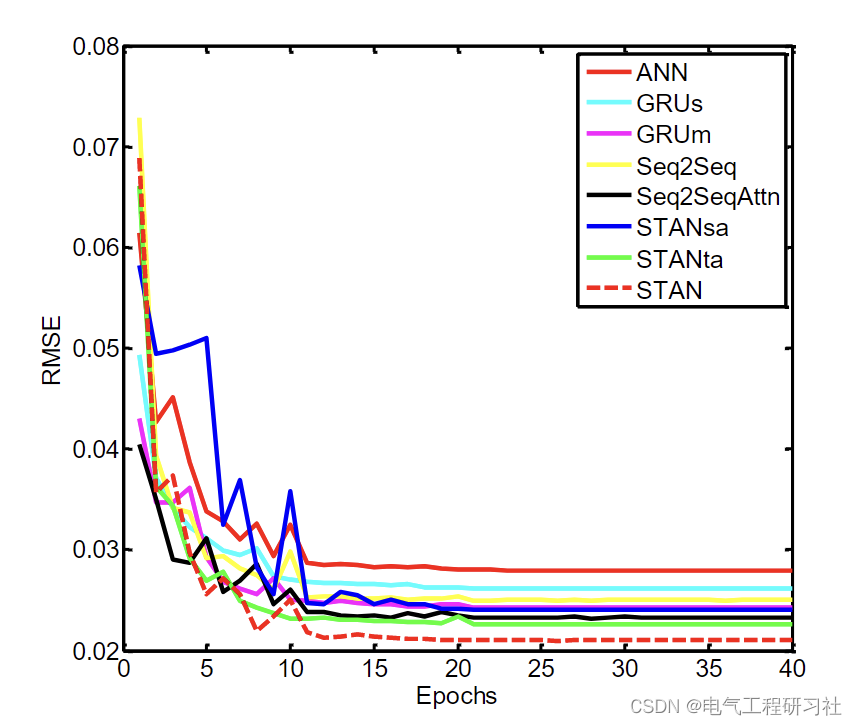
•本文的IncepFormer设计了三种不同尺寸的版本。如图1所示, IncepFormer在ADE20K数据集上实现了性能和计算成本之间的最佳权衡。

图1 ADE20K验证集的性能参数曲线。
方法
如图2(a)所示,InceptFormer由两个主要部分组成:1)金字塔Inception Transformer编码器,用于捕获粗粒度和细粒度特征;以及2)轻量级上采样Concat解码器,以直径方向合并多尺度特征并进行piexl级预测。

图2.(a):所提出的IncepFormer架构,由两个主要部分组成:1)一个金字塔transformer编码器,用于捕获粗粒度和细粒度特征;以及2)轻量级上采样Concat解码器,以直径方向合并多尺度特征并进行peixl级预测。
Inception Transformer Encoder
将InceptionNet中的多尺度卷积思想应用于transformer。所提出的初始transformer可以捕获更丰富的上下文信息,同时显著降低计算复杂性。初始transformer块(IPTB)结构如图2(b)所示。首先输入到标准化层,然后传递到Incep MHSA,其输出与原始输入残差连接。为了更好地适应2D图像结构,使用BatchNorm。第二个子块中,根据2D图像的特征对前馈网络E-FFN进行微调,以进行特征投影。可表述为:

Incep MHSA
Incep MHSA的设计如图3所示,不同于SRA和线性SRA,它们分别使用卷积和平均池来进行注意力操作之前的空间缩减,我们在X上应用三个不同的分支来生成特征图。在图3(c)中,在第一个分支,X经过核大小为1×R的深度卷积,然后再次进行核大小为R×1的深度卷积。

图3.PVT v1中的SRA、PVT v2中的线性SRA和Incep MHSA的比较。
第二个分支在X上应用了核大小为3×3的深度卷积。第三个分支首先使用具有缩减比率R的平均池,然后使用3×3深度卷积。上述过程为

之后,将特征图连接起来:
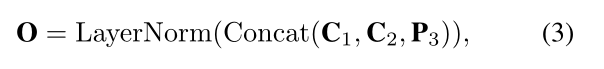
以这种方式,所获得的token序列O比输入X变平更短。此外,O包含输入X的丰富上下文抽象,因此在计算MHSA时可以作为输入X的替代。分别用Q、K和V表示MHSA中的查询、键和值张量。

Q、K、V被馈送到自我注意力模块以计算注意力度,其公式如下:
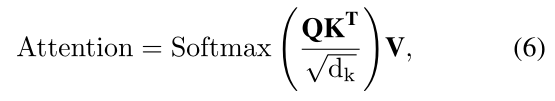
E-FFN
前馈网络(FFN)是transformer块特征增强的重要组成部分。如图4(a)所示,在应用于NLP领域的vanilla transformer中,之前的大部分方法都遵循了原来的FFN。

图4。原始前馈网络与高效前馈网络(E-FFN)的比较
这种设计虽然有效,但在学习二维局部性方面的能力较差,而这对于语义分割任务来说是必不可少的。用1 × 1卷积代替FC层,这样生成的FFN网络可以继承CNN的优点(即二维局域性)。首先,将输入序列Xatt转换为二维特征图Xin:

利用上述定义的Icep MHSA和E-FFN,作者设计了三种不同大小的编码器模型,分别称为微型版本IPT-T、小型版本IPT-S和基础版本IPT-B。相应的分割框架分别命名为IncepFormer-T、IncepFormer-S和IncepFormer-B,如图5所示。
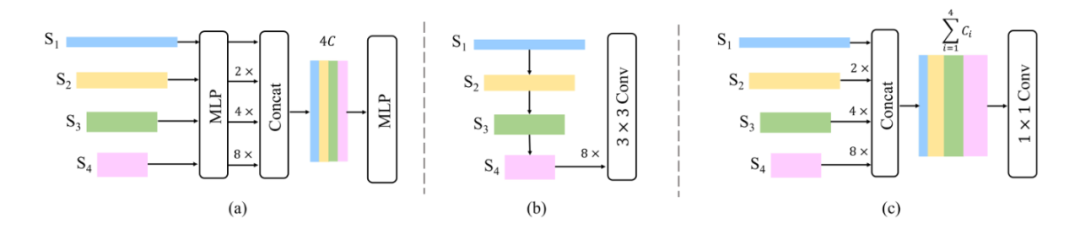
图5.三种不同的编码器架构。
A Simple Upsample-Concat Decoder
将每个阶段的特征图上采样到第14个,并连接在一起。然后,采用1 × 1卷积对拼接后的特征图进行线性transformer。最后,将拼接后的特征图输入到另一个1× 1卷积中,预测分割掩码M。该过程可表述为:

与其他典型的解码器相比,本文的解码器省去了对计算量要求很高的组件。而驱动该解码器的关键是金字塔型Transformer编码器,它不仅具有丰富的上下文信息和有效的感受野 (ERF),而且还通过使用多个带状卷积核来考虑小对象的特性。
实验

表1。与最新的ImageNet验证集方法的比较。

图6。城市景观数据集上SegFormer-B2和IncepFormer-S的定性比较。

表2。输出通道C对ADE20K解码器的影响。
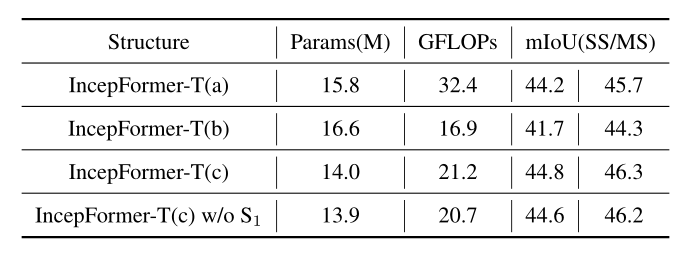
表3。不同编码器设计的结果。

表5所示。在ADE20K, cityscape和Pascal VOC数据集上与最先进的基于cnn的方法进行比较。

表6所示。Pascal Context数据集的比较。
结论
本文提出了一种简单、高效和强大的语义分割方法IncepFormer,它包含一个具有Inception自注意和有效FFN的金字塔transformer编码器和一个轻量级的Upsample-Concat解码器。
提出的incp-mhsa注重多尺度条形卷积的使用,在极大地降低复杂度的同时,获得了更好的局部特征提取和空间注意力建模。实验结果表明,IncepFormer在很大程度上超越了目前最先进的基于transformer和基于cnn的方法。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
模型部署交流群:732145323。用于计算机视觉方面的模型部署、高性能计算、优化加速、技术学习等方面的交流。
ECCV2022 | 重新思考单阶段3D目标检测中的IoU优化
目标检测模型的评价标准总结
Vision Transformer和MLP-Mixer联系和对比
Visual Attention Network
TensorRT教程(一)初次介绍TensorRT
TensorRT教程(二)TensorRT进阶介绍
从零搭建Pytorch模型教程(一)数据读取
从零搭建Pytorch模型教程(二)搭建网络
从零搭建Pytorch模型教程(三)搭建Transformer网络
从零搭建Pytorch模型教程(四)编写训练过程--参数解析
从零搭建Pytorch模型教程(五)编写训练过程--一些基本的配置
从零搭建Pytorch模型教程(六)编写训练过程和推理过程
从零搭建Pytorch模型教程(七)单机多卡和多机多卡训练
从零搭建pytorch模型教程(八)实践部分(一)微调、冻结网络
从零搭建pytorch模型教程(八)实践部分(二)目标检测数据集格式转换
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
入门必读系列(十五)神经网络不work的原因总结
入门必读系列(十四)CV论文常见英语单词总结
入门必读系列(十三)高效阅读论文的方法
入门必读系列(十二)池化各要点与各方法总结
入门必读系列(十一)Dropout原理解析
入门必读系列(十)warmup及各主流框架实现差异
入门必读系列(九)彻底理解神经网络
入门必读系列(八)优化器的选择
入门必读系列(七)BatchSize对神经网络训练的影响
入门必读系列(六)神经网络中的归一化方法总结
入门必读系列(五)如何选择合适的初始化方法
入门必读系列(四)Transformer模型
入门必读系列(三)轻量化模型
入门必读系列(二)CNN经典模型
入门必读系列(一)欠拟合与过拟合总结
![[附源码]Python计算机毕业设计Django预约挂号app](https://img-blog.csdnimg.cn/edec0154433e44e1ab04d30845442be9.png)