Go Mutex 的基本用法
Mutex 我们一般只会用到它的两个方法:
Lock:获取互斥锁。(只会有一个协程可以获取到锁,通常用在临界区开始的地方。)Unlock: 释放互斥锁。(释放获取到的锁,通常用在临界区结束的地方。)
Mutex 的模型可以用下图表示:

说明:
- 同一时刻只能有一个协程获取到
Mutex的使用权,其他协程需要排队等待(也就是上图的G1->G2->Gn)。 - 拥有锁的协程从临界区退出的时候需要使用
Unlock来释放锁,这个时候等待队列的下一个协程可以获取到锁(实际实现比这里说的复杂很多,后面会细说),从而进入临界区。 - 等待的协程会在
Lock调用处阻塞,Unlock的时候会使得一个等待的协程解除阻塞的状态,得以继续执行。
这几点也是
Mutex的基本原理。
Go Mutex 原子操作
Mutex结构体定义:
type Mutex struct {
state int32 // 状态字段
sema uint32 // 信号量
}
其中 state 字段记录了四种不同的信息:
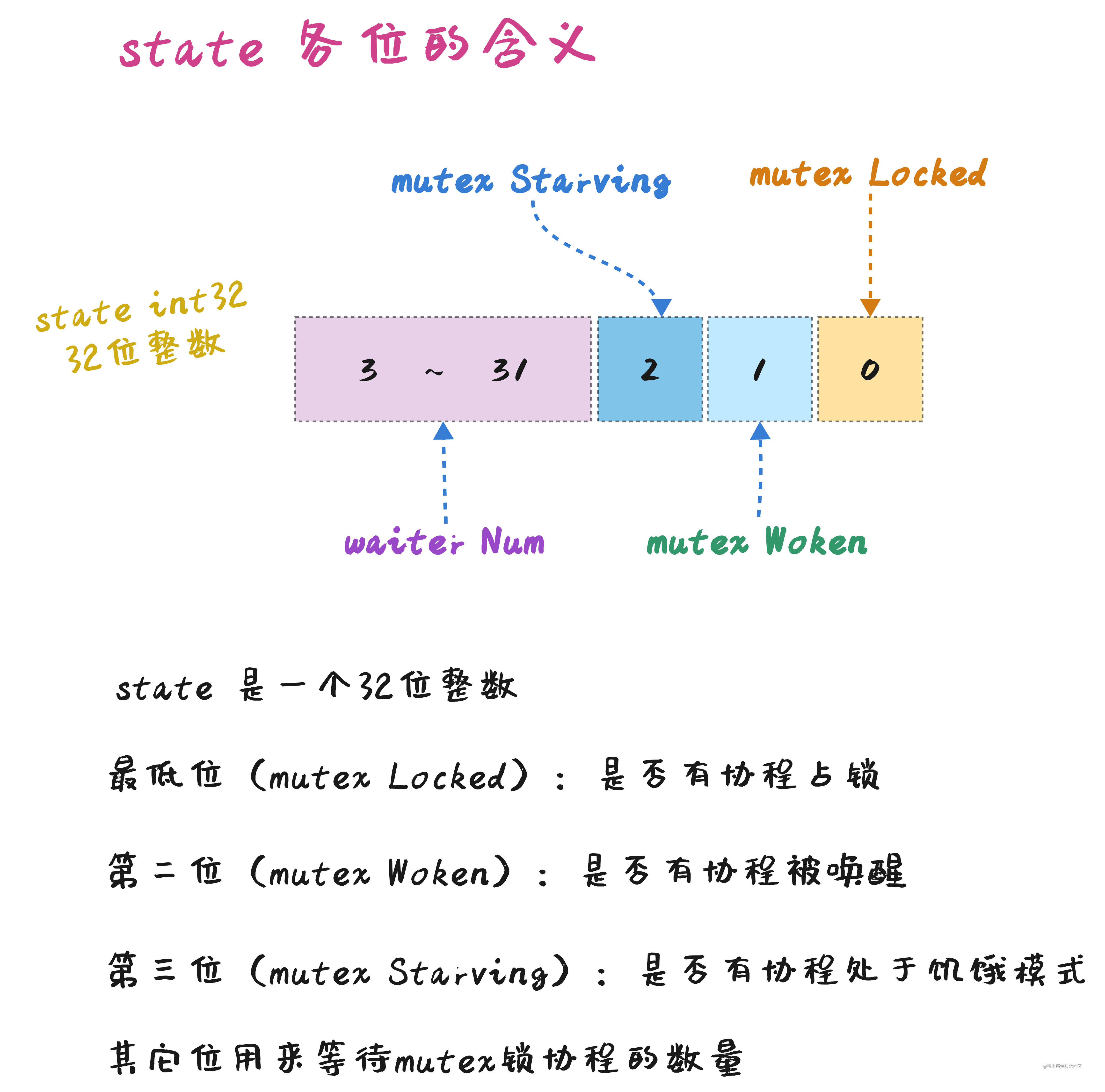
这四种不同信息在源码中定义了不同的常量:
const (
mutexLocked = 1 << iota // 表示有 goroutine 拥有锁
mutexWoken // 唤醒(就是第 2 位)
mutexStarving // 饥饿(第 3 位)
mutexWaiterShift = iota // 表示第 4 位开始,表示等待者的数量
starvationThresholdNs = 1e6 // 1ms 进入饥饿模式的等待时间阈值
)
而 sema 的含义比较简单,就是一个用作不同 goroutine 同步的信号量。
go 的 Mutex 实现中,state 字段是一个 32 位的整数,不同的位记录了四种不同信息,在这种情况下, 只需要通过原子操作就可以保证一次性实现对四种不同状态信息的更改,而不需要更多额外的同步机制。
但是毋庸置疑,这种实现会大大降低代码的可读性,因为通过一个整数来记录不同的信息, 就意味着,需要通过各种位运算来实现对这个整数不同位的修改。
当然,这只是 Mutex 实现中最简单的一种位运算了。下面以 state 记录的四种不同信息为维度来具体讲解一下:
-
mutexLocked:这是state的最低位,1表示锁被占用,0表示锁没有被占用。new := mutexLocked新状态为上锁状态
-
mutexWoken: 这是表示是否有协程被唤醒了的状态new = (old - 1<<mutexWaiterShift) | mutexWoken等待者数量减去 1 的同时,设置唤醒标识new &^= mutexWoken清除唤醒标识
-
mutexStarving:饥饿模式的标识new |= mutexStarving设置饥饿标识
-
等待者数量:
state >> mutexWaiterShift就是等待者的数量,也就是上面提到的FIFO队列中 goroutine 的数量new += 1 << mutexWaiterShift等待者数量加 1delta := int32(mutexLocked - 1<<mutexWaiterShift)上锁的同时,将等待者数量减 1
在上面做了这一系列的位运算之后,我们会得到一个新的 state 状态,假设名为 new,那么我们就可以通过 CAS 操作来将 Mutex 的 state 字段更新:
atomic.CompareAndSwapInt32(&m.state, old, new)
通过上面这个原子操作,我们就可以一次性地更新 Mutex 的 state 字段,也就是一次性更新了四种状态信息。
这种通过一个整数记录不同状态的写法在
sync包其他的一些地方也有用到,比如WaitGroup中的state字段。
最后,对于这种操作,我们需要注意的是,因为我们在执行 CAS 前后是没有其他什么锁或者其他的保护机制的, 这也就意味着上面的这个 CAS 操作是有可能会失败的,那如果失败了怎么办呢?
如果失败了,也就意味着肯定有另外一个 goroutine 率先执行了 CAS 操作并且成功了,将 state 修改为了一个新的值。 这个时候,其实我们前面做的一系列位运算得到的结果实际上已经不对了,在这种情况下,我们需要获取最新的 state,然后再次计算得到一个新的 state。
所以我们会在源码里面看到 CAS 操作是写在 for 循环里面的。
state的状态及枚举
| state状态 | state状态枚举 | 对应二进制 | 对应状态 |
|---|---|---|---|
| mutexUnLock | state=0 | 0000 | 未加锁 |
| mutexLocked | state=1 | 0001 | 加锁 |
| mutexWoken | state=2 | 0010 | 唤醒 |
| mutexStarving | state=4 | 0100 | 饥饿 |
| mutexWaiterShift | state=3 | 0011 | 代表位移 |
在看下面代码之前,一定要记住这几个状态之间的 与运算 或运算,否则代码里的与运算或运算
state: |32|31|...|3|2|1|
__________/ | |
| | |
| | mutex的占用状态(1被占用,0可用)
| |
| mutex的当前goroutine是否被唤醒
|
当前阻塞在mutex上的goroutine数
互斥锁的作用
互斥锁是保证同步的一种工具,主要体现在以下2个方面:
-
避免多个线程在同一时刻操作同一个数据块 (sum)
-
可以协调多个线程,以避免它们在同一时刻执行同一个代码块 (sum++)
什么时候用
-
需要保护一个数据或数据块时
-
需要协调多个协程串行执行同一代码块,避免并发问题时
比如 经常遇到A给B转账100元的例子,这个时候就可以用互斥锁来实现。
注意的坑
1. 不同 goroutine 可以 Unlock 同一个 Mutex,但是 Unlock 一个无锁状态的 Mutex 就会报错。
2. 因为 mutex 没有记录 goroutine_id,所以要避免在不同的协程中分别进行上锁/解锁操作,不然很容易造成死锁。
建议: 先 Lock 再 Unlock、两者成对出现。
3. Mutex 不是可重入锁
Mutex 不会记录持有锁的协程的信息,所以如果连续两次 Lock 操作,就直接死锁了。
如何实现可重入锁?记录上锁的 goroutine 的唯一标识,在重入上锁/解锁的时候只需要增减计数。
type RecursiveMutex struct {
sync.Mutex
owner int64 // 当前持有锁的 goroutine id // 可以换成其他的唯一标识
recursion int32 // 这个 goroutine 重入的次数
}
func (m *RecursiveMutex) Lock() {
gid := goid.Get() // 获取唯一标识
// 如果当前持有锁的 goroutine 就是这次调用的 goroutine,说明是重入
if atomic.LoadInt64(&m.owner) == gid {
m.recursion++
return
}
m.Mutex.Lock()
// 获得锁的 goroutine 第一次调用,记录下它的 goroutine id,调用次数加1
atomic.StoreInt64(&m.owner, gid)
m.recursion = 1
}
func (m *RecursiveMutex) Unlock() {
gid := goid.Get()
// 非持有锁的 goroutine 尝试释放锁,错误的使用
if atomic.LoadInt64(&m.owner) != gid {
panic(fmt.Sprintf("wrong the owner(%d): %d!", m.owner, gid))
}
// 调用次数减1
m.recursion--
if m.recursion != 0 { // 如果这个 goroutine 还没有完全释放,则直接返回
return
}
// 此 goroutine 最后一次调用,需要释放锁
atomic.StoreInt64(&m.owner, -1)
m.Mutex.Unlock()
}
4. 多高的 QPS 才能让 Mutex 产生强烈的锁竞争?
模拟一个 10ms 的接口,接口逻辑中使用全局共享的 Mutex,会发现在较低 QPS 的时候就开始产生激烈的锁竞争(打印锁等待时间和接口时间)。
解决方式:首先要尽量避免使用 Mutex。如果要使用 Mutex,尽量多声明一些 Mutex,采用取模分片的方式去使用其中一个 Mutex 进行资源控制。避免一个 Mutex 对应过多的并发。
简单总结:压测或者流量高的时候发现系统不正常,打开 pprof 发现 goroutine 指标在飙升,并且大量 Goroutine 都阻塞在 Mutex 的 Lock 上,这种现象下基本就可以确定是锁竞争。
5. Mutex 千万不能被复制
因为复制的时候会将原锁的 state 值也进行复制。复制之后,一个新 Mutex 可能莫名处于持有锁、唤醒或者饥饿状态,甚至等阻塞等待数量远远大于0。而原锁 Unlock 的时候,却不会影响复制锁。
关于锁的使用建议:
-
写业务时不能全局使用同一个 Mutex
-
千万不要将要加锁和解锁分到两个以上 Goroutine 中进行(容易形成死锁)
-
Mutex 千万不能被复制(包括不能通过函数参数传递),否则会复制传参前锁的状态:已锁定 or 未锁定。很容易产生死锁,关键是编译器还发现不了这个 Deadlock~
-
尽量避免使用 Mutex,如果非使用不可,尽量多声明一些 Mutex,采用取模分片的方式去使用其中一个 Mutex(分段锁)(尽量减小锁的颗粒度)
参考
- 标准库文档 —— sync.Mutex
结束语
本篇文章介绍说明了:
sync.Mutex 的基本用法
sync.Mutex 原子操作
sync.Mutex state 的
sync.Mutex 注意的坑
希望本篇文章对你有所帮助,谢谢。