目录
数据集
解释
movie.csv
ratings.csv
tag.csv
数据预处理
mongodb
将数据按照csv文件里的分割符进行分割,转换为DF
Moive
Rating
Tag
es
导入后数据库信息
mongodb
Movie
Rating
Tag
es
完整代码
数据集
链接:https://pan.baidu.com/s/1OjJ66PsES-qsun7sV_OeJA?pwd=2580
提取码:2580
解释
movie.csv
1^Toy Story (1995)^ ^81 minutes^March 20, 2001^1995^English
^Adventure|Animation|Children|Comedy|Fantasy ^Tom Hanks|Tim Allen|Don
Rickles|Jim Varney|Wallace Shawn|John Ratzenberger|Annie Potts|John
Morris|Erik von Detten|Laurie Metcalf|R. Lee Ermey|Sarah Freeman|Penn
Jillette|Tom Hanks|Tim Allen|Don Rickles|Jim Varney|Wallace Shawn ^John
Lasseter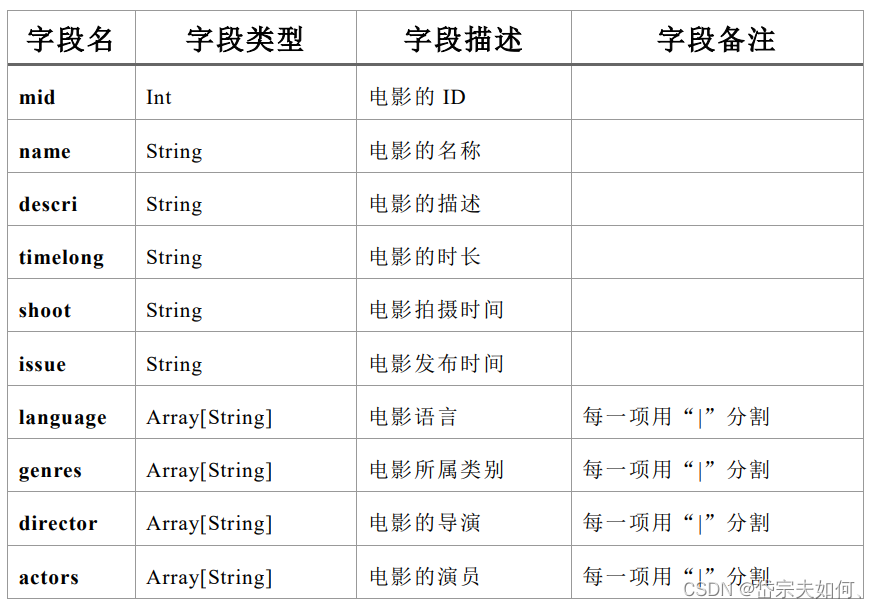
ratings.csv
1,31,2.5,1260759144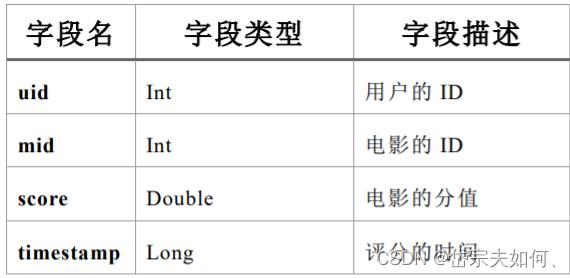
tag.csv
1,31,action,1260759144 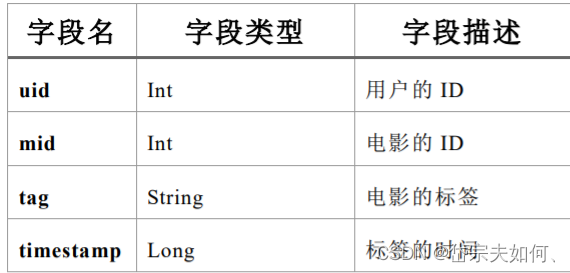
数据预处理
mongodb
将数据按照csv文件里的分割符进行分割,转换为DF
核心代码
Moive
//加载数据
val movieRDD = spark.sparkContext.textFile(MOVIE_DATA_PATH)
// 将数据预处理 字符串分割 => 数组 => 封装 成 Movie类
// 1^Toy Story (1995)^ ^81 minutes^March 20, 2001^1995^English ^Adventure|Animation|Children|Comedy|Fantasy ^Tom Hanks|Tim Allen|Don Rickles|Jim Varney|Wallace Shawn|John Ratzenberger|Annie Potts|John Morris|Erik von Detten|Laurie Metcalf|R. Lee Ermey|Sarah Freeman|Penn Jillette|Tom Hanks|Tim Allen|Don Rickles|Jim Varney|Wallace Shawn ^John Lasseter
val movieDF = movieRDD.map(
item => {
// .split() 里面一般是正则 ^ 的正则 \\^
val s = item.split("\\^")
// scala 数组用()
// .split()切割后,一般需要.trim
Movie(s(0).toInt, s(1).trim, s(2).trim, s(3).trim, s(4).trim, s(5).trim, s(6).trim, s(7).trim, s(8).trim, s(9).trim)
}
).toDF()
// mongodb
// { "_id" : ObjectId("644b85b62ecfa735d034ce31"), "mid" : 1, "name" : "Toy Story (1995)", "descri" : "", "timelong" : "81 minutes", "issue" : "March 20, 2001", "shoot" : "1995", "language" : "English", "genres" : "Adventure|Animation|Children|Comedy|Fantasy", "actors" : "Tom Hanks|Tim Allen|Don Rickles|Jim Varney|Wallace Shawn|John Ratzenberger|Annie Potts|John Morris|Erik von Detten|Laurie Metcalf|R. Lee Ermey|Sarah Freeman|Penn Jillette|Tom Hanks|Tim Allen|Don Rickles|Jim Varney|Wallace Shawn", "directors" : "John Lasseter" }Rating
val ratingRDD = spark.sparkContext.textFile(RATING_DATA_PATH)
// 1,31,2.5,1260759144
val ratingDF = ratingRDD.map(item => {
val s = item.split(",")
Rating(s(0).toInt, s(1).toInt, s(2).toDouble, s(3).toInt)
}).toDF()
// mongodb
//{ "_id" : ObjectId("644b85b62ecfa735d034d83f"), "uid" : 1, "mid" : 31, "score" : 2.5, "timestamp" : 1260759144 }Tag
// 15,1955,dentist,1193435061
val tagRDD = spark.sparkContext.textFile(TAG_DATA_PATH)
val tagDF = tagRDD.map(item => {
val s = item.split(",")
Tag(s(0).toInt, s(1).toInt, s(2).trim, s(3).toInt)
}).toDF()
// mongodb
// { "_id" : ObjectId("644b85b72ecfa735d035854f"), "uid" : 15, "mid" : 1955, "tag" : "dentist", "timestamp" : 1193435061 }es
将mongo集合tag 根据mid tag => mid tags(tag1|tag2|tag3...)
形成
mid1 tags(tag1|tag2|tag3...)
mid2 tags(tag1|tag2|tag3...)
mid3 tags(tag1|tag2|tag3...)
mid4 tags(tag1|tag2|tag3...) ...
核心代码
/* mid tags
* tags: tag1 |tag2|tag3
*/
val newTag = tagDF.groupBy($"mid")
//agg函数经常与groupBy函数一起使用,起到分类聚合的作用;
//如果单独使用则对整体进行聚合;
.agg(concat_ws("|", collect_set($"tag")).as("tags"))
.select("mid", "tags")相当于 hql
select mid, concat_ws("|",collect_set(tag)) as tags
from tag
group by mid;moive 添加一列 tags
核心代码
val newMovieDF = movieDF.join(newTag, Seq("mid"), "left")相当于 Hql
select *
from movie m
left join
select *
from newTag t
where m.mid = t.mid;导入后数据库信息
mongodb
sudo ./bin/mongod -config ./data/mongodb.confshow dbs
use 数据库名字
show collections
db.集合名字.find()Movie
{ "_id" : ObjectId("644b85b62ecfa735d034ce31"), "mid" : 1, "name" : "Toy Story (1995)", "descri" : "", "timelong" : "81 minutes", "issue" : "March 20, 2001", "shoot" : "1995", "language" : "English", "genres" : "Adventure|Animation|Children|Comedy|Fantasy", "actors" : "Tom Hanks|Tim Allen|Don Rickles|Jim Varney|Wallace Shawn|John Ratzenberger|Annie Potts|John Morris|Erik von Detten|Laurie Metcalf|R. Lee Ermey|Sarah Freeman|Penn Jillette|Tom Hanks|Tim Allen|Don Rickles|Jim Varney|Wallace Shawn", "directors" : "John Lasseter" }
Rating
{ "_id" : ObjectId("644b85b62ecfa735d034d83f"), "uid" : 1, "mid" : 31, "score" : 2.5, "timestamp" : 1260759144 }
Tag
{ "_id" : ObjectId("644b85b72ecfa735d035854f"), "uid" : 15, "mid" : 1955, "tag" : "dentist", "timestamp" : 1193435061 }
es
./bin/elasticsearch -dcurl http://hadoop100:9200/
完整代码
package com.qh.recommender
import com.mongodb.casbah.commons.MongoDBObject
import com.mongodb.casbah.{MongoClient, MongoClientURI}
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.elasticsearch.action.admin.indices.create.CreateIndexRequest
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest
import org.elasticsearch.action.admin.indices.exists.indices.IndicesExistsRequest
import org.elasticsearch.common.settings.Settings
import org.elasticsearch.common.transport.InetSocketTransportAddress
import org.elasticsearch.transport.client.PreBuiltTransportClient
import java.net.InetAddress
/**
* 将数据封装成样例类
*/
case class Movie(mid: Int, name: String, descri: String, timelong: String, issue: String,
shoot: String, language: String, genres: String, actors: String, directors: String)
case class Rating(uid: Int, mid: Int, score: Double, timestamp: Int)
case class Tag(uid: Int, mid: Int, tag: String, timestamp: Int)
/**
* 把mongodb, es的配置封装3成样例类
*/
/**
*
* @param uri MongoDB连接
* @param db MongoDB数据库
*/
case class MongoConfig(uri: String, db: String)
/**
*
* @param httpHosts http主机列表,逗号分割 9200
* @param transportHosts transport主机列表,集群内部传输用的端口号
* @param index 需要操作的索引
* @param clustername 集群名称,默认配置名
* 启动es cluter_name
* Movie/_search
*/
case class ESConfig(httpHosts: String, transportHosts: String, index: String, clustername: String)
object DataLoader {
val MOVIE_DATA_PATH = "E:\\project\\BigData\\MovieSystem\\recommender\\DataLoader\\src\\main\\resources\\movies.csv"
val RATING_DATA_PATH = "E:\\project\\BigData\\MovieSystem\\recommender\\DataLoader\\src\\main\\resources\\ratings.csv"
val TAG_DATA_PATH = "E:\\project\\BigData\\MovieSystem\\recommender\\DataLoader\\src\\main\\resources\\tags.csv"
// 定义表名参数
val MONGODB_MOVIE_COLLECTION = "Movie"
val MONGODB_RATING_COLLECTION = "Rating"
val MONGODB_TAG_COLLECTION = "Tag"
val ES_MOVIE_INDEX = "Movie"
def main(args: Array[String]): Unit = {
val config = Map(
"spark.cores" -> "local[*]",
"mongo.uri" -> "mongodb://hadoop100:27017/recommender",
"mongo.db" -> "recommender",
"es.httpHosts" -> "hadoop100:9200",
"es.transportHosts" -> "hadoop100:9300",
"es.index" -> "recommender",
"es.cluster.name" -> "es-cluster"
)
//创建一个sparkConf
val sparkConf = new SparkConf().setMaster(config("spark.cores")).setAppName("DataLoader")
//创建一个SparkSession
// builder中有一个getOrCreate方法,它是获取一个已经存在的会话,或者没有的情况下创建一个新的会话。
// https://zhuanlan.zhihu.com/p/343668901
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
// rdd=> df ds
// https://wenku.csdn.net/answer/6b3d109ee8d01601ccd9ac1944772477
import spark.implicits._
//加载数据
val movieRDD = spark.sparkContext.textFile(MOVIE_DATA_PATH)
// 将数据预处理 字符串分割 => 数组 => 封装 成 Movie类
// 1^Toy Story (1995)^ ^81 minutes^March 20, 2001^1995^English ^Adventure|Animation|Children|Comedy|Fantasy ^Tom Hanks|Tim Allen|Don Rickles|Jim Varney|Wallace Shawn|John Ratzenberger|Annie Potts|John Morris|Erik von Detten|Laurie Metcalf|R. Lee Ermey|Sarah Freeman|Penn Jillette|Tom Hanks|Tim Allen|Don Rickles|Jim Varney|Wallace Shawn ^John Lasseter
val movieDF = movieRDD.map(
item => {
// .split() 里面一般是正则 ^ 的正则 \\^
val s = item.split("\\^")
// scala 数组用()
// .split()切割后,一般需要.trim
Movie(s(0).toInt, s(1).trim, s(2).trim, s(3).trim, s(4).trim, s(5).trim, s(6).trim, s(7).trim, s(8).trim, s(9).trim)
}
).toDF()
// mongodb
// { "_id" : ObjectId("644b85b62ecfa735d034ce31"), "mid" : 1, "name" : "Toy Story (1995)", "descri" : "", "timelong" : "81 minutes", "issue" : "March 20, 2001", "shoot" : "1995", "language" : "English", "genres" : "Adventure|Animation|Children|Comedy|Fantasy", "actors" : "Tom Hanks|Tim Allen|Don Rickles|Jim Varney|Wallace Shawn|John Ratzenberger|Annie Potts|John Morris|Erik von Detten|Laurie Metcalf|R. Lee Ermey|Sarah Freeman|Penn Jillette|Tom Hanks|Tim Allen|Don Rickles|Jim Varney|Wallace Shawn", "directors" : "John Lasseter" }
val ratingRDD = spark.sparkContext.textFile(RATING_DATA_PATH)
// 1,31,2.5,1260759144
val ratingDF = ratingRDD.map(item => {
val s = item.split(",")
Rating(s(0).toInt, s(1).toInt, s(2).toDouble, s(3).toInt)
}).toDF()
// mongodb
//{ "_id" : ObjectId("644b85b62ecfa735d034d83f"), "uid" : 1, "mid" : 31, "score" : 2.5, "timestamp" : 1260759144 }
// 15,1955,dentist,1193435061
val tagRDD = spark.sparkContext.textFile(TAG_DATA_PATH)
val tagDF = tagRDD.map(item => {
val s = item.split(",")
Tag(s(0).toInt, s(1).toInt, s(2).trim, s(3).toInt)
}).toDF()
// mongodb
// { "_id" : ObjectId("644b85b72ecfa735d035854f"), "uid" : 15, "mid" : 1955, "tag" : "dentist", "timestamp" : 1193435061 }
//对于配置这样的,每次都需要传并且不变的的参数,可以 隐式定义
implicit val mongoConfig = MongoConfig(config("mongo.uri"), config("mongo.db"))
//保存到mongoudb
storeDataInMongoDB(movieDF, ratingDF, tagDF)
//数据预处理, 把movie对应的tag信息加入,添加一列 tag1|tag2|... string
//用sparksql
// org.apache.spark.sql.functions是一个Object,提供了约两百多个函数。
//大部分函数与Hive的差不多。
//除UDF函数,均可在spark-sql中直接使用。
//经过import org.apache.spark.sql.functions._ ,也可以用于Dataframe,Dataset。
//大部分支持Column的函数也支持String类型的列名。这些函数的返回类型基本都是Column。
//https://blog.csdn.net/qq_33887096/article/details/114532707
// 简单来说,如果用sparksql里面的函数,就要导入给类
import org.apache.spark.sql.functions._
// groupBy(cols $"列名" )
// scala 中 列名 可以用 $"列名"
/**
* 用Hive里函数
* 在tagDF将相同的mid的tag用|连接成tags列
* movie 对应的tag信息 用|链接 tag1 |tag2|tag3
* mid tags
* tags: tag1 |tag2|tag3
*/
// select mid, concat_ws("|",collect_set(tag)) as tags
//from tag
//group by mid;
val newTag = tagDF.groupBy($"mid")
//agg函数经常与groupBy函数一起使用,起到分类聚合的作用;
//如果单独使用则对整体进行聚合;
.agg(concat_ws("|", collect_set($"tag")).as("tags"))
.select("mid", "tags")
/**
* 将newTag和movie 左外连接
* join 默认内链接
*/
// select *
// from movie m
// left join
// select *
// from newTag t
// where m
// .mid = t.mid;
val newMovieDF = movieDF.join(newTag, Seq("mid"), "left")
implicit val esConfig = ESConfig(config("es.httpHosts"), config("es.transportHosts"), config("es.index"), config("es.cluster.name"))
//保存到es
storeDataInEs(newMovieDF)
spark.stop()
}
def storeDataInMongoDB(movieDF: DataFrame, ratingDF: DataFrame, tagDF: DataFrame)(implicit mongoConfig: MongoConfig): Unit = {
// 新建一个mongodb的连接
val mongoClient = MongoClient(MongoClientURI(mongoConfig.uri))
// 如果mongodb中已经有相应的数据库,先删除
mongoClient(mongoConfig.db)(MONGODB_MOVIE_COLLECTION).dropCollection()
mongoClient(mongoConfig.db)(MONGODB_RATING_COLLECTION).dropCollection()
mongoClient(mongoConfig.db)(MONGODB_TAG_COLLECTION).dropCollection()
// 将DF数据写入对应的mongodb表中
movieDF.write
.option("uri", mongoConfig.uri)
.option("collection", MONGODB_MOVIE_COLLECTION)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
ratingDF.write
.option("uri", mongoConfig.uri)
.option("collection", MONGODB_RATING_COLLECTION)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
tagDF.write
.option("uri", mongoConfig.uri)
.option("collection", MONGODB_TAG_COLLECTION)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
//对数据表建索引
mongoClient(mongoConfig.db)(MONGODB_MOVIE_COLLECTION).createIndex(MongoDBObject("mid" -> 1))
mongoClient(mongoConfig.db)(MONGODB_RATING_COLLECTION).createIndex(MongoDBObject("uid" -> 1))
mongoClient(mongoConfig.db)(MONGODB_RATING_COLLECTION).createIndex(MongoDBObject("mid" -> 1))
mongoClient(mongoConfig.db)(MONGODB_TAG_COLLECTION).createIndex(MongoDBObject("uid" -> 1))
mongoClient(mongoConfig.db)(MONGODB_TAG_COLLECTION).createIndex(MongoDBObject("mid" -> 1))
mongoClient.close()
}
def storeDataInEs(movieDF: DataFrame)(implicit esConfig: ESConfig): Unit = {
// 新建es配置
val settings: Settings = Settings.builder().put("cluster.name", esConfig.clustername).build()
// 新建一个es客户端
val esClient = new PreBuiltTransportClient(settings)
//用正则进行集群主机名分割
val REGEX_HOST_PORT = "(.+):(\\d+)".r
// 添加集群主机和端口
esConfig.transportHosts.split(",").foreach {
case REGEX_HOST_PORT(host: String, port: String) => {
// es里面的类InetSocketTransportAddress 需要 java的InetAddress类
esClient.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName(host), port.toInt))
}
}
// 清洗遗留数据
if (esClient.admin().indices().exists(new IndicesExistsRequest(esConfig.index))
.actionGet()
.isExists
) {
esClient.admin().indices().delete(new DeleteIndexRequest(esConfig.index))
}
//创建 库
esClient.admin().indices().create(new CreateIndexRequest(esConfig.index))
// 写入数据
movieDF.write
.option("es.nodes", esConfig.httpHosts)
.option("es.http.timeout", "100m")
.option("es.mapping.id", "mid")
.mode("overwrite")
.format("org.elasticsearch.spark.sql")
.save(esConfig.index + "/" + ES_MOVIE_INDEX)
}
}来源:尚硅谷
(9条消息) MongoDB 查看集合中所有的数据_mongodb查询集合所有数据_Tw_light的博客-CSDN博客